
0. 简介
最近几年随着深度学习的发展,现在通过深度学习去预估出景深的做法已经日渐成熟,所以随之而来的是本文的出现《Real-Time Dense Monocular SLAM with Neural Radiance Fields》。这篇文章是一个结合单目稠密SLAM和层次化体素神经辐射场的3D场景重建算法,能实时地用图像序列实现准确的辐射场构建,并且不需要位姿或深度输入。核心思想是,使用一个单目稠密SLAM方法来估计相机位姿和稠密深度图以及它们的不确定度,用上述信息作为监督信号来训练NeRF场景表征。代码已经在Github上完成了开源。
【搬】NeRF-SLAM:具有神经辐射场的实时密集单目 SLAM
1. 什么是NeRF
NeRF 是 2020 年 ECCV 上获得最佳论文荣誉提名的工作,其影响力是十分巨大的,不论是后续的学术论文还是商业落地,都引起了大量从业人员的关注。
NeRF 将隐式表达推上了一个新的高度,仅用 2D 的 posed images 作为监督,即可表示复杂的三维场景,在新视角合成这一任务上的表现是非常 impressive 的。当然 NeRF 在其他领域也逐渐开始展露头角,作为新兴的方向,势必也会和传统方法发生碰撞融合,产生新的火花。在B站中有比较详细的课程
NeRF系列公开课01 | 基于NeRF的三维内容生成
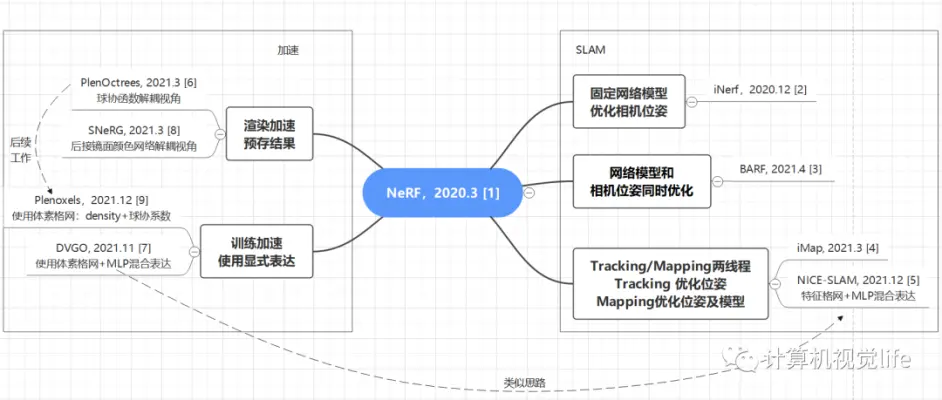
首先是一张框架图,梳理了这几篇工作各自的创新点和之间的关联关系,帮助大家有个宏观上的概念。[2][3][4][5]是和SLAM有关的工作,[6][8]和[7][9]分别是渲染加速和训练加速的工作,与SLAM无直接关系,但其加速的部分可能被SLAM用到。
