
💗博主介绍:✌全网粉丝10W+,CSDN全栈领域优质创作者,博客之星、掘金/华为云/阿里云等平台优质作者。
👇🏻 精彩专栏 推荐订阅👇🏻
计算机毕业设计精品项目案例-200套
🌟文末获取源码+数据库+文档🌟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以和学长沟通,希望帮助更多的人
一.前言

近些年来,随着科技的飞速发展,互联网的普及逐渐延伸到各行各业中,给人们生活带来了十分的便利,热点新闻分析系统利用计算机网络实现信息化管理,使整个热点新闻分析的发展和服务水平有显著提升。
本文拟采用PyCharm开发工具, django框架、Python语言、Hadoop大数据处理技术进行开发,后台使用MySQL数据库进行信息管理,设计开发的热点新闻分析系统。通过调研和分析,系统拥有管理员和用户两个模块,主要具备有系统首页、个人中心、用户管理、新闻类型管理、主题标签管理、热点新闻管理、新闻评分管理、新闻资讯管理、系统管理等功能模块。将纸质管理有效实现为在线管理,极大提高工作效率。
二.技术环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
爬虫框架:Scrapy
大数据框架:Hadoop
开发软件:PyCharm/vs code
前端框架:vue.js
三.功能设计
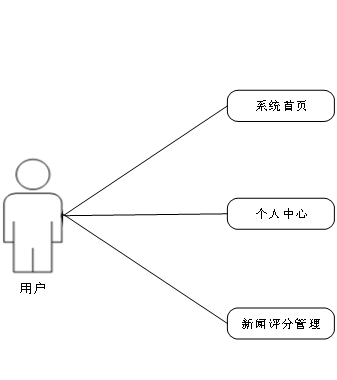
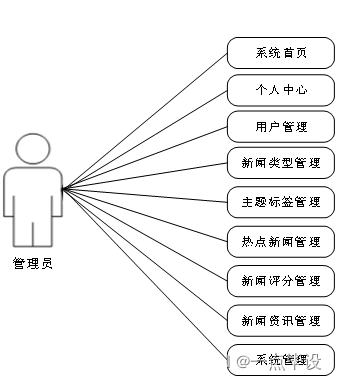
在设计系统的过程中,用例图也是系统设计过程中必不可少的模型,如果说系统的结构图可以简洁明了的表示出系统的有关功能模块,那么用例图则可以更为细致的,结合系统中人员的有关分配,能够从细节上描绘出系统中有关功能所完成的具体事件,确切的反映出某个操作以及它们相互之间的内部联系。
其中参与者就是和系统能够发生交互的外在实体,一般可以指系统的某个用户。一个用例图就能对应出系统中的一个功能过程,系统中完整的功能都是由许多不同的用例图所组成的。
系统用例图如图3-1、图3-2、图3-3所示。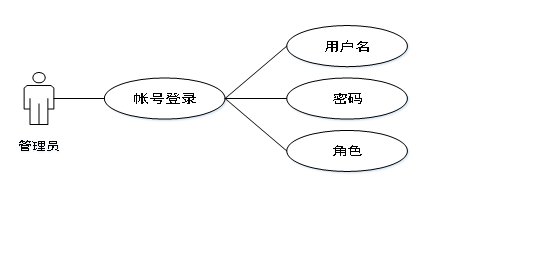
系统功能结构图是系统设计阶段,系统功能结构图只是这个阶段一个基础,整个系统的架构决定了系统的整体模式,是系统的根据。热点新闻分析可视化系统的整个设计结构如图所示。
四.数据设计
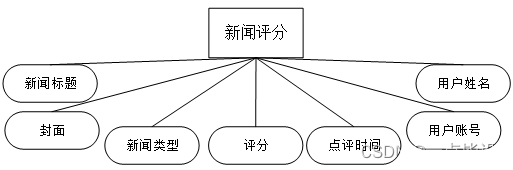
概念模型的设计是为了抽象真实世界的信息,并对信息世界进行建模。它是数据库设计的强大工具。数据库概念模型设计可以通过E-R图描述现实世界的概念模型。系统的E-R图显示了系统中实体之间的链接。而且Mysql数据库是自我保护能力比较强的数据库,下图主要是对数据库实体的E-R图:
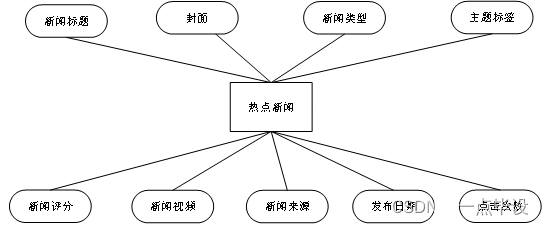
五.部分效果展示
系统前台功能实现效果
