
大家好,我是 Jack。
因 ChatGPT、Stable Diffusion 让 AI 在文本、图像生成领域火出了圈。
但 AI 在生成方面的能力,可不仅如此,音频领域也出现了很多优秀的项目。
我用我本人的音频数据,训练了一个 AI 模型,生成了几段歌曲,效果已经在我最新一期的视频中展示了,感兴趣的可以看下:
https://www.bilibili.com/video/BV1x24y147yq
视频、教程制作不易,跪求三连支持,一个免费的赞也行~
勿用技术做恶
勿用技术做恶,必须放在第一个来说。
请勿用该技术从事诈骗等违法行为,请遵守《互联网信息服务深度合成管理规定》等法律法规。
本教程仅供交流学习使用,同时,本人也不提供任何人的训练好的音频模型。
准备工作
视频里所使用的技术是 so-vits-svc,是音频转音频,属于音色转换算法,支持正常的说话,也支持歌声的音色转换。
项目不提供任何人的音频训练模型,所以想要体验,必须先自己训练模型。
显卡建议使用 N 卡,且显存 8G 以上,我的显卡是 RTX 2060 S,训练自己的模型大概用了 14 个小时。
训练数据很关键,需要准备至少 1 个小时的音频,越多高质量的音频数据,效果越好。
比如我的本次训练,就是使用了我往期视频的音频数据,数据时长 1 个小时。
