
摘要
本专栏是讲解如何改进RT-DETR的专栏。改进方法采用了最新的论文提到的方法。改进的方法包括:增加注意力机制、更换卷积、更换block、更换backbone、更换head、更换优化器等;每篇文章提供了一种到N种改进方法。
评测用的数据集是我自己标注的数据集,里面包含32种飞机。每种改进方法我都做了测评,并与官方的模型做对比。
代码和PDF版本的文章,我在验证无误后会上传到百度网盘中,方便大家下载使用。
求质不求量,争取尽心尽力打造精品专栏!!!
欢迎订阅,谢谢大家支持!!!
已经更6篇内容,还在持续更新中。。。。
RT-DETR改进策略:双动态令牌混合器(D-Mixer)的TransXNet,实现RT-DETR的有效涨点
RT-DETR改进策略:双动态令牌混合器(D-Mixer)的TransXNet,实现RT-DETR的有效涨点
双动态令牌混合器(D-Mixer),一种输入依赖的方式聚合全局信息和局部细节。D-Mixer通过分别在均匀分割的特征片段上应用有效的全局注意力模块和输入依赖的深度卷积,使网络具有强大的归纳偏差和扩大的有效感受野。使用D-Mixer作为基本构建块设计了TransXNet,这是一种新型的混合CNN-Transformer视觉主干网络,可提供引人注目的性能。在ImageNet-1K图像分类任务中,TransXNet-T在计算成本不到Swin-T的一半的情况下,Top-1准确率提高了0.3%。此外,TransXNet-S和TransXNet-B表现出优秀的模型可扩展性,分别实现了83.8%和84.6%的Top-1准确率,同时计算成本合理。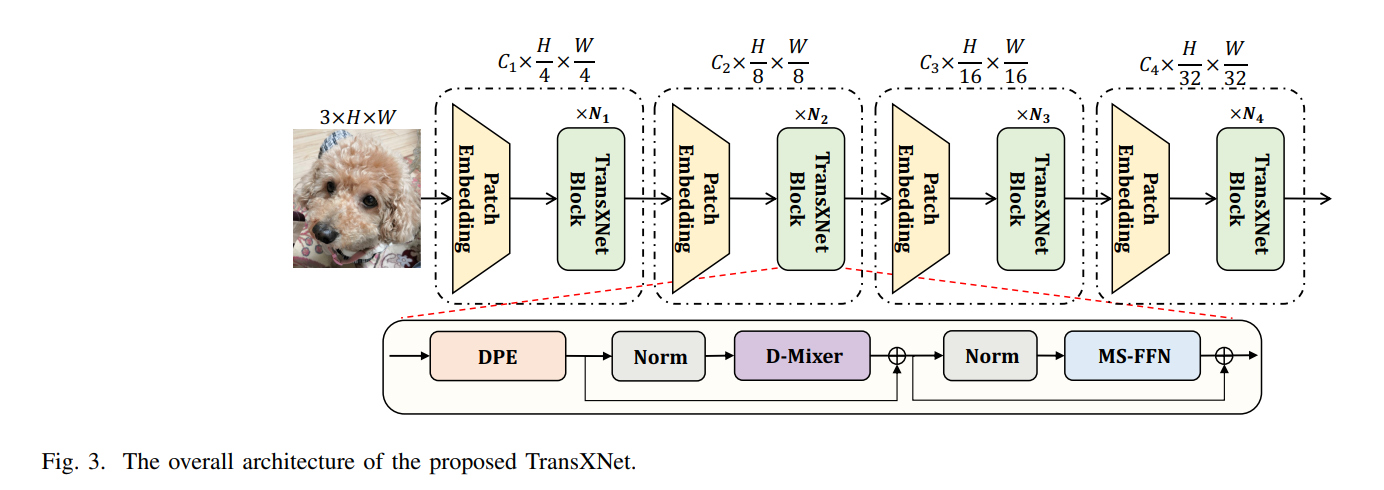
RT-DETR改进策略:AKConv即插即用,轻松涨点
RT-DETR改进策略:AKConv即插即用,轻松涨点
提出了一种算法,用于生成任意尺寸卷积核的初始采样坐标。与常规卷积核相比,提出的AKConv实现了不规则卷积核的函数来提取特征,为各种变化目标提供具有任意采样形状和尺寸的卷积核,弥补了常规卷积的不足。在COCO2017和VisDrone-DET2021上进行目标检测实验,并进行了比较实验。结果表明,提出的AKConv方法在目标检测方面具有更好的性能。
RT-DETR改进策略:UniRepLKNet,大核卷积的最新成果,轻量高效的首选(全网首发)
RT-DETR改进策略:UniRepLKNet,大核卷积的最新成果,轻量高效的首选(全网首发)
将UniRepLKNet应用到RT-DERT的改进中,经过测试,涨点明显,运算量也有下降!
RT-DETR详解与实战
RT-DETR详解与实战
RT-DETR:在实时目标检测上,DETRs打败了yolo
RT-DETR:在实时目标检测上,DETRs打败了yolo
论文:https://arxiv.org/pdf/2304.08069.pdf
最近,基于Transformer的端到端检测器(DETRs)取得了显著的成果。然而,DETRs的高计算成本限制了它们的实际应用,并阻止了它们充分利用无后处理(例如非极大值抑制(NMS))的优势。在本文中,我们首先分析了NMS对现有实时目标检测器的准确性和速度的负面影响,并建立了端到端的实时速度基准。为了解决上述问题,我们提出了第一个实时端到端目标检测器——RT-DETR(Real-Time Detection Transformer)。具体来说,我们设计了一个高效的混合编码器,通过分离尺度内的相互作用和跨尺度融合来有效地处理多尺度特征,并提出了IoU-aware查询选择来进一步提高性能,为解码器提供更高质量的初始目标查询。此外,我们提出的检测器支持使用不同的解码层进行灵活的推理速度调整,无需重新训练,这有利于在各种实时场景中的实际应用。我们的RT-DETR-L在COCO val2017上实现了53.0%的AP,在T4 GPU上实现了114 FPS,而RT-DETR-X实现了54.8%的AP和74 FPS,在速度和准确性方面都优于相同规模的YOLO检测器。此外,我们的RT-DETR-R50实现了53.1%的AP和108 FPS,在准确性方面比DINO-DeformableDETR-R50高出2.2%,在FPS方面高出约21倍。源代码和预训练模型可在https://github.com/lyuwenyu/RT-DETR上获得。
DETR:End-to-End Object Detection with Transformers
DETR:End-to-End Object Detection with Transformers
https://arxiv.org/pdf/2005.12872.pdf
本文提出一种新方法,将目标检测视为直接的集合预测问题。该方法简化了检测管道,有效地消除了对许多手工设计组件的需要,如非最大抑制程序或锚点生成,这些组件显式编码了我们关于任务的先验知识。新框架称为检测TRansformer或DETR,其主要成分是基于集合的全局损失,通过二分图匹配强制进行独特的预测,以及TRansformer编码器-解码器架构。给定一个固定的小集合的学习对象查询,DETR对对象和全局图像上下文的关系进行推理,以直接并行输出最终的预测集。与许多其他现代检测器不同,新模型在概念上很简单,不需要专门的库。在具有挑战性的COCO目标检测数据集上,DETR展示了与完善的、高度优化的Faster RCNN基线相当的准确性和运行时间性能。此外,DETR易于推广,以统一的方式产生全景分割。实验表明,它明显优于有竞争力的基线。训练代码和预训练模型可以在https://github.com/facebookresearch/detr上找到。
版权归原作者 静静AI学堂 所有, 如有侵权,请联系我们删除。