
第一部分:低层次视觉
1、滤波器
2、梯度—>边缘;梯度—>能量(线裁剪)
3、模板匹配;二值图像分析
4、纹理
第二部分:中层次视觉
5、霍夫变换
6、分割
7、局部不变特征——检测、描述和匹配
8、立体
第三部分:高层次的视觉
9、实例识别
10、监督分类的对象检测
11、支持向量机和核函数
12、深度学习的视觉识别
1、线性滤波器
滤波器的用途:
增强图像(去噪,调整大小等)
提取信息(纹理,边缘等)
检测模式(模板匹配)
数码相机的传感器阵列中的每个单元都是将光子转换为电子的光敏二极管。
拜耳阵列:绿光占50%,红、蓝占25%
常见的图像噪声类型:
1)椒盐噪声:随机出现的黑白像素
2)脉冲噪声:随机出现的白色像素
3)高斯噪声:由高斯(正态)分布得出的强度变化的脉冲噪声
噪声使得相同场景的多张图像之间也会不同,所以需要降噪,给出真实强度的估计。
常用的线性滤波器:相关、均值、高斯
1)相关(correlation)滤波:
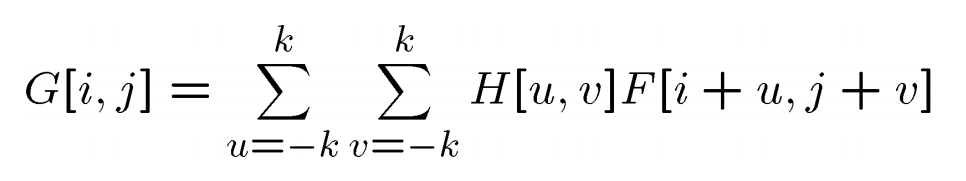
其中H[u,v]是针对每一个邻近像素点赋予的权重(相关核)。
记作
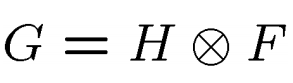
进行的是互相关运算,计算核和对应位置元素的乘积,再把结果加到一起,作为该中心元素新值
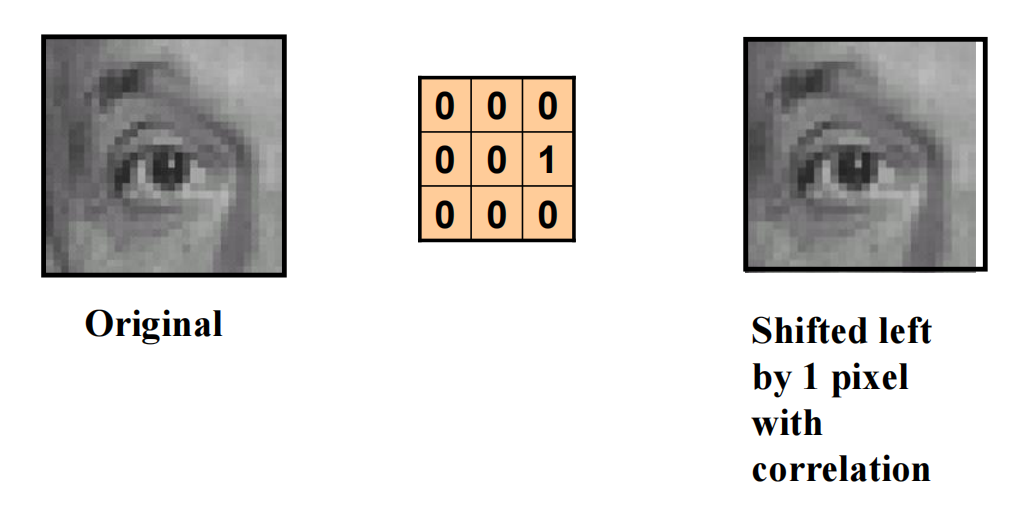
应用:移动图像
2)均值滤波:
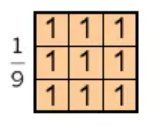
临近元素权重相同并归一化。
应用:锐化滤波器——突出与邻域平均值的差异