我们先来熟悉一下NeRF具体含义。简单的来说,NeRF工作的过程可以分成两部分:三维重建和渲染。
- 三维重建部分本质上是一个2D到3D的建模过程,利用3D点的位置( x , y , z x,y,z x,y,z)及方位视角( θ , φ θ,φ θ,φ)作为输入,通过多层感知机(MLP)建模该点对应的颜色color( c c c)及体素密度volume density( σ σ σ),形成了3D场景的”隐式表示“。
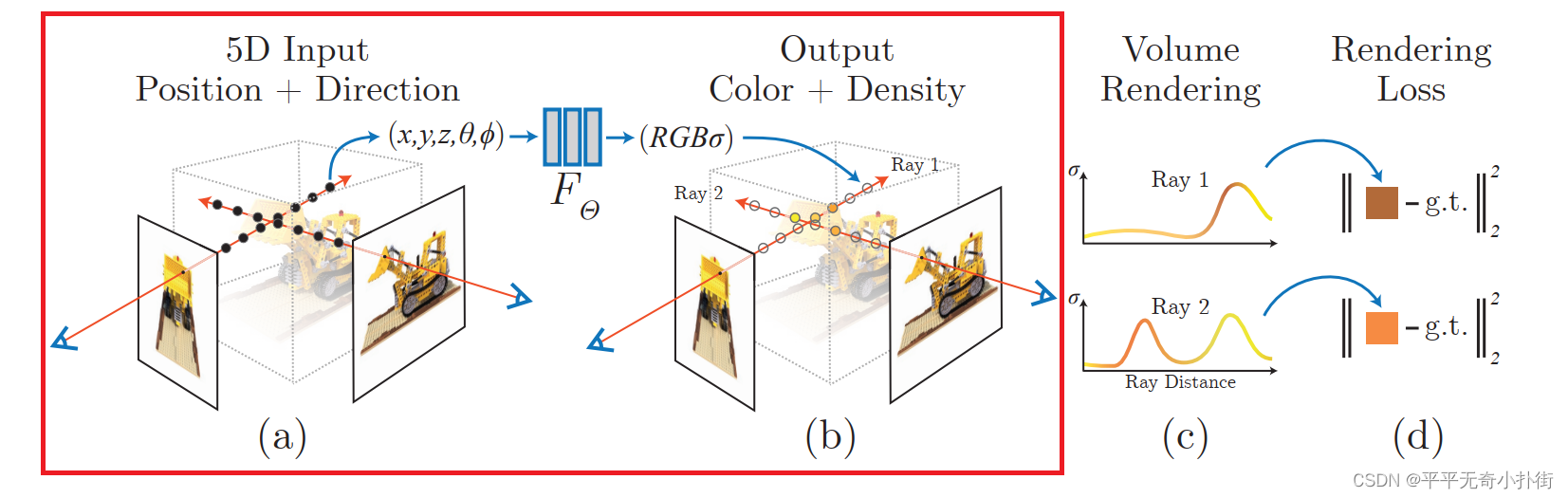
我们可以看到上图有一个映射
F
F
F,这代表了从二维向三维场景的”隐式表示”。也就是所述的MLP网络,由于最终要得到的是一个三维结果,即任意角度观察生成的物体,所以对于体积密度(不透明度)
σ
σ
σ和颜色
c
c
c有以下定义:
- 体积密度(不透明度) σ 只与三维位置 x , y , z x,y,z x,y,z有关而与视角方向 d 无关。物体不同位置的密度应该和观察角度无关.可以理解为该像素体无论从哪个角度观察,其本身性质是不变的。
- 颜色 c 与三维位置 x , y , z x,y,z x,y,z和视角方向 θ , φ θ,φ θ,φ都相关。由于光照等影响,各个角度观察同一个东西肯定颜色不同。
从上面可以得知网络训练出的参数中预测体积密度σ 的网络部分输入仅仅是输入位置
x
x
x,而预测颜色
c
c
c的网络输入是视角和方向
d
d
d。
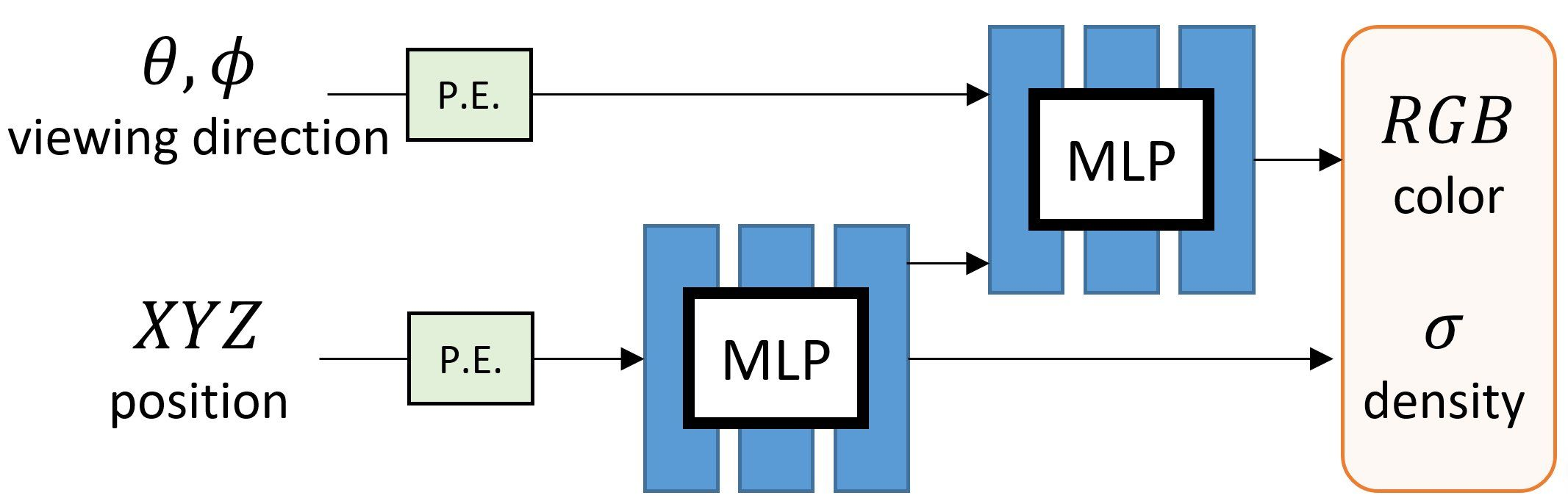
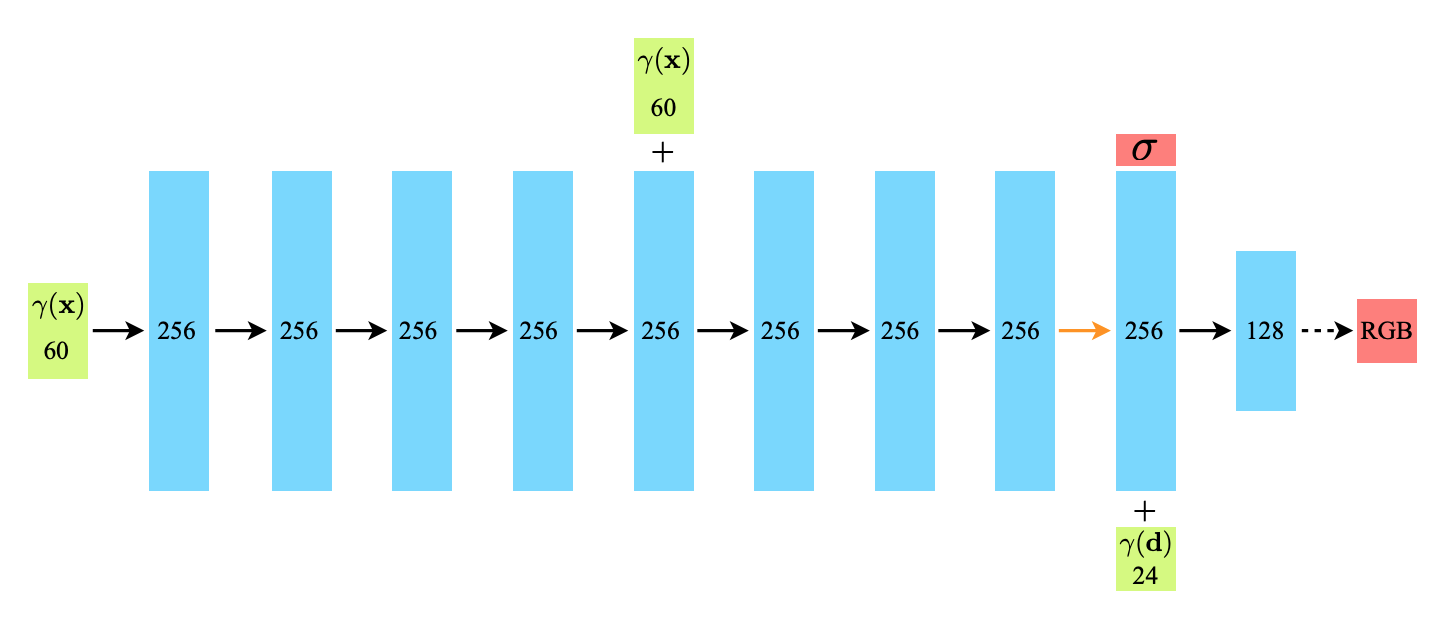
所以MLP的输入方式如下图所示,每个MLP 网络
