
数据
为了说明这是如何工作的,让我们假设我们有一个简单的数据集,它有一个datetime列和几个其他分类列。您感兴趣的是某一列(“类型”)在一段时间内(“日期”)的汇总计数。列可以是数字、类别或布尔值,但是这没关系。
注意:初始部分包含用于上下文和显示常见错误的代码,对于现成的解决方案,请参阅最后的GitHub的代码。
# Example Datadata = {'dates':
['2012-05-04',
'2012-05-04',
'2012-10-08'],
'types':
['a',
'a',
'z'],
'some_col':
['n',
'u',
'q']
}
df = pd.DataFrame.from_dict(data)
分组、组织和分类
作为第一步,对数据进行分组、组织和排序,以根据所需度量的时间生成计数。在下面的代码块中,您可以在此阶段进行一些逐行转换。
# some housekeeping
df['dates'] = pd.to_datetime(df['dates'])
# subset
df = df[['dates', 'types']]
# groupby and aggregate
df = df.groupby([pd.Grouper(key='dates')]).agg('count')
# reset index
df = df.reset_index()# rename the types col (optional)
df = df.rename(columns={'types':'count'})
为了清晰起见,这些步骤可以通过如下所示的方式使用一些额外的数据来完成。重要的是分组,然后按日期时间计数。
data = {'dates':
['2012-05-04',
'2012-05-04',
'2012-06-04',
'2012-08-08'],
'types':
['a',
'a',
'z',
'z',],
'some_col':
['n',
'u',
'q',
'']
}
df['dates'] = pd.to_datetime(df['dates'])
df = df[['dates', 'types']].groupby([pd.Grouper(key='dates')]).agg('count').reset_index()
df = df.rename(columns={'types:'count'})
print(df)
"""
dates count
1 2012-06-04 1
2 2012-08-08 1
0 2012-05-04 2
"""
如果您注意到,前面的代码会按提供的日期分组。但是,如果您想按月或年进行分组呢?为了完成这个任务,使用Grouper参数的频率。
freq='M'
# or 'D' or 'Y'
df = df[['dates', 'types']].groupby([pd.Grouper(key='dates', freq=freq)]).agg('count').reset_index()
"""
dates count
2 2012-07-31 0
1 2012-06-30 1
3 2012-08-31 1
0 2012-05-31 2
"""
# group by the category being counted, or count in this case
group = df.groupby('count')
print(group)
"""
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7fc04f3b9cd0>
"""
以上代码来自pandas的doc文档
在上面的代码块中,当使用每月“M”频率的Grouper方法时,请注意结果dataframe是如何为给定的数据范围生成每月行的。最后,作为DataFrame准备的最后一步,通过“计数”将数据分组——我们在处理Plotly之后会回到这个问题上。
Plotly Express 和 Plotly Graph Objects
在所有的图形库中,Plotly是可视化效果最好的了,但是他也存在一些问题。好的一方面是,Plotly能够产生出色的可视化效果,并与HTML集成。从不好的是,在单图和混合图之间切换时,语法可能会非常混乱。例如,使用plotly_express(px),可以传递整个DataFrames作为参数;但是,使用graph_objects(go)时,输入会更改,并且可能需要使用字典和Pandas系列而不是DataFrames。
为了熟悉用法我们先使用Plotly Express进行的简单绘图
import plotly_express as pxfig = px.area(df, x='dates', y='count')
fig.show()
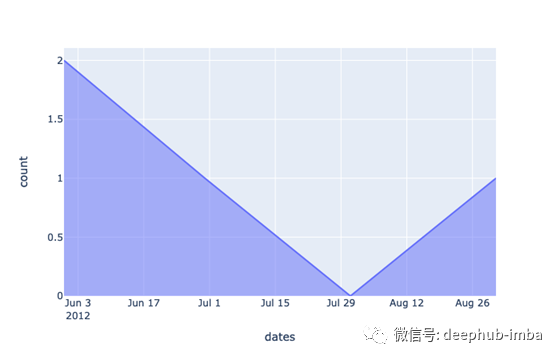
如果您只需要一个简单的时间序列,例如下面所示的时间序列,那么也许就足够了。但是,在同一x轴(时间)上具有两个或更多数据计数的Plotly呢?