3)高斯滤波:
权重函数为高斯函数,属于低通滤波,可以使图像变光滑,抑制高频噪声。
参数σ(sigma)越大,图像越平滑。

常用的非线性滤波器:中值滤波器
—没有引入新的像素值
—适合处理脉冲噪声、椒盐噪声
—能够保留边缘信息
需要考虑的问题:边界问题(边界的像素无法参与到上述操作)
在matlab中,针对此问题,对于输出结果,有以下三种操作:
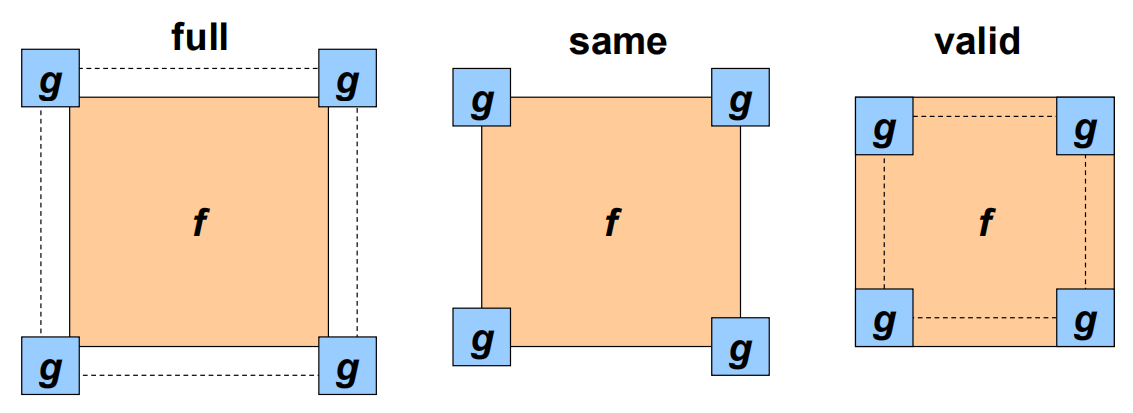
当过滤器窗口超出图像边缘,图像需要外推,有以下几种方法:
1)clip filter(四周加黑边)
2)wrap around(用另一侧像素来填充这一侧的扩充边界)
3)copy edge(复制最边缘像素)
4)reflect across edge(以最边缘像素为轴,对称复制像素)
卷积(convolution):
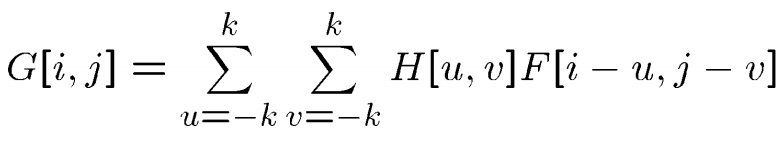
记作
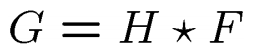
对比相关,卷积同样是将计算核和对应位置元素的乘积,再把结果加到一起,作为该中心元素新值
但是需要将核在两个维度上都翻转(上下以及左右),等价于绕中心旋转180度
但因为我们平时接触的卷积核大都是关于x轴或y轴对称的,所以卷积和互相关在这种情况下没什么区别。
某些情况下,核函数可以进行分解,使计算更高效

2、梯度—>边缘;梯度—>能量(线裁剪);
边缘检测的核心思想:寻找强烈的梯度
步骤一:图像平滑去噪,克服噪声的影响(高斯滤波的sigma可以影响检测到的边缘的尺度)
步骤二:利用梯度检测边缘
卷积的导数定理:
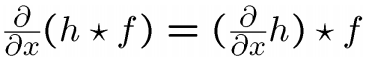
h为核函数,f为图像,意思是对图像先进行卷积操作,再求导获取边缘信息,
可以转换成先直接对核函数求导,求得的结果再与图像进行卷积操作。
prewitt算子:

sobel算子:
—Sobel算子能提供更为准确的边缘方向信息
—对噪声有平滑作用,结果会具有更多的抗噪性,常用于噪声较多、灰度渐变的图像

Laplacian算子:
除了检测线,有时候也需要检测点,这就需要用二阶导数进行检测,著名的就是拉普拉斯(Laplacian)算子。
Laplacian算子分为四邻域和八邻域,四邻域是对邻域中心像素的四个方向求梯度,八邻域是对八个方向求梯度。

通过Laplacian算子的模板可以发现:
1)当邻域内像素灰度相同时,模板的卷积运算结果为0;
2)当中心像素灰度高于邻域内其他像素的平均灰度时,模板的卷积运算结果为正数;
3)当中心像素的灰度低于邻域内其他像素的平均灰度时,模板的卷积为负数。对卷积运算的结果用适当的衰弱因子处理并加在原中心像素上,就可以实现图像的锐化处理。
优缺点:
对图像中的阶跃型边缘点定位准确;
但该算子对噪声非常敏感,它使噪声成分得到加强,使用使需要注意先进行降噪。
线裁剪:
根据梯度计算能量大小,以八连通确定图像中最小的总能量路径。

常规边缘检测步骤:
1)平滑:抑制噪声
2)边缘增强:通过滤波器增强对比度
3)计算图像梯度,计算可能边缘
4)边缘定位:设置阈值,高于阈值则是边,低于阈值则是噪声
canny边缘检测思路:
1)图像降噪:去除噪声,因为噪声是灰度变化很大的地方,容易被识别为伪边缘。
2)计算图像梯度,得到可能边缘:边缘也是灰度变化明显的地方,这一步就有了所有可能是边缘的集合。
3)非极大值抑制:通常灰度变化大的地方都比较集中,将邻域内梯度方向上灰度变化最大的像素保留下来,其它的不保留,将有多个像素宽的边缘变成一个单像素宽的边缘。
4)双阈值筛选:设置一个双阈值,即低阈值(low),高阈值(high)。灰度变化大于high的,设置为强边缘像素;低于low的,剔除;在low和high之间的设置为弱边缘。进一步判断弱边缘像素,如果其邻域内有强边缘像素,则保留,如果没有,则剔除。
canny边缘伪代码:
1)高斯平滑:对灰度图像进行高斯滤波,去除噪声。
2)计算梯度:输入高斯平滑后的灰度图像,用sobel算子计算的每个像素点在水平和竖直方向上的导数Gx、Gy,得出梯度向量(Gx,Gy),计算梯度的值G=sqrt(Gx^2+Gy^2)和方向theta=arctan(Gy/Gx)。
3)非极大值抑制:将每个像素点的梯度值与其梯度方向上的相邻像素比较,如果当前像素值非极大值,则将其置0。
4)双阈值检测:设置一个双阈值,即低阈值和高阈值。像素点梯度值大于高阈值的,置为255;低于低阈值的,置为0;在高阈值和低阈值之间的设置为弱边缘,进一步判断其八邻域内的像素,若有梯度值高于高阈值的像素,则置255,如果没有,则置0。
3、模板匹配;二值图像分析
模板匹配:
将滤波器充当模板,使用归一化(控制相对亮度)的互相关分数去找到待寻找图像中的给定模式

