
机器学习的研究使我们进入了研究各种模式和行为的过程。它使我们能够构建可以研究封闭环境的模型。预测能力通常遵循模型训练过程。这是我们在训练模型时需要经常问的一个重要问题。还有另一个问题需要回答——多少数据足以帮助模型理解分布,以便我们有一个好的表示?本章将针对这些重要问题给出示例和概念。我们正在讨论计算机视觉中的异常检测。
我们有一个学习数据分布的机器学习模型,并最终可用于对未知数据集进行预测。学习过程仅限于我们用于训练的数据所代表的分布。训练过程完成后,少数样本可能会与大多数行为相矛盾。我们必须注意,检测异常会受到一些观点的影响,例如分布需要多宽松。例如,抛光钢板可以有几排来自机器的直线。可能会有轻微的划痕,但这些仍可能不被视为有缺陷(异常)。在其他情况下,这些划痕或突变可能被视为异常。因此,对于所有场景,异常都需要有一个阈值。
异常检测在图像中有很多应用,例如,检测建筑工地金属板的异常。异常检测可用于发现传送带上的异常情况。
异常检测
与所有其他领域一样,视觉分析中的异常检测可分为两种主要类型:
新颖性检测:在训练过程中,模型会受到标准事件分布产生的数据的影响。当我们对未知样本进行测试或预测时,算法应该会发现异常数据。在这个过程中,假设数据没有任何非标准数据。这是半监督学习方法的一个例子。
离群值检测:在这种情况下,该算法受标准和非标准数据的影响。由于原则上标准数据将集中,因此算法会学习它并忽略异常值。我们可以举一个决策树的例子,其中的分支总是会在分裂过程中更早地尝试分离异常值。这种方法中的数据被标准和非标准数据污染。该算法计算出哪些数据点是异常值,哪些是异常值。这是一种无监督的训练方式。
我们有多种方法来检测异常值或新颖性。我们可以使用总体均值和标准差等统计方法来查找异常值。然而,在那些场景中,分布知识是必须的。在机器学习方法中,我们有一些算法可以帮助我们进行异常检测。
Local outlier factor:算法计算出一个量化局部密度偏差的值。它试图找到与其邻居相比密度较低的样本。
Isolation forest:有一些方法可以使用基于决策的迭代分裂,可以用来确定样本中的异常值。如果我们可以利用基于决策树或随机森林集合的算法,我们可以很容易地得出结论,落在随机森林较短路径上的样本是异常值。
One class SVM:它可以被认为是SVM类的扩展,其中在确定阈值时,可以检查概率分布的支持度,从而分离过程中的异常值。
让我们看看计算机视觉领域的一些应用。
Unsupervised density estimation:该算法试图估计特征或训练图像的概率分布。一旦模型知道分布,对于所有未知样本,它会尝试确定样本与分布的差异。
Unsupervised image reconstruction:训练编码器-解码器架构的一般过程。它让网络学习向量化的潜在特征并重建原始图像,但有一些损失。与异常图像相比,正常图像的重建损失会更小。
One class anomaly detection:这种方法类似于前面讨论的One class SVM。该算法尝试估计决策边界以将正常类与异常类分开。
生成类算法可用于检测异常,并且已由多位研究人员建立。现在我们已经了解了一些基本概念,让我们看一个异常检测的例子。
其中一些方法包括:
使用经过最后几层训练的预训练模型进行异常分类
编码和解码方法
异常图像分类并使用特征图定位图像中的异常
方法 1:使用预训练分类模型
从给定的图像数据集中寻找异常图像可以被认为是二值图像分类任务,即根据训练数据集判断图像是否异常。这里使用一种名为 VGG-16 的成熟架构来训练最后几层。
VGG-16 架构包含 16 层,其中 13 层是卷积层,最后三层是全连接层。该网络经过训练,可以预测总共 1,000 个类别中的输入类别。