我家里的电脑是 Windows,所以本教程以 Windows 为例进行讲解。
我将项目所需要的代码、环境、工具,进行了打包,可以一键运行:
下载地址(网盘提取码:qi2p):
https://pan.baidu.com/s/1Jm-p_DZ2IVcNkkOYVULerg?pwd=qi2p
当然,也可以直接用作者开源的代码直接部署:
https://github.com/StarStringStudio/so-vits-svc
本项目不支持文本转音频,如果需要文本转音频,可以移步看看这个:
https://github.com/jaywalnut310/vits
准备干声数据
训练数据、还有预测推理的数据,都必须是人物的干声。
也就是说,不能包括背景音、伴奏、合声等,所以无论是训练和预测,都需要对数据进行处理。
这里用到的工具是 UVR5,我提供的整合包里包含了这个工具。
在 Windows 下可以直接使用,打开软件,按照如下配置:
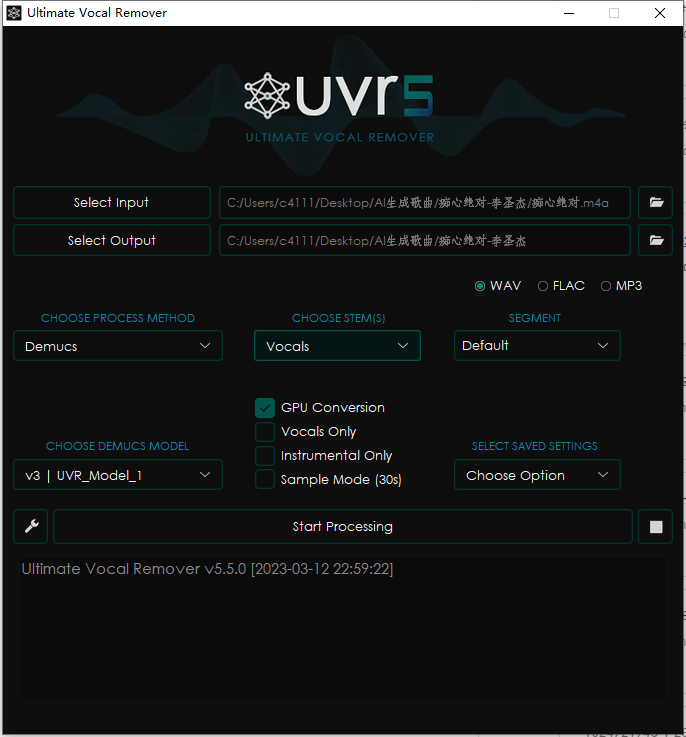
运行即可分离人声和伴奏:

然后再按照如下配置,去除合声:
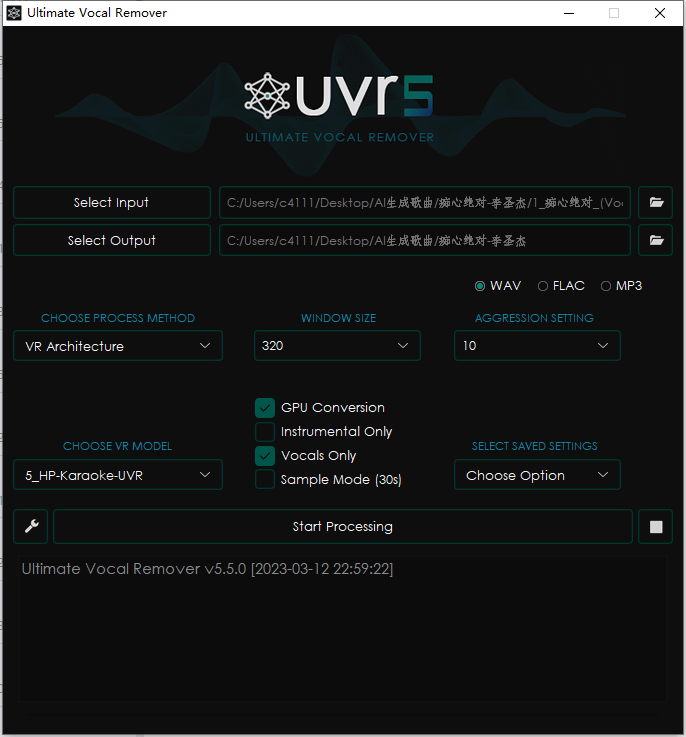
有 Vocals_Vocals 后缀的音频就是处理后的,这个音频就可以用来训练。