使用倒角距离进行模板匹配:(此时模板和图像都是二值边缘图像)
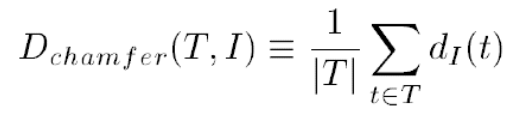
其中

所以倒角距离即模板T中一点t和图像I中某点最小距离的平均值。
距离变换:
距离变换是一个函数D(p),非负数D(p)对应像素p距离图像I中最近特征的距离。
左边是特征,右边是距离变换的结果
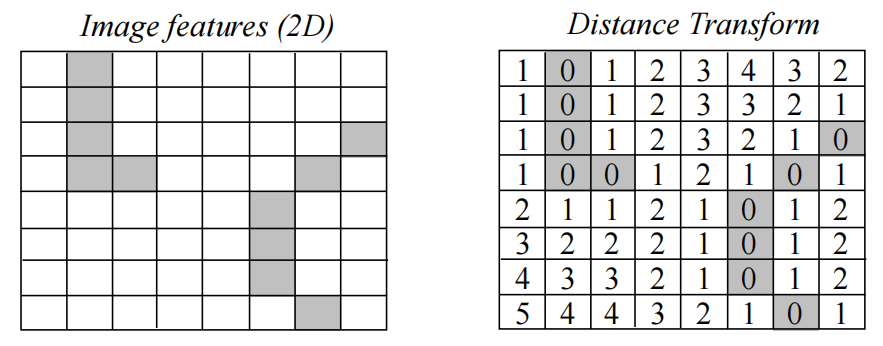
将图像的特征点叠加在模板的距离变换上,即可计算倒角距离

特点:对尺度和旋转敏感;容忍小的形状变化;需要大量的模板;是匹配形状的廉价方式
二值图像分析:
基本步骤:
1)通过阈值将图像转换为二值图像
2)形态学算子(扩张、侵蚀等)清理二值图像
3)提取不同的区域(四连通、八连通区域标记算法)
4)描述区域的属性(像素数、质心、边界框)
形态学算子:
diliation——扩张(有1出1,全0出0)
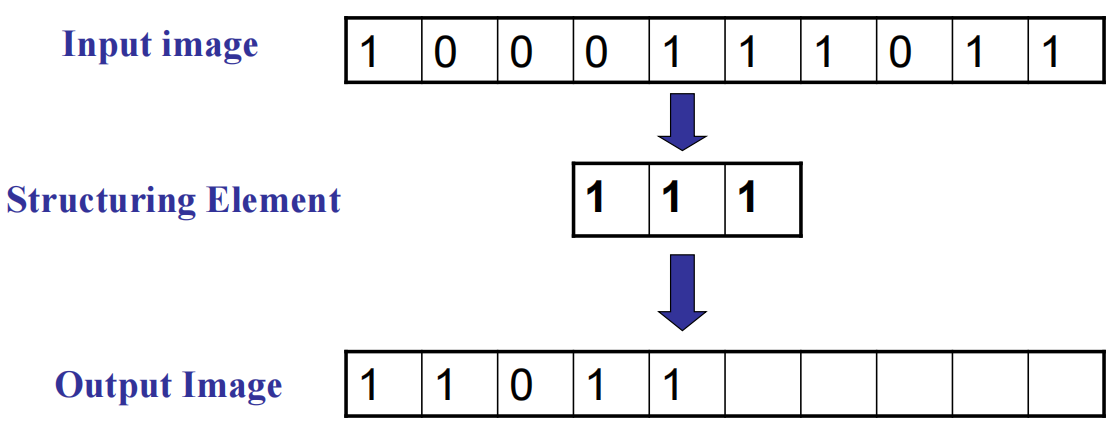
erosion——侵蚀(全1出1,有0出0)
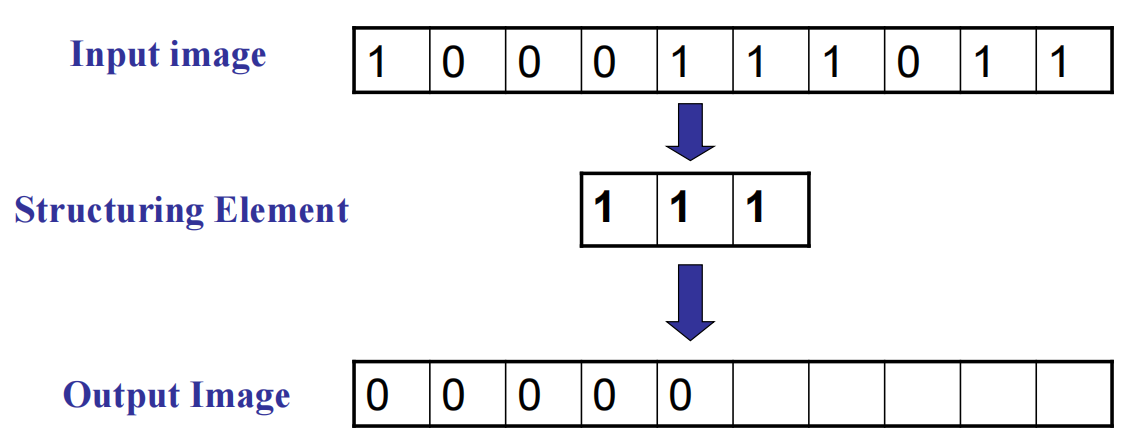
opening——开操作(先侵蚀,再扩张):移除小物体,但保留原有形状

