
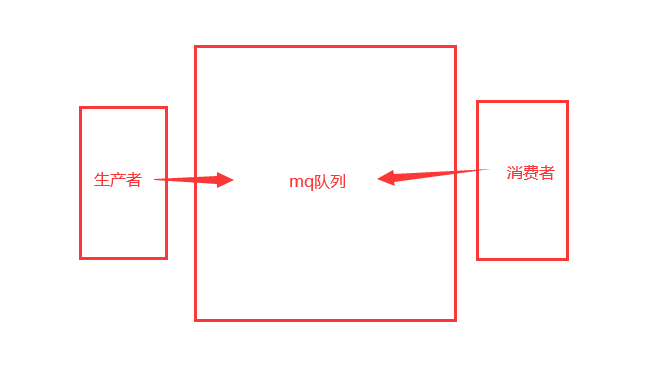
简单模式
生产者
1 链接rabbitmq
2 创建队列
3 向指定的队列插入数据
消费者
1 链接rabbitmq
2 监听模式
3 确定回调函数
示例:
#生产者
import pika
#链接rabbitmq
creadentials = pika.PlainCredentials(username='用户名',password='密码')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='地址',port=端口))
channel = connection.channel()
#创建队列
channel.queue_declare(queue='ceshi')
#向指定队列插入数据 [exchange:交换机模式,简单模式为空 routing_key:指定队列 body:要插入的值]
channel.basic_publish(exchange='',routing_key='ceshi',body='hello world!')
print('[x]--')
#消费者
import pika
#创建链接
pika.PlainCredentials(username='用户名',password='密码')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='地址',port=端口))
channel = connection.channel()
#创建队列
channel.queue_declare(queue='ceshi')
#确定回调函数
def callback(ch,method,properties,body):
print("[x]:",body)
#确定监听队列 [auto_ack:默认应答]
channel.basic_consume(queue='ceshi',auto_ack=True,on_message_callback=callback)
print('[*]:---')
#正式监听
channel.start_consuming()
参数使用
1.应答参数
消费者确定监听队列时的一个参数
auto_ack
True:默认应答:
从队列取走一条数据后队列里这条数据就不存在了,如果在数据处理过程中程序出现问题,会造成数据丢失现象
False:手动应答:
从队列取走一条数据后,这条数据还存在于队列中
ch.basic_ack(delivery_tag=method.delivery_tag)添加在回调函数最后
最后执行这条命令会告诉队列,我已经执行完成了,可以删除这条数据了
手动应答必然会影响效率,具体根据项目需求抉择:是追求数据安全还是效率
2.持久化
将数据保存到磁盘,防止程序运行中途rabbitmq服务异常导致数据丢失
生产者
创建队列时进行申明 durable=True
channel.queue_declare(queue='ceshi',durable=True)
插入数据时申明 properties=pika.BasicProperties(delivery_mode=2)
channel.basic_publish(exchange='',
routing_key='ceshi',
body='hello world!',
properties=pika.BasicProperties(
delivery_mode=2)
)
消费者
创建队列时进行申明 durable=True
channel.queue_declare(queue='ceshi2',durable=True)
3.分发参数
轮询分发
正常开启多个消费者都是轮询分发,比如队列有8个数据,每人4个
公平分发
处理快的获取到的数据便越多,,公平分发需要使用手动应答方式才可以
消费者添加 channel.basic_qos(prefetch_count=1)
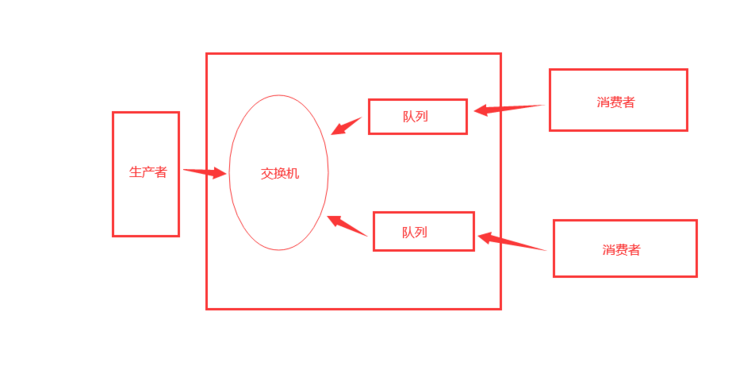
交换机模式
发布订阅模式
生产者
1 链接rabbitmq
2 创建一个交换机,类型为fanout
3 向交换机内插入数据
消费者
1 链接rabbitmq
2 创建一个交换机,类型为fanout
3 创建队列并绑定交换机
4 监听模式
5 确定回调函数
示例:
#生产者
import pika
#链接rabbitmq
pika.PlainCredentials(username='用户名',password='密码')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='地址',port=端口))
channel = connection.channel()
#声明一个名为logs类型为fanout的交换机
channel.exchange_declare(exchange='logs',
exchange_type='fanout') #fanout:发布订阅模式
#向logs交换机插入数据 hello world!
