
Hawk和Griffin是DeepMind推出的新型循环神经网络(RNNs),2月刚刚发布在arxiv上。Hawk通过使用门控线性递归(gated linear recurrences)超越了Mamba的性能,而Griffin则是一种混合型模型,结合了门控线性递归和局部注意力(local attention),与Llama-2的性能相当,但使用的训练数据明显较少。Griffin在处理比训练时更长的序列时表现出色。这两种模型在硬件效率方面与Transformer相当,但在推理过程中具有更低的延迟和更高的吞吐量。Griffin的规模已扩展到了140亿个(14B)参数。
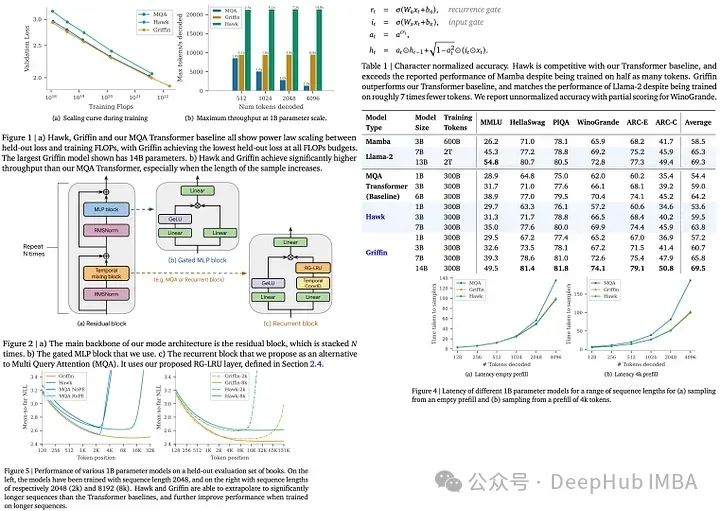
模型架构
该架构有三个主要组件:残差块(residual block)、MLP块和时序混合块(temporal-mixing block)。残差块和MLP块在不同模型中保持一致,而时序混合块有三种类型:全局多查询注意力(global Multi-Query Attention,MQA)、局部MQA和一种新颖的循环块。
残差块:受到预归一化Transformer的启发,通过多层处理输入序列,对最终激活应用RMSNorm,并使用一个共享的线性层来计算标记概率。
MLP块:采用具有扩展因子的门控机制,应用线性层和GeLU非线性激活,然后进行逐元素乘法和最终的线性层。
时序混合块:
- 全局MQA旨在通过使用128维的头,并且要求模型维度是128的倍数来提高推理速度(与Multi-Head Attention相比)。使用旋转位置嵌入(Rotary Position Embedding,RoPE)代替绝对位置嵌入。
- 局部滑动窗口注意力通过将注意力限制在固定窗口的过去标记上,解决了全局注意力的计算效率问题。
- 循环块受现有块(如GSS块和Mamba的块)的启发,对输入应用两个平行线性层。在一个小的Conv1D后一个分支上使用新发明的RG-LRU,另一个分支使用GeLU进行激活,然后通过逐元素乘法合并它们,输入到最终的线性层。
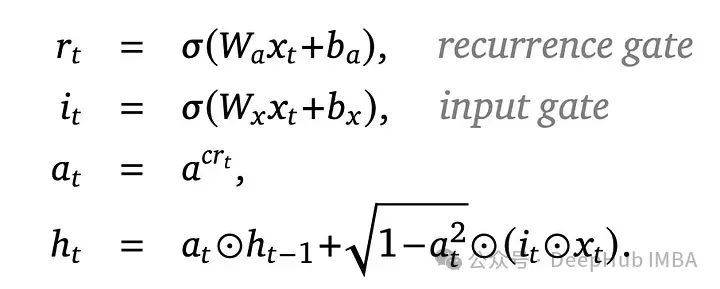
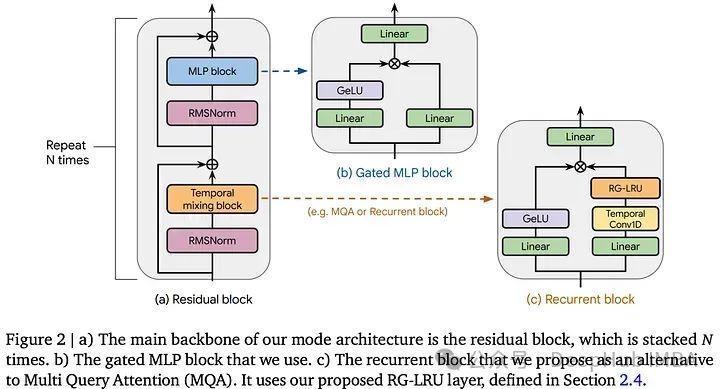
Real-Gated Linear Recurrent Unit(RG-LRU)具有一个循环门和一个输入门,两者都使用Sigmoid函数进行非线性处理,并执行逐元素操作以实现稳定的循环。RG-LRU使用可学习参数来确保门控值稳定在0到1之间。这些门控不依赖于循环状态,这样可以实现高效的计算。