closing——闭操作(先膨胀,再腐蚀):填洞,但保留原有形状

二值图像处理的优缺点:
优点:计算快速,易于存储;有简单的处理技巧可用;相关的一些描述很有用。
缺点:很难得到清晰的轮廓;现实中的场景有很多噪声;表示比较粗糙;不是三维的信息。
种子填充法(标记二值图像连通区域)伪代码:
假设二值图像为image,种子点为seed,已标记的点为marked
将seed点加入marked集合
将seed点的邻域中的所有点加入待处理队列queue
当queue不为空时
3.1. 取出queue的第一个点p
3.2. 如果p点未被标记且为前景点,则将p点加入marked集合
3.3. 将p点的邻域中的所有点加入queue
- 返回marked集合
4、纹理
与纹理相关的任务:
1)形状来自纹理:从图像纹理估计表面方向或形状
2)从纹理线索进行分割/分类:纹理一致的图像区域分组
3)合成:生成新的纹理块/图像
总结:
1)纹理是一种有用的属性,通常是材料的指示,外观线索
2)纹理表示试图总结局部结构的重复模式
3)滤波器组(filter bank)用于测量局部邻域中冗余结构,每个像素的特征向量是多维的

4)邻域统计数据可以用于“采样”或合成新的纹理区域,这是基于实例的技术
5、霍夫变换
思路:通过为每个可能的子集拟合模型来检查所有特征的组合是不可行的。所以使用投票(voting)方法,如霍夫变换,找到可能的模型参数,而不搜索所有的特征组合。
霍夫变换直线检测伪代码:
1)彩色图像转换为灰度图
2)高斯滤波去噪
3)Canny边缘检测
4)将边缘像素坐标值变换到极坐标系中,会对应一系列点(rho,theta),并且该点计数加一,计数值超过阈值且大于直线间最小距离的点就对应图像中的一条直线
5)在图像上绘制直线
优缺点:
所有的点都是独立处理的,所以可以应付遮挡、缝隙;对噪声有一定的鲁棒性。
随着模型参数的增加,搜索时间的复杂度呈指数增长;非目标形状会在参数空间中产生伪峰。
广义霍夫变换:
通过边界点和参考点定义模型形状。

6、分割
Gestalt 理论:图像整体包含的信息大于部分信息的总和,不同部分之间的关系可以产生出新的特征。
自底向上的聚类分割:聚类算法是无监督学习——需要数据,但不需要标签
-算法:k-means;mean shift(均值漂移);normolized cuts(归一化割)
-基于特征:颜色,纹理

