
MySQL是一个流行的开源关系型数据库管理系统,被广泛应用于各种Web应用程序和企业级应用系统中。为了更好地理解和使用MySQL,我们需要了解其逻辑架构。 MySQL的逻辑架构整体可以分为:连接层、服务处、存储引擎层、数据存储层。它整体的逻辑架构大致如下:
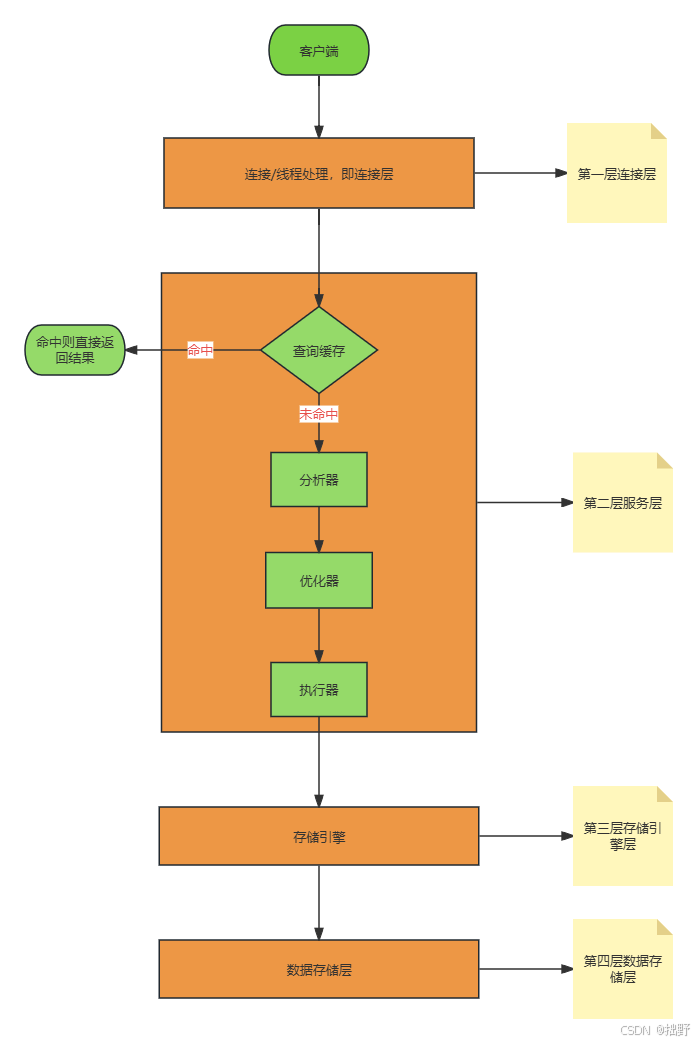
它更详情,更经典的逻辑架构图如下:

这张逻辑架构图,可以说非常经典的一个了,相信不少同学看到这张架构图,会有种似曾相识的感觉。以下我们就结合这张经典的逻辑架构图来,针对每一层来具体的去展开去说。
一、连接层
在系统(客户端)与MySQL服务器进行交互之前,首要任务是建立TCP连接。这一过程始于TCP的三次握手机制,确保连接的成功建立。一旦连接建立,MySQL服务器随即对传输过来的账号密码执行身份认证,并授予相应权限。若用户名或密码错误,将收到“Access denied for user”的错误提示,并导致客户端程序停止运行。反之,如果用户名和密码通过验证,服务器会从权限表中检索该账号关联的权限,并将这些权限与当前连接绑定。这意味着后续的所有权限检验都将基于此时获取的权限数据。当TCP连接接收到请求时,必须指派一个线程来专门管理与该客户端的互动。因此为了避免了频繁地创建和销毁线程所带来的资源开销,便引入了线程池的概念,用以优化后续流程,每个新的连接都会从线程池中分配一个线程。