当游客打开系统的网址后,首先看到的就是首页界面。在这里,游客能够看到热点新闻分析系统的导航栏显示首页、热点新闻、新闻资讯、后台管理、个人中心。系统首页界面如图所示:

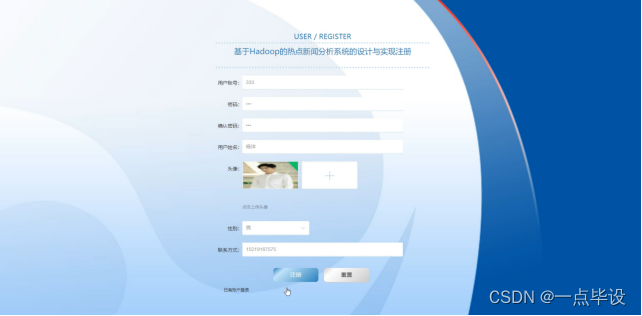
在系统首页点击中间的注册/登录按钮,然后页面跳转到注册登录界面,后来输入信息完成后,单击注册或者登录操作,如图所示:
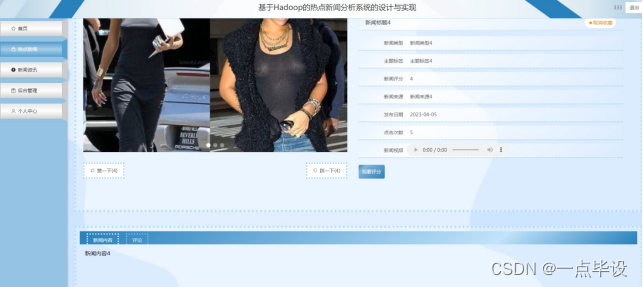
用户点击热点新闻,在热点新闻页面的搜索栏输入新闻标题、主题标签、新闻内容,进行查询,然后可以查看新闻标题、封面、新闻类型、主题标签、新闻评分、新闻视频、新闻来源 、发布日期、点击次数,还可以对评分、赞、踩、收藏或者评论操作;如图所示:
在个人中心页面可以输入个人详细信息,进行信息更新操作,还可以对我的收藏进行详细操作,如图所示:
用户击后台管理,然后页面跳转到系统主页面,主要功能包括对系统首页、个人中心、新闻评分管理等进行操作。用户主页面如图所示: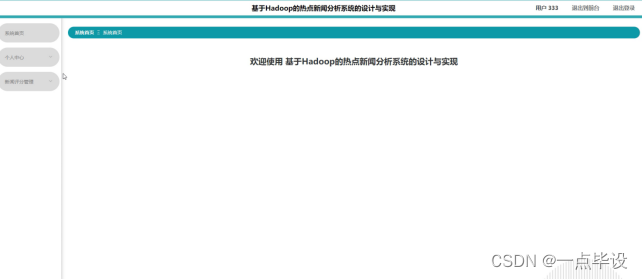
系统后台功能实现效果
管理员登录,在登录页面正确输入用户名和密码后,选择角色点击登录操作;如图所示。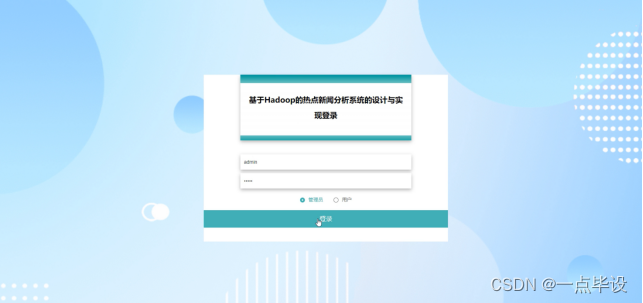
管理员进入系统后,主要功能包括对系统首页、个人中心、用户管理、新闻类型管理、主题标签管理、热点新闻管理、新闻评分管理、新闻资讯管理、系统管理等进行操作。管理员主页面如图所示: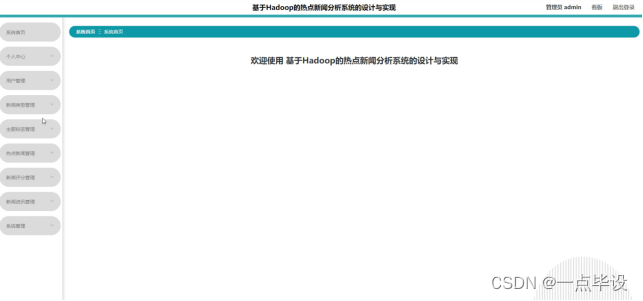
管理员点击用户管理:在用户管理页面,可以对用户账号、用户姓名、头像、性别、联系方式等信息,进行查询、新增或者删除用户信息等操作,如图所示: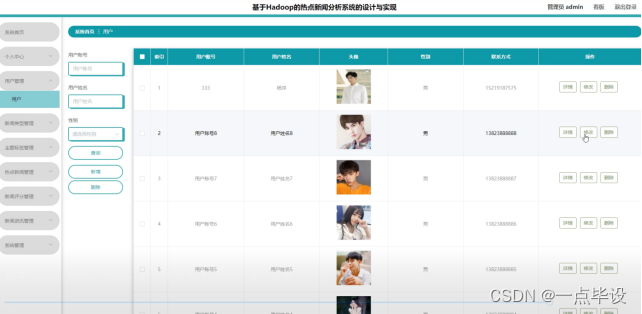
管理员点击主题标签管理:在主题标签管理页面,可以对主题标签等信息,进行查询或者新增、删除主题标签等操作,如图所示: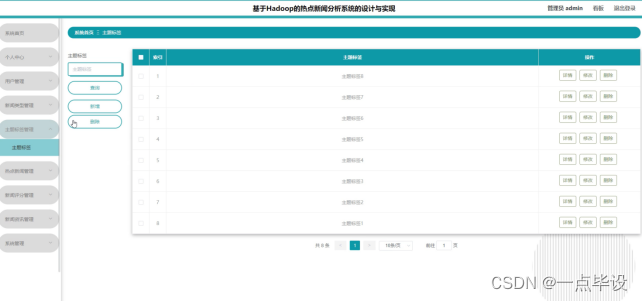
管理员点击热点新闻管理:在热点新闻管理页面,可以对新闻标题、封面、新闻类型、主题标签、新闻评分、新闻视频、新闻来源 、发布日期、点击次数等信息,进行查询或者新增、删除热点新闻等操作,如图所示:
管理员点击新闻评分管理:在新闻评分管理页面,可以对新闻标题、封面、新闻类型、评分、点评时间、用户账号、用户姓名等信息,进行查询或者删除新闻评分等操作,如图所示: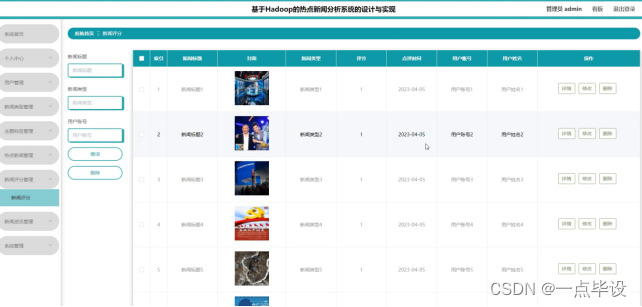
数据可视化分析大屏展示实现效果
热点新闻分析系统展示图,如图所示。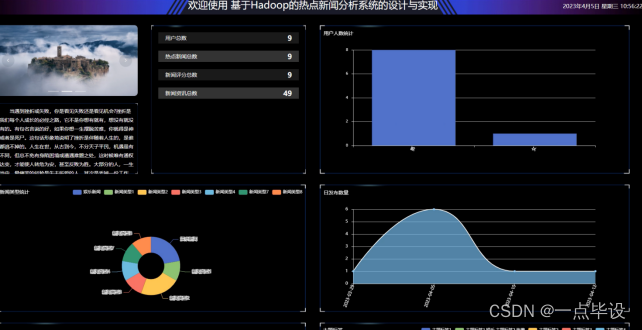
下面展示是用户人数统计,对于用户人数统计大数据,数据获取之后,开始对这些数据进行可视化分析,首先是用户人数统计的基本情况,其中根据爬取的数据以柱状图的形式来展示,如图所示。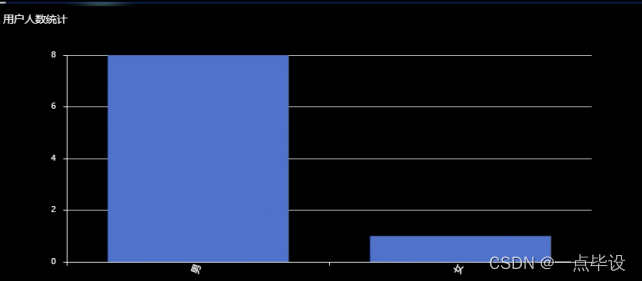