为了解决上面的问题,我们就需要从Plotly Express切换到Plotly Graph Objects。大多数时候,我都会使用Plotly的graph_objects库,因为里面包含了很多Express不可用的功能。例如,使用graph_objects,我可以生成混合子图,并且重要的是,可以覆盖多种类型的数据(例如时间序列)。
在使用px之前,我们将px对象分配给了fig(如上所示),然后使用fig.show()显示了fig。现在,我们不想创建一个包含一系列数据的图形,而是要创建一个空白画布,以后再添加到其中。如果运行以下代码,则将按字面值返回一个空白画布。
import plotly.graph_objects as go
fig = go.Figure()
在使用空白的graph_objects的情况下,可以向画布添加痕迹(图形)。对于线和散点图等最常见的任务,go.Scatter()方法是您想要使用的方法。
# add a graph to the canvas as a trace
fig.add_trace(go.Scatter(x=df['dates'], y=df['count']))
尽管这可行,但是您可能会发现输出不是理想的。代替由点按时间顺序连接的点,我们有了某种奇怪的“ z”符号。

运行中的go.Scatter()图,但未达到预期。点的连接顺序错误。下面图形是按日期对值进行排序后的相同数据。

这个小问题可能会令人沮丧,因为使用px,图形可以按您期望的方式运行,而无需进行任何调整,但go并非如此。要解决该问题,只需确保按日期对数组进行排序,以使其按某种逻辑顺序绘制和连接点。
# sort the df by a date col, then show fig
df = df.sort_values(by='dates')
此时,在相同的时间序列上手动绘制不同类型的数据可能就足够了。例如,如果您有两个不同的具有时间序列数据或多个子集的DataFrame,则可以继续向graph_object添加。
# if multiple DataFrames: df1 and df2
fig.add_trace(go.Scatter(x=df1['dates'], y=df1['count']))
fig.add_trace(go.Scatter(x=df2['dates'], y=df2['count']))
# ... and so on
但是,如果您有大量的数据,那么很快就不希望编写同样的代码了。所以我们使用分组来进行优化
df = df.groupby('types')# after grouping, add traces with loops
for group_name, df in group:
fig.add_trace(
go.Scatter(
x=df['dates']
, y=df['count']
))
把它们放在一起
在前面的小节中,我们逐步介绍了将整个可视化整合在一起所需的一些部件和部件,但是还有一些缺失的部分。例如,使用groupby方法时,我们丢失了类别(a、b)的type列,仅凭三个数据点很难判断是否存在任何类型的趋势。在本节中,让我们切换到一个样本数据集,该数据集有几百条记录和两个类别(a、b),它们跨越了几年时间。
读取和分组数据
在下面的代码块中,一个示例CSV表被加载到一个Pandas数据框架中,列作为类型和日期。类似地,与前面一样,我们将date列转换为datetime。这一次,请注意我们如何在groupby方法中包含types列,然后将types指定为要计数的列。
在一个列中,用分类聚合计数将dataframe分组。
gitcsv = 'https://raw.githubusercontent.com/justinhchae/medium/main/sample.csv'
df = pd.read_csv(gitcsv, index_col=0)
df['dates'] = pd.to_datetime(df['dates'])
freq='M'
df = df.groupby(['types', pd.Grouper(key='dates', freq=freq)])['types'].agg(['count']).reset_index()
print(df)
"""
types dates count
0 b 2016-01-31 1
1 a 2016-01-31 5
2 b 2016-02-29 3
3 a 2016-02-29 4
4 b 2016-03-31 3
5 a 2016-03-31 6
6 b 2016-04-30 1
...