二、服务层
1、SQL Interface:SQL接口
SQL接口是**MySQL数据库中用于处理、执行增删改查等SQL语句的一套组件**。在数据库管理系统中,SQL接口作为连接用户与数据库的纽带,承担着命令分发与结果反馈的关键角色。它不仅影响着数据的存取效率,还直接关系到整个系统的交互体验和运行性能。
2、Parser: 解析器
在数据库管理系统中,SQL解析器发挥着至关重要的作用。当一条SQL语句被发送到解析器时,解析器会对其进行语法分析和语义分析,将语句分解并转换成抽象语法树(AST)这一数据结构。这个过程是后续步骤的基础,也就是说,后续的SQL语句处理和传递都是基于这个由解析器生成的数据结构。解析器主要就是做如下几点 :
- 是否存在任何错误或不符合语法规则的情况,如果存在,解析器会判定该SQL语句不合理,并直接中断后续处理,抛出异常。例如,我们常见到的错误:You have an error in your SQL syntax。这其实也就是语法分析。
- 检查表名和列名是否存在、数据类型是否匹配、用户是否具有查询或其他操作的权限等。如果该检查未通过也是会中断后续处理,并抛出异常。这其实也就是语义分析。
3、Optimizer: 查询优化器
查询优化器在语法解析之后和查询执行之前起作用,负责为SQL语句确定最优的执行路径。查询优化器的核心功能是**生成一个高效的执行计划,这个计划指导数据库如何执行查询,包括选择合适的索引、确定表的连接顺序等,以确保查询能够快速且高效地完成。**执行计划是查询优化器输出的结果,它明确了查询执行的具体策略,如是否使用索引进行检索或者需要进行全表扫描,以及多表查询时的连接顺序等。这些决定基于数据库当前的统计数据和结构信息,旨在最小化查询的执行时间和资源消耗。
这里让我想到一个在面试中比较常问的问题,就是:**当你在通过索引进行查询的时候,返回的记录数超过总记录数的70%的时候,这个时候索引会失效吗?**
这个面试题其实就是考量你对MySQL的优化器是否了解。正常在没有优化器的情况下,这个答案肯定是索引不会失效。但是,在有优化器的情况下就不一定了。为什么说不一定,就是因为这个问题其实是有坑的。因为他并没有说他的查询条件是什么。如果查询的条件是主键索引,那么索引不会失效。如果非主键索引则会失效。
**那么为什么查询条件是主键索引的话不会失效呢?**
** **主键索引实质上也就是聚集索引,而聚集索引的独特之处在于,其将所有数据行存储在叶子节点上。因此,通过主键索引进行的查询能够直接获取到所需的所有字段信息,无需进行额外的回表操作。正因为此,当你在根据聚集索引查询的数据记录较多的时候,查询优化器依然会在索引与全表扫描之间选择使用索引。

** 那么为什么查询条件是非主键索引的话就会失效呢?**
** **非主键索引,也就是非聚集索引,其叶子节点并不储存整行数据。通常,基于非聚集索引执行查询时,往往需要进行回表操作以获取完整数据行。然而,当使用该索引进行大量数据查询时,比如该面试题中当查询的数据量占到总记录数的70%以上,Mysql的优化器会判断此时进行全表扫描较使用索引更为高效。因此,在这种情况下,即使存在索引,优化器也可能选择忽略它,导致索引失效。例如,在根据“告警等级”(该字段已建立索引)进行查询时,如果告警等级为3的记录数超过总记录数的70%,则观察到索引并未被使用,这就是索引失效的一个例子。

**实际上,当通过非聚集索引查询的数据量约占总记录数的20%时,优化器可能会认为不使用索引更为高效。**
** **其实,这个面试题还有一个坑就是,他并没有说当前表使用的存储引擎,而以上我们说的其实都是有一个前提条件的,那就是当前使用的存储引擎是InnoDB。而当我们使用的存储引擎是MyISAM的时候,上述结果就是恰恰相反的。感兴趣的兄弟可以自己试试,具体什么原因大家也可以评论区一起讨论一下。
4、Caches & Buffers: 查询缓存组件
MySQL内部维护了一系列的Cache和Buffer,其中Query Cache用于存储SELECT语句的执行结果。当相同的查询再次执行时,如果Query Cache中存在对应的查询结果,那么系统将无需再次进行查询解析、优化和执行的过程,而是直接将结果返回给客户端。这个缓存机制由多个小缓存组成,包括表缓存、记录缓存、key缓存和权限缓存等。这些缓存可以在不同客户端之间共享,从而提高了查询性能。然而,从MySQL 5.7.20版本开始,官方不再推荐使用查询缓存,并在MySQL 8.0版本中将其移除。这是因为查询缓存在某些情况下可能导致性能下降,而且现代的数据库优化技术已经足够成熟,可以提供更好的性能提升。并且在实际使用中,缓存的命中率并不高。
三、引擎层
在MySQL中,数据的存储和提取实际上是由插件式存储引擎层(Storage Engines)负责处理的。这些存储引擎与物理服务器进行交互,执行底层数据的操作,并通过API与服务器进行通信。不同的存储引擎具有不同的功能特性,使得我们能够根据实际的应用需求选择合适的存储引擎。
以下是Mysql5.7.26支持的存储引擎,可以看出InnoDB存储引擎是默认的存储引擎,也是唯一支持事务的存储引擎。

四、存储层
在MySQL中,所有数据、数据库和表的定义、表中的每一行内容以及索引都是以文件的形式存储在文件系统上,并通过文件系统与存储引擎进行交互。某些存储引擎如InnoDB支持不使用文件系统而直接管理裸设备,但随着现代文件系统技术的成熟,这种做法已不再必要。在文件系统之下,可以选择使用本地磁盘或各种存储系统。
本文转载自: https://blog.csdn.net/weixin_50348837/article/details/140390005
版权归原作者 拙野 所有, 如有侵权,请联系我们删除。
版权归原作者 拙野 所有, 如有侵权,请联系我们删除。