在本方法中,预训练权重用于前十个卷积层。最后一层用于对自定义数据集进行模型训练。输出被分类为两类之一。图7-1中突出显示的框用于训练自定义数据集。
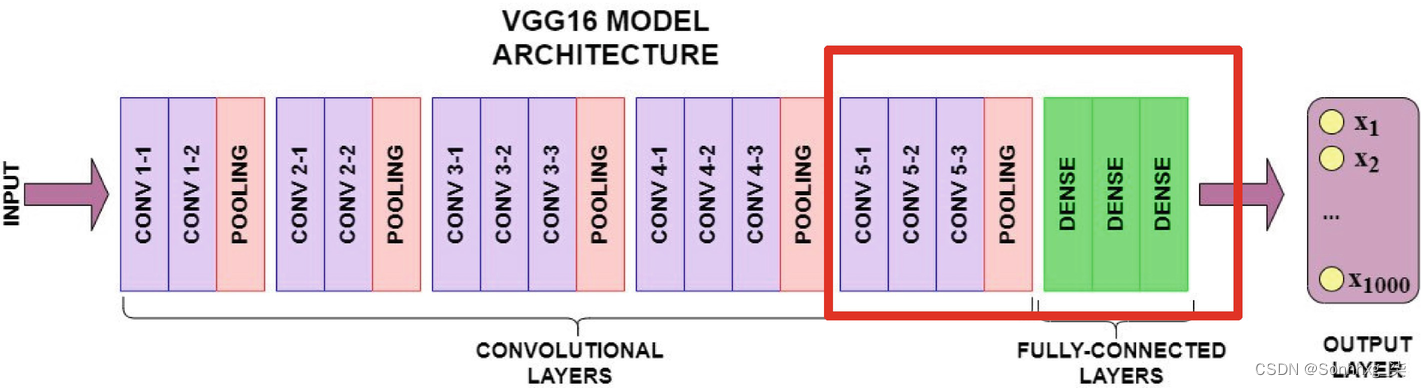
图 7-1VGG -16 架构
第 1 步:导入所需的库
# 导入 torch
import torch
import torchvision
import matplotlib.pyplot as plt
# 导入 time,os etc
import time
import os
import numpy as np
import random
from distutils.version import LooseVersion as Version
from itertools import product
第 2 步:创建种子函数和确定性函数
这些函数有助于为所有迭代生成相同的随机数。
def seed_setting(sd):
os.environ["PL_GLOBAL_SEED"] = str(sd)
random.seed(sd)
np.random.seed(sd)
torch.manual_seed(sd)
torch.cuda.manual_seed_all(sd)
def fn_det_setting():
# 检查cuda是否可用
if torch.cuda.is_available():
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# 检查 torch 版本
if torch.__version__ <= Version("1.7"):
torch.fn_det_setting(True)
else:
torch.use_deterministic_algorithms(True)
第 3 步:设置超参数
# 设置 seed, batch size
RNDM_SEED = 245
btch_input_sz = 128
epch_nmbr = 25
DEVICE = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')
seed_setting(RNDM_SEED)
#fn_det_setting() 这可能不适用于 Gpu,因为某些算法在 Gpu 上不是确定性的。/
第 4 步:导入数据集
这是训练数据:
tr_ds_path = "/content/drive/MyDrive/car_img/tr" #Training Images
这是验证数据:
vd_ds_path = "/content/drive/MyDrive/car_img/vds" #Validation Images
这是测试数据:
ts_ds_path = "/content/drive/MyDrive/car_img/ts" #Test Images
第 5 步:图像预处理阶段
图像变换包括以下步骤:
图像大小调整:保持训练、测试和验证数据集中的通用图像大小
图像裁剪:裁剪图像的边缘
将图像转换为张量:用于 PyTorch 实现
图像归一化:为了更快的损失收敛
import torch.utils.data as data
tr_data_trans = torchvision.transforms.Compose([
torchvision.transforms.Resize((70, 70)),
torchvision.transforms.RandomCrop((64, 64)),
torchvision.transforms.ToTensor(), #it converts data in the range 0-255 to 0-1.