F
F
F会使用 8 层的全连接层(使用 ReLU 激活函数,每层有 256 个通道),处理 3D 坐标
x
,
y
,
z
x,y,z
x,y,z,得到
σ
σ
σ和一个 256 维的特征向量,然后在用接着用4个全连接层处理,输出颜色
c
=
(
r
,
g
,
b
)
c=(r,g,b)
c=(r,g,b)
“显示表示”:3D场景包括Mesh,Point Cloud,Voxel,Volume等,它能够对场景进行显式建模,但是因为其是离散表示的,导致了不够精细化会造成重叠等伪影,更重要的是,它存储的三维场景表达信息数据量极大,对内存的消耗限制了高分辨率场景的应用。
”隐式表示“:3D场景通常用一个函数来描述场景几何,可以理解为将复杂的三维场景表达信息存储在函数的参数中。因为往往是学习一种3D场景的描述函数,因此在表达大分辨率场景的时候它的参数量相对于“显示表示”是较少的,并且”隐式表示“函数是种连续化的表达,对于场景的表达会更为精细。
- 渲染部分本质上是一个3D到2D的建模过程,渲染部分利用重建部分得到的3D点的颜色及不透明度沿着光线进行整合得到最终的2D图像像素值。
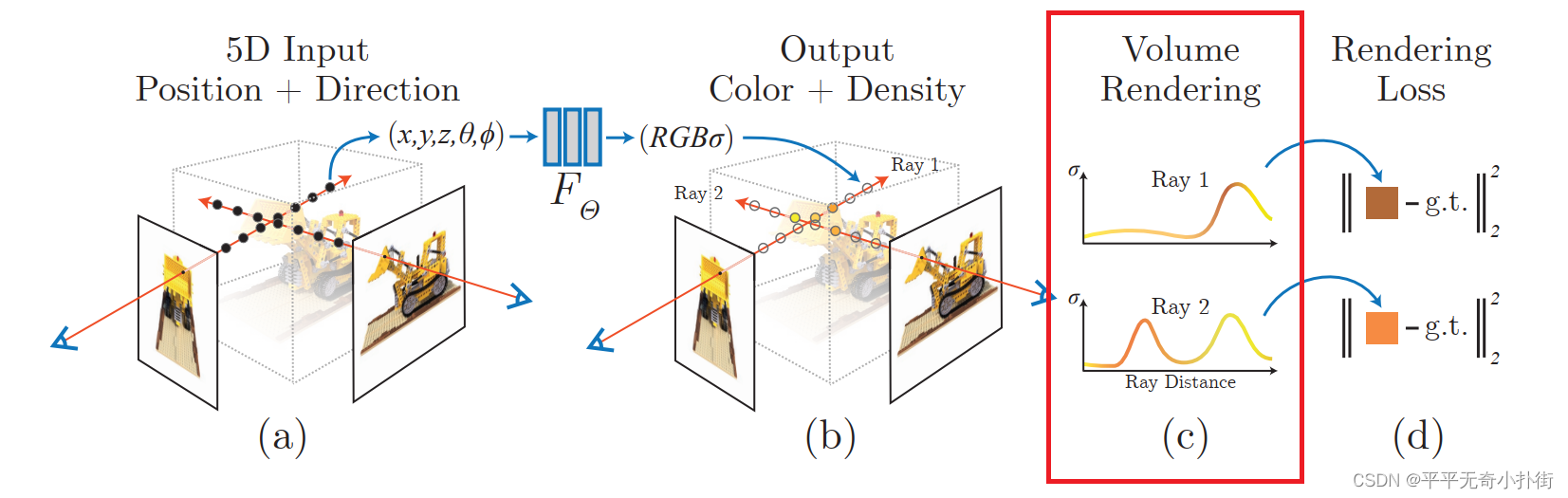 这部分最重要的就是:可见光的颜色 RGB 就是不同频率的光辐射作用于相机的结果。因此在 NeRF 中认为辐射场就是对于颜色的近似建模。
这部分最重要的就是:可见光的颜色 RGB 就是不同频率的光辐射作用于相机的结果。因此在 NeRF 中认为辐射场就是对于颜色的近似建模。