下面展示是新闻类型统计,对于新闻类型统计大数据获取之后,开始对这些数据进行可视化分析,首先通过页面查看新闻类型统计详情以饼状图分析进行来展示,如图所示。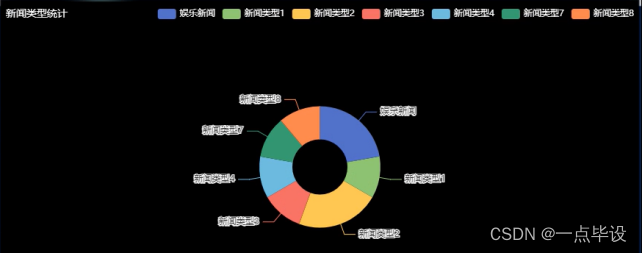
在日发布数量页面以波浪线图进行展示所示。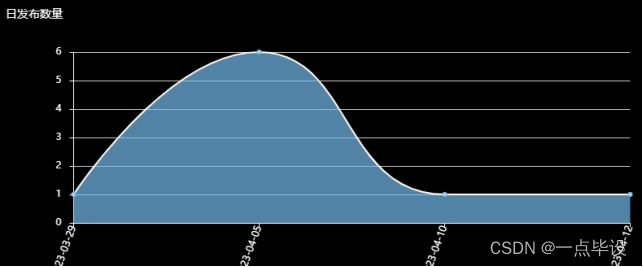
下图是主题标签,通过python爬取清洗后的数据以饼状图的形式展示如图所示: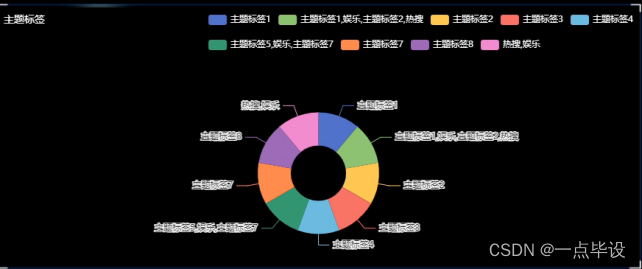
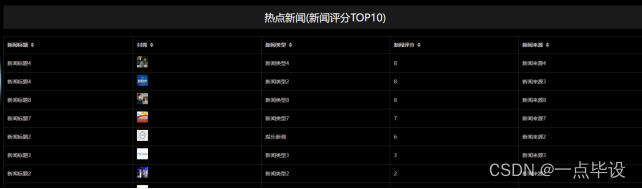
下图是热点新闻(新闻评分TOP10),通过python爬取清洗后的数据以信息表的形式展示如图所示:
六.部分功能代码
# 数据爬取文件import scrapy
import pymysql
import pymssql
from..items import XinwenzixunItem
import time
import re
import random
import platform
import json
import os
from urllib.parse import urlparse
import requests
import emoji
# 新闻资讯classXinwenzixunSpider(scrapy.Spider):
name ='xinwenzixunSpider'
spiderUrl ='https://i.news.qq.com/trpc.qqnews_web.kv_srv.kv_srv_http_proxy/list?sub_srv_id=24hours&srv_id=pc&offset=0&limit=199&strategy=1&ext={%22pool%22:[%22top%22,%22hot%22],%22is_filter%22:7,%22check_type%22:true}'
start_urls = spiderUrl.split(";")
protocol =''
hostname =''def__init__(self,*args,**kwargs):super().__init__(*args,**kwargs)# 列表解析defparse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()if plat =='windows_bak':passelif plat =='linux'or plat =='windows':
connect = self.db_connect()
cursor = connect.cursor()if self.table_exists(cursor,'dc9ci_xinwenzixun')==1:
cursor.close()
connect.close()
self.temp_data()return