torchvision.transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
validation_data_trans = torchvision.transforms.Compose([
torchvision.transforms.Resize((70, 70)),
torchvision.transforms.CenterCrop((64, 64)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
tst_data_transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((70, 70)),
torchvision.transforms.CenterCrop((64, 64)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
DataLoader函数通过并行传递数据来提供帮助,从而使数据加载过程更快。
train_ds_cln = torchvision.datasets.ImageFolder(root=tr_ds_path, transform= tr_data_trans)
train_loader_cln = data.DataLoader(train_ds_cln, btch_input_sz=206, shuffle=True)
test_ds_cln = torchvision.datasets.ImageFolder(root=ts_ds_path, transform= tst_data_transform)
test_loader_cln = data.DataLoader(test_ds_cln, btch_input_sz=206, shuffle=True)
valid_ds_cln = torchvision.datasets.ImageFolder(root=vd_ds_path, transform= validation_data_trans)
valid_loader_cln = data.DataLoader(valid_ds_cln, btch_input_sz=63, shuffle=True)
# 检查数据集
for images, labels in train_loader_cln:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
print('Class labels of 10 examples:', labels[:10])
break
这是输出:
Image batch dimensions: torch.Size([206, 3, 64, 64])
Image label dimensions: torch.Size([206])
Class labels of 10 examples: tensor([1, 0, 0, 1, 0, 0, 1, 1, 1, 1])
这是训练数据集:
for images, labels in train_loader_cln:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
print('Class labels of 10 examples:', labels[:10])
break
这是输出:
Image batch dimensions: torch.Size([206, 3, 64, 64])
Image label dimensions: torch.Size([206])
Class labels of 10 examples: tensor([0, 1, 0, 1, 1, 1, 1, 1, 0, 1])
tr_ds = images
tr_ds.shape
这是输出:
torch.Size([206, 3, 64, 64])
tr_label = labels
tr_label.shape
这是输出:
torch.Size([206])
这是验证数据集:
for images, labels in valid_loader_cln:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
print('Class labels of 10 examples:', labels[:10])
break
这是输出:
Image batch dimensions: torch.Size([63, 3, 64, 64])
Image label dimensions: torch.Size([63])
Class labels of 10 examples: tensor([1, 1, 0, 0, 1, 0, 1, 1, 1, 1])
vd_ds = images
vd_ds.shape
这是输出:
torch.Size([63, 3, 64, 64])
这是测试数据集:
for images, labels in test_loader_cln:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
print('Class labels of 10 examples:', labels[:10])
