
Spark 基本架构及运行原理
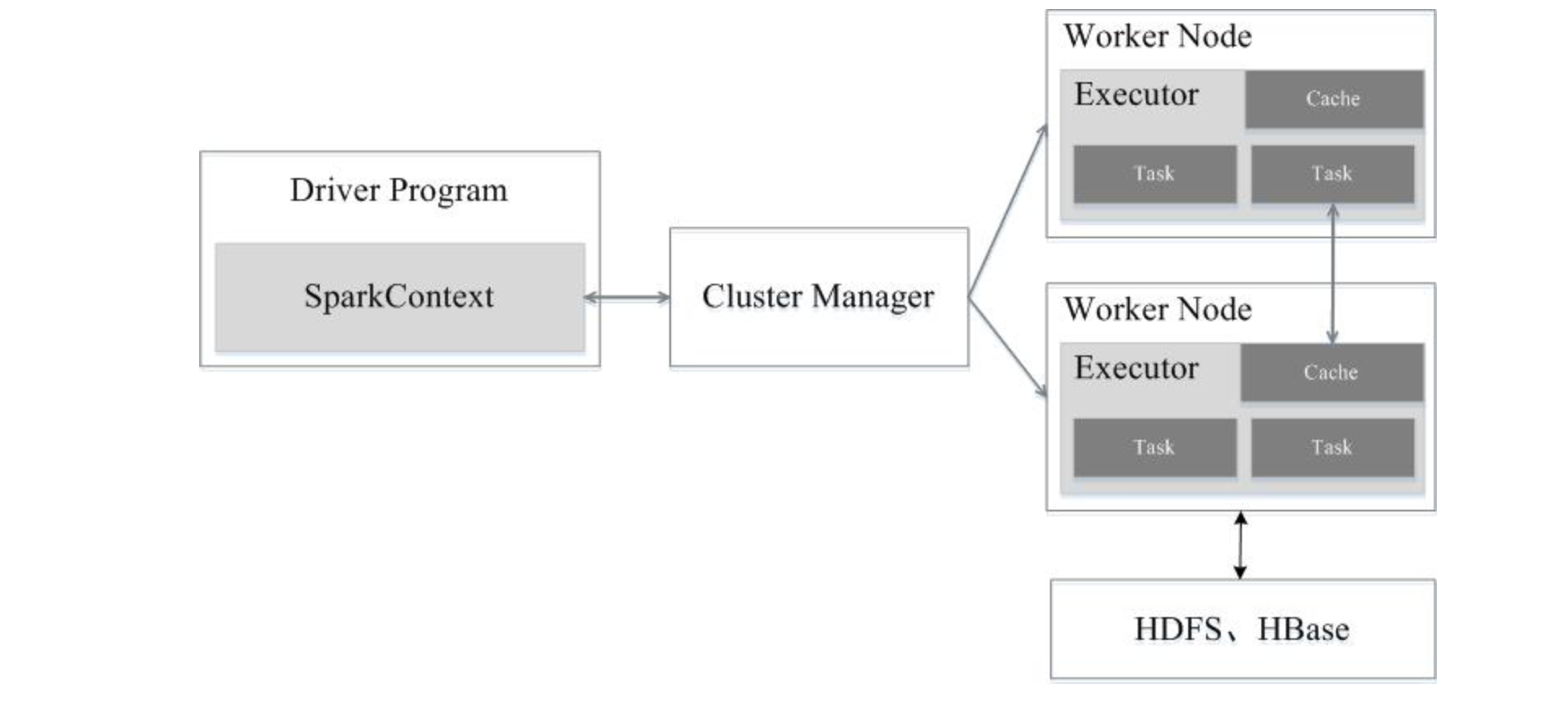
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:一是利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销;二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。
基本概念
Application
用户编写的Spark应用程序,包含了Driver Program以及在集群上运行的程序代码,物理机器上涉及了driver,master,worker三个节点。
Driver
Spark中的Driver即运行Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中由SparkContext负责与Cluster Manager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
Worker
集群中任何一个可以运行spark应用代码的节点。Worker就是物理节点,可以在上面启动Executor进程。
Executor
在每个Worker上为某应用启动的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor。Executor是一个执行Task的容器。它的主要职责是:
- 初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。
- 向cluster manager汇报当前的任务状态。
Executor是一个应用程序运行的监控和执行容器。
RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性
- 一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPUCore的数目。
- 一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
- RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
- 一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parentRDDShuffle输出时的分片数量。
- 一个列表,存储存取每个Partition的优先位置(preferredlocation)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
DAG
有向无环图,反映RDD之间的依赖关系。
Task
被发送到executor上的工作单元。每个Task负责计算一个分区的数据。
在Spark中有两类task:
shuffleMapTask
输出是shuffle所需数据,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。
resultTask
输出是计算结果,比如:
rdd.parallize(1 to 10).foreach(println)
这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个。
rdd.map(x=>(x,1)).reduceByKey(_+_).foreach(println)
上面这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage。
Job
一个Job包含多个RDD及作用于相应RDD上的各种操作,它包含很多task的并行计算,可以认为是SparkRDD里面的action,每个action的触发会生成一个job。用户提交的Job会提交给DAGScheduler,Job会被分解成Stage,Stage会被细化成Task,Task简单的说就是在一个数据partition上的单个数据处理流程。
Stage
是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为一个Stage就像MapStage,ReduceStage,或者也被称为TaskSet,代表一组关联的,相互之间没有Shuffle依赖关系的任务组成的任务集。
Partition
Partition类似hadoop的Split,计算是以partition为单位进行的,当然partition的划分依据有很多,这是可以自己定义的,像HDFS文件,划分的方式就和MapReduce一样,以文件的block来划分不同的partition。总而言之,Spark的partition在概念上与hadoop中的split是相似的,提供了一种划分数据的方式。
Block与Partition之间区别
hdfs中的block是分布式存储的最小单元,类似于盛放文件的盒子,一个文件可能要占多个盒子,但一个盒子里的内容只可能来自同一份文件。假设block设置为128M,你的文件是250M,那么这份文件占3个block(128+128+2)。这样的设计虽然会有一部分磁盘空间的浪费,但是整齐的block大小,便于快速找到、读取对应的内容。
注意:考虑到hdfs冗余设计,默认三份拷贝,实际上3*3=9个block的物理空间。
spark中的partition是弹性分布式数据集RDD的最小单元,RDD是由分布在各个节点上的partition组成的。partition是指的spark在计算过程中,生成的数据在计算空间内最小单元,同一份数据(RDD)的partition大小不一,数量不定,是根据application里的算子和最初读入的数据分块数量决定的,这也是为什么叫“弹性分布式”数据集的原因之一。
block位于存储空间、partition位于计算空间,block的大小是固定的、partition大小是不固定的,block是有冗余的、不会轻易丢失,partition(RDD)没有冗余设计、丢失之后重新计算得到。
Cluter Manager
指的是在集群上获取资源的外部服务。目前有三种类型:
- Standalon : spark原生的资源管理,由Master负责资源的分配。
- Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架。
- Hadoop Yarn: 主要是指Yarn中的Resource Manager。
在Yarn模式下,客户端程序会向Yarn申请计算我这个任务需要多少的memory,多少CPU等等。然后Cluster Manager会通过调度告诉客户端可以使用,客户端就可以把程序送到每个Worker上面去执行了。
