
哈希表
哈希概念
通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素
哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
映射方式
①直接定址法
用数组与数据的相对映射或绝对位置建立索引关系,此时增删查改时间复杂度O(1)
缺陷:
1.如果数据范围很大,直接定制法会浪费大量的空间
2.不能处理字符串,浮点数等数据,无法被拿来作为数组的索引
适用于:整数,并且数据集中的情况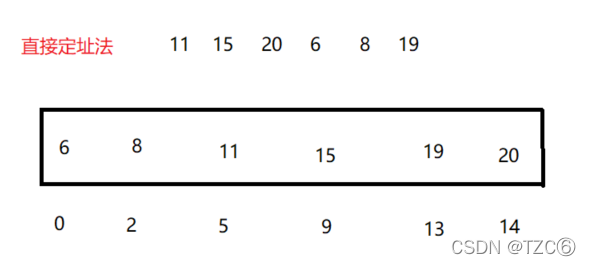
②除留余数法
解决数据范围很大的问题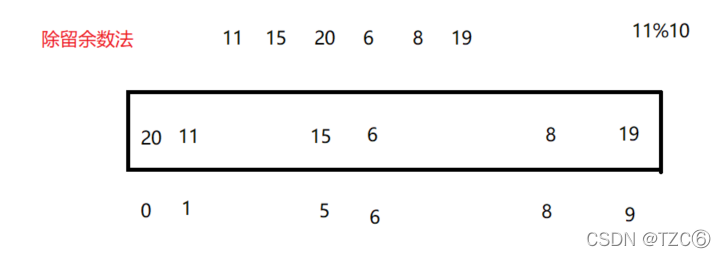
但是除留余数法存在哈希冲突(不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞)
解决哈希冲突
1.闭散列(开放定址法)
①线性探测

线性探测会导致踩踏效应(连续的位置出现冲突)
②二次探测

二次探测相对线性探测数据更分散,能有效缓解踩踏效应
负载因子(载荷因子)=存储的有效数据个数/空间大小
负载因子越大,冲突的概率越高,增删查改的效率就会越低,空间利用率越高
负载因子越小,冲突的概率越低,增删查改的效率就会越高,空间利用率越低
所以哈希表一个重要的问题就是控制负载因子的大小
③结点的设计
为了判断数组的某一个位置是否为空,我们用State来标识数组中数据的状态
//枚举出数据的三种状态enumState{
EMPTY,//空
EXITS,//存在
DELETE,//被删除 删除时只需要将状态修改为DELETE,这样实现"假"删除};template<classK,classV>structHashData{//每一个数据结点 存于vector//kv结构
pair<K, V> _kv;
State _state = EMPTY;};
④查找操作
当查找为空时就没找到,我们控制负载因子大小小于0.8,所以一定会存在空位置
HashData<K,V>*Find(const K& key){//判断是否为空if(_table.size()==0){returnnullptr;}
HashFunc hf;
size_t start =hf(key)% _table.size();
size_t index = start;
size_t i =1;while(_table[index].state != EMPTY){//找到了if(_table[index]._state==EXITS && _table[index]._kv.first == key){return&_table[index];}//往后查找//线性探测 二次探测只需改为 index=start+i*i;
index =start+ i;
index %= _table.size();++i;}returnnullptr;}
⑤插入操作
插入操作需要注意增容问题,增容后,数据必须重新映射
boolInsert(const pair<K, V>& kv){//判断是否存在
HashData<K,V>* ret =Find(kv.first);if(ret){returnfalse;}//size==0if(_table.size()==0){
_table.resize(10);}//计算负载因子 elseif((double)_n/(double)_table.size()>0.8){//增容后所有数据必须重新映射进新数组//重新创建HashTable对象 复用其insert函数
HashTable<K, V,HashFunc> newHashTable;
newHashTable.resize(2* _table.size());//遍历原Table的数据for(auto& e : _table){if(e._state == EXITS){//复用Insert
newHashTable.Insert(e._kv);}}
_table.swap(newHashTable._table);}
HashFunc hf;//如果访问大于size<capacity 的数据
size_t start =hf(kv.first)% _table.size();
size_t index = start;
size_t i =1;//线性探测或者二次探测while(_table[index]._state == EXITS){
index += start+i;
index %= _table.size();++i;}
_table[index]._kv = kv;
_table[index]._state = EXITS;++_n;}
⑥删除操作
找到后只需修改状态即可
boolErase(const K& key){//查找
HashData<K, V>* ret =Find(key);if(ret ==nullptr){returnfalse;}else{//修改结点状态
ret->_state = DELETE;--_n;returntrue;}}
完整代码
#pragmaonce#include<vector>#include<iostream>usingnamespace std;//closeHashnamespace tzc
{enumState{
EMPTY,
EXITS,
DELETE,};template<classK,classV>structHashData{
pair<K, V> _kv;
State _state = EMPTY;};template<classK>structHashFunc{intoperator()(int i){return i;}};template<>structHashFunc<string>{
size_t operator()(const string& s){//return s[0];
size_t value =0;for(auto ch : s){
value += ch;
value *=131;}return value;}};structpairHashFunc{