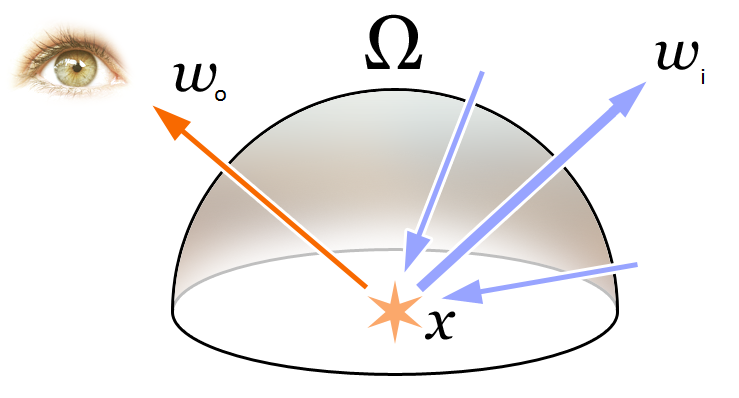 C ( r ) = ∫ t n t f T ( t ) σ ( r ( t ) ) c ( r ( t ) , d ) d t , w h e r e T ( t ) = ∫ t n t σ ( r ( s ) ) d s C(r)=\int_{t_n}^{t_f}T(t)σ(r(t))c(r(t), d)dt,whereT(t)=\int_{t_n}^{t}σ(r(s))ds C(r)=∫tntfT(t)σ(r(t))c(r(t),d)dt,whereT(t)=∫tntσ(r(s))ds 上面的是式子包含了我们第一部分提到的 σ ( r ( t ) ) σ(r(t)) σ(r(t))和 c ( r ( t ) , d ) c(r(t), d) c(r(t),d),其中函数T(t)表示射线从tn到t沿射线累积透射率,即射线从tn到t不碰到任何粒子的概率; r ( t ) = o + t d r(t)=o+td r(t)=o+td,具体含义为视角 o o o发出的方向为 t t t时刻到达点,表达的是位置信息。
C ( r ) = ∫ t n t f T ( t ) σ ( r ( t ) ) c ( r ( t ) , d ) d t , w h e r e T ( t ) = ∫ t n t σ ( r ( s ) ) d s C(r)=\int_{t_n}^{t_f}T(t)σ(r(t))c(r(t), d)dt,whereT(t)=\int_{t_n}^{t}σ(r(s))ds C(r)=∫tntfT(t)σ(r(t))c(r(t),d)dt,whereT(t)=∫tntσ(r(s))ds 上面的是式子包含了我们第一部分提到的 σ ( r ( t ) ) σ(r(t)) σ(r(t))和 c ( r ( t ) , d ) c(r(t), d) c(r(t),d),其中函数T(t)表示射线从tn到t沿射线累积透射率,即射线从tn到t不碰到任何粒子的概率; r ( t ) = o + t d r(t)=o+td r(t)=o+td,具体含义为视角 o o o发出的方向为 t t t时刻到达点,表达的是位置信息。
由于在计算机中不能连续积分,于是我们采用连续积分,通过采用分层采样的方式对
[
t
n
,
t
f
]
[t_n,t_f]
[tn,tf]划分成均匀分布的小区间,对每个区间均匀采样,并能还原一个连续的场景(类似重要性采样,对整个积分域进行非均匀离散化,较能还原原本的积分分布)。
C
^
(
r
)
=
∑
i
=
1
N
T
i
(
1
−
e
x
p
(
−
σ
i
δ
i
)
)
c
i
,
w
h
e
r
e
T
i
=
e
x
p
(
−
∑
j
=
1
i
−
1
σ
j
δ
j
)
\hat{C}(r)=\sum_{i=1}NT_i(1-exp(-\sigma_i\delta_i))c_i,whereT_i=exp(-\sum_{j=1}^{i-1}\sigma_j\delta_j)
C^(r)=i=1∑NTi(1−exp(−σiδi))ci,whereTi=exp(−j=1∑i−1σjδj)
- 在训练的时候,利用渲染部分得到的2D图像,通过与Ground Truth做L2损失函数(L2 Loss)进行网络优化。(即下图的红框部分)
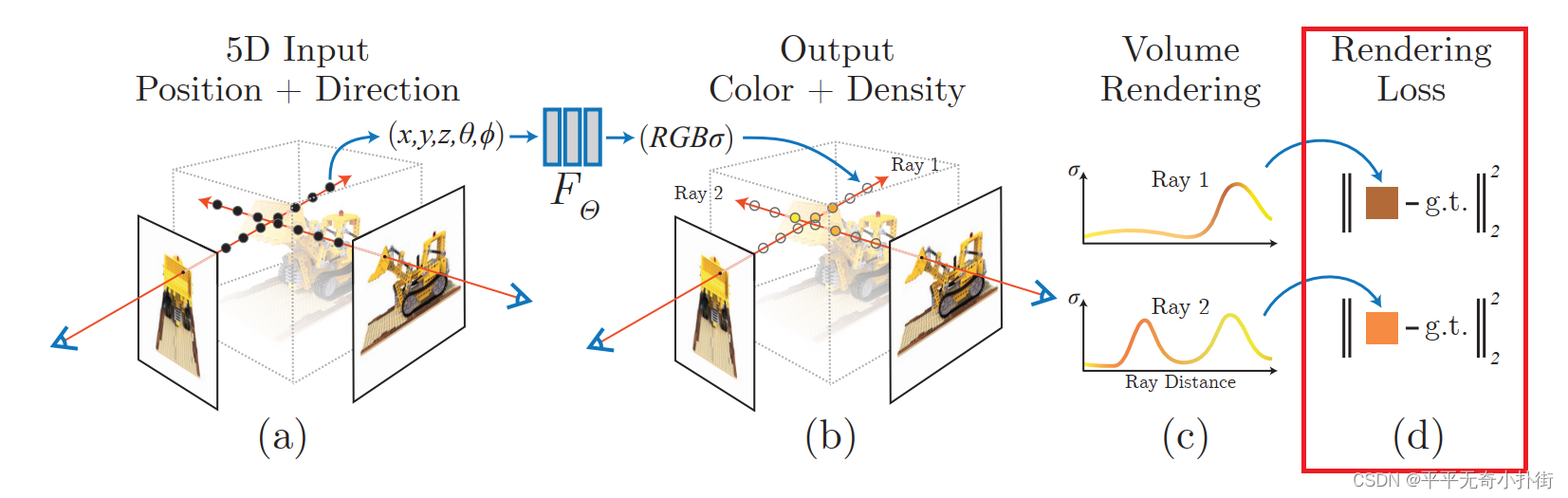 总体来说就是通过输入位姿以及2维图像(用于计算损失),得到3D的体素和不同方向的RGB。但是仍然存在训练细节不够精细,渲染在表示颜色和几何形状方面的高频变化方面表现不佳,训练速度慢等原因,为了进一步提升重建的精度和速度,引入了如下两个策略:
总体来说就是通过输入位姿以及2维图像(用于计算损失),得到3D的体素和不同方向的RGB。但是仍然存在训练细节不够精细,渲染在表示颜色和几何形状方面的高频变化方面表现不佳,训练速度慢等原因,为了进一步提升重建的精度和速度,引入了如下两个策略:
- 位置编码(Positional Encoding):使得MLP学习到的函数nerf能更好的表示高频信息,使用高频函数将输入映射到更高维度的空间,可以更好地拟合包含高频变化的数据。该高频编码函数为: γ ( p ) = ( s i n ( 2 0 π p ) , c o s ( 2 0 π p ) , … , s i n ( 2 L − 1 π p ) , c o s ( 2 L − 1 π p ) ) \gamma(p)=(sin(2^0\pi p),cos(2^0\pi p),…,sin(2^{L-1}\pi p),cos(2^{L-1}\pi p)) γ(p)=(sin(20πp),cos(20πp),…,sin(2L−1πp),cos(2L−1πp))
- 金字塔采样方案(Hierarchical Sampling Procedure):该部分指出在Volume Rendering中是在每条相机光线上的N个查询点密集地评估神经辐射场网络,这是低效的(仍然重复采样与渲染图像无关的自由空间和遮挡区域),于是提出一种分层体积采样的做法,同时优化一个“粗糙”的网络和一个“精细”的网络。通过这一策略,能使训练过程更高效地采样高频信息,该方法对于颜色贡献大的点附近采样密集,贡献小的点附近采样稀疏,从而由粗到细的分层采样方案。
