
大家好,我叫微学AI,今天给大家带来图像识别实战项目。
图像识别实战是一个实际应用项目,下面介绍如何使用深度学习技术来识别和检测图像中的物体。主要涉及计算机视觉,实时图像处理和相关的深度学习算法。学习者将学习如何训练和使用深度学习模型来识别和检测图像中的物体,以及如何使用实时图像处理技术来处理图像。
项目还将涉及如何使用计算机视觉方法来识别和检测图像中的特征,以及利用卷积神经网络来进行识别图像。
一、图像识别原理与步骤
图像识别是指通过深度学习技术从图像中识别出特征和对象的过程。
图像识别我们主要采用卷积神经网络来实现,它可以用来识别和识别图像中的特征。它采用一种叫做卷积的技术来提取图像中的关键特征,并使用多层的神经网络来分类和识别图像。
对CNN进行复习:CNN的结构一般由输入层、卷积层、池化层、全连接层、输出层组成。
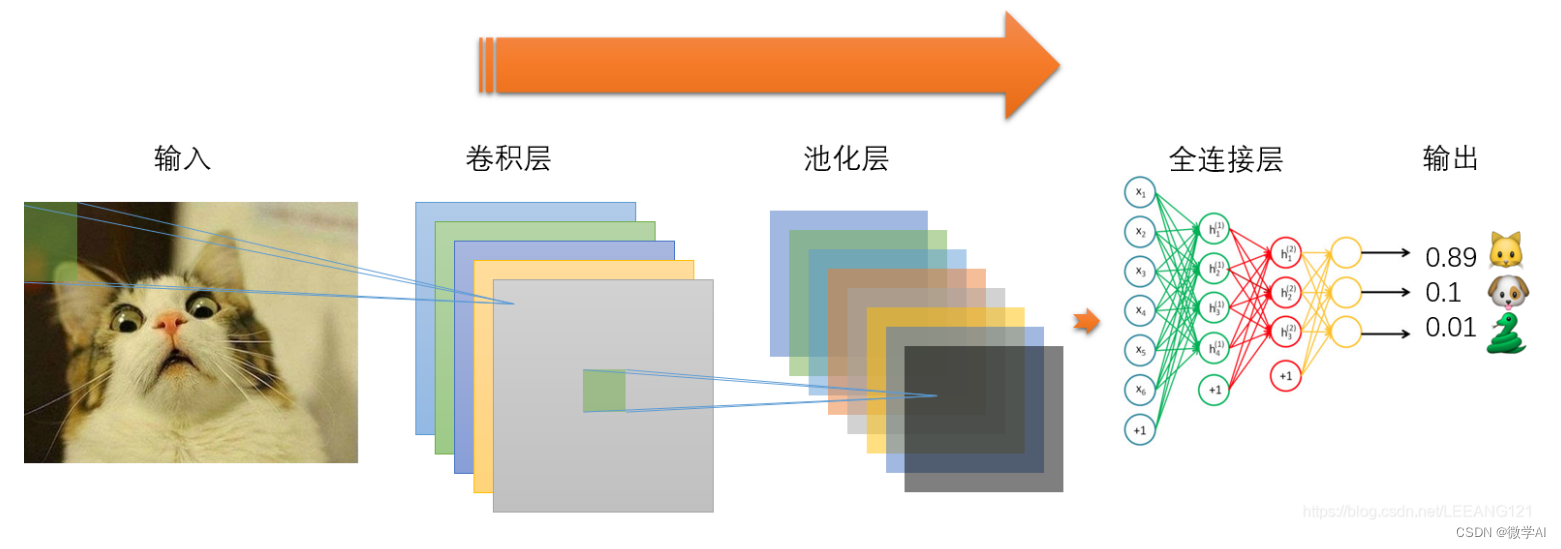
- 输入层:将图像转化为数字信号,将每个像素转换为一个数字,作为神经网络的输入层。
- 卷积层:卷积层用来提取图像的特征,它对图像的每个区域进行特征提取,并将提取的特征输出到另一卷积层。
- 池化层:池化层可以提取图像的主要特征,它将大小相同的特征池化成更小的特征,并丢弃不具有代表性的特征。
- 全连接层:全连接层可以将池化层提取出的特征拼接成一个完整的特征向量,用来进一步分析和提取图像特征。
- 输出层:输出层将前面层提取出的特征转换为最终的识别结果。
二、卷积神经网络网络层与记忆方法
输入层:Input(In),把数据输入进去;
卷积层:Convolution(Conv),将图像数据翻译成特征数据;
池化层:Pooling(Pool),对特征数据进行子采样降维;
全连接层:Fully Connected(FC),将特征数据拉长到神经网络的输入;
输出层:Output(Out),将模型的输出展示出来。
记忆方法:
Input:想象你手上拿着一叠图片,要把它们输入到电脑里;
Conv:想象你用缝纫机把一张复杂的图案缝制在布料上,它把图案中的每个元素翻译成特征;
Pool:想象你一块块地把布料剪开,剪出来的图案比之前要小,它把特征数据降维了;
FC:想象你用胶水把图案拉长,它把原有的复杂图案拉长成神经网络的输入;
Out:想象你把拉长的图案绣在棉布上,它把模型的输出展示出来了。
三、卷积神经网络网络的优点
- 具有非常强大的特征提取能力,能够从图像中提取有价值的特征;
- 参数共享,卷积网络在同一层中共享参数,有效减少了参数量,大大减少了训练时间;
- 能够学习到更多的高层抽象特征,使得卷积网络能够更好地处理复杂的问题;
- 支持不同尺度的特征提取,可以从不同的尺度提取特征,并将不同尺度的特征结合起来;
- 使用少量的参数能够很好的拟合大量的数据,使得训练模型的效果更好;
- 支持在线学习,可以通过少量的训练数据快速拟合;
- 可以用来实现深度学习,提升模型的性能。
四、图像分类实战代码
以CIFAR-10数据集为例子做图像分类,CIFAR-10数据集是一个用于机器学习和计算机视觉识别研究的图像数据库。它由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的,包含五万张32x32彩色图像,分成10个类别:飞机,汽车,鸟类,猫,鹿,狗,青蛙,马,船和卡车。每一类都有5000张图像,总计50,000张图像。每张图像是一个numpy数组,尺寸为 32x32x3,每个像素的可能值从0到255。

