
Cloud Removal in Optical Remote Sensing Imagery Using Multiscale Distortion-Aware Networks
Abstract
云层污染是光学遥感图像中常见的问题。基于深度学习的遥感图像去云技术近年来受到越来越多的关注。然而,由于缺乏对云失真效果的有效建模和网络较弱的特征表示能力,从云图像中开发有用的多尺度云感知表示仍然具有挑战性。为了规避这些挑战,我们提出了一个多尺度扭曲感知云移除(MSDA-CR)网络,该网络由多个云扭曲感知表示学习(CDARL)模块组合在一个多尺度网格架构中。具体来说,定义云畸变控制函数(CDCFs)并将其纳入CDARL模块中,以自适应地模拟成像过程中云干扰引起的畸变效应,并使用可学习的参数来利用畸变恢复表示。这些表征在MSDA-CR网络中进一步在不同尺度上进行提炼,并基于注意力机制进行整合,以恢复无云图像,同时保留地面物体的空间结构。在可见光和多光谱遥感数据集上的大量实验证实了所提出的MSDA-CR网络的有效性。
1 Introduction
随着对地观测技术的发展,遥感影像信息已广泛应用于土地覆盖测绘、自然资源监测、灾害响应等领域。然而,这种光学RS图像的质量可能受到大气和照明条件的强烈影响。特别是,被观测的地表可能部分甚至完全被云层遮蔽,这将严重影响后续的应用。因此,迫切需要开发有效的信号处理技术,从被云层污染的遥感影像中忠实地恢复真实的地表信息。
在文献中,RS图像云去除的方法一般有两类:
基于图像增强的方法
基于深度学习的方法
在以往的研究中,基于图像增强的方法因其易于解释和实现而被广泛用于去除云。这些方法主要是基于对被云覆盖的图像进行空间频率处理来实现去云。基于非云区域的像素在至少一个颜色通道中表现出低强度的原则,可以将暗通道先验(dark channel prior, DCP)集成到图像的低频分量中,以估计云的传输图,用于去云。Zhang等提出了一种基于群稀疏约束的主成分分析的从粗到精的框架,从低秩分量中恢复背景信息。然而,这些方法严重依赖于RS图像的手工特征和低秩假设。因此,他们的结果表明,对于被不同形式的云遮挡的RS图像,鲁棒性较低。 基于深度学习的去云方法由于具有较强的挖掘遥感图像代表性特征的能力而引起了大量的研究关注。具体来说,从污染图像中去除云可以看作是通过深度表示学习将像素从云退化域映射到无云域的任务。例如,Zi等人在U-Net架构中使用卷积神经网络(cnn)来估计每个光谱带的厚度系数,并为多云图像生成云厚度图。此外,基于cnn的模型已被嵌入到对抗学习框架中,以实现增强的特征表示能力,从而允许基于生成式对抗网络(GAN)的图像到图像翻译模型应用于云去除。例如,循环GAN和条件GAN模型采用了不同的训练策略,其中生成器旨在将云覆盖图像转换为无云图像,判别器学习从恢复图像中区分真实图像。此外,Zheng等人将U-Net、生成器和鉴别器结合在对抗学习框架下,在恢复不规则云覆盖区域的同时去除薄云。这种生成模型可以从受污染的图像中学习高级云感知特征表示,并从这些图像的编码表示中重建这些图像的无云内容。然而,他们无法通过深度表征学习网络对污染图像的多尺度云失真效应进行建模。尽管使用GAN模型使用云失真的物理模型从污染图像中分解云失真层,但其用于云提取的U-Net架构不能充分利用有用的多尺度云失真感知表示来处理不同厚度的云。 在这篇文章中,我们提出了一个多尺度失真感知云去除(MSDA-CR)网络,使用云失真感知表示学习(CDARL)模块作为基本编码块来恢复云覆盖下的地表。CDARL模块通过自定义云畸变控制函数(CDCFs)学习自适应地对云反射、云传输和全球大气亮度的影响进行建模,以便从云图中生成云畸变恢复的表示图。MSDA-CR模型采用网格结构逐步提取不同尺度的无云表示,并基于注意机制自适应集成这些多尺度表示。此外,利用Smooth L1损失、感知损失和对抗损失组成的新型混合损失函数来训练MSDA-CR模型。
2 Methodology
2.1 云畸变的物理模型
卫星传感器接收到的信号可能因云层畸变而严重衰减。Li等基于太阳辐射在成像过程中的传播,提出了云畸变的物理模型。对于云畸变图像x中的每个像素z,即传感器接收到的信号,云畸变的物理模型定义如下:

式中,I 为太阳辐照度,r(z)、t(z)、和s(z)分别为云反射率、云双向透过率和地表反射率。第一项即 表示云层反射的辐射,第二项即  表示地表通过云层透射的退化反射。因此,通过对成像过程中的云反射、云透射和太阳辐照度进行建模,得到地表无云信号,表示为,恢复地表信息。
2.2 云扭曲感知表征学习模型(Cloud-distortion-aware Representation Learning,CDARL)
如图1所示,CDARL模块设计用于对CDCFs建模,以学习扭曲感知表示。首先,将原始图像输入特征提取主干,提取深度特征;然后,设计了三个具有可学习参数的CDCFs来捕获深度表征学习中的云失真效果。最后,通过结合CDCFs来利用无云表示生成扭曲恢复的地图。
构造特征提取主干,利用两个由紧密连接的卷积层组成的并行分支从原始输入中提取特征。然后利用提取的特征X对CDCFs的参数进行建模。云畸变效应,即云干扰引起的信号衰减,对RS成像有不利影响。基于云畸变的物理模型,我们设计了三个具有可学习参数的CDCFs来模拟云畸变效应。
为了有效地捕捉云量的空间变化特征,同时保留地表局部空间结构,基于可学习尺度和偏差的空间自适应仿射变换,设计了云反射和云透射的CDCFs,如下:

其中和分别表示云反射和云透射对第i个通道中第z个像元的影响。,,, 是可学习的仿射参数。μ(·)和σ(·)分别为通道均值和标准差函数。
对于跨光学波段的图像,地表场景的照度可以认为是由太阳辐照度提供的,即全球大气亮度,它具有通道特性。因此,使用自适应信道仿射变换对全球大气亮度B进行编码,并在每个特征信道的空间维度上独立计算可学习参数,如下所示:

其中,和是函数的可学习仿射参数。压缩函数使用跨空间维度的全局平均池化将每个二维特征通道转换为实数。
最后,通过对CDCFs模型进行建模,生成一个扭曲恢复的表示图,以恢复无云扭曲的表示。根据2.1给出的云恢复公式,通过对R(z)、T(z)、B引起的信号衰减进行建模,可以从原始图像中提取出期望的地表信息Y(z),即成像过程中捕获的地表无云信号:

2.3 多尺度扭曲感知去云网络(Multi-scale Distortion-aware Cloud Removal,MSDA-CR)

图1 提出的MSDA-CR网络框架和CDARL模块结构。
以CDARL模块为基本编码块,通过密集连接建立MSDA-CR网络,目的是提取不同尺度的无云表示。如图1所示,MSDA-CR网络中的每一行对应一个不同的尺度,使用多个CDARL模块进行代表性特征挖掘,而列使用上采样/下采样块作为不同尺度之间的桥梁,以方便信息交换。获得的多尺度扭曲恢复图通过一个灵活的表示聚合注意机制进行融合,然后将其馈送到下一个连接模块进行表示蒸馏。为了提高网络的特征表示能力,通过引入鉴别器来区分生成的无云图像和真实图像,将MSDA-CR网络嵌入到对抗学习框架中。
针对第 j 个CDARL模块在第 l 层生成的失真恢复图,提出了一种基于Sigmoid激活函数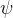的门控函数的通道注意力机制,强调信息性表征,抑制无关信息:

其中,为CDARL输出的注意权值,δ为整流线性单元(ReLU)激活函数。其中,, 为线性投影矩阵,其中 r 为降维比。在此基础上,通过扭曲恢复的地图与相应的注意权值之间的元素相乘,可以自适应地融合多尺度表示。因此,可以通过上采样或下采样后,将同一级别的一个模块和下一级别或更高级别的一个模块的输出融合产生CDARL模块的输入。
2.4 损失函数
引入一种新的混合损失函数,包括、感知损失和对抗损失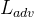,用于训练MSDA-CR模型。该混合损失函数定义如下:

其中、、为三个损耗分量的可调权值。
**Smooth L1 Loss **
Smooth L1 损失测量的是MSDA-CR网络输出图像与其对应的真地图像之间的像素差。这种损失的定义如下:

式中,N为图像中像素总数,Z为光谱带数,α(·)为Smooth L1 函数,和分别为真实图像和去云图像中第i通道像素Z的强度。
感知损失Perceptual Loss
感知损失度量来自MSDA-CR网络的预测特征表示与其相应的Groundtruth图像之间的一致性,该图像由预训练网络获得(例如,在ImageNet数据集上预训练的VGG19)。感知损失的定义如下:

其中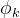为网络第k层提取的特征图,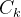、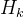、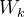分别为特征图的通道数、高度和宽度。
对抗性损失Adversarial Loss
使用鉴别器D来使用带有梯度惩罚的Wasserstein损失度量:

其中是真实数据x上的分布,是合成数据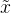上的分布。这里,前两项用于最小化和之间的Wasserstein距离,而最后一项强制Lipschitz约束以使对抗训练更稳定,而是梯度惩罚系数。
3 Experiment Results
3.1 数据描述
使用RICE和WHUS2-CR两个RS数据集来验证所提出方法的有效性。RICE数据集包含500张来自Google Earth的薄云层图像对和736张大小为512 × 512像素的Landsat-8 (RGB波段)厚云层图像对。其中875对作为训练数据,其余361对作为测试数据。此外,WHUS2-CR数据集包含2000对大小为512 × 512像素的多云和无云Sentinel-2图像。实验采用空间分辨率为10 m的Sentinel-2图像的可见光和近红外波段(NIR),即2/3/4/8波段,对多光谱图像的去云性能进行测试。
在WHUS2-CR数据集中,获得1500对作为训练样本,其余500对用于评价。
3.2 实验设置
将提出的MSDA-CR方法与其他最先进的云去除方法,即基于U-net的云去除(UCR),以及两种基于GAN的方法,即CloudGAN和CR-GAN-PM进行了比较。我们选择批大小为36的ADAM优化器来训练MSDA-CR网络,其中参数β1和β2分别设置为默认值0.9和0.999。学习率最初设置为0.0001,并且在每20个epoch后衰减一半。和分别设为0.04和0.05,以控制模型的训练稳定性,和分别设为经验值1.2和10。为了公平比较,所有其他方法都实现了最佳参数设置。为了定量评价各种方法的去云效果,采用峰值信噪比(PSNR)和结构相似指数度量(SSIM)来定量评价预测图像与真实图像的一致性。
3.3 结果与分析

图2 RICE数据集的定性比较:(a)云图,(b)地面真值,(c) UCR, (d) CloudGAN, (e) CR-GAN-PM, (f) MSDA-CR。
图2显示了RICE数据集上所有方法去除薄云和厚云结果的6个实例。可以看出,在多云区域,UCR产生的结果存在细节丢失和图像模糊的问题。因此,它不能成功地恢复云层覆盖区域的地表信息。在CloudGAN的结果中,由于对云厚度的估计不准确,在几个斑块中可以观察到大量的云残留物。CR-GAN-PM虽然保留了背景的大部分纹理信息,但在厚云恢复区域仍然存在颜色失真的噪声区域,干扰了生成图像的空间连续性。相比之下,本文提出的MSDA-CR能够获得更精细的背景空间信息,光谱与地面真实值的一致性更好。

图3 对WHUS2-CR数据集的定性比较:(a)云图,(b)地面真值,(c) UCR, (d) CloudGAN, (e) CR-GAN-PM, (f) MSDA-CR。第1、3、5行为真彩色合成图像结果,第2、4、6行为对应近红外波段结果。
图3为在WHUS2-CR数据集上获得的真彩色复合图像和近红外波段定性结果。对于多光谱图像中的厚云去除,UCR、CloudGAN和CR-GAN-PM不能很好地恢复被厚云覆盖的地物,在真彩色合成图像中存在严重的云残。由于近红外波段受云的影响比可见光波段小,因此生成的近红外图像对云畸变的敏感性较低。如图3(f)所示,MSDA-CR网络生成的无云图像在可行波段和近红外波段都显示出更多的背景细节恢复。

表1 不同云清除方法的定量比较,↑表示越高越好.
表1总结了MSDA-CR方法与其他考虑比较的方法的定量结果。所提出的MSDA-CR方法在PSNR和SSIM方面显著优于其他方法,证明了MSDA-CR网络对云去除的有效性。值得注意的是,在WUHS2-CR数据集上,UCR比CloudGAN获得更高的SSIM值,但更低的PSNR值。这一观察结果表明,CloudGAN产生的均方误差较小,代价是在亮度和结构方面与地面真实值的一致性较差。
四种方法的帧/秒(Frames per second, FPS)如表1所示。由于CloudGAN网络中采用了残差块和卷积运算,MSDA-CR的推理速度比CloudGAN更快。
3.4 消融实验
我们通过测试MSDA-CR模型的几种变体进行了消融研究。为了验证MSDA-CR方法中使用的cdcf和对抗损失Ladv的有效性,我们通过用密集连接的卷积层替换CDARL模块并消除对抗损失进行了比较。如表2所示,由于MSDA-CR模型的表示能力下降,消除Ladv只会导致性能略有下降,而没有cdcf的模型的性能明显下降。这是因为CDCFs可以有效地模拟表征学习中的云失真效果,从而更好地利用失真恢复表征。此外,没有CDCFs和Ladv的实验结果表明,PSNR和SSIM性能较差。这些结果表明,将所提出的CDCFs和对抗损失结合起来是非常有效的。
4 Conclusion
在这篇文章中,我们提出了一种新的MSDA-CR模型,用于光学RS图像的云去除。具体来说,CDCFs被定义并合并到每个CDARL块中,以模拟云反射、云传输和全球大气亮度的影响,同时促进利用失真恢复表示。利用基于注意力的多尺度网格网络,逐步提取和自适应集成不同尺度的无云表示。在高分辨率可见光RS图像和多光谱数据集上进行的实验表明,与最先进的方法相比,所提出的MSDA-CR模型在薄云和厚云去除方面取得了令人印象深刻的性能。具体而言,MSDA-CR模型可以在保留图像局部空间结构的同时恢复光谱一致的地表信息。
本文转载自: https://blog.csdn.net/iazzz/article/details/140893754
版权归原作者 IAz- 所有, 如有侵权,请联系我们删除。
版权归原作者 IAz- 所有, 如有侵权,请联系我们删除。