循环门允许丢弃输入并保留所有来自先前历史的信息。
循环模型和Transformers一样有效
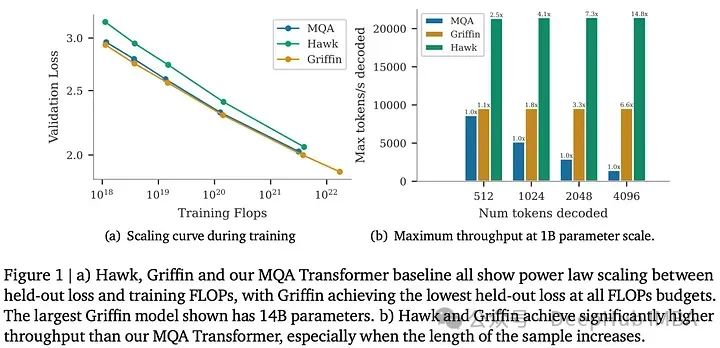
这三个模型系列都是在从100M到14B参数的各种规模上进行训练的,遵循Chinchilla扩展定律并使用MassiveText数据集。所有模型显示出验证损失与训练FLOPs之间都呈线性关系。Griffin在所有相同的FLOP下都比Transformer模型实现了更低的验证损失(没有使用全局注意力层);而Hawk显示出稍高的验证损失,但随着FLOP的增加,这种差距逐渐缩小。
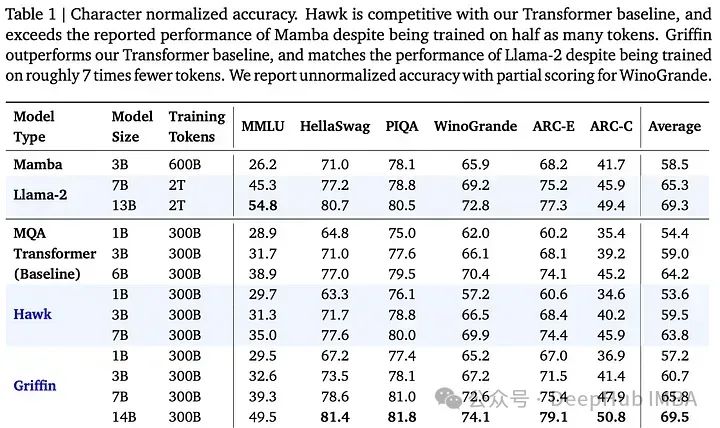
对于下游任务评估,模型使用了300B标记的进行训练,与使用更多标记进行训练的Mamba-3B和Llama-2进行了比较。Hawk在3B大小上优于Mamba-3B,而Griffin不仅超过了Mamba-3B,在7B和14B规模上还与Llama-2不相上下。此外Griffin还优于MQA Transformer基线,显示了这些模型在使用更少的训练令牌标记实现高性能方面是有效的。
循环模型的高效训练
对于大规模训练,作者使用Megatron的分片技术来处理MLP和MQA模块,并使用块对角权重来处理RG-LRU门控,减少设备间的通信。使用ZeRO并行和bfloat16表示来控制内存消耗。
为了解决RG-LRU层低FLOPs与字节比的计算挑战,作者在Pallas(JAX)中编写了一个自定义内核,这种线性扫描的方法提升了3倍的速度。
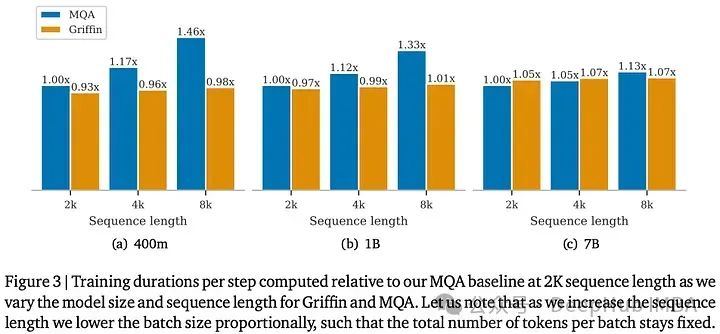
跨不同模型和序列长度的训练速度比较显示:随着序列长度增加,Griffin可以保持一致的训练时间,这与Transformer的训练时间形成对比。这种效率归因于线性层与RG-LRU和注意力机制的不同,而对于短序列由于Griffin稍高的参数和FLOP数量导致它的训练速度略低于MQA基线。
推理速度
在大型语言模型(LLMs)中的推理包括两个阶段:“预填充”阶段(其中提示信息被并行处理,这会导致速度与训练期间相似),以及“解码”阶段(其中标记被自回归地生成),循环模型在较长序列长度上展示出较低的延迟和较高的吞吐量。
所以延迟和吞吐量是评估推理速度的主要指标。在解码过程中Transformer和循环模型都受到内存限制,但是与Transformer的KV缓存相比,循环模型具有较小的循环状态大小,所以具有较低的延迟并且可以处理更大的批次数据从而提高吞吐量。
