
先从Github上下载YOLOv5,下载好解压配置好就可以使用,地址:
https://github.com/ultralytics/yolov5

1.训练数据集的准备工作
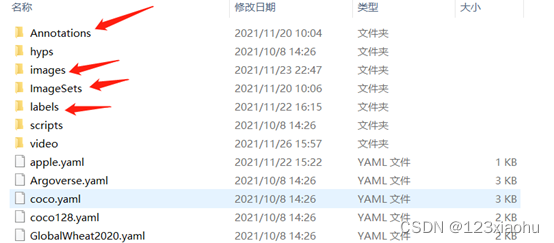
在yolov5 目录的data文件夹下新建四个文件夹,先说明这四个文件夹分别是用来干什么的,后面会往里面一一加入需要添加的内容。
Annotations文件夹:用来存放使用labelimg给每张图片标注后的xml文件,后面会讲解如何使用labelimg进行标注。
Images文件夹:用来存放原始的需要训练的数据集图片,图片格式为jpg格式。
ImageSets文件夹:用来存放将数据集划分后的用于训练、验证、测试的文件。
Labels文件夹:用来存放将xml格式的标注文件转换后的txt格式的标注文件。
2.准备数据集
我做的是关于苹果成熟度的检测,将苹果根据成熟度划分为3类:高成熟度 High_Ripeness,中成熟度 Medium_Ripeness,低成熟度 Low_Ripeness。下图为数据集的一部分,共准备了60张原始图片,高中低成熟度的图片各有20张,图片都是从百度上一一下载的。此处会用到一个非常高效的重命名方式,就不用一张一张图片的进行重命名。批量重命名的代码如下。60张图片准备好后就放在images文件夹中即可。

import os
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = 'E:\GitHub\yolov5-master\yolov5-master\data\images\新建文件夹' #表示需要命名处理的文件夹
self.new_path='E:\GitHub\yolov5-master\yolov5-master\data\images\新建文件夹'
def rename(self):
filelist = os.listdir(self.path) #获取文件夹中文件的所有的文件
total_num = len(filelist) #获取文件长度(个数)
i = 1 #表示文件的命名是从1开始的
for item in filelist:
if 1: #初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(self.path), item) #连接两个或更多的路径名组件
# dst = os.path.join(os.path.abspath(self.new_path), ''+str(i) + '.jpg')#处理后的格式也为jpg格式的,当然这里可以改成png格式
dst = os.path.join(os.path.abspath(self.path), 'Low Ripeness0000' + format(str(i), '0>3s') + '.jpg') #这种情况下的命名格式为0000000.jpg形式,可以自主定义想要的格式
try:
os.rename(src, dst) #src – 要修改的目录名 dst – 修改后的目录名
print('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()
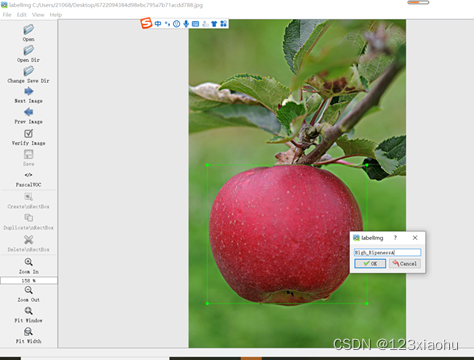
3.使用labelimg进行标注
Labelimg是一个图像标注工具,软件使用非常简单,下载解压后在data文件夹下有一个predefined_classes文件,在里面提前写好要训练的类型,后面标注的效率会快很多。

(1)Open就是打开图片,我们不需要一张一张的打开,太麻烦了,使用下面的Open Dir
(2)Open Dir就是打开需要标注的图片的文件夹,这里就选择images文件夹
(3)change save dir就是标注后保存标记文件的位置,选择需要保存标注信息的文件夹,这里就选择Annotations文件夹
(4)特别注意需要选择好所需要的标注文件的类型。有yolo(txt), pascalVOC (xml)两种类型。yolov5需要txt文件格式的标注文件,但是这里我们选择pascalVOC,后面再将xml格式的标注文件转化为所需的txt格式(黑人问号脸)。

(5)按W键或点击Create\nRectBox开始创建矩形框,把要进行识别训练的区域标记出来就行,选好框后我们选是什么类别(predefined_classes文件,在里面提前写好要训练的类型的原因),整张图片的所有目标都标记好了之后按Ctrl+S或点击Save保存 ,然后切换下一张继续,快捷键为按D键,每一张图片标记后都要保存,这个过程是一个比较繁琐的过程
4.数据集的划分
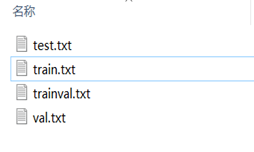
在yolov5的根目录下创建一个脚本,创建一个split_train_val.py文件,运行文件之后会在imageSets文件夹下将数据集划分为训练集、验证集、测试集,里面存放的就是用于训练、验证、测试的图片名称。代码内容如下:

import os
import random
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
5.转换数据集格式
创建voc_label.py文件,他的作用:(1)就是把Annoctions里面的xml格式的标注文件转换为txt格式的标注文件,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height。格式如下:

(2)就是运行后除了会生成转换后labels文件夹下的60张图片的txt文件,还会在data文件夹下得到三个包含数据集路径的txt文件,train.tx,tes.txt,val.txt这3个txt文件为划分后图像所在位置的绝对路径,如train.txt就含有所有训练集图像的绝对路径。


import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ['High Ripeness','Low Ripeness','Medium Ripeness']
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + 'data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
6.配置文件(恭喜来到最后一步啦,马上就要成功啦)
(1)数据集方面的yaml文件修改。
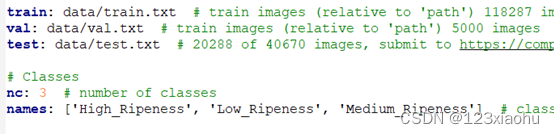
在yolov5目录下的data文件夹下新建一个apple.yaml文件,用来存放训练集、验证集、测试集的划分文件,目标的类别数目和具体类别列表。
(2)网络参数方面的yaml文件修改
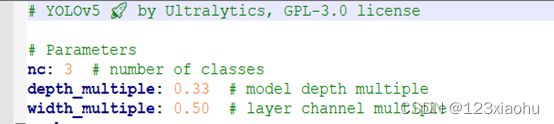
接着在models目录下的yolov5s.yaml文件进行修改,这里取决于你使用了哪个模型就去修改对于的文件,该项目中使用的是yolov5s模型。需要修改的参数仅有一个,就是具体类别的数目:
(3)train.py****中的参数修改
最后,在根目录中对train.py中的一些参数进行修改,加载的权重文件即yolov5s.pt文件,模型配置文件即修改好的yolov5s.yaml文件,数据集配置文件即第一个apple.yaml文件

7.准备工作全部完成,开始训练
全部配置好后,直接执行train.py文件开始训练
8.训练完成后,实现检测
训练结束,用训练好的权重文件之后,就可以就行目标检测试了。在根目录的detect.py中进行修改
参数,主要用到的只有这几个参数而已:–weights,–source。
选用训练的权重,用runs/train/exp/weights/best.pt,达到了预期的检测效果。
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / r'runs\train\exp14\weights\best.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT /'data/video/detection_video_Trim_1.mp4', help='file/dir/URL/glob, 0 for webcam')
版权归原作者 123xiaohu 所有, 如有侵权,请联系我们删除。