data = json.loads(response.body)list= data['data']['list']for item inlist:
fields = XinwenzixunItem()
fields["biaoti"]= item['title']
fields["laiyuan"]= item['url']
fields["fabushijian"]= item['update_time']
fields["fenlei"]= item['media_name']
fields["fengmian"]= item['img']
detailUrlRule = item['url']if detailUrlRule.startswith('http')or self.hostname in detailUrlRule:passelse:
detailUrlRule = self.protocol +'://'+ self.hostname + detailUrlRule
fields["laiyuan"]= detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse)# 详情解析defdetail_parse(self, response):
fields = response.meta['fields']try:if'(.*?)'in'''div.content-article''':
fields["xiangqing"]= re.findall(r'''div.content-article''', response.text, re.S)[0].strip()else:if'xiangqing'!='xiangqing'and'xiangqing'!='detail'and'xiangqing'!='pinglun'and'xiangqing'!='zuofa':
fields["xiangqing"]= self.remove_html(response.css('''div.content-article''').extract_first())else:
fields["xiangqing"]= emoji.demojize(response.css('''div.content-article''').extract_first())except:passreturn fields
# 去除多余html标签defremove_html(self, html):if html ==None:return''
pattern = re.compile(r'<[^>]+>', re.S)return pattern.sub('', html).strip()# 数据库连接defdb_connect(self):type= self.settings.get('TYPE','mysql')
host = self.settings.get('HOST','localhost')
port =int(self.settings.get('PORT',3306))
