
- 首先讲一下下本文解决痛点,感谢叮叮当当博主提供解决思路
- 当然我知道肯定存在更快更好的方法,如果社区同学有相应解决方案,希望可以在本文后面不吝赐教,提供下具体思路,不胜感激
- 如果有幸官方大大看到博文,觉得能入眼,不知是否有奖励一块20T板供后续学习的机会

- 接着介绍下设备,使用的是香橙派12T + 1.6GHZ + 8.0.RC2.alpha003
- 镜像烧录在 m.2 nvme PM981A固态中,如何选择固态可见我之前博文
- 由于海鲜市场购买,没购置铁盒,所以二次改装,露出固态以加强散热
- 经测试在持续视频推理中,发热量还是比较大的,到烫级别

- 由于固态如果从海鲜市场淘的,多少是会带有类似EFI System的, 要考虑格式化
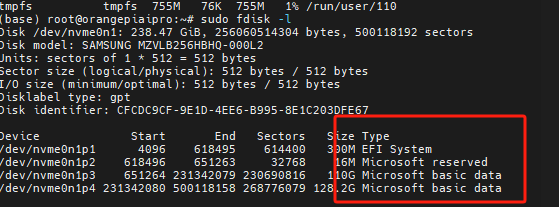
- 官方工具应该会自动格式化整盘,所以不再手动格式化
- 使用官方提供方式,界面烧录镜像,当前最新镜像自带的CANN版本是7.0
- 所以要升级CANN版本到最新
- 官网开发资源中点击资源下载中心
- 保证全为空,再进入下载最新版本的CANN
- 更新CANN 使用./Ascend-cann-toolkit_8.0.RC2.alpha003_linux-aarch64.run --upgrade --quiet 命令
- 具体的就不再阐释,看CANN的官方文档有更新一项
- 下载完CANN还没完,抱歉,这才是刚开始
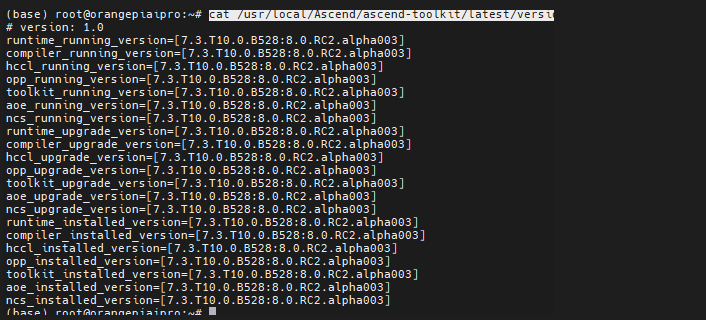
- 我们 cat /usr/local/Ascend/ascend-toolkit/latest/version.cfg
- 会发现适配驱动要求是7.3.T10.0.B528 ,这是超频1.6GHZ和12T的 firmware安装版本
- 有人会问不安装行不行,答案是不行,因为不安装 acl 等细操都运行报错
- 所以还需要升级firmware, 此处省略安装,具体过程在香橙派下载的官方工具中
搞完了这一步,终于可以进入正题,这次我优化的方式是使用aipp+nms后处理融合后的Om模型