"""
以前我们只按一列计数排序,但是我们也需要按日期排序。我们如何根据日期和计数排序?对于这个任务,在sort_values()的' by= '参数中指定列名。
# return a sorted DataFrame by date then count
df = df.sort_values(by=['dates', 'count'])# if you want to reset the index
df = df.reset_index(drop=True)
最后,让我们看看使用Plotly Express使用样本数据生成的图是什么样子的。
fig = px.area(df, x='dates', y='count', color='types')

现在,同样的数据表示为回归曲线。
fig = px.scatter(df
, x='dates'
, y='count'
, color='types'
, trendline='lowess'
)
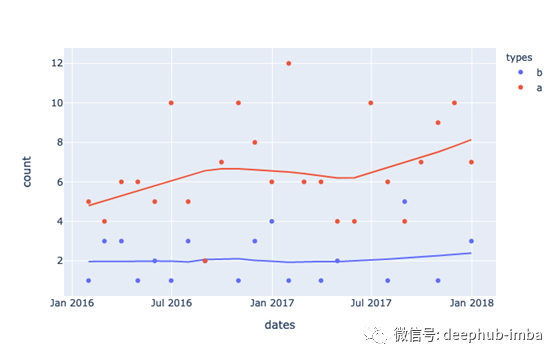
这些都很好,但是我们如何才能将回归曲线覆盖在时间序列之上呢?有几种方法可以完成这项工作,但是经过一番研究之后,我决定使用图形对象来绘制图表并Plotly表达来生成回归数据。
从绘图对象开始重新绘制时间序列,为了填充每行下面的区域,将fill= ' tozeroy '作为参数添加到add_trace()方法。
import plotly.graph_objects as go
import plotly_express as px
# group the dataframe
group = df.groupby('types')
# create a blank canvas
fig = go.Figure()
# each group iteration returns a tuple
# (group name, dataframe)
for group_name, df in group:
fig.add_trace(
go.Scatter(
x=df['dates']
, y=df['count']
, fill='tozeroy'
))