size_t operator()(const pair<string, string>& kv){
size_t value =0;//以KEY作为标准for(auto& ch : kv.first){
value += ch;
value *=131;}return value;}};template<classK,classV,classHashFunc>classHashTable{public:boolInsert(const pair<K, V>& kv){//判断是否存在
HashData<K,V>* ret =Find(kv.first);if(ret){returnfalse;}//size==0if(_table.size()==0){
_table.resize(10);}//计算负载因子 elseif((double)_n/(double)_table.size()>0.8){//增容后所有数据必须重新映射进新数组//重新创建HashTable对象 复用其insert函数
HashTable<K, V,HashFunc> newHashTable;
newHashTable.resize(2* _table.size());for(auto& e : _table){if(e._state == EXITS){//复用插入
newHashTable.Insert(e._kv);}}
_table.swap(newHashTable._table);}
HashFunc hf;
size_t start =hf(kv.first)% _table.size();//table[]
size_t index = start;
size_t i =1;//线性探测或者二次探测while(_table[index]._state == EXITS){
index += start+i;
index %= _table.size();++i;}
_table[index]._kv = kv;
_table[index]._state = EXITS;++_n;}
HashData<K,V>*Find(const K& key){//判断是否为空if(_table.size()==0){returnnullptr;}
HashFunc hf;
size_t start =hf(key)% _table.size();
size_t index = start;
size_t i =1;while(_table[index].state != EMPTY){//找到了if(_table[index]._state==EXITS && _table[index]._kv.first == key){return&_table[index];}//往后查找//线性探测 二次探测只需改为 index=start+i*i;
index =start+ i;
index %= _table.size();++i;}returnnullptr;}boolErase(const K& key){
HashData<K, V>* ret =Find(key);if(ret ==nullptr){returnfalse;}else{
ret->_state = DELETE;--_n;returntrue;}}private:
vector<HashData<K,V>> _table;
size_t _n;//数组中存的数据的个数};}
哈希存在的问题
对于下列语句:
size_t start =hf(kv.first)% _table.size();
当key存储的是string,自定义类型等数据时,不能转换成为映射关系存储在哈希表中
这时就需要自己实现对应的仿函数来转换key取模
template<classK>structHashFunc{intoperator()(int i){return i;}};//模板特化template<>structHashFunc<string>{
size_t operator()(const string& s){//return s[0];
size_t value =0;for(auto ch : s){
value += ch;
value *=131;}return value;}

可以看出如果一个类型去做map/set的key需要能支持比较大小
去做unordered_map/unordered_set的key需要能转换成整形(支持取模)以及能比较相等
2.开散列
开散列–哈希桶/拉链法
数组中存储结构体的单链表指针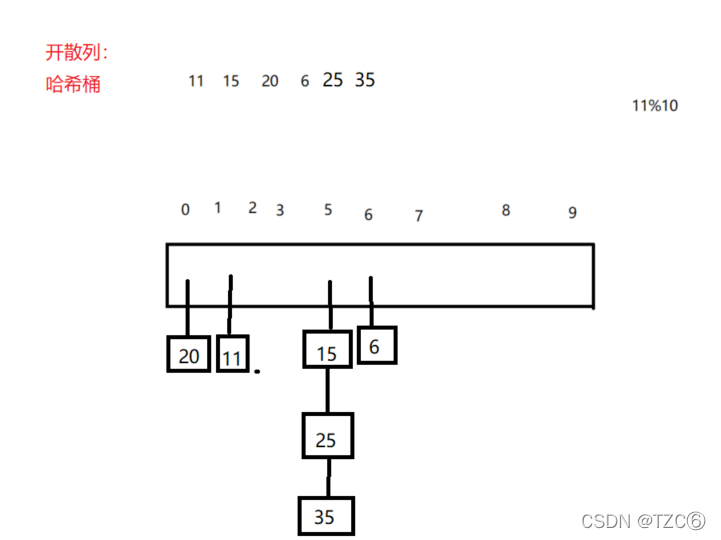
①结点设计
vector存储的结点
template<classK,classV>structHashNode{
pair<K, V> _kv;
HashNode<K, V>* _kv;HashNode(const pair<K, V>& kv):_next(__nullptr),_kv(kv){}};
HashTable所包含的私有成员
vector<Node*> _table;
size_t _n =0;//有效数据个数
②插入操作
增容:约定当负载因子等于1时,需要增容重整,遍历旧表中的结点插入到新表中
哈希表重整方法一:巧妙地复用了insert的方法
boolInsert(const pair<K.V>& kv){if(Find(kv.first)){returnfalse;}if(_n == _table.size()){//开辟新的vector
vector<Node*> newtable;
size_t newSize = _table.size()==0?11: _table.size()*2;
newtable.resize(GetNextPrime(_table.size()),nullptr);//遍历旧的表for(size_t i =0; i < _table.size();++i){if(_table[i]){
Node* cur = _table[i];while(cur){