那么我们需要借鉴 Ascend EdgeAndRobotics 中的 YOLOV5Video 案例 ,在gitee Ascend仓库可以找到
由于使用的是ACLLite 进行 编程 ,所以我们要下载ACLLite,也在gitee Ascend仓库
这里切记一定要完成ACLLite python 文件夹的搬迁,作为CANN的 thirdpart, 否则会报出缺文件的错误
具体安装按照 两个Md 去操作,我就贴出几个会让我们抓狂的注意事项
安装ACLLite 环境时 按照官方指示先安装cython,再安装av==6.2.0
但是会报出无法安装av这个版本的错误 因为两个库有版本依赖关系
你只要安装cython==0.29.37 就可以解决这个问题
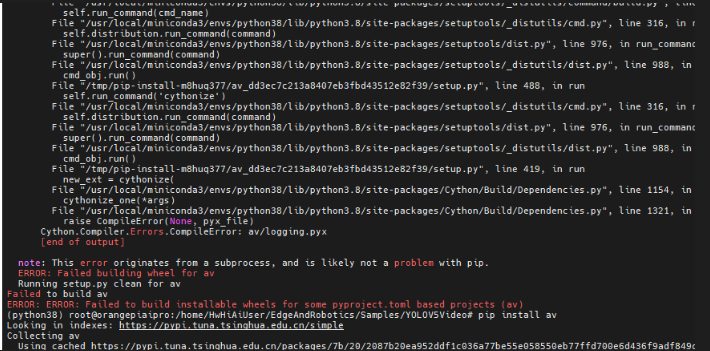
- 在工程代码中 需要 import videocapture as video
- videocapture 并不是 python 库文件,而是ACLLite 工程中python 中以 av库 为基础编写的文件
- 这里一定要注意,别一直在解决Pip install videocapture的问题
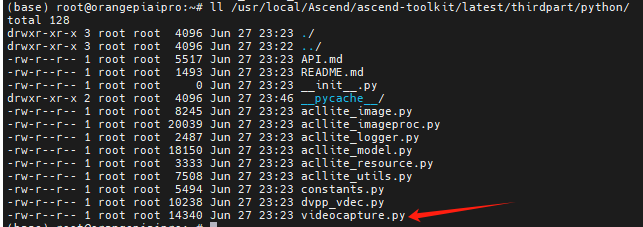
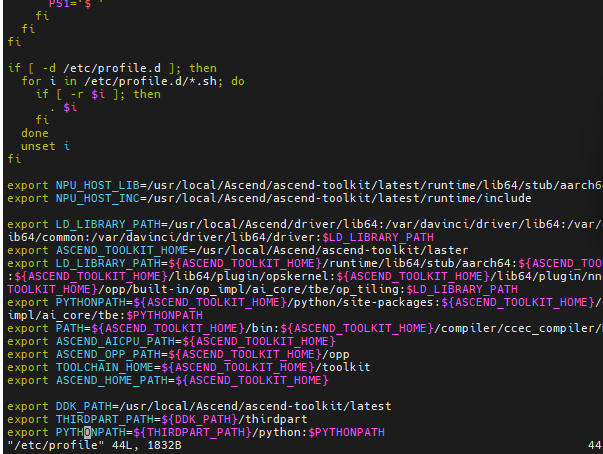
- 另外所有环境变量,也就是md中提及要export的变量,需要放在/etc/profile 中,并且要source /etc/profile 生效
- 否则MobaXterm 多窗口关闭或者重新登录,你会发现环境修改并未生效
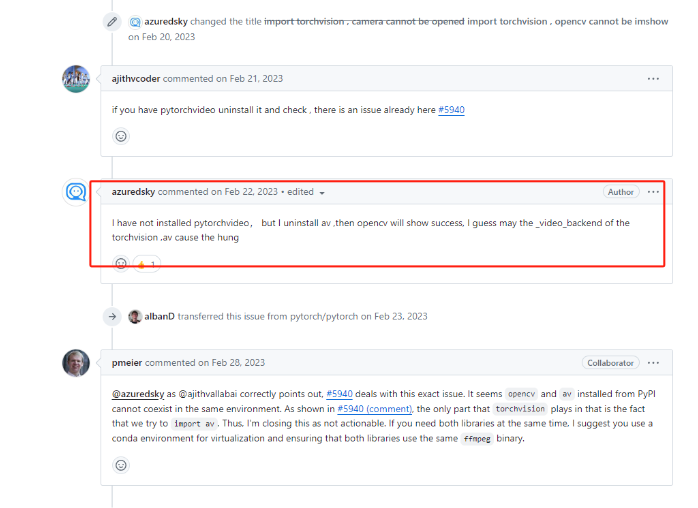
- 另外最好使用Anaconda 重新 conda create --name python38 python=3.8 一个环境
- 并且重新安装好环境,为了后续使用 base 环境 pip uninstall av, 使用 python38 这个环境 安装av
- 为什么呢? 因为 torchvision 会跟 av 运行起 冲突,使得 opencv 无法正常弹出窗口以及imshow操作