下面是我从Stack Overflow的帖子中借鉴的一个技巧,在循环中组合Plotly Express和Graph对象。有人想要在条形图中添加趋势线,当我们使用Plotly Express来生成趋势线时,它也会创建数据点——这些数据点可以作为普通的x、y数据访问,就像dataframe中的计数一样。因此,我们可以将它们作为图形对象在循环中绘制出来。
注意,我们使用Graph Objects将两类数据绘制到一个图中,但使用Plotly Express为每个类别的趋势生成数据点。
import plotly.graph_objects as go
import plotly_express as px
# group the dataframe
group = df.groupby('types')
# create a blank canvas
fig = go.Figure()
# each group iteration returns a tuple
# (group name, dataframe)
for group_name, df in group:
# in each loop, draw a time series then a regression line
fig.add_trace(
go.Scatter(
x=df['dates']
, y=df['count']
, fill='tozeroy'
))
# source: https://stackoverflow.com/questions/60204175/plotly-how-to-add-trendline-to-a-bar-chart
# generate a regression line with px
help_fig = px.scatter(df, x=df['dates'], y=df['count'], trendline="lowess")
# extract points as plain x and y
x_trend = help_fig["data"][1]['x']
y_trend = help_fig["data"][1]['y']
# add the x,y data as a scatter graph object
fig.add_trace(
go.Scatter(x=x_trend, y=y_trend, name='trend'))
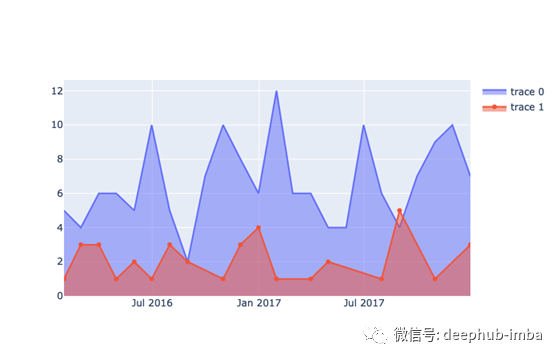
我们已经有了带有线条和趋势的基本图形对象,但还需要清理一些东西。例如,标签不是很有帮助,颜色都掉了。