Node* next = cur->_next;
size_t index = cur->_kv.first % newtable.size();//头插法
cur->_next = _table[index];
_table[index]= cur;
cur = next;}
_table[i]=nullptr;}}//旧的与新的交换
_table.swap(newtable);}
HashFunc fc;
size_t index =fc(kv.first)% _table.size();
Node* newnode =newNode(kv);//头插
newnode->_next = _table[index];
_table[index]= newnode;++_n;returntrue;}
哈希表重整方法二:通过不断地将旧桶结点的头结点插入到新的对应的vector,来实现了重整
boolInsert(const pair<K.V>& kv){if(Find(kv.first)){returnfalse;}if(_n == _table.size()){
vector<Node*>newtable(sizeof(_table.size()),(Node*)0);//遍历旧结点for(size_t i=0;i<_table.size();i++){
Node* cur=_table[i];while(cur){//找出结点在哪个桶
HashFunc fc;
size_t cur_bucket=fc(cur.first)% _table.size();//四步微妙的操作//1.将cur的下一个结点拿到该桶的头部
_table[i]=cur->next;//2,3:将cur结点用头插法插入新的vector中
cur->next=newtable[cur_bucket];
newtable[cur_bucket]=cur;//4.cur重新成为旧桶的头部
cur=_table[i];}}
_table.swap(newtable);}
HashFunc fc;
size_t index =fc(kv.first)% _table.size();
Node* newnode =newNode(kv);//头插
newnode->_next = _table[index];
_table[index]= newnode;++_n;returntrue;}
③查找操作
Node*Find(const K& key){if(_table.size()==0){returnfalse;}
HashFunc fc;
size_t index =fc(key)% _table.size();
Node* cur = _table[index];while(cur){if(cur->_kv.first == key){return cur;}else{
cur = cur->_next;}}returnnullptr;}
④删除操作
boolErase(const K& key){
HashFunc fc;
size_t index =fc(key)% _table.size();
Node* prev =nullptr;
Node* cur = _table[index];while(cur){if(cur->_kv.first == key){//删除的是头结点if(_table[index]== cur){
_table[index]= cur->_next;}else{
prev->_next = cur->_next;}--_n;delete cur;returntrue;}
prev = cur;
cur = cur->_next;}}
哈希桶的优势:
1.空间利用率高
2.极端情况(全部冲突)还有解决方案
哈希桶冲突的解决
如果此时数据集中在某几个桶上,在查找,删除时,时间复杂度会非常大,可能等于O(N)
1.所以可以控制负载因子
而开散列的负载因子可能会大于1,所以控制负载因子一般在[0,1]
2.其次在数据不多的时候,负载因子很低,但这大部分数据都冲突了
可以采用在数据多的这个桶,将其数据结构改成红黑树
桶的大小的设计:
尽量让表的大小是素数,这样更不容易冲突
constint PRIMECOUNT =28;const size_t primeList[PRIMECOUNT]={53ul,97ul,193ul,389ul,769ul,1543ul,3079ul,6151ul,12289ul,24593ul,49157ul,98317ul,196613ul,393241ul,786433ul,1572869ul,3145739ul,6291469ul,12582917ul,25165843ul,50331653ul,100663319ul,201326611ul,402653189ul,805306457ul,1610612741ul,3221225473ul,4294967291ul};
size_t GetNextPrime(size_t prime){
size_t i =0;for(; i < PRIMECOUNT;++i){if(primeList[i]> primeList[i])return primeList[i];}return primeList[i];}
封装
①迭代器
迭代器除了传当前结点指针,还应该传入该哈希表
因为迭代器走到一个桶的末尾结点时,++找不到下一个桶的位置
这时传入哈希表,重新计算下一个桶的位置
// 前置声明 //定义的时候才给默认参数template<classK,classT,classKeyOfT,classHashFunc>classHashTable;// 迭代器template<classK,classT,classKeyOfT,classHashFunc= Hash<K>>struct__HTIterator{typedef HashNode<T> Node;typedef __HTIterator<K, T, KeyOfT, HashFunc> Self;typedef HashTable<K, T, KeyOfT, HashFunc> HT;
Node* _node;