- 最后 不要忘了 pip install opencv-contrib-python opencv-python
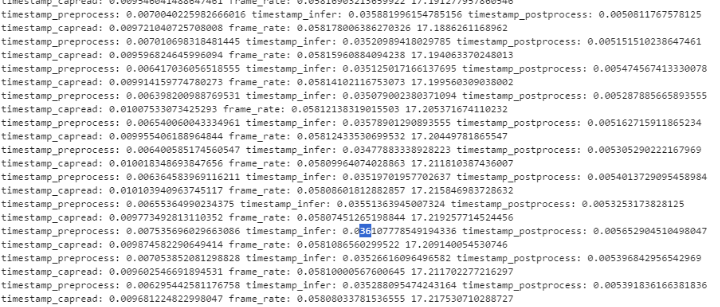
- 运行程序,当然在代码里,增加了前处理,推理,后处理的时间间隔输出
- 我们可以看到程序有27帧的处理速率,这里用到了dvpp + aipp +nms融合,效果明显
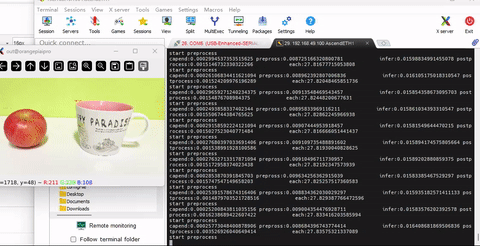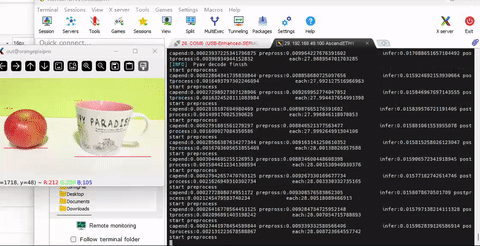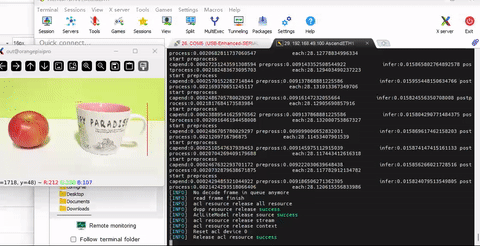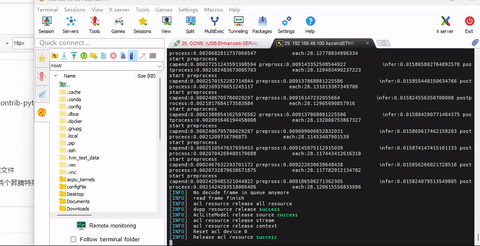
- 运行非常流畅

- 相比使用01-yolov5的官方案例,在jupyter 跑时间测量程序,只有9帧速率,效果好多了

- 如果去除了jupyter显示,也才17帧左右 ,所以是不能使用Jupyter进行一个帧率演示的
- 官方用了ACLLite 高一级语言处理,其实就是封装后的语言
- 我的思路是01-yolov5 推理框架不变,不用ACLLite ,使用yolov5_nms.om进行推理,然后使用AIPP进行前处理
- 因为AIPP 是在AI CORE 上面处理的,在BGR 转 RGB , HWC 转 CHW , 均值化处理上面 ,能得到很大的性能提升
- DVPP 主要涉及一个resize 工作 和 后处理 尺寸恢复以及 画框操作 可以直接用Python 来编写
- 这里DVPP resize 工作 我直接使用 原配letterbox 函数,preprocess_image其余删除
- 后处理 尺寸恢复以及 画框操作 使用 YOLOV5Video 的 postprocess操作
- 思路就大概如此,当然代码上需要做些细微调整,这里主要讲思路,代码就不贴了
aipp_op {
aipp_mode: static
input_format : RGB888_U8
src_image_size_w : 640
src_image_size_h : 640
csc_switch : false
