
在ChatGPT、无际Ai等生成式AI中,Tokens是一个重要的概念,它被用于将输入序列切分成一个个的单元,以便于模型进行处理。本文我将详细给大家介绍什么是Tokens以及如何计算Tokens的数量。

首先,我们来了解一下什么是****Tokens:
在自然语言处理领域中,机器学习模型通常以Token作为其输入单位。Token可以被理解为文本中的最小单位,在文本处理中,Token可以是一个词语、数字、标点符号、单个字母或任何可以成为文本分析的单个元素。
在GPT模型中,首先会对输入的文本进行预处理,将其切分成Tokens。这些Tokens会被输入到模型中,经过一系列的Transformer层处理后,最终生成回复。
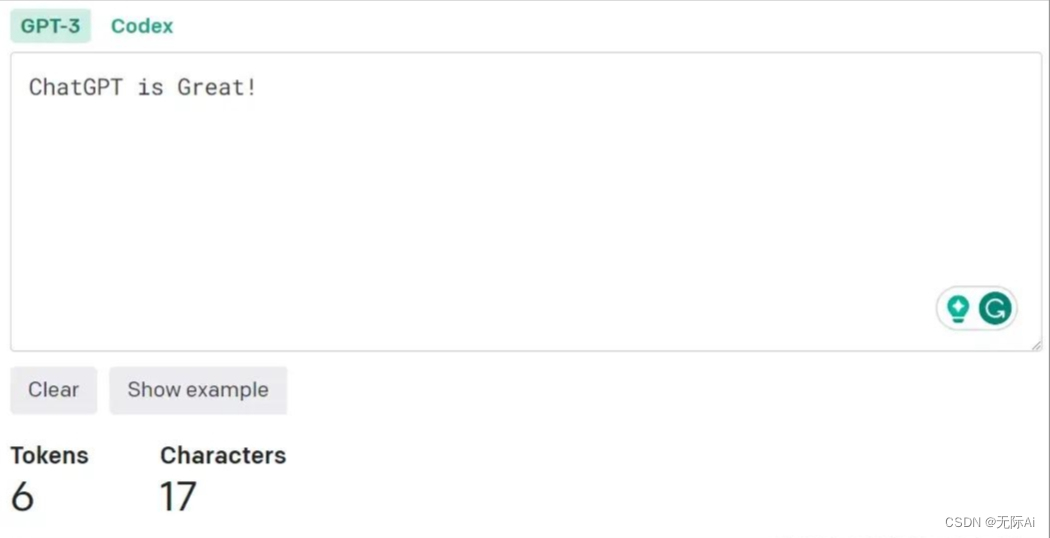
那么,在GPT中如何计算Tokens的数量呢?
首先,我们需要明确的是,Tokens的数量与输入文本的长度有关。一般来说,输入文本越长,切分出来的Tokens数量就越多。在GPT中,计算Tokens数量的方法如下:
1.首先,对输入序列进行预处理。预处理的过程包括将文本转换为小写、去除标点符号、去除特殊字符等操作。
2.然后,使用空格将预处理后的文本切分成一个个的单词。这些单词被称为词元(wordpieces)。词元的选择是根据一种称为WordPiece的算法进行的。该算法将最常用的单词切分成更小的子词,以便于模型更好地处理不同的单词形式。
3.最后,将每个词元标记为一个独立的Tokens。例如,对于输入文本“Hello, world!”,经过预处理和词元切分后,会得到如下的Tokens标记:“hello , world !”。
在GPT中,不同的输入文本可能会被切分成不同数量的Tokens。这是因为不同的文本可能需要使用不同的词元切分方式来更好地处理不同的单词形式。因此,Tokens的数量是取决于具体的输入文本的。
需要注意的是,你请求的Token总数量是由你的问题和你请求的回复长度决定的。例如,你提问耗费了100Token,GPT根据你的输入,生成文本(也就是回答)了200Token,那么一共消费的 Token数就是300 。
总的来说,在GPT中,Tokens是用于将输入文本切分成一个个可处理的单元。它与输入文本的长度有关,并且需要根据具体的输入文本来计算。对于不同的自然语言处理任务,可能会采用不同的Tokens切分方法和计算方式。但是,在大多数情况下,Tokens的数量与输入文本的长度成正比。
以上内容由【无际Ai】整理发布,转载请注明出处。点关注,不迷路!未来将会持续更新AI人工智能方面的热点资讯和科普教程等内容~
版权归原作者 无际Ai 所有, 如有侵权,请联系我们删除。