user = self.settings.get('USER','root')
password = self.settings.get('PASSWORD','123456')try:
database = self.databaseName
except:
database = self.settings.get('DATABASE','')iftype=='mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)return connect
# 断表是否存在deftable_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables =[cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list =[re.sub("'",'',each)for each in table_list]if table_name in table_list:return1else:return0# 数据缓存源deftemp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql ='''
insert into xinwenzixun(
biaoti
,laiyuan
,fabushijian
,fenlei
,fengmian
,xiangqing
)
select
biaoti
,laiyuan
,fabushijian
,fenlei
,fengmian
,xiangqing
from dc9ci_xinwenzixun
where(not exists (select
biaoti
,laiyuan
,fabushijian
,fenlei
,fengmian
,xiangqing
from xinwenzixun where
xinwenzixun.biaoti=dc9ci_xinwenzixun.biaoti
and xinwenzixun.laiyuan=dc9ci_xinwenzixun.laiyuan
and xinwenzixun.fabushijian=dc9ci_xinwenzixun.fabushijian
and xinwenzixun.fenlei=dc9ci_xinwenzixun.fenlei
and xinwenzixun.fengmian=dc9ci_xinwenzixun.fengmian
and xinwenzixun.xiangqing=dc9ci_xinwenzixun.xiangqing
))
limit {0}
'''.format(random.randint(20,30))
cursor.execute(sql)
connect.commit()
connect.close()
最后
最新计算机毕业设计选题篇-选题推荐(值得收藏)
计算机毕业设计精品项目案例-200套(值得订阅)
版权归原作者 一点毕设 所有, 如有侵权,请联系我们删除。