rbuv_swap_switch : true
crop: true
load_start_pos_h : 0
load_start_pos_w : 0
crop_size_w : 640
crop_size_h : 640
min_chn_0 : 0
min_chn_1 : 0
min_chn_2 : 0
var_reci_chn_0: 0.0039215686274509803921568627451
var_reci_chn_1: 0.0039215686274509803921568627451
var_reci_chn_2: 0.0039215686274509803921568627451
}复制
def infer_frame_with_vis(image, model, labels_dict, cfg, bgr2rgb=True):
# 数据预处理
timestamp_start = time.time()
# img, scale_ratio, pad_size = preprocess_image(image, cfg, bgr2rgb)
img, scale_ratio, pad_size = letterbox(image, new_shape=cfg['input_shape'])
timestamp_preprocess = time.time()
# 模型推理
image_info = np.array([640, 640,
640, 640],
dtype=np.float32)
output = model.infer([img,image_info])
# output = torch.tensor(output)
timestamp_infer = time.time()
img_vis = postprocess(img,output,cfg)
timestamp_postprocess = time.time()
# print("timestamp_preprocess:",timestamp_preprocess - timestamp_start,"timestamp_infer:",timestamp_infer - timestamp_preprocess,"timestamp_postprocess:",timestamp_postprocess - timestamp_infer)
return img_vis复制
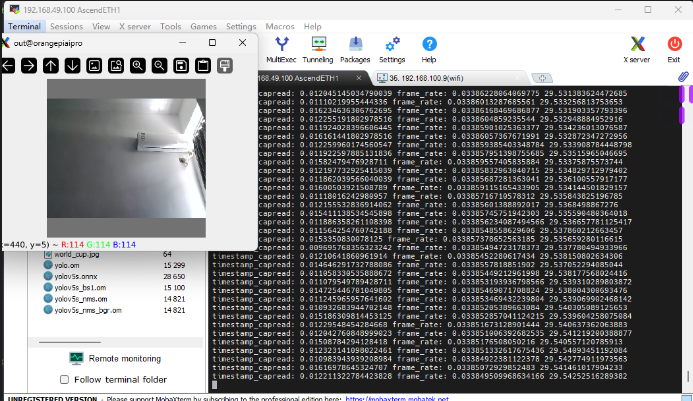
- 最后我是用了行人和车辆测试两个视频进行测试,效果如下
- 两个视频都是跑到了27fps

- 摄像头实时识别也能达到29fps-30fps
- 当然为什么比27fps高,我想应该是前处理输入视频的大小导致letterbox处理时间的不同,最终影响帧率
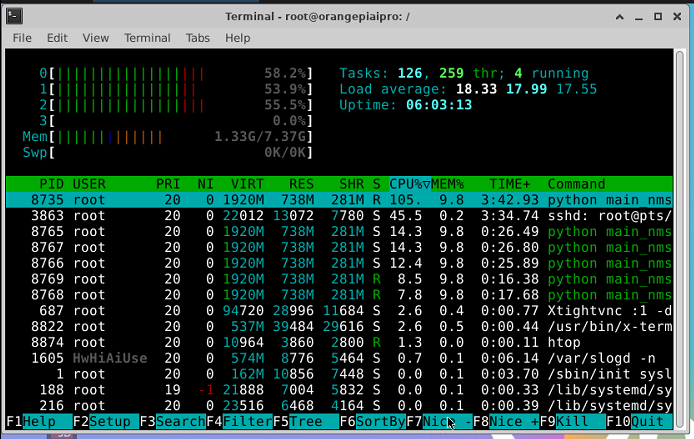
- 从cpu使用上看还是有提升空间的
- 最后我们来分析模型文件
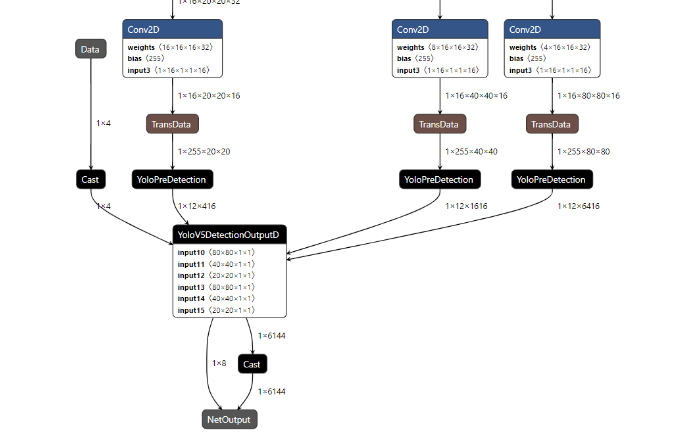
- yolov5_nms.om 网络分层中融合了两个昇腾特殊算子 YoloV5DetectionOutput算子和YoloPreDetection
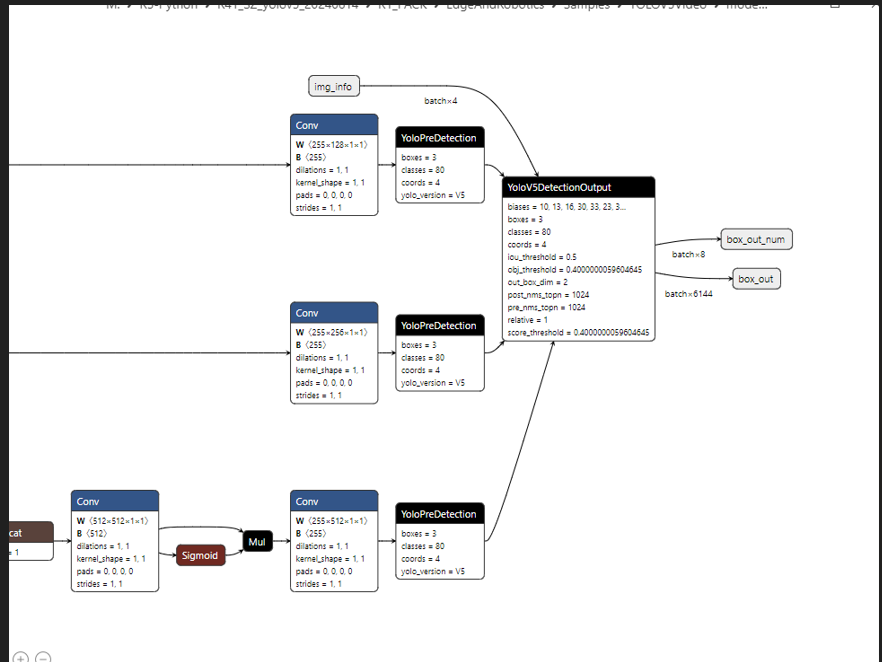
- 复习一下yolov5目标检测模型 输出张量的说明
- 正常情况应该是如下图输出
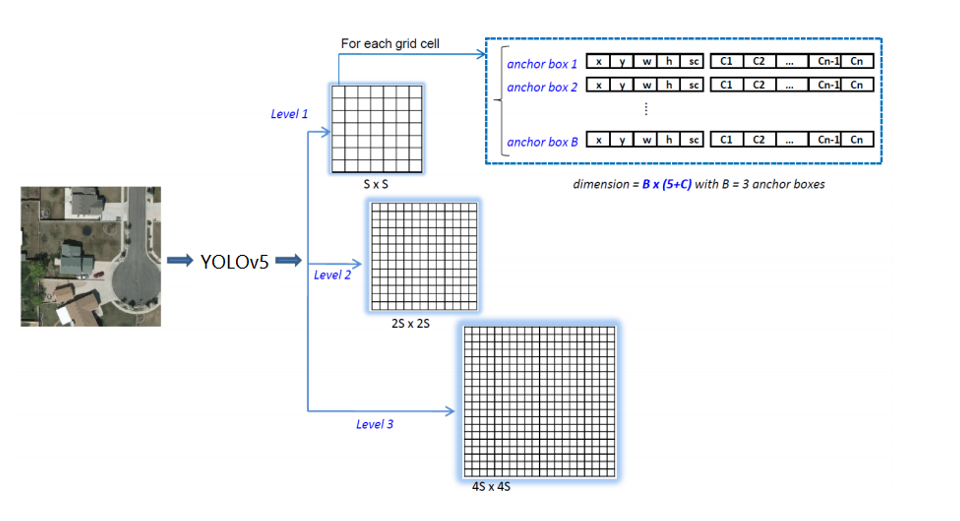
- box_out 是 float32 ,box_out_num 是 int32类型,可以看到跟正常模型输出很不一样
- 可以参照下图,感兴趣可以参考源码,源码架构写的很清楚,对80 * 80 40 * 40 20 * 20 框架进行分别处理,这里不细说了
- https://gitee.com/ascend/modelzoo-GPL/blob/master/built-in/ACL_Pytorch/Yolov3_for_PyTorch/common/util/add_nms.py
- 最后附录整个流程一些自问自答
AIPP是在哪个器件完成工作的?
DVPP是在哪个器件完成工作的?
整个流处理过程是怎么样的?对比opencv优势在哪里
什么痛点用到DVPP?
什么痛点用到AIPP?