k-means伪代码:
1.选择k个点作为初始聚类中心;
2.计算数据集中的每一个点x与聚类中心的距离,将其分配到最近的簇;
3.重新计算每个簇的均值,将距离均值最近的点更新为聚类中心;
4.重复2和3两个步骤直到K个簇收敛或达到最大迭代次数;
优缺点:
简单,计算快速;收敛到聚类内平方误差的局部最小值
k值的设定;对初始中心敏感;对异常值敏感;检测的是球形聚类;假设平均数可以计算
均值漂移算法:在特征空间中寻找模式或局部密度极大值
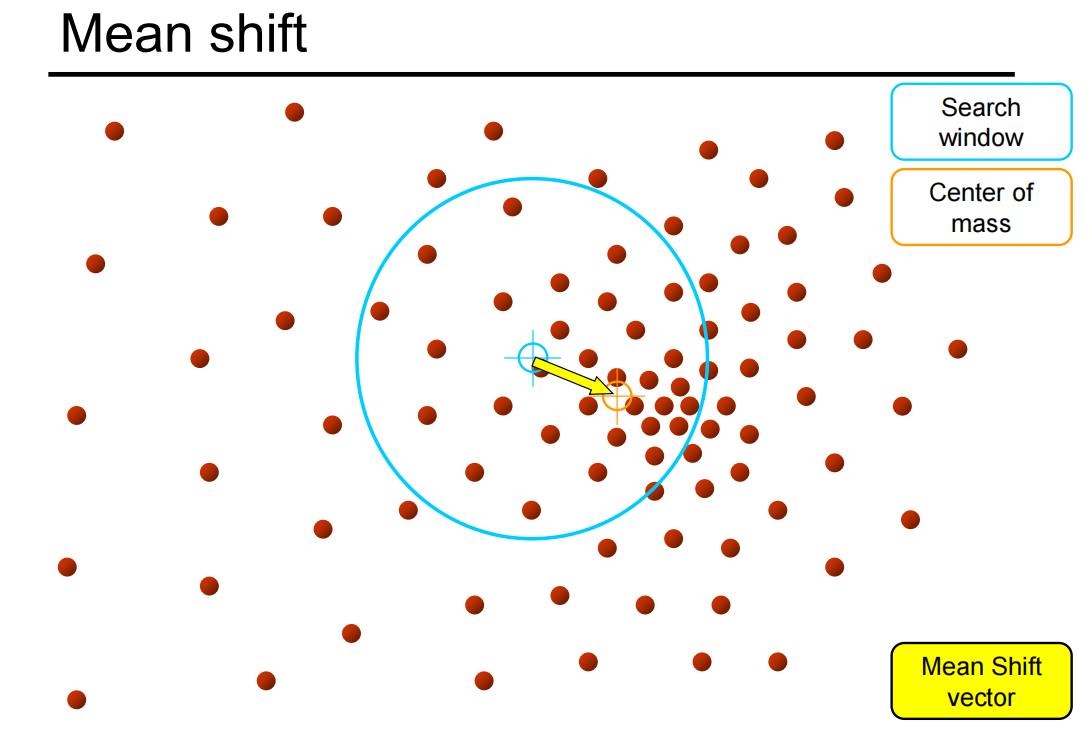
mean shift实现图像分割的伪代码:
INPUT: 图像I,像素点集P,邻域半径r
OUTPUT: 图像I的分割结果
1)对于图像I中的每个像素点p,初始化聚类中心
2)用高斯核函数计算其在邻域半径r内的偏移均值m
3)将聚类中心移动到偏移均值m的位置
4)重复步骤2、3,直到聚类中心收敛
5)根据最终的聚类中心,分割像素到不同类别,返回分割结果
优缺点:
不会在聚类上假设形状;一个参数选择(窗口大小);通用技术;找到多种模式;
窗口大小的选择;不能很好地缩放特征空间的维度
基于图像分割——归一化割(normolized cuts):断开相似度低(权重低)的链接
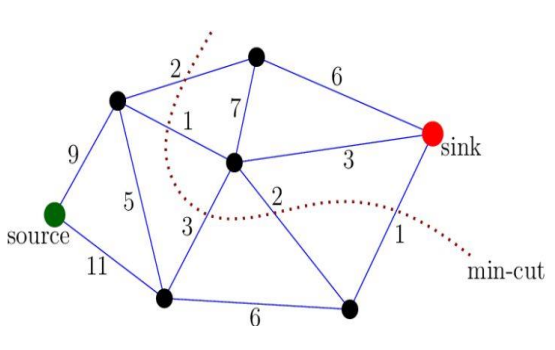
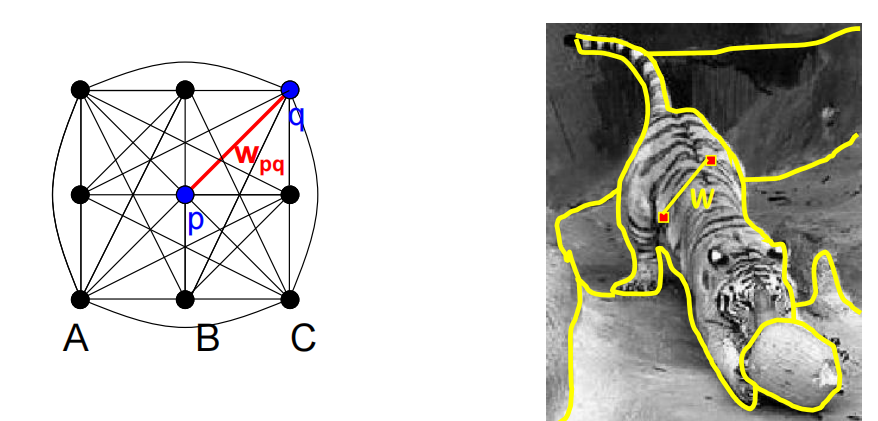
优缺点:
通用框架,可以灵活地选择计算节点间权重的函数;不需要数据分布的模型;
时间复杂度可能高;平衡分区的偏好
7、局部不变特征——检测、描述和匹配
Global feature(全局特征):
颜色特征、纹理特征、边缘特征,全局特征容易受到光照、形变、视点不同、尺度、遮挡的影响。
Local feature(局部特征):
可重复性——在几张图像中可以发现相同的特征,尽管几何和测光的变化;
显著性—每个特征都有不同的描述;
紧凑性和高效性——特征比图像像素少得多;
局部性——特征在图像中占据相对较小的区域;对杂乱和遮挡具有鲁棒性
Harris corner detection(角点检测):检测局部不变特征
窗口内的图像不同,则x、y导数的分布不同
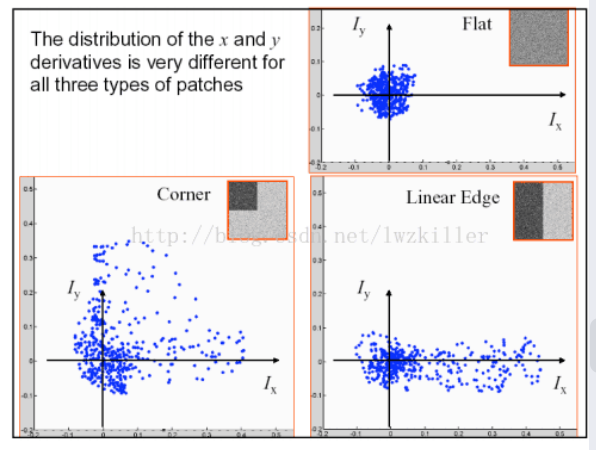
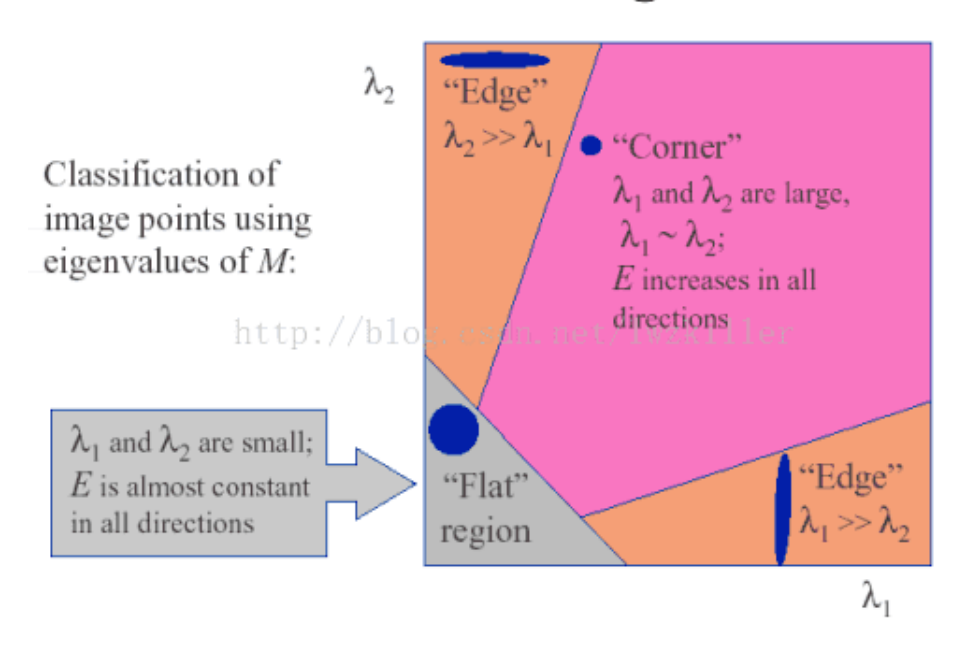
角点响应函数:

步骤:
1)计算每个图像窗口的M矩阵,得到它们的角点响应函数值
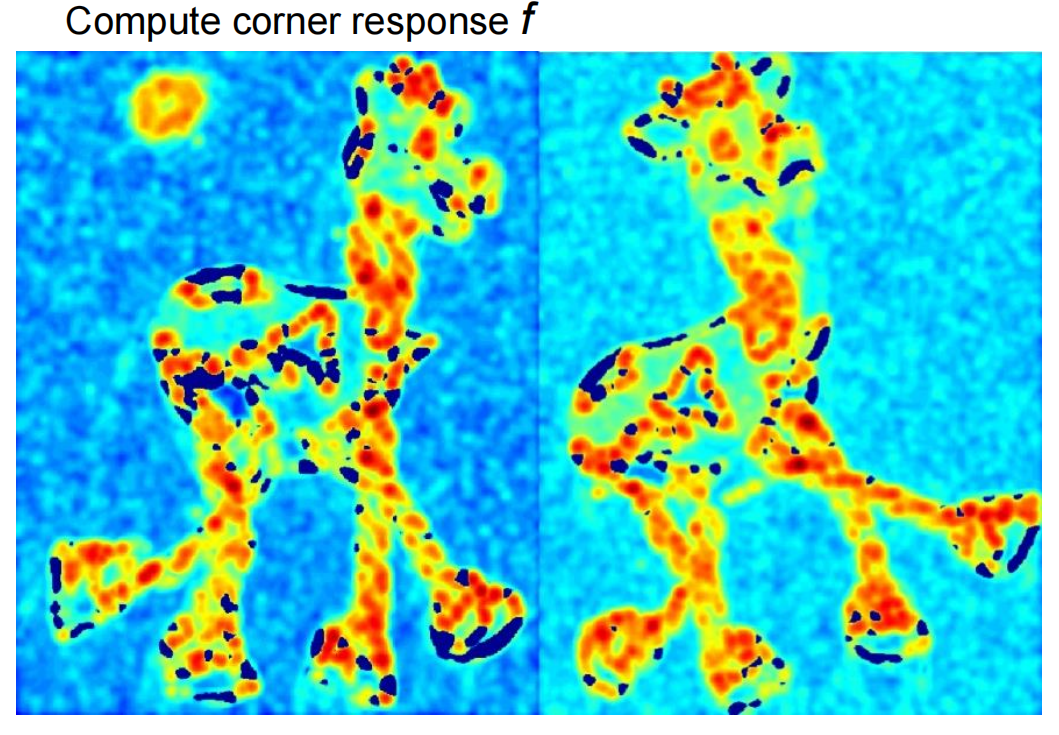
2)寻找周边窗口角点响应较大的点(f>threshold)