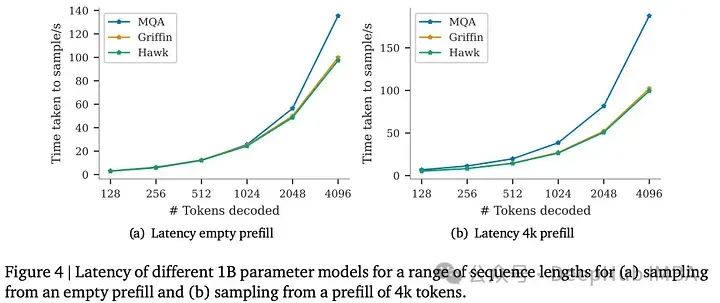
在1B参数模型的推理性能比较中,Hawk和Griffin展示了与MQA Transformer基线相比更好的延迟和吞吐量(特别是对于长序列)。随着预填充长度的增加,Hawk和Griffin的低延迟变得更加明显,突出了线性递归和局部注意机制的效率。
长上下文建模
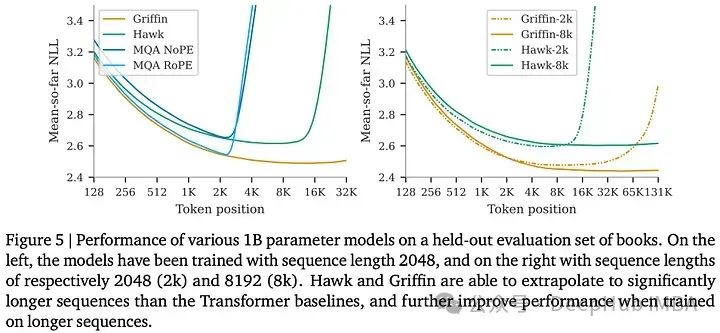
作者评估了Hawk和Griffin的长上下文预测能力。其中Griffin展现出了显著的外推能力。使用8k标记序列训练的模型与使用2k标记序列训练的模型进行对比,Hawk-8k和Griffin-8k在处理更长序列时表现更好。对于较短的序列,使用2k标记训练的模型(Hawk-2k和Griffin-2k)则更好。这表明了将训练序列长度与模型预期应用需求保持一致是非常有必要的。
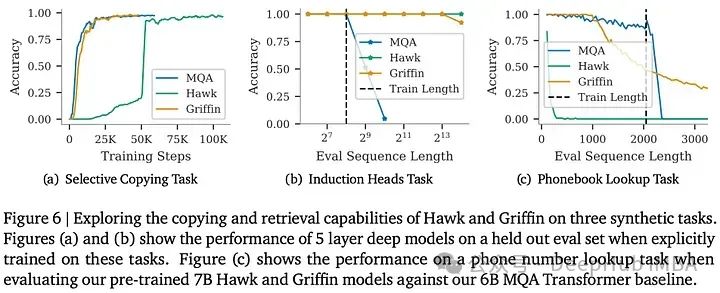
论文还通过一个synthetic tasks和一个实际的电话号码查找任务,研究了Hawk和Griffin在复制和检索上下文中的标记的能力,并将它们与MQA Transformer基线进行了比较。在选择性复制和归纳任务中,Griffin与Transformer的学习速度相匹配,并展示了对较长序列的优越外推能力,而Transformer基线在外推方面表现不佳。Hawk在归纳头部任务中表现出色的外推能力但是它学习速度上较慢。
在一个真实的电话簿查找任务中,对预训练的Hawk、Griffin和MQA Transformer模型进行了测试。Hawk在较短的电话簿长度上表现良好,但由于其状态是固定大小的,所以随着长度的增加性能逐渐降低。Transformer基线在其训练序列长度范围内是没有问题的,但在序列长处超出了范围则获得了非常差的性能。Griffin在解决任务时表现出色,对较长序列的外推能力更好,但是上下文超出窗口大小性能也会下降。
总结
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models是一个非常有意思的研究,想想Transformer 就是17年google发布的,现在又看是研究回状态空间和循环了,也许这个方向是LLM的下一个突破也不一定,有兴趣的可以多关注下。
论文地址:
https://arxiv.org/abs/2402.19427
代码目前我们看到,看看有什么后续吧
作者:Andrew Lukyanenko