break
这是输出:
Image batch dimensions: torch.Size([63, 3, 64, 64])
Image label dimensions: torch.Size([63])
Class labels of 10 examples: tensor([1, 1, 1, 1, 1, 0, 1, 1, 1, 0])
第 6 步:加载预训练模型
model = torchvision.models.vgg16(pretrained=True)
model
这是输出:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
第 7 步:冻结模型
在这里,自适应 AVG 池化层是卷积层和线性层之间的桥梁。我们将只训练线性层。最简单的方法是先冻结整个模型。所以我们迭代模型中的所有参数。
假设我们要微调(训练)最后三层:
for param in model.parameters():
param.requires_grad = False
现在我们仍然可以向前和向后运行模型,但它不会更新参数。我们在接下来的步骤中微调最后三层。
model.classifier[1].requires_grad = True
model.classifier[3].requires_grad = True
对于最后一层,因为类别标签的数量与 ImageNet 不同,我们将输出层替换为您的输出层:
model.classifier[6] = torch.nn.Linear(4096, 2)
第 8 步:训练模型
这是训练过程:
def find_acc_metric(input_model, input_data_ldr, dvc):
with torch.no_grad():
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(input_data_ldr):
features = features.to(dvc)
targets = targets.float().to(dvc)
preds = input_model(features)
_, predicted_labels = torch.max(preds, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
def mdl_training(model, epch_nmbr, train_loader,
valid_loader, test_loader, optimizer,
device, logging_interval=50,
scheduler=None,
scheduler_on='valid_acc'):
tme_strt = time.time()
list_from_loss, accuracy_train, accuracy_validation = [], [], []
for epoch in range(epch_nmbr):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader): #iterating over minibatches
features = features.to(device) #Loading the data
targets = targets.to(device)
# ## 前向和后向 PROP
preds = model(features) #预测
loss = torch.nn.functional.cross_entropy(preds, targets)
optimizer.zero_grad()
loss.backward() #反向传播
# ## 更新模型参数
optimizer.step()
# ## LOGGING
list_from_loss.append(loss.item())
if not batch_idx % logging_interval:
print(f'Epoch: {epoch+1:03d}/{epch_nmbr:03d} '
f'| Batch {batch_idx:04d}/{len(train_loader):04d} '
f'| Loss: {loss:.4f}')
model.eval()
with torch.no_grad(): # save memory during inference
train_acc = find_acc_metric(model, train_loader, device=device)
valid_acc = find_acc_metric(model, valid_loader, device=device)
print(f'Epoch: {epoch+1:03d}/{epch_nmbr:03d} '
f'| Train: {train_acc :.2f}% '
f'| Validation: {valid_acc :.2f}%')
accuracy_train.append(train_acc.item())
accuracy_validation.append(valid_acc.item())
tr_time = (time.time() - tme_strt)/60
print(f'Time tr_time: {tr_time:.2f} min')