不过因为音频太长,很容易爆显存,可以对音频文件进行切片,这个整合包里也提供了饮品切分工具 Audio Slicer,直接运行 slicer-gui.exe。
填写输入路径,填写输出路径,其它参数都默认即可,这样你就会得到切分好的音频段。
在项目的 so-vits-svc-4.0/dataset_raw 目录下创建一个文件夹,比如我的是 jackcui_processed,将处理好的数据放到里面:
这样数据的准备工作,手动配置的部分就完成了。
训练模型
数据预处理
接下来可以直接运行我提供的整合包里的脚本 1、数据预处理.bat。
这个脚本就是按照步骤,运行各个 py 脚本:
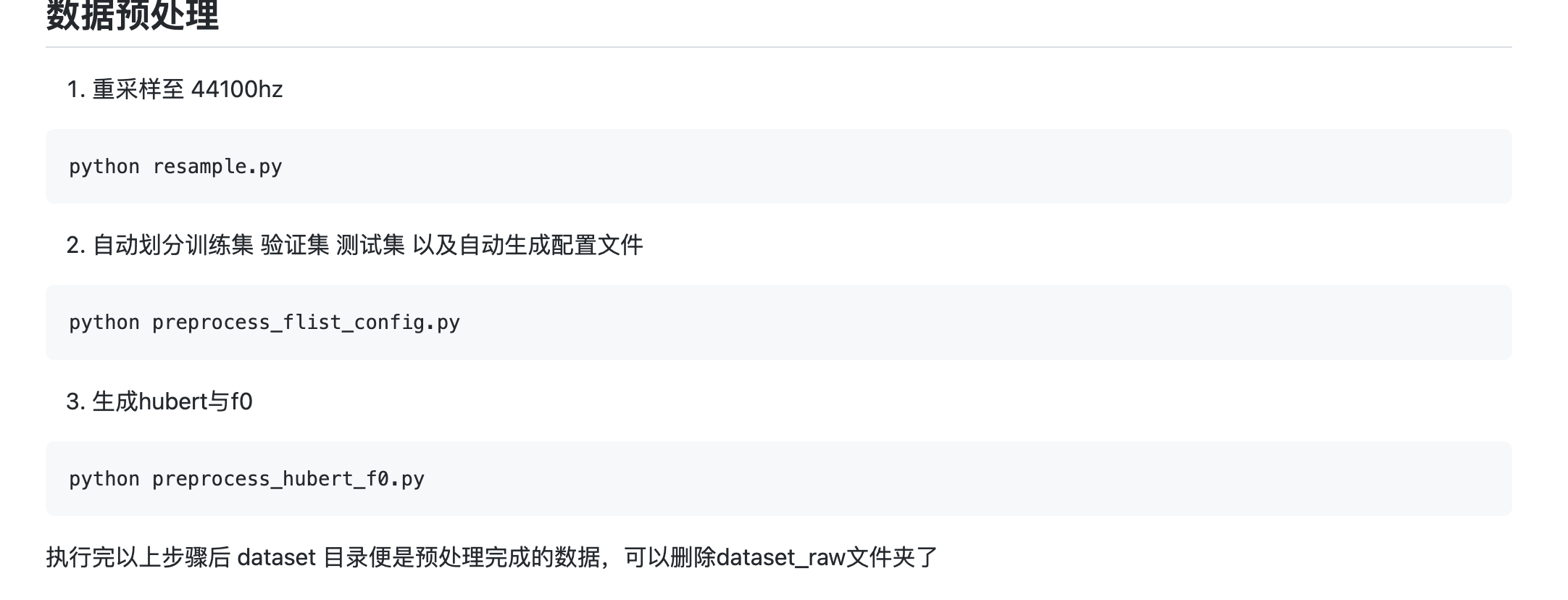
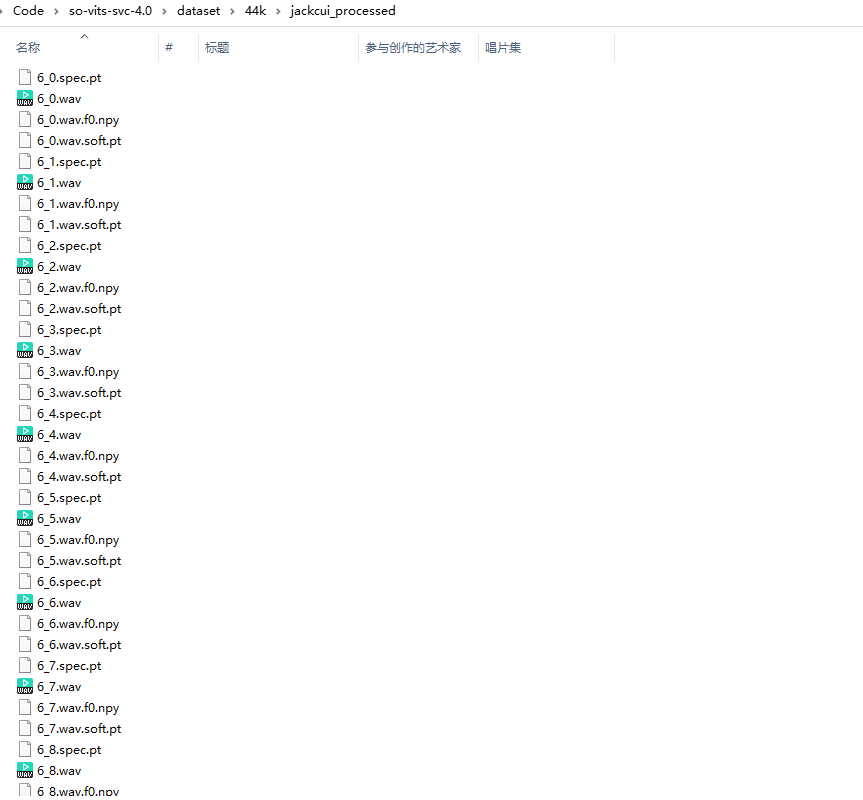
大约跑个几分钟,就能处理完成,处理完毕后,会在 datset/44k 下生成一个文件夹,里面的数据如下图所示:
模型训练
直接运行 2、训练.bat 即可开启训练。
如果你的显卡够好,可以增加 batch_size 提高训练速度,对应的配置文件在 configs/config.json 文件里。
这个训练时间很长,大概需要几个小时的时间。
推理预测