这里训练使用颜色作为残差项,Loss是“粗糙”网络和“精细”网络渲染结果和真实像素颜色之间的总平方误差。
C
c
(
r
)
C_c(r)
Cc(r)为“粗糙”网络输出,
C
f
(
r
)
C_f(r)
Cf(r)为“精细”网络的输出。
L
o
s
s
=
∑
r
∈
R
[
∣
∣
C
^
c
(
t
)
−
C
(
r
)
∣
∣
2
2
+
∣
∣
C
^
f
(
t
)
−
C
(
r
)
∣
∣
2
2
]
Loss=\sum_{r\in R}[||\hat C_c(t)-C(r)||_2^2+||\hat C_f(t)-C(r)||_2^2]
Loss=r∈R∑[∣∣C^c(t)−C(r)∣∣22+∣∣C^f(t)−C(r)∣∣22]
2. NeRF-SLAM特点
本工作提出了的场景重建方法结合了单目稠密SLAM和层次化体素神经辐射场的优点,使用Droid-SLAM,稠密的光流估计,从而估计出了深度的不确定度。把深度图,深度的不确定度和相机位姿输入到NeRF网络里进行监督(残差引入了深度)。一个线程用来跟踪,另一个线程用来监督和渲染。具体如下。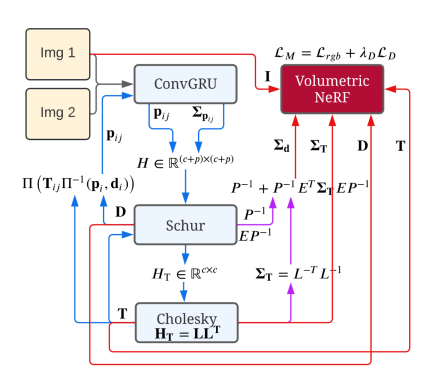
算法包含跟踪和建图两个并行的线程,跟踪模块使用单目稠密(dense monocular)SLAM估计稠密深度图(dense depth maps)和相机位姿,同时会输出对深度和位姿的不确定度估计,后端建图使用前端的输出信息作为监督,训练一个辐射场(radiance field),其损失函数是颜色误差和带权重的深度误差,权重值由先前的不确定度得到。
…详情请参照古月居
版权归原作者 敢敢のwings 所有, 如有侵权,请联系我们删除。