if scheduler is not None:
if scheduler_on == 'valid_acc':
scheduler.step(accuracy_validation[-1])
elif scheduler_on == 'minibatch_loss':
scheduler.step(list_from_loss[-1])
else:
raise ValueError(f'Invalid `scheduler_on` choice.')
tr_time = (time.time() - tme_strt)/60
print(f'Final Training Time: {tr_time:.2f} min')
test_acc = find_acc_metric(model, test_loader, device=device)
print(f'Test accuracy {test_acc :.2f}%')
return list_from_loss, accuracy_train, accuracy_validation
第 9 步:评估模型
def Viz_acc(acc_training, val_acc, loc_res):
epch_nmbr = len(acc_training)
plt.plot(np.arange(1, epch_nmbr+1),
acc_training, label='Training')
plt.plot(np.arange(1, epch_nmbr+1),
val_acc, label='Validation')
plt.xlabel('# of Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
if loc_res is not None:
image_path = os.path.join(
loc_res, 'plot_acc_training_validation.pdf')
plt.savefig(image_path)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), momentum=0.9, lr=0.01)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=0.1,
mode='max',
verbose=True)
list_from_loss, accuracy_train, accuracy_validation = mdl_training(
model=model,
epch_nmbr=5,
train_loader=train_loader_cln,
valid_loader=valid_loader_cln,
test_loader=test_loader_cln,
optimizer=optimizer,
device=DEVICE,
scheduler=scheduler,
scheduler_on='valid_acc',
logging_interval=100)
这是输出:
Epoch: 001/005 | Batch 0000/0001 | Loss: 1.4587
Epoch: 001/005 | Train: 79.13% | Validation: 76.21%
Time elapsed: 0.34 min
Epoch: 002/005 | Batch 0000/0001 | Loss: 0.8952
Epoch: 002/005 | Train: 92.72% | Validation: 90.29%
Time elapsed: 0.67 min
Epoch: 003/005 | Batch 0000/0001 | Loss: 0.3280
Epoch: 003/005 | Train: 97.57% | Validation: 96.60%
Time elapsed: 0.99 min
Epoch: 004/005 | Batch 0000/0001 | Loss: 0.1774
Epoch: 004/005 | Train: 99.03% | Validation: 96.60%
Time elapsed: 1.32 min
Epoch: 005/005 | Batch 0000/0001 | Loss: 0.0581
Epoch: 005/005 | Train: 99.51% | Validation: 98.06%
Time elapsed: 1.66 min
Total Training Time: 1.66 min
Test accuracy 100.00%
训练与验证的可视化:
Viz_acc(accuracy_train=accuracy_train,
accuracy_validation=accuracy_validation,
results_dir=None)
plt.ylim([60, 100])
plt.show()
输出如图7-2所示。
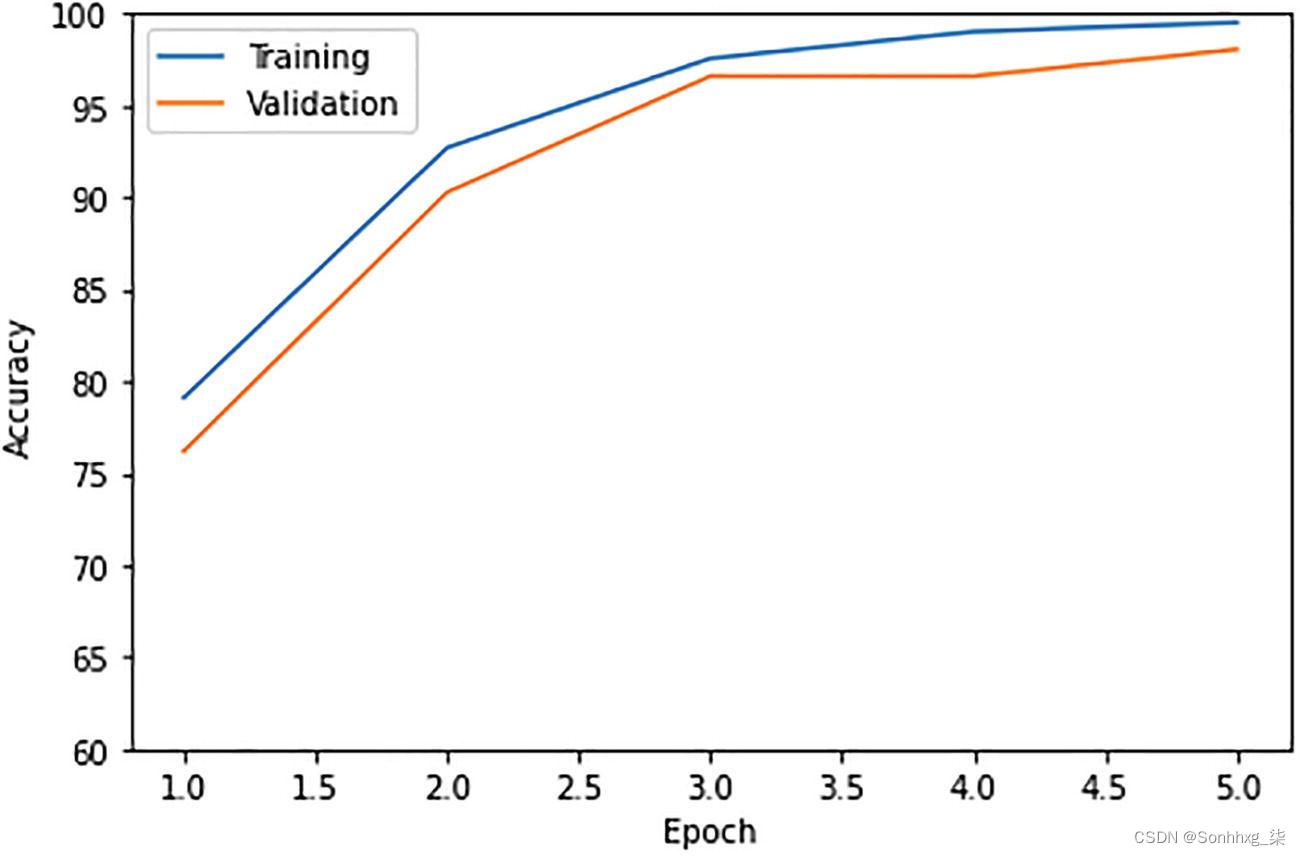
图 7-2 输出训练与验证准确性
def example_sample(model, data_loader, unnormalizer=None, class_dict=None):