一个Application由一个Driver和若干个Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成。
当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,执行结果会返回给Driver,或者写到HDFS或者其它数据库中。
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:
- 利用多线程来执行具体的任务减少任务的启动开销。
- Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销。
Spark运行基本流程
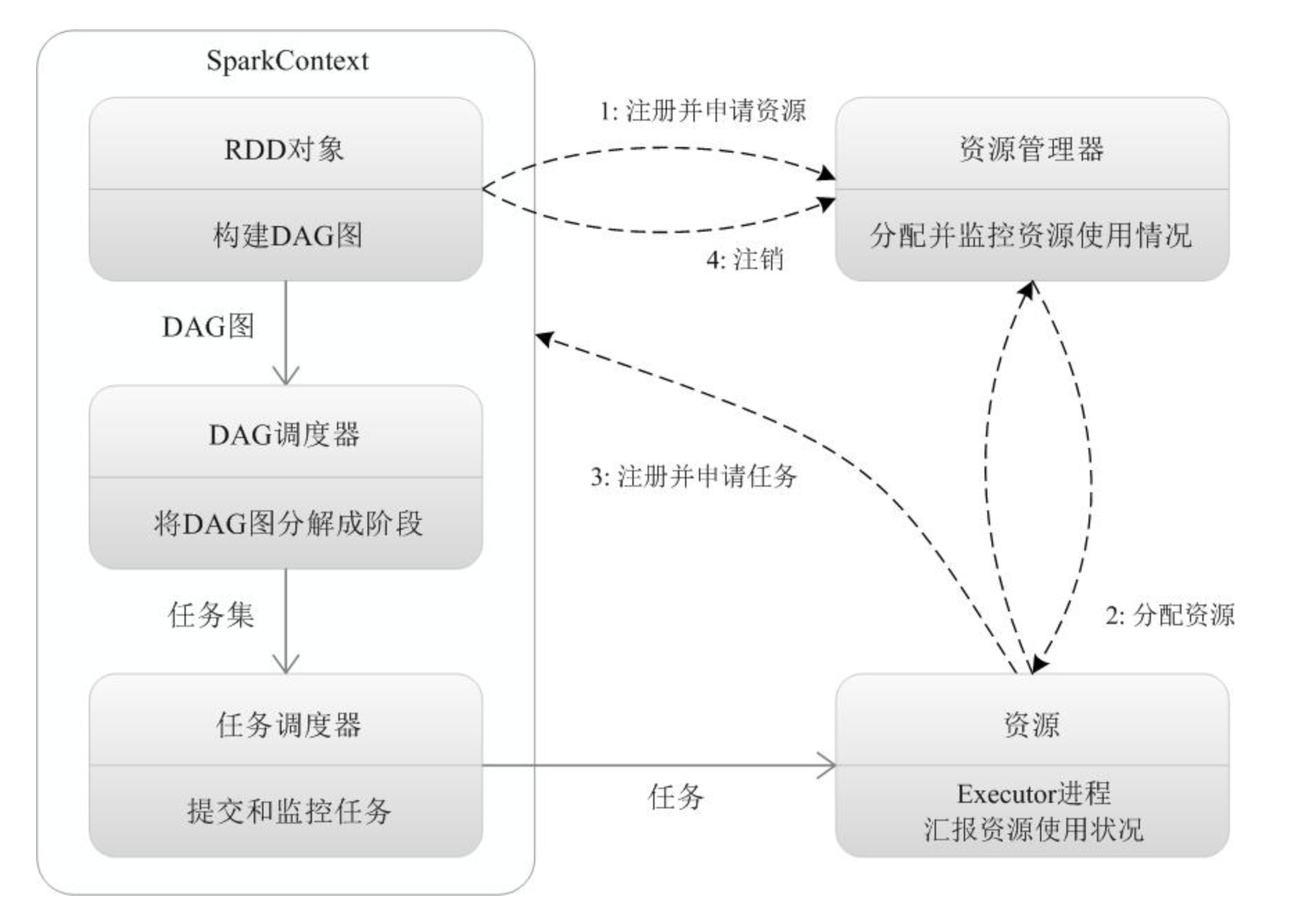
- 为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控。
- 资源管理器为Executor分配资源,并启动Executor进程
- SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理。
- Executor向SparkContext申请Task,TaskScheduler将Task发放给Executor运行并提供应用程序代码。
- Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
Spark运行架构特点
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
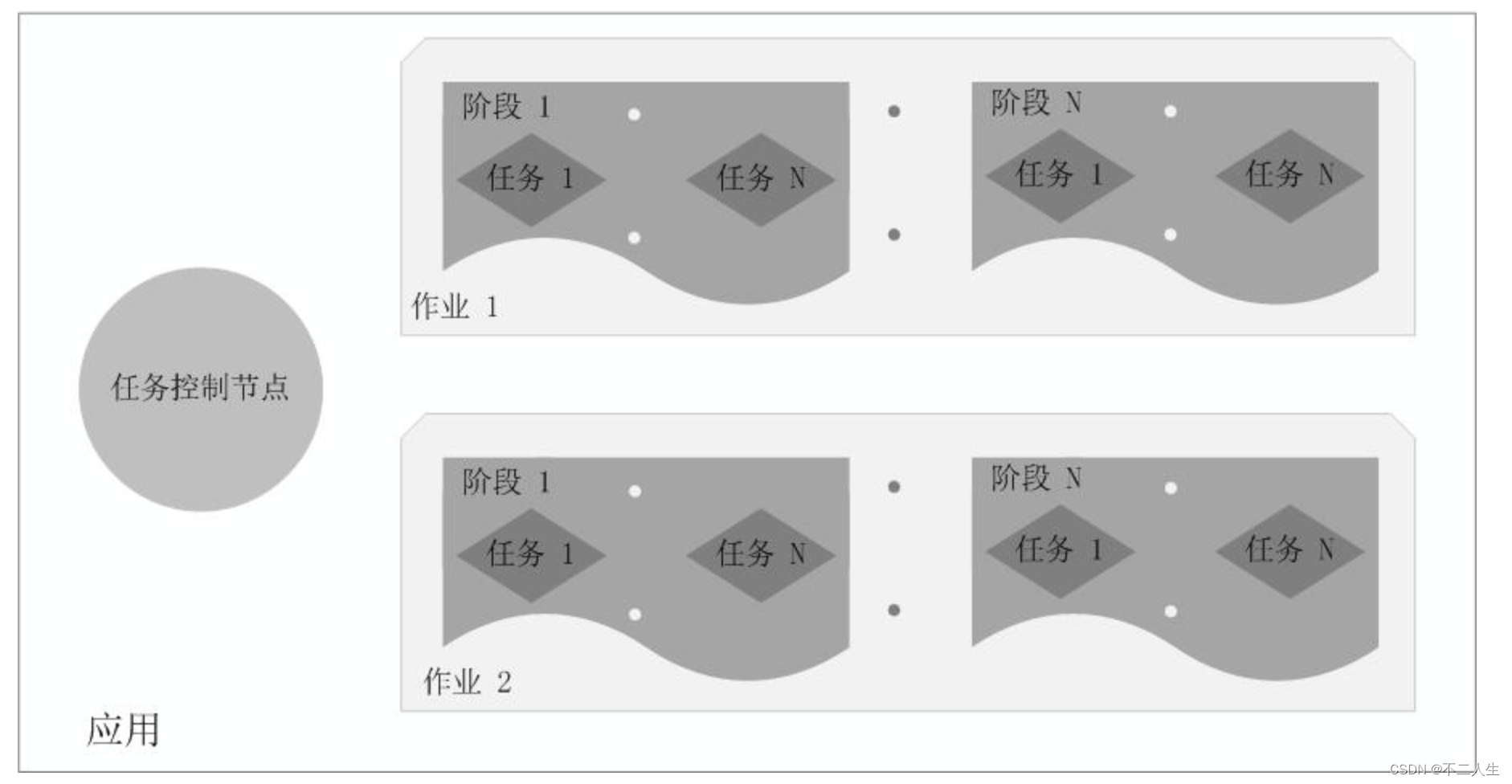
Spark结构的特点可以总结成下面3个。
- 每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task。
- Spark运行过程与资源管理器无关,只要能够获取Executor进程并保存通信即可。
- Task采用数据本地性和推测执行等优化机制。
版权归原作者 不二人生 所有, 如有侵权,请联系我们删除。