channel.basic_publish(exchange='logs',
routing_key='',
body='hello world!')
print('[x]---')
connection.close()
channel = connection.channel()
#声明一个与生产者名称类型相同的交换机,避免先启动消费者-队列找不到交换机的情况
channel.exchange_declare(exchange='logs',
exchange_type='fanout') #fanout:发布订阅模式
#创建队列 exclusive:系统会创建一个随机唯一的队列名
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
#将指定队列绑定到交换机上
channel.queue_bind(exchange='logs',
queue= queue_name)
#确定回调函数
def callback(ch,method,properties,body):
print("[x]:",body)
#确定监听队列 [auto_ack:默认应答]
channel.basic_consume(queue=queue_name,
auto_ack=True,
on_message_callback=callback)
print('[*]:---')
#正式监听
channel.start_consuming()
关键字模式
生产者
1 链接rabbitmq
2 创建一个交换机,类型为direct
3 向交换机内插入数据,插入时添加关键字,routing_key:想要进入哪一个消费者的队列,就设置某个队列的关键字
消费者
1 链接rabbitmq
2 创建一个交换机,类型为direct
3 创建队列并绑定交换机,绑定交换机时添加关键字 routing_key
4 监听模式
5 确定回调函数
示例:
#生产者
import pika
#链接rabbitmq
pika.PlainCredentials(username='用户名',password='密码')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='地址',port=端口))
channel = connection.channel()
#声明一个名为logs类型为direct的交换机
channel.exchange_declare(exchange='logs',
exchange_type='direct') #direct:关键字模式
#向logs交换机插入数据 hello world! routing_key为关键字
channel.basic_publish(exchange='logs',
routing_key='info',
body='hello world!')
print('[x]---')
connection.close
#消费者
import pika
#创建链接
pika.PlainCredentials(username='用户名',password='密码')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='地址',port=端口))
channel = connection.channel()
#声明一个与生产者名称类型相同的交换机,避免先启动消费者-队列找不到交换机的情况
channel.exchange_declare(exchange='logs',
exchange_type='direct') #direct:关键字模式
#创建队列 exclusive:系统会创建一个随机唯一的队列名
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
#将指定队列绑定到交换机上,routing_key:关键字,多个关键字绑定多个
channel.queue_bind(exchange='logs',
queue= queue_name,
routing_key='info')
channel.queue_bind(exchange='logs',
queue= queue_name,
routing_key='error')
#确定回调函数
def callback(ch,method,properties,body):
print("[x]:",body)
#确定监听队列 [auto_ack:默认应答]
channel.basic_consume(queue=queue_name,
auto_ack=True,
on_message_callback=callback)
print('[*]:---')
#正式监听
channel.start_consuming()
通配符模式
生产者
1 链接rabbitmq
2 创建一个交换机,类型为topic
3 向交换机内插入数据,插入时添加关键字,routing_key:想要进入哪一个消费者的队列,就设置某个队列的关键字,关键字可以使用.来分割
消费者
1 链接rabbitmq
2 创建一个交换机,类型为topic
3 创建队列并绑定交换机,绑定交换机时添加关键字 routing_key 关键字可以使用通配符[*:匹配一次,#:匹配一次或多次]
4 监听模式
5 确定回调函数
示例:
#生产者
import pika
#链接rabbitmq
pika.PlainCredentials(username='用户名',password='密码')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='地址',port=端口))
channel = connection.channel()
#声明一个名为logs类型为topic的交换机
channel.exchange_declare(exchange='logs',
exchange_type='topic') #topic:通配符模式
#向logs交换机插入数据 hello world!
channel.basic_publish(exchange='logs3',
routing_key='usa.aaaa',
body='hello 21321!')
print('[x]---')
connection.close()
#消费者
import pika
#创建链接
pika.PlainCredentials(username='用户名',password='密码')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='地址',port=端口))
channel = connection.channel()
#声明一个与生产者名称类型相同的交换机,避免先启动消费者-队列找不到交换机的情况
channel.exchange_declare(exchange='logs',
exchange_type='topic') #topic:通配符模式
#创建队列 exclusive:系统会创建一个随机唯一的队列名
result = channel.queue_declare(queue='',exclusive=True)
queue_name = result.method.queue
print(queue_name)
#将指定队列绑定到交换机上,routing_key:关键字,多个关键字绑定多个
channel.queue_bind(exchange='logs',
queue= queue_name,
routing_key='#.aaaa')
#确定回调函数
def callback(ch,method,properties,body):
print("[x]:",body)
#确定监听队列 [auto_ack:默认应答]
channel.basic_consume(queue=queue_name,
auto_ack=True,
on_message_callback=callback)
print('[*]:---')
#正式监听
channel.start_consuming()
以上就是全部内容,希望对大家有所帮助学习,
标签:
Python