for batch_idx, (features, targets) in enumerate(data_loader):
with torch.no_grad():
features = features
targets = targets
preds = model(features)
predictions = torch.argmax(preds, dim=1)
break
fig, axes = plt.subplots(nrows=3, ncols=5,
sharex=True, sharey=True)
if unnormalizer is not None:
for idx in range(features.shape[0]):
features[idx] = unnormalizer(features[idx])
nhwc_img = np.transpose(features, axes=(0, 2, 3, 1))
if nhwc_img.shape[-1] == 1:
nhw_img = np.squeeze(nhwc_img.numpy(), axis=3)
for idx, ax in enumerate(axes.ravel()):
ax.imshow(nhw_img[idx], cmap='binary')
if class_dict is not None:
ax.title.set_text(f'P: {class_dict[predictions[idx].item()]}'
f'\nT: {class_dict[targets[idx].item()]}')
else:
ax.title.set_text(f'P: {predictions[idx]} | T: {targets[idx]}')
ax.axison = False
else:
for idx, ax in enumerate(axes.ravel()):
ax.imshow(nhwc_img[idx])
if class_dict is not None:
ax.title.set_text(f'P: {class_dict[predictions[idx].item()]}'
f'\nT: {class_dict[targets[idx].item()]}')
else:
ax.title.set_text(f'P: {predictions[idx]} | T: {targets[idx]}')
ax.axison = False
plt.tight_layout()
plt.show()
class UnNormalize(object): #for plotting the images
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, tensor):
"""
参数:
--------------
tensor(Tensor):要归一化的大小为(C,H,W)的张量图像。
Returns:
--------------
Tensor:归一化图像。
"""
for t, m, s in zip(tensor, self.mean, self.std):
t.mul_(s).add_(m)
return tensor
model.cpu()
unnormalizer = UnNormalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.2255))
class_dict = {0: 'anomaly',
1: 'clean'}
example_sample(model=model, data_loader=test_loader_cln, unnormalizer=unnormalizer, class_dict=class_dict)
输出如图7-3所示。

图 7-3 输出图像
混淆矩阵如下:
def conf_matrix(model, input_data_ldr, input_dvc):
trgt_data, pred_data = [], []
with torch.no_grad():
for i, (features, targets) in enumerate(input_data_ldr):
features = features.to(input_dvc)
targets = targets
preds = model(features)
_, predicted_labels = torch.max(preds, 1)
trgt_data.extend(targets.to('cpu'))
pred_data.extend(predicted_labels.to('cpu'))
pred_data = pred_data
pred_data = np.array(pred_data)
trgt_data = np.array(trgt_data)
lable_values = np.unique(np.concatenate((trgt_data, pred_data)))
if lable_values.shape[0] == 1:
if lable_values[0] != 0:
lable_values = np.array([0, lable_values[0]])
else:
lable_values = np.array([lable_values[0], 1])