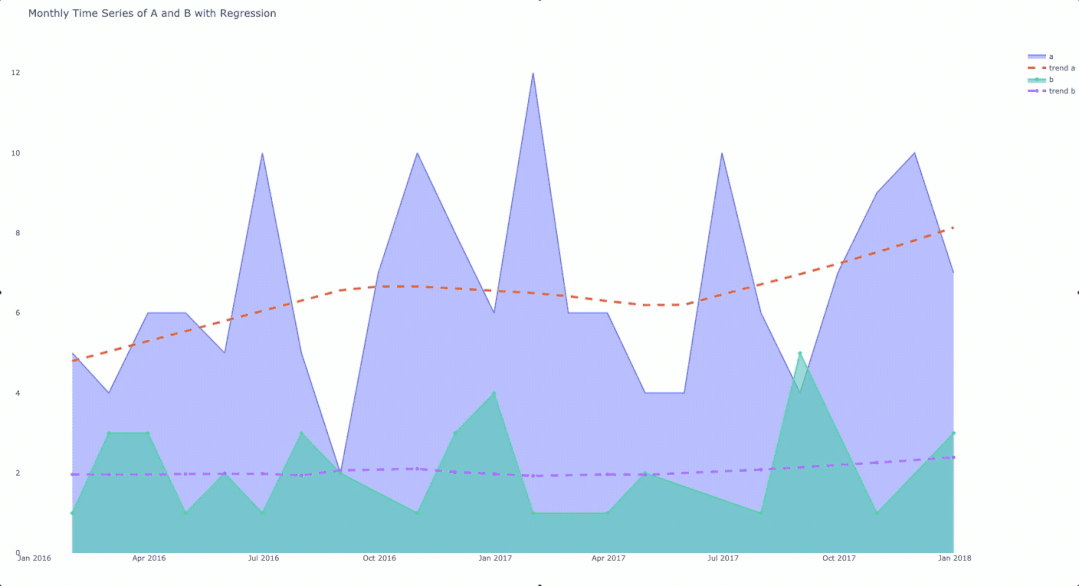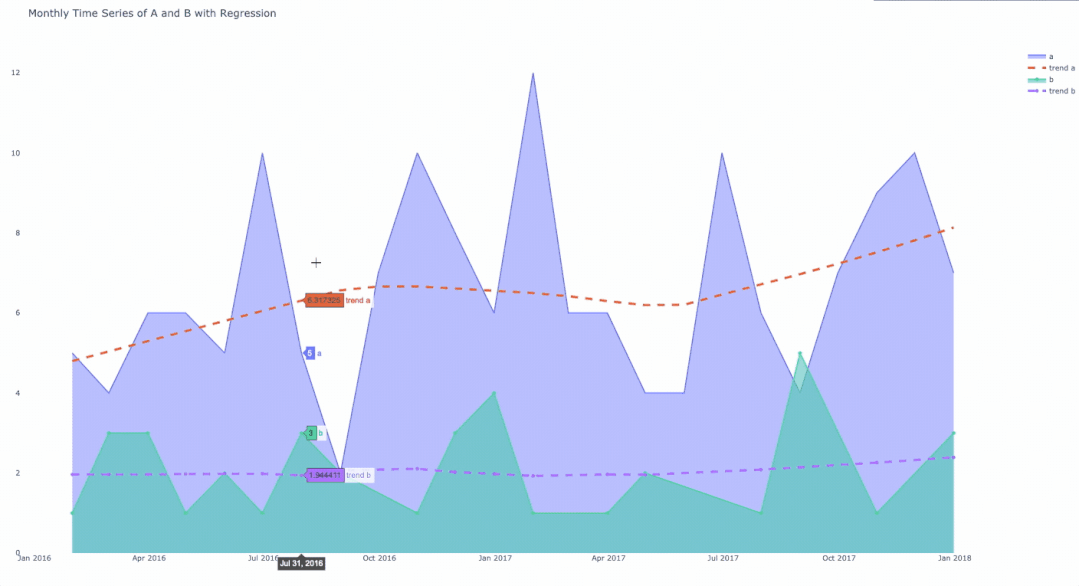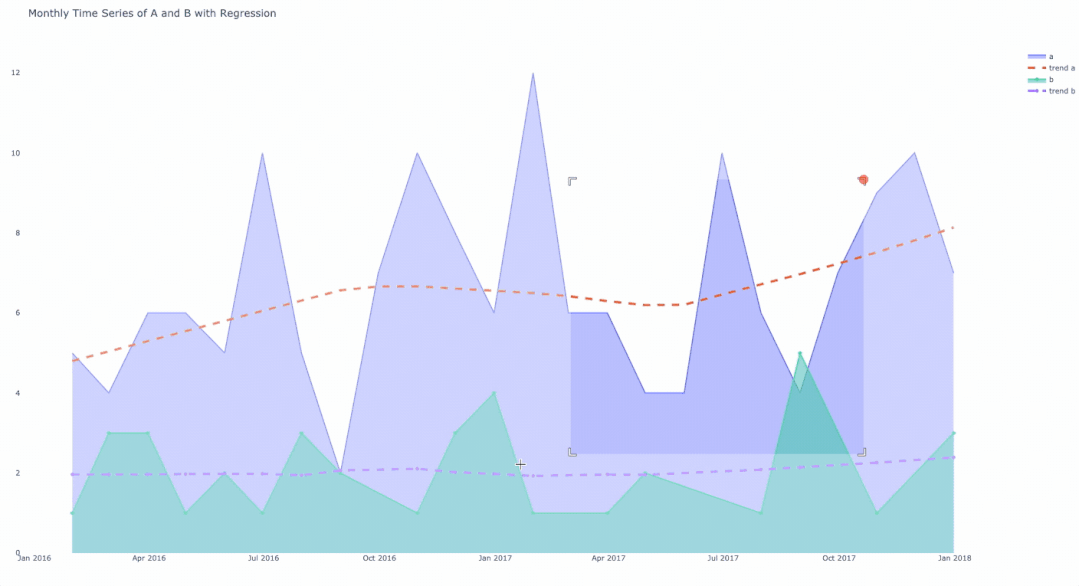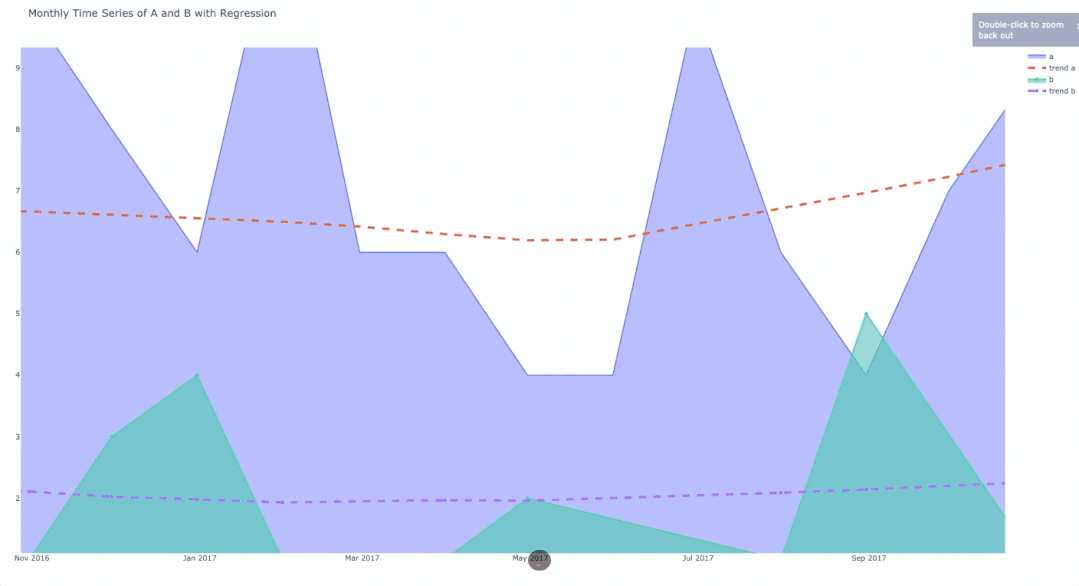
要处理一些内部管理问题,需要向go.Scatter()方法添加更多参数。因为我们在for循环中传递了分组的dataframe,所以我们可以迭代地访问组名和数据帧的元素。在这段代码的最终版本中,请注意散点对象中的line和name参数,以指定虚线。
import pandas as pd
import plotly.graph_objects as go
import plotly_express as px
gitcsv = 'https://raw.githubusercontent.com/justinhchae/medium/main/sample.csv'
df = pd.read_csv(gitcsv, index_col=0)
df['dates'] = pd.to_datetime(df['dates'])
freq='M' # or D or Y
df = df.groupby(['types', pd.Grouper(key='dates', freq=freq)])['types'].agg(['count']).reset_index()
df = df.sort_values(by=['dates', 'count']).reset_index(drop=True)
# group the dataframe
group = df.groupby('types')
# create a blank canvas
fig = go.Figure()
# each group iteration returns a tuple
# (group name, dataframe)
for group_name, df in group:
fig.add_trace(
go.Scatter(
x=df['dates']
, y=df['count']
, fill='tozeroy'
, name=group_name
))