3)取局部极大值点,即进行非极大值抑制
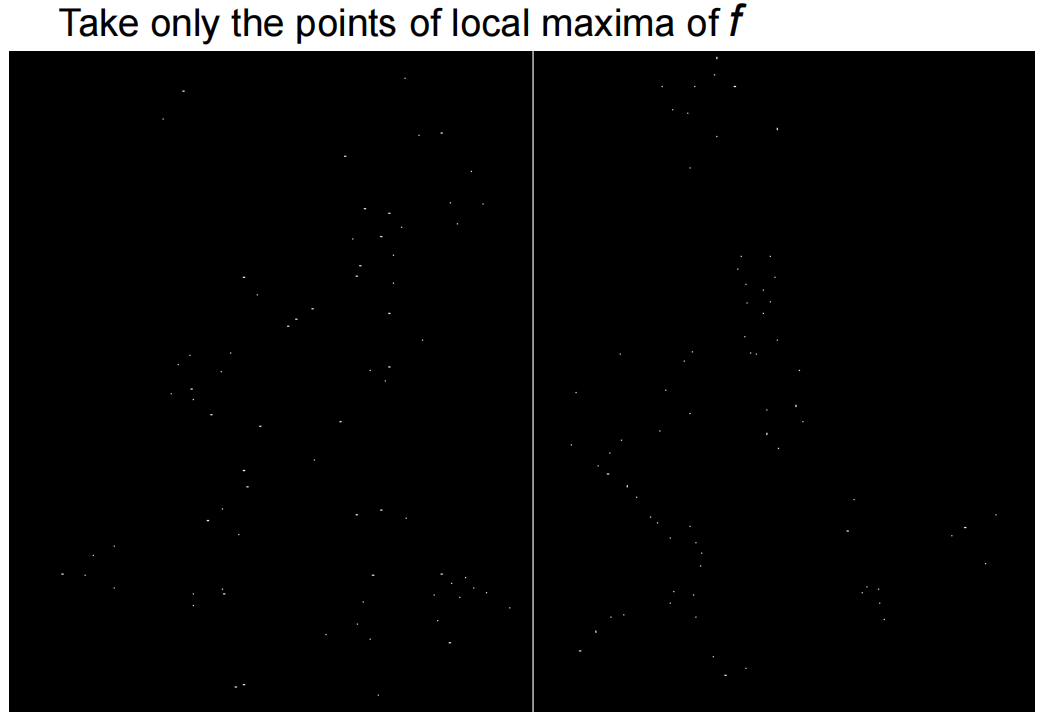
性质:具有旋转不变性,但是不具有尺度不变性
Laplacian of Gaussian:Blob detection(斑点检测)——自动尺度选择
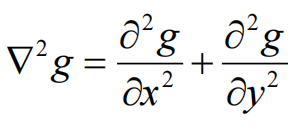
尺度参数sigma越大,则对图像进行相应的下采样
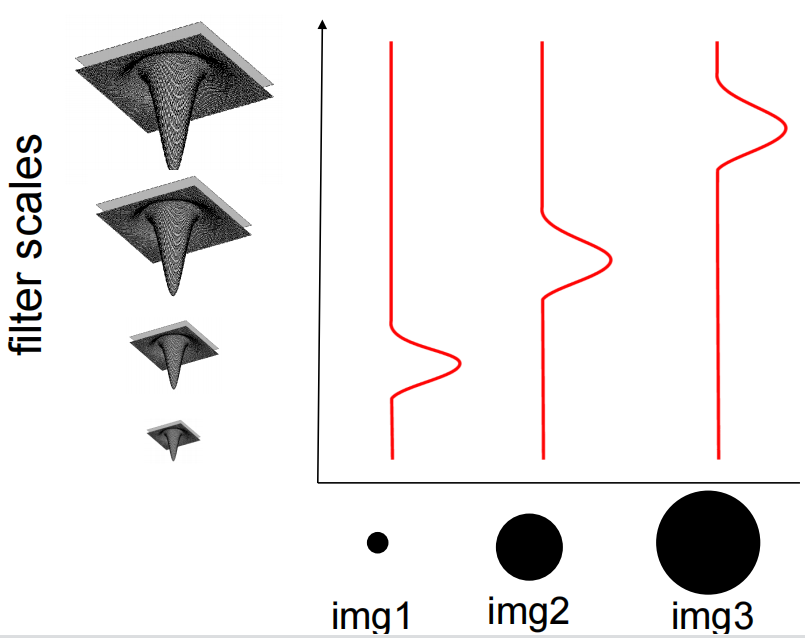
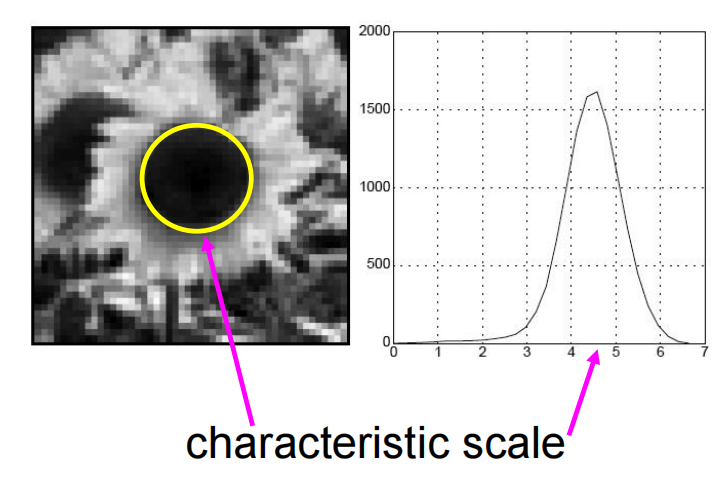
我们将特征尺度定义为产生Laplacian响应峰值的尺度
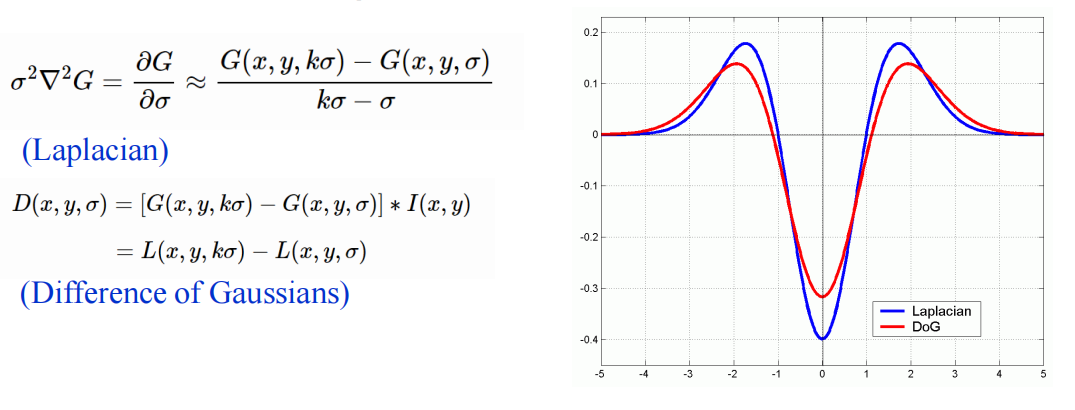
我们可以用高斯的差分(DoG)来近似高斯的拉普拉斯(LoG);执行起来更有效率。
SIFT(尺度不变特征变换):
local descriptor(局部特征描述子)
性质:具有旋转不变性和尺度不变性;对光照变化、相机的视角、遮挡和杂乱有一定的鲁棒性。
SIFT特征提取(具有尺度不变特性的关键点检测器的伪代码):
1)尺度空间的构建:通过高斯模糊和下采样逐层生成低分辨率的图像,构建尺度空间——高斯金字塔
2)极值点的检测:在每个尺度空间通过高斯差分函数检测图像中的极值点
3)关键点的精确定位:通过计算高斯函数的梯度向量来确定关键字的位置
4)关键点的方向分配:基于关键点邻域计算梯度值和方向的,为关键点提供方向,相当于提供了方向不变性
5)关键点描述子的生成:通过高斯加权处理和梯度直方图统计,生成描述每个关键点的特征向量
对两张图片进行特征匹配的步骤:
1)找到一组独特的关键点
2)在每个关键点周围定义一个区域
3)提取区域内容并归一化
4)从归一化区域计算局部特征描述子
5)匹配本地描述子
8、立体
使用SAD(灰度差绝对值之和)算法实现立体匹配(通过视差图获得深度图)的伪代码:
输入:一幅左图,一幅右图,且两图已校正实现对准
1)用SAD窗口分别覆盖左图和右图的部分区域
2)计算左图像像素与右图像像素的像素差值
3)计算该组像素差值的绝对值的和
4)对于每组像素,如果像素差值的和最小,则记录该组像素的深度信息
5)将深度信息输出到图片
9、实例识别
基于尺度不变特征SIFT的图像检索系统的伪代码:
输入:图像集合 I,待查询的图像 Iq,SIFT 特征描述符的阈值 T
输出:与查询图像最相似的图像 Ism
预处理图像集合I,对每张图像提取它们的 SIFT 特征描述子,保存在特征数据库中
对查询图像 Iq 提取 SIFT 特征描述子
针对每个查询图像中的描述子,计算它们与数据库中描述子的匹配程度
将匹配程度高于阈值的数据库中的图像加入到候选图像集合中
计算候选图像集合中的每个图像和查询图像的相似度
将具有最高相似度的图像作为结果返回
总结:
匹配局部不变特征:不仅可以为多视图提供匹配,还可以找到物体和场景。