DVPP在AIPP前还是后面?
AIPP和DVPP分工的不同?
需要的预处理如何用AIPP转换
DVPP要使用ACLLite进行编程吗?代码里面有所有实例,包括VDEC吗
aipp_mode 代表了什么?
mean_chn_i var_reci_chn 代表了什么? 如何计算得到的像素
csc_switch 是什么作用
rbuv_swap_switch 什么作用?
matrix_r0c0 列表数据要去哪里获得?是固定的吗?还是会改变的?
AIPP atc编译的时候使用 --insert_op_conf=aipp.cfg
经过AIPP处理后的图片,统一采用什么格式存储
AIPP NHWC 输入,最后会输出成什么格式
安装ACLLite核心流程应该是怎么样的?跟opencv 一样下载库文件然后设定环境变量就OK?还是使用Pip 或者conda 下载?
有多少个环境变量需要设定?
NPU_HOST_LIB 的环境变量跟 /etc/profile中的不一样怎么办?哪个为准?
环境变量里面哪两个最重要?是不是Python的引用需要使用到这两个环境变量?
ACLLite的本质代码是是什么?是CANN的底层代码封装吗?
av 下载应该选择怎么样的版本
怎么查看opencv版本号
opencv支持 h.264 直接cap.read() 或者 cv2.VideoCapture吗
如果opencv不支持h.264, DVPP应该进行怎么样的转码?是VDEC 吗?
h.264转RGB或者YUV 是如何控制转换的类型的?
h.264是什么格式?通过cap.read()读取每一帧是什么格式?
import videocapture as video , videocapture 读取h.264直接转换成jpeg吗?
videocapture是库文件吗?还是只是个py
av 下载应该选择怎么样的版本?大于6.2.0 版本可以吗?
配套的cython应该选择什么版本?0.29.37可以吗,大于会怎么样?
videocapture.VideoCapture和cv2.VideoCapture的区别?
版权归原作者 william_myq 所有, 如有侵权,请联系我们删除。