
Lasso变体:Group Lasso,Sparse Group Lasso
关于Lasso回归的讲解可以看我的另一篇博客:Lasso回归系列二:Lasso回归/岭回归的原理
Group Lasso
在Lasso回归中,是单独地看待每个特征(即假定特征不存在先验的分组),但有些使用场景下,变量本身就存在分组,比如在股市分析问题中,来自同一个商业领域的公司可以划分到一个小组。在2006年【Model selection and estimation in regression with grouped variables】论文提出Group Lasso,通过引入特征先验的分组信息来解决这类问题:数据的变量之间本身就存在一些已知的分组关系。
根据先验的变量之间的分组信息,权重
β
\beta
β 可以被分成
m
m
m 组,分组后
β
G
=
β
(
1
)
,
β
(
2
)
,
⋯
,
β
(
m
)
β_G={β(1),β(2),⋯,β(m)}
βG=β(1),β(2),⋯,β(m),
β
(
l
)
β(l)
β(l) 代表一组来自
β
β
β 的权重,其中 $ 1≤l≤m$ 。进一步我们对数据
X
X
X 也进行分组,
X
(
I
)
X(I)
X(I)代表对应
β
(
l
)
β(l)
β(l) 的子矩阵。这个优化问题就变成了
β
∗
=
arg
min
β
∣
∣
y
−
∑
l
=
1
m
X
(
l
)
β
(
l
)
∣
∣
2
2
+
λ
∑
l
=
1
m
p
l
∣
∣
β
(
l
)
∣
∣
2
\beta^* = \underset {\beta}{\arg \min} ||y−∑_{l=1}^mX^{(l)}β^{(l)}||^2_2+λ∑_{l=1}^m \sqrt p_l ||β^{(l)}||_2
β∗=βargmin∣∣y−l=1∑mX(l)β(l)∣∣22+λl=1∑mpl∣∣β(l)∣∣2
其中
p
l
p_l
pl 代表
β
(
l
)
β^{(l)}
β(l)中权重参数的个数。
Group Lasso倾向于把一个组的变量当作一个整体,如果这一组变量是有意义的,那么就会选择该组的所有变量,否则,整组变量对应的参数会被设置为0。
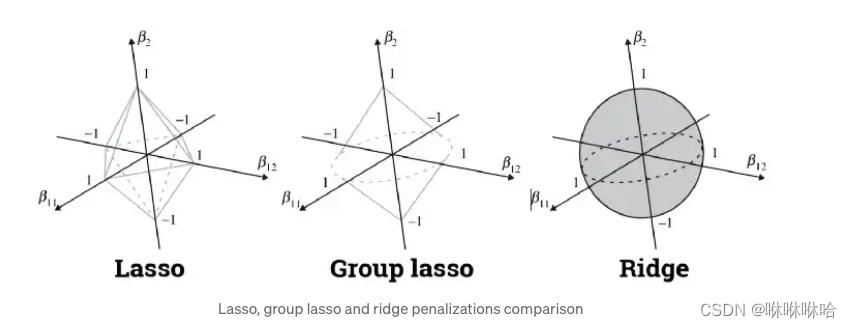
如上图所示,
β
11
,
β
12
\beta_{11}, \beta_{12}
β11,β12是一组变量,
β
2
\beta_2
β2 是第二组变量,
我们仍旧可以用“不可微分的地方更容易和平方误差等值项相交”的规律来进行分析。在
<
β
11
,
β
12
>
<\beta_{11}, \beta_{12}>
<β11,β12> 所在的平面上更容易出现不可微的点,此时
β
2
=
0
\beta_2=0
β2=0 ,即第二组变量对应
β
β
β 的参数为0,第二组变量被抛弃。
此外,我们还可以发现,当m=1时,Group Lasso就等价于岭回归,当m=n时,Group Lasso就变成了Lasso回归。
Sparse Group Lasso
Sparse Group Lasso是Lasso和Group Lasso的线性结合,最终得到的结果同样也是介于Lasso和Group Lasso的结果之间。
Sparse Group Lasso 是一种非常受欢迎的变量选择方法,能够从最有意义的变量组中选出最有意义的变量。
此时,优化问题就变成了:
β
∗
=
arg
min
β
∣
∣
y
−
∑
l
=
1
m
X
(
l
)
β
i
∣
∣
2
2
+
α
λ
∑
l
=
1
n
∣
∣
β
i
∣
∣
1
+
(
1
−
α
)
λ
∑
l
=
1
m
p
l
∣
∣
β
(
l
)
∣
∣
2
\beta^*= \underset {\beta}{\arg \min} ||y−∑_{l=1}^mX^{(l)}β_{i}||^2_2+\alphaλ∑_{l=1}^n ||β_{i}||_1+(1-\alpha)λ∑_{l=1}^m \sqrt p_l ||β^{(l)}||_2
β∗=βargmin∣∣y−l=1∑mX(l)βi∣∣22+αλl=1∑n∣∣βi∣∣1+(1−α)λl=1∑mpl∣∣β(l)∣∣2
其中包含两个需要优化的参数:
λ
\lambda
λ 和
α
\alpha
α ,
λ
\lambda
λ 控制惩罚力度,
α
\alpha
α 权衡Lasso和Group Lasso的比重,通常可以通过网格搜索确定这两个参数的值。
参考:
Group Lasso
Sparse Group Lasso in Python
本文转载自: https://blog.csdn.net/qq_40924873/article/details/128014355
版权归原作者 咻咻咻哈 所有, 如有侵权,请联系我们删除。
版权归原作者 咻咻咻哈 所有, 如有侵权,请联系我们删除。