
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
损失函数
前言
如果有人问你现在有多幸福,你会如何回答呢?一般的人可能会给出诸如“还可以吧”或者“不是那么幸福”等笼统的回答。如果有人回答“我现在的幸福指数是10.23”的话,可能会把人吓一跳吧。因为他用一个数值指标来评判自己的幸福程度。
这里的幸福指数只是打个比方,实际上神经网络的学习也在做同样的事情。神经网络的学习通过某个指标表示现在的状态。然后,以这个指标为基准,寻找最优权重参数。和刚刚那位以幸福指数为指引寻找“最优人生”的人一样,神经网络以某个指标为线索寻找最优权重参数。
一、损失函数是什么?
损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。以“性能的恶劣程度”为指标可能会使人感到不太自然,但是如果给损失函数乘上一个负值,就可以解释为“在多大程度上不坏”.即“性能有多好”。并且,“使性能的恶劣程度达到最小”和“使性能的优良程度达到最大”是等价的,不管是用“恶劣程度”还是“优良程度”,做的事情本质上都是一样的。
神经网络以某个指标为线索寻找最优权重参数。神经网络的学习中所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数但一般用均方误差和交叉熵误差等
二、常用的损失函数
1.均方误差
可以用作损失函数的函数有很多,其中最有名的是均方误差(mean squared error)。均方误差如下式所示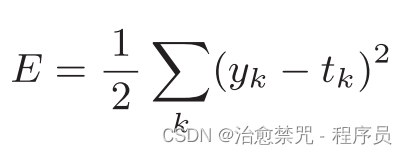
这里,yk是表示神经网络的输出,tk表示监督数据,k表示数据的维数。
均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和。现在,我们用Python来实现这个均方误差实现方式如下所示。
defmean_squared_error(y,t):return0.5* np.sum((y-t)**2)
2.交叉熵误差
除了均方误差之外,交叉熵误差(cross entropy error)也经常被用作损失函数。交叉熵误差如下式所示: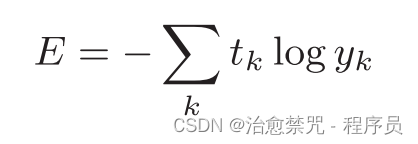
这里,log表示以e为底数的自然对数(log e)。yk是神经网络的输出,tk是正确解标签。并且,tk中只有正确解标签的索引为1,其他均为 0(one-hot 表示)因此,实际上只计算对应正确解标签的输出的自然对数。比如,假设正确解标签的索引是“2”,与之对应的神经网终的输出是0.6,则交叉熵误差是-log 0.6 = 0.51;若“2”对应的输出是0.1,则交叉误差为 -log 0.1 = 2.30.也就是说,交叉熵误差的值是由正确解标签所对应的输出结果决定的。
自然对数的图像如图所示 交叉熵误差代码:
交叉熵误差代码:
defcross_entropy_error(y,t):
delta = le-7return-np.sum(t * np.log(y + delta))
这里,参数y和t是NumPy数组。函数内部在计算 np.log时,加上了一个微小值delta。这是因为,当出现np.log(0) 时,np.log(0) 会变为负无限大的 -inf,这样一来就会导致后续计算无法进行。作为保护性对策,添加一个微小值可以防止负无限大的发生。
总结
上面我们讨论了损失函数,可能有人要问:“为什么要导入损失函数呢?以数字识别任务为例,我们想获得的是能提高识别精度的参数,特意再导人一个损失函数不是有些重复劳动吗?也就是说,既然我们的目标是获得使识别精度尽可能高的神经网络,那不是应该把识别精度作为指标吗?
对于这一疑问,我们可以根据“导数”在神经网络学习中的作用来回答下一节中会详细说到,在神经网络的学习中,寻找最优参数(权重和偏置)时要寻找使损失函数的值尽可能小的参数。为了找到使损失函数的值尽可能小的地方,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引,逐步更新参数的值。
假设有一个神经网络,现在我们来关注这个神经网络中的某一个权重参数。此时,对该权重参数的损失函数求导,表示的是“如果稍微改变这个权重参数的值,损失函数的值会如何变化”。如果导数的值为负,通过使该权重参数向正方向改变,可以减小损失函数的值;反过来,如果导数的值为正.则通过使该权重参数向负方向改变,可以减小损失函数的值。不过,当导数的值为0时,无论权重参数向哪个方向变化,损失函数的值都不会改变,此时该权重参数的更新会停在此处。
在进行神经网络的学习时,不能将识别精度作为指标。因为如果以识别精度为指标,则参数的导数在绝大多数地方都会变为 0。
我们来思考另一个具体例子。假设某个神经网络正确识别出了 100 笔训练数据中的32笔,此时识别精度为32 %。如果以识别精度为指标,即使稍微改变权重参数的值,识别精度也仍将保持在32 %,不会出现变化。也就是说,仅仅微调参数,是无法改善识别精度的。即便识别精度有所改善,它的值也不会像32.0123…%这样连续变化,而是变为33 %34 %这样的不连续的、离散的值。而如果把损失函数作为指标,则当前损失函数的值可以表示为0.92543…· 这样的值。并且,如果稍微改变一下参数的值,对应的损失函数也会像0.93432·.· 这样发生连续性的变化。
版权归原作者 燃烧的小趴菜 所有, 如有侵权,请联系我们删除。