HT* _pht;//传给迭代器哈希表__HTIterator(Node* node, HT* pht):_node(node),_pht(pht){}
Self&operator++(){// 1、逐个遍历每个桶的结点if(_node->_next){
_node = _node->_next;}//到下一个桶else{//size_t index = HashFunc()(KeyOfT()(_node->_data)) % _pht->_table.size();
KeyOfT kot;
HashFunc hf;
size_t index =hf(kot(_node->_data))% _pht->_table.size();++index;while(index < _pht->_table.size()){if(_pht->_table[index]){//_pht访问私有成员需要申明友元
_node = _pht->_table[index];return*this;}//为空桶else{++index;}}
_node =nullptr;}return*this;}//底层实现用的是单向链表,并没有重载--
T&operator*(){return _node->_data;}
T*operator->(){return&_node->_data;}booloperator!=(const Self& s)const{return _node != s._node;}booloperator==(const Self& s)const{return _node == s.node;}};
②hash functions
hash fuctions是仿函数,解决存储的值的取模的问题
①针对char,int,long等本身就是整数型别,直接返回值
②对string,以及内置类型需要进行特殊的运算后才能返回
并且返回的值要考虑产生的哈希冲突的问题
//转化Key,实现取模运算template<classK>structHash{
size_t operator()(const K& key){return key;}};// 特化stringtemplate<>structHash< string >{
size_t operator()(const string& s){// BKDR Hash
size_t value =0;for(auto ch : s){
value += ch;
value *=131;}return value;}};
③哈希表
//结点存储Ttemplate<classT>structHashNode{
HashNode<T>* _next;
T _data;HashNode(const T& data):_next(nullptr),_data(data){}};template<classK,classT,classKeyOfT,classHashFunc= Hash<K>>classHashTable{typedef HashNode<T> Node;template<classK,classT,classKeyOfT,classHashFunc>friendstruct__HTIterator;//类模板参数友元public:typedef __HTIterator<K, T, KeyOfT, HashFunc> iterator;HashTable()=default;// 显示指定生成默认构造//深拷贝HashTable(const HashTable& ht){
_n = ht._n;
_table.resize(ht._table.size());for(size_t i =0; i < ht._table.size(); i++){
Node* cur = ht._table[i];while(cur){
Node* copy =newNode(cur->_data);// 遍历插入
copy->_next = _table[i];
_table[i]= copy;
cur = cur->_next;}}}
HashTable&operator=(HashTable ht){
_table.swap(ht._table);swap(_n, ht._n);return*this;}~HashTable(){for(size_t i =0; i < _table.size();++i){
Node* cur = _table[i];while(cur){
Node* next = cur->_next;delete cur;
cur = next;}
_table[i]=nullptr;}}//计算表中桶的个数
size_t bucket_count()const{return _table.size();}
iterator begin(){
size_t i =0;while(i < _table.size()){if(_table[i]){returniterator(_table[i],this);}++i;}returnend();}
iterator end(){returniterator(nullptr,this);}
size_t GetNextPrime(size_t prime){constint PRIMECOUNT =28;staticconst size_t primeList[PRIMECOUNT]={53ul,97ul,193ul,389ul,769ul,1543ul,3079ul,6151ul,12289ul,24593ul,49157ul,98317ul,196613ul,393241ul,786433ul,1572869ul,3145739ul,6291469ul,12582917ul,25165843ul,50331653ul,100663319ul,201326611ul,402653189ul,805306457ul,1610612741ul,3221225473ul,4294967291ul};