实战代码:
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
# 加载数据
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
train_data_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
test_data_loader = torch.utils.data.DataLoader(test_dataset, batch_size=128, shuffle=False)
# 定义网络架构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 创建网络实例
net = Net()
# 定义优化器和损失函数
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 开始训练
for epoch in range(50):
running_loss = 0.0
for i, data in enumerate(train_data_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 0:
print('Epoch: %d, step: %d, loss: %.3f' % (epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
# 开始测试
correct = 0
total = 0
with torch.no_grad():
for data in test_data_loader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
代码解析:
# 定义网络架构
class Net(nn.Module):
- 继承自 pytorch 中的 nn.Module 类,构建网络框架,进而构建网络结构;
- 在__init__()函数中,使用nn.Conv2d()函数定义卷积层;使用nn.MaxPool2d()函数定义池化层;使用nn.Linear()函数定义全连接层;
- 在forward()函数中,使用F.relu()函数定义ReLu激活函数;使用x.view()函数将卷积层输出展平,作为全连接层的输入;最后使用self.fc3(x)输出最终结果。
模型训练过程:
定义交叉熵损失函数 criterion 和随机梯度下降优化器 optimizer。
用 for 循环迭代 50 个 epoch,每个 epoch 内迭代所有的训练数据集 train_data_loader。
在每个 mini-batch 中:
使用 optimizer.zero_grad() 将梯度缓存清零,清空上一步的残余更新参数值。
将输入数据 inputs 送入网络,得到输出 outputs。
计算损失值 loss,反向传播梯度,更新网络参数。
每 2000 个 mini-batch 打印一次平均损失 running_loss,其值等于当前损失 loss 与上 2000 个 mini-batch 的损失之和除以 2000。
相信大家都能很清楚的理解!有问题私信哦。
版权归原作者 微学AI 所有, 如有侵权,请联系我们删除。