n_labels = lable_values.shape[0]
lst = []
z = list(zip(trgt_data, pred_data))
for combi in product(lable_values, repeat=2):
lst.append(z.count(combi))
mat = np.asarray(lst)[:, None].reshape(n_labels, n_labels)
return mat
def plot_confusion_matrix(conf_mat,
hide_spines=False,
hide_ticks=False,
figsize=None,
cmap=None,
colorbar=False,
show_absolute=True,
show_normed=False,
class_names=None):
if not (show_absolute or show_normed):
raise AssertionError('Both show_absolute and show_normed are False')
if class_names is not None and len(class_names) != len(conf_mat):
raise AssertionError('len(class_names) should be equal to number of'
'classes in the dataset')
total_samples = conf_mat.sum(axis=1)[:, np.newaxis]
normed_conf_mat = conf_mat.astype('float') / total_samples
fig, ax = plt.subplots(figsize=figsize)
ax.grid(False)
if cmap is None:
cmap = plt.cm.Blues
if figsize is None:
figsize = (len(conf_mat)*1.25, len(conf_mat)*1.25)
if show_normed:
matshow = ax.matshow(normed_conf_mat, cmap=cmap)
else:
matshow = ax.matshow(conf_mat, cmap=cmap)
if colorbar:
fig.colorbar(matshow)
for i in range(conf_mat.shape[0]):
for j in range(conf_mat.shape[1]):
cell_text = ""
if show_absolute:
cell_text += format(conf_mat[i, j], 'd')
if show_normed:
cell_text += "\n" + '('
cell_text += format(normed_conf_mat[i, j], '.2f') + ')'
else:
cell_text += format(normed_conf_mat[i, j], '.2f')
ax.text(x=j,
y=i,
s=cell_text,
va='center',
ha='center',
color="white" if normed_conf_mat[i, j] > 0.5 else "black")
if class_names is not None:
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names, rotation=90)
plt.yticks(tick_marks, class_names)
if hide_spines:
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.yaxis.set_ticks_position('left')
ax.xaxis.set_ticks_position('bottom')
if hide_ticks:
ax.axes.get_yaxis().set_ticks([])
ax.axes.get_xaxis().set_ticks([])
plt.xlabel('predicted label')
plt.ylabel('true label')
return fig, ax
mat = conf_matrix(model=model, data_loader=test_loader_cln, device=torch.device('cpu'))
plot_confusion_matrix(mat, class_names=class_dict.values())
plt.show()
输出如图7-4所示。

图 7-4 混淆矩阵
方法 2:使用自动编码器
构建一个自动编码器训练网络,其中包含以下内容:
编码器:对原始图像进行编码(基于像素值)。
解码器:根据编码器的输出重建图像。
评估原始图像和重建图像之间的模型。根据错误度量分数,检测到最异常的数字。
下面是五步实现:
第 1 步:准备数据集对象。
第 2 步:构建自动编码器网络。
第 3 步:训练自动编码器网络。
第 4 步:根据原始数据计算重建损失。