size_t i =0;for(; i < PRIMECOUNT;++i){if(primeList[i]> prime)return primeList[i];}return primeList[i];}//计算最大桶的个数
size_t maxbucket_count()const{return primeList[PRIMECOUNT-1];}//哈希桶实现
pair<iterator,bool>Insert(const T& data){
KeyOfT kot;// 找到了auto ret =Find(kot(data));if(ret !=end())returnmake_pair(ret,false);
HashFunc hf;// 负载因子到1时,进行增容if(_n == _table.size()){
vector<Node*> newtable;//size_t newSize = _table.size() == 0 ? 8 : _table.size() * 2;//newtable.resize(newSize, nullptr);
newtable.resize(GetNextPrime(_table.size()));// 遍历取旧表中节点,映射到新表中for(size_t i =0; i < _table.size();++i){if(_table[i]){
Node* cur = _table[i];while(cur){
Node* next = cur->_next;
size_t index =hf(kot(cur->_data))% newtable.size();// 头插
cur->_next = newtable[index];
newtable[index]= cur;
cur = next;}
_table[i]=nullptr;}}
_table.swap(newtable);}
size_t index =hf(kot(data))% _table.size();
Node* newnode =newNode(data);// 头插
newnode->_next = _table[index];
_table[index]= newnode;++_n;returnmake_pair(iterator(newnode,this),true);}
iterator Find(const K& key){if(_table.size()==0){returnend();}
KeyOfT kot;//取key
HashFunc hf;//转化key取模
size_t index =hf(key)% _table.size();
Node* cur = _table[index];while(cur){if(kot(cur->_data)== key){returniterator(cur,this);}else{
cur = cur->_next;}}returnend();}boolErase(const K& key){
size_t index =hf(key)% _table.size();
Node* prev =nullptr;
Node* cur = _table[index];while(cur){if(kot(cur->_data)== key){if(_table[index]== cur){
_table[index]= cur->_next;}else{
prev->_next = cur->_next;}--_n;delete cur;returntrue;}
prev = cur;
cur = cur->_next;}returnfalse;}private:
vector<Node*> _table;
size_t _n =0;// 有效数据的个数};
UnorderedSet
运用set是方便能够快速找到元素
底层是红黑树的set具有自动排序的功能(中序遍历),而底层是哈希表的UnorderedSet就没有
namespace tzc
{template<classK>classunordered_set{//取keystructSetKeyOfT{const K&operator()(const K& k){return k;}};public:typedeftypenameOpenHash::HashTable<K, K, SetKeyOfT >::iterator iterator;
iterator begin(){return _ht.begin();}
iterator end(){return _ht.end();}
pair<iterator,bool>insert(const K k){return _ht.Insert(k);}private:
OpenHash::HashTable<K, K, SetKeyOfT> _ht;//开散列实现的哈希表};}
UnorderedMap
namespace tzc
{template<classK,classV>classunordered_map{//取KeystructMapKeyOfT{const K&operator()(const pair<K, V>& kv){return kv.first;}};public:typedeftypenameOpenHash::HashTable<K, pair<K, V>, MapKeyOfT>::iterator iterator;
iterator begin(){return _ht.begin();}
iterator end(){return _ht.end();}
pair<iterator,bool>insert(const pair<K, V>& kv){return _ht.Insert(kv);}
V&operator[](const K& key)//重载[]{
pair<iterator,bool> ret = _ht.Insert(make_pair(key,V()));return ret.first->second;}private:
OpenHash::HashTable<K, pair<K, V>, MapKeyOfT> _ht;};}
版权归原作者 TZC⑥ 所有, 如有侵权,请联系我们删除。