推理预测同理,新运行 3、训练聚类模型.bat 生成数据 pt 文件。几分钟即可跑完。
然后修改 app.py 里的这一行:
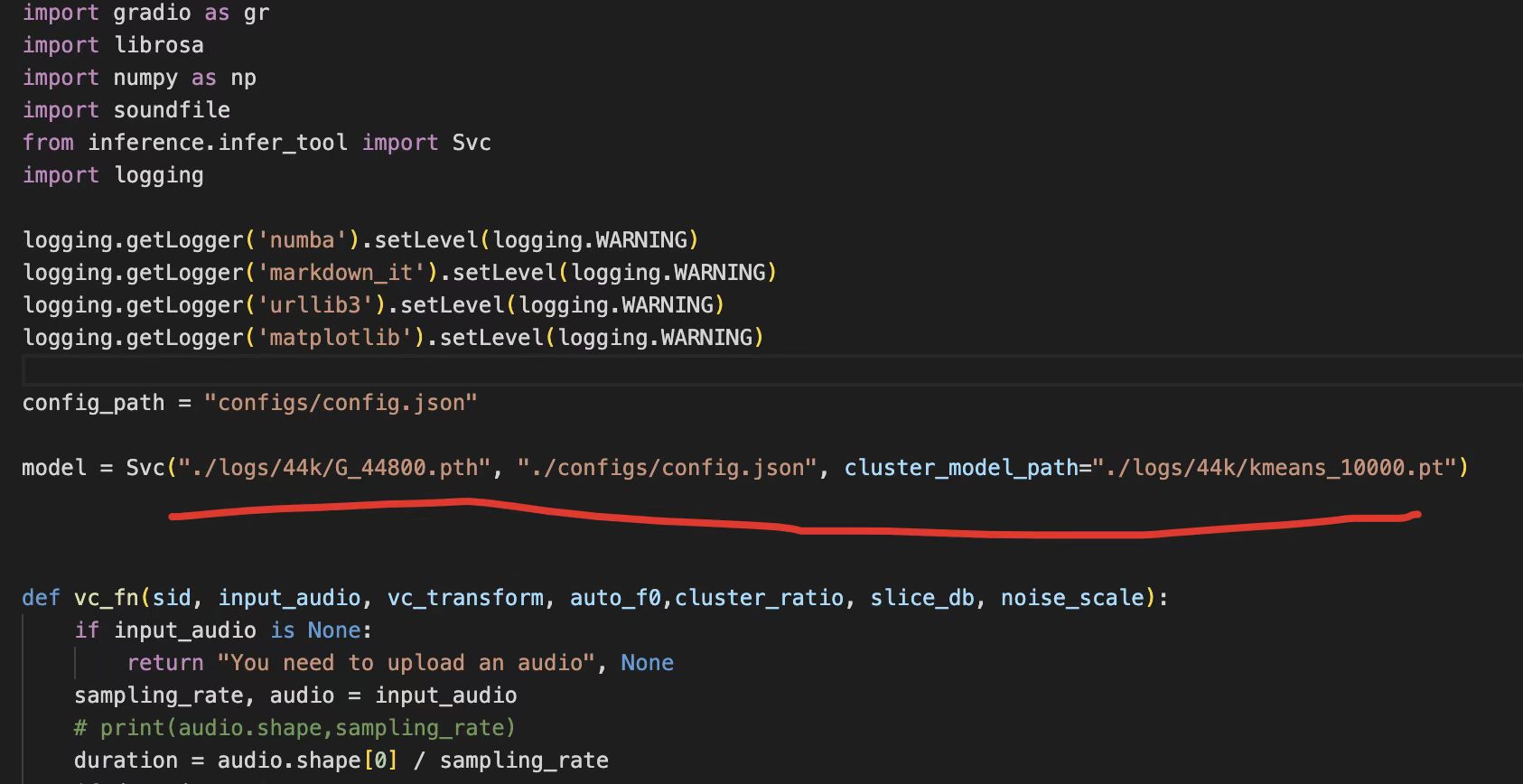
训练好的模型存放在了 logs/44k 目录下,这里改为你训练好的模型地址,以及对应的配置文件,最后是第三步生成的 pt 文件路径。
记住这里 app.py 必须改好,否则第四步会报错。
最后运行 4、推理预测.bat 文件。
程序会直接开启一个 webui,将开启的 url,直接复制到浏览器地址栏中打开即可。
就是一个简单的 Web 页面,里面的参数,可以直接使用默认的,放入一个音频,即可转换音色,很简单,这里就不展示了。
确认流程都跑通后,可以试着调整一些参数,个人影响太大,主要还是看训练数据,也就是用软件分离的干声质量。
最后
最后也再强调一下,请勿用技术做恶!
我的训练数据,只用了往期视频的音频文件,数据丰富度很差,都是叙事的语调,缺少高低音的歌唱数据。
所以效果上,高低起伏的变化少了,听起来就是,全是技巧,莫得感情。
但是如果用于普通对话的音色转换,绝对是够用了。
视频结尾也展示了一个惊艳一些的效果,歌手的数据就丰富很多了,所以效果更好。
版权归原作者 Jack-Cui 所有, 如有侵权,请联系我们删除。