# generate a regression line with px
help_fig = px.scatter(df, x=df['dates'], y=df['count']
, trendline="lowess")
# extract points as plain x and y
x_trend = help_fig["data"][1]['x']
y_trend = help_fig["data"][1]['y']
# add the x,y data as a scatter graph object
fig.add_trace(
go.Scatter(x=x_trend, y=y_trend
, name=str('trend ' + group_name)
, line = dict(width=4, dash='dash')))
transparent = 'rgba(0,0,0,0)'
fig.update_layout(
hovermode='x',
showlegend=True
# , title_text=str('Court Data for ' + str(year))
, paper_bgcolor=transparent
, plot_bgcolor=transparent
, title='Monthly Time Series of A and B with Regression'
)
fig.show()
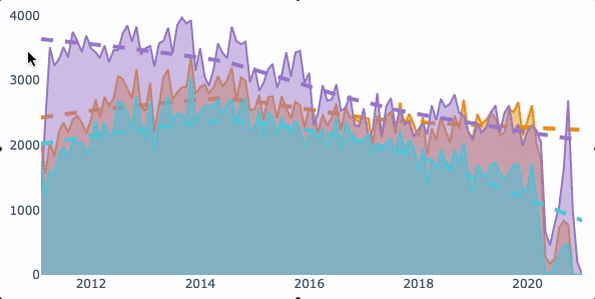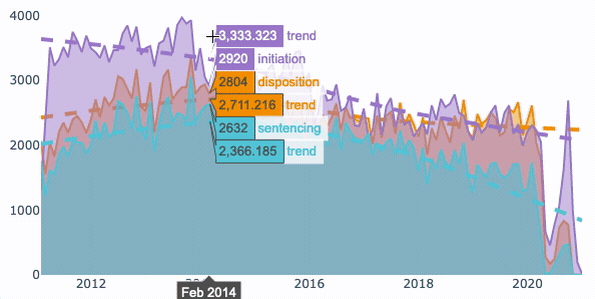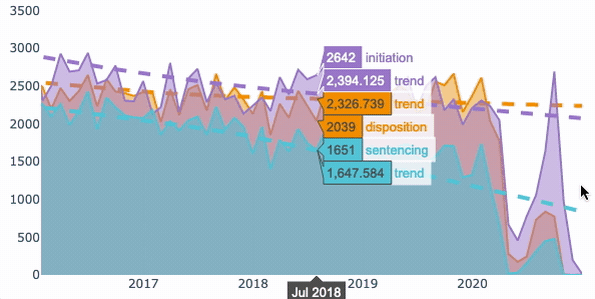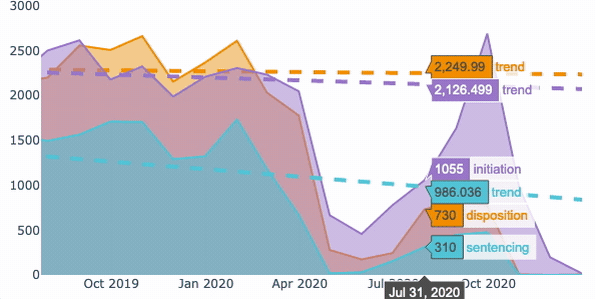
将聚合的数据分组并使用for循环对其绘图后的最终结果。
总结
在本文中介绍了使用Plotly将对象绘制成带有趋势线的时间序列来绘制数据。
解决方案通常需要按所需的时间段对数据进行分组,然后再按子类别对数据进行分组。在对数据分组之后,使用Graph Objects库在每个循环中生成数据并为回归线绘制数据。
结果是一个交互式图表,显示了每一类数据随时间变化的计数和趋势线。
译者注:plotly是一个非常好的可视化神器,尤其是在交互操作方面,所以我选择sns和matplotlib
作者:Justin Chae
deephub翻译组