词袋(不够详细,请自己补充):量化特征空间,形成离散的视觉词集
—通过单词分布来总结图像
—索引单个单词
倒排索引:预先计算索引,在查询时实现更快的搜索
通过对齐来识别实例:匹配局部特征,然后进行空间验证
10、监督分类的对象检测
Viola-Jones人脸检测主要思想:
1)在感兴趣的窗口内,用高效可计算的“矩形”特征表示局部纹理
2)选择判别特征作为弱分类器
3)通过弱分类器的线性组合构成强分类器
4)把若干个强分类器级联起来,一开始使用少量的特征将大部分的非人脸区域剔除掉,后面再利用更复杂的特征将更复杂的非人脸区域剔除掉
伪代码:
输入:原始测试图像
输出:带标志框的图像
for i<—1 to 图像金字塔的尺度数 do
下采样image创建image’
计算积分图像image‘’
for j<—1 to 子窗口的位移步数 do
for k<—1 to 级联分类器的级数 do
for l<—1 to k级滤波器的个数 do
滤波器检测子窗口
累计滤波器输出
end for
if 累计数低于每级的阈值 then
拒绝子窗口作为一个脸
Break这级的循环
end if
end for
if 子窗口通过了所有级的检查 then
接受该子窗口作为一个脸
end if
end for
end for
总结:一种开创性的实时物体检测方法;训练很慢,但检测很快。
11、支持向量机和核函数
K最近邻(k-Nearest Neighbor,KNN)分类算法:
思想:如果一个待分类样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。 KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在只依据最邻近的几个样本的类别来决定待分类的样本所属的类别。

SVM通过定义核函数代替高维空间的内积运算
用于识别的SVM(支持向量机):
1) 定义每个例子的表示形式
2) 选择一个核函数
3)在标记的示例之间两两计算核值
4) 使用这个“核矩阵”来求解支持向量机的支持向量和权重
5) 分类一个新例子:计算新的输入和支持向量之间的核值,应用权重,检查输出的符号。
将SVM用于多分类:
1)训练SVM(每个类vs剩余的部分),测试时将决策值最高的SVM对应的类别赋值给它
2)训练SVM(每一对类),每个SVM投票给两个类中的一个类
优缺点:
基于核函数的框架非常强大和灵活;小的训练样本效果也很好;
需要组合多个二分类SVM来实现多分类;需要选择最好的核函数;计算量较大;对于大规模问题,需要学习很长时间。
12、深度学习的视觉识别
神经网络/多层感知器
—将神经网络视为特征的学习层次结构
卷积神经网络
—网络架构说明图像结构
—像素的“端到端”识别
—结合大(标签)数据和大量计算,在基准测试、图像分类等方面取得了重大成功
版权归原作者 Mr.Junnnnn 所有, 如有侵权,请联系我们删除。