第 5 步:根据错误度量分数选择最异常的数字。
第 1 步:准备数据集对象
加载input.csv文件。input.csv文件包含每条记录的 65 个值。前 64 个值表示手写数字的灰度像素值。最后一个值表示数字的原始类别,介于 0 到 9 之间。
将 CSV 数据记录转换为张量。之后,对像素值和原始类数据进行归一化。
# 步骤1
# 准备数据集对象
print("\nLoad csv data, convert to data as normalized tensors ")
# Load 包含 65 个值的 .csv 数据集
# first 64代表灰度格式的64个像素值
# last 1 值代表实际数字(在 0 到 9 之间)
csv_data = "hand_written_digits.txt"
# 使用辅助函数“tensor_converter”将 csv 格式转换为标准化张量
tensor_data = tensor_converter(csv_data)
第 2 步:构建自动编码器网络
在这里,我们构建了自动编码器网络,其中包含编码器和解码器架构。
编码器将原始数字像素值转换为较低维空间。(例如,它将 64 像素灰度值转换为 8 个值。)
解码器从较低维度重建原始数字。(例如,它使用 8 个值重建 64 像素灰度图像。)
在此问题陈述中,在编码和解码期间使用全连接层。使用三个全连接 (FC) 层构建编码网络,其中第一个 FC 层将 65 个值 (64+1) 转换为 48,第二层将 48 个值转换为 32。最后一层将 32 个值转换为 8。编码 — > 65–48-32-8。
解码网络使用三个全连接层构建,其中第一层将 8 个值转换为 32 个值,第二个 FC 层将 32 个值转换为 48 个值。最后一层将 48 个值转换为 65。解码 —> 8-32-48-65。
def __init__(self):
super(Autoencoder, self).__init__()
self.fc1 = T.nn.Linear(65, 48)
self.fc2 = T.nn.Linear(48, 32)
self.fc3 = T.nn.Linear(32, 8)
self.fc4 = T.nn.Linear(8, 32)
self.fc5 = T.nn.Linear(32, 48)
self.fc6 = T.nn.Linear(48, 65)
def encode(self, x):
# 65-48-32-8
z = T.tanh(self.fc1(x))
z = T.tanh(self.fc2(z))
z = T.tanh(self.fc3(z))
return z
def decode(self, x):
# 8-32-48-65
z = T.tanh(self.fc4(x))
z = T.tanh(self.fc5(z))
z = T.sigmoid(self.fc6(z))
return z
第 3 步:训练自动编码器网络
使用学习率、时期、批次大小、损失指标和损失优化器等超参数训练自动编码器网络。对于训练,辅助函数采用自动编码器网络、张量数据和所有其他超参数,如前所述。
# Step 3. 训练自动编码器模型
batch_size = 10
max_epochs = 200
log_interval = 8
learning_rate = 0.002
train(autoenc,tensor_data, batch_size, max_epochs,log_interval, learning_rate)
第 4 步:根据原始数据计算重建损失
通过比较原始手写数字和重建数字来评估训练模型。计算并存储图像重建损失:
# 设置自动编码器模式进行评估
autoenc.eval()
# 存储重建的MSE损失
MSE_list = make_err_list(autoenc, tensor_data)
# 根据MSE损失从高到低对列表进行排序
MSE_list.sort(key=lambda x: x[1], reverse=True)
第 5 步:根据错误度量分数选择最异常的数字
基于最高的 MSE 损失,我们需要找到数据集中异常的数字。
# Step 5. 显示数据集中最异常的手写数字
print("Anomaly digit in the dataset given based on Highest MSE: ")
(idx,MSE) = MSE_list[0]
print(" Index : %4d , MSE : %0.4f" % (idx, MSE))
display_digit(tensor_data, idx)
输出
基于最高 MSE 给出的数据集中的异常数字:
Index:486,MSE:0.1360
输出如图7-5所示。
digit = 7
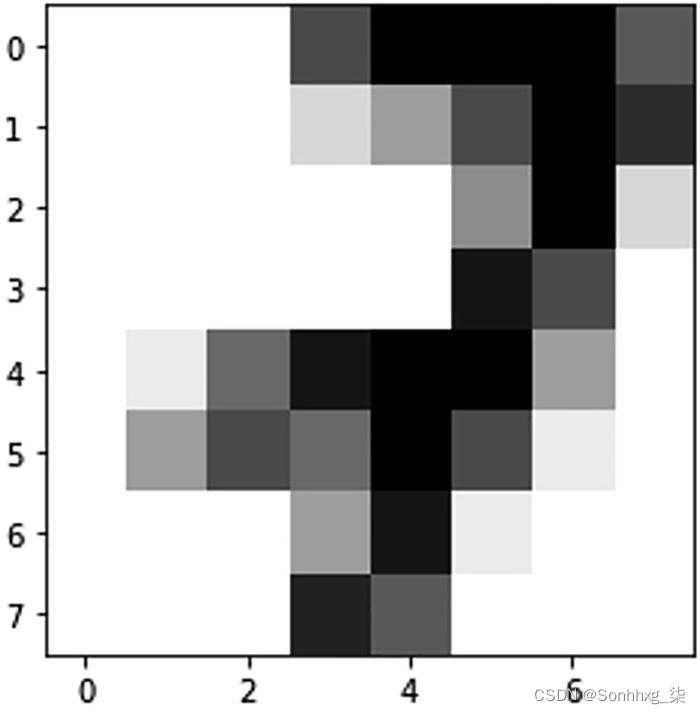
图 7-5 异常输出
概括
我们使用 VGG 架构来确定样本图像数据集中的异常。我们检查了代码并开发了一个端到端的管道。这个模型只需很少的改动就可以用于工业级问题。
现在我们了解了异常检测,下一章将讨论最先进的用例,即“图像超分辨率”。我们已经看到许多提高图像质量和分辨率的应用程序。您可以通过在 PyTorch 中构建模型来自己完成吗?让我们在下一章中弄清楚。
版权归原作者 Sonhhxg_柒 所有, 如有侵权,请联系我们删除。