
续:【AI底层逻辑】——篇章3(上):数据、信息与知识&香农信息论&信息熵
三、信息是如何交换的
信息量与信息熵都是用来度量信息的,但要真正将信息用起来,信息必须作用在特定对象上——双方必须进行信息交换。当今的信息交换技术已经广泛应用于无线电通信、气象探测、雷达扫描、举例测量、宇宙探索以及人工智能的各个领域。以智能机器人为例,其身上安装有大量的传感器,这些传感器能够捕获图像、声音、受力、周边物体的信息,并实时传送到后台的控制系统,通过信息交换它才能很好的执行操作、使用环境。
1、互联网与信息交换
1969年美国加州大学洛杉矶分校的查理-克莱恩将login这5个字母通过网络传送到距离560千米以外的位于硅谷的斯坦福研究所,这是人类历史上第一次通过网络实现远距离信息交换,使用的这个网络名为阿帕网(ARPAnet),是互联网的前身。
计算机要互相通信,必须遵守一套共同约定的沟通方法——通信协议。通信协议有两个功能:一是要准确找到对方(寻址);二是要知道如何组织内容(编码)。通信网络在最初设计时就考虑到了未来大规模部署的需要,在这样的网络中每个节点都是对等的,没有任何的中央控制节点(“去中心化”),网络只关心“最终把数据信息送到目的地”的结果,不关心“具体走哪条路线”的过程,这是一种非常大胆和创新的信息交换方式。
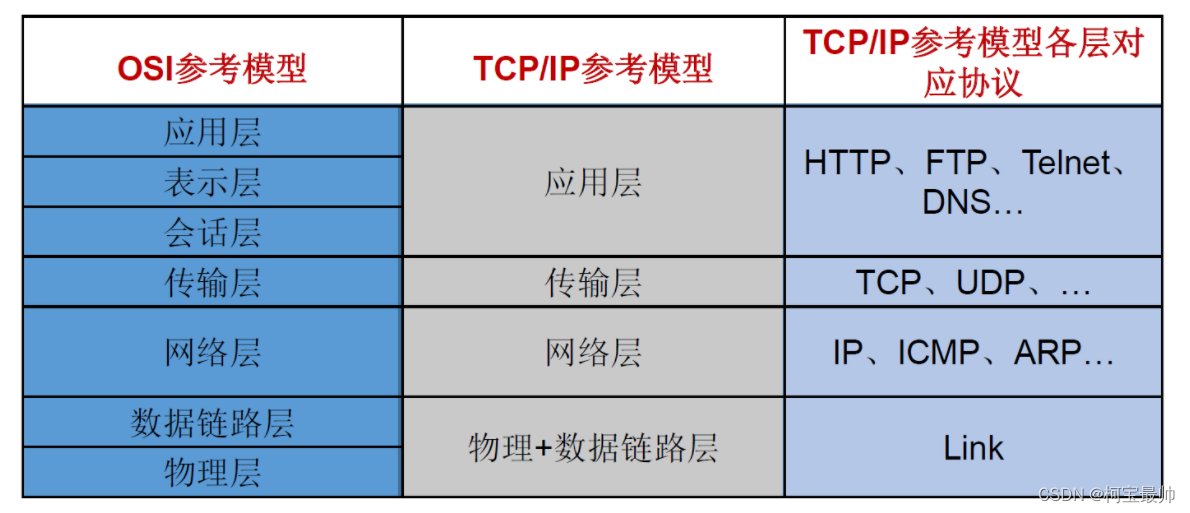
在实际的网络通信模型中,协议是分层的,也更复杂。如要发一封电子邮件,计算机用到的协议可能包括IMAP、SMTP或者POP3;为了保证数据包的稳定传输,计算机之间要遵守TCP/IP,让数据能够顺利找到并传送至目标设备。整个网络通信要依赖不同的网络协议,将复杂的通信问题分解到不同层去解决,本层的功能不会影响其他层,各层完成特定功能,并按照通信协议完成信息交换。无论是网络通信协议中的分层协议,还是其他形式,所有的信息交换都要完成对信息的编码、解码、传输。
编码:把信息转换为信号(电信号),经编码信息才能发出去;解码:把信号再转换为信息,经解码信息才能被接收。信息交换必须使用双方事先约定的语言系统,信息的传递可参考下图:
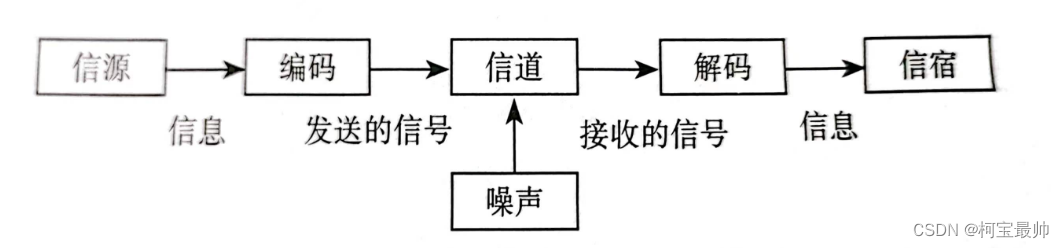
信息发送的起点是信源,它是信息的发送者,如人说话时人、一台机器设备等。信息接收的终点成为信宿,它是信息的接收者。信息传输的媒介称为信道,它是信息传输的通道。信息传递过程中,要想办法将信号源和噪声源剥离出来,避免噪声的干扰,最大概率得到准确的信息,中间有很多抗干扰的技术要做。如果信息在交换中存在冗余和错误,那么信息交换的速率会大打折扣,所以人们试图找到一种最优编码形式来提升信息传递效率。
2、哈夫曼和有效编码
实例引入:关于信息编码,香农曾经做过这样的试验:他从书架上随机选择一本书中的任意一个段落,然后让他的妻子逐个猜里面出现的字母,比如她可以问:“第一个字母是H吗?”。如果她猜错了,就告诉她正确答案。
如果猜对了,就继续猜下一个字母。一开始,这样的猜测没有方向,可随着知道的内容越来越多,猜对字母的准确率会越来越高,甚至可以一下子猜对好多个单词。这是一个通过不断提问来消除不确定的过程(就像海龟汤游戏那样)。
如果一个字母能根据之前的内容猜出来,那它就可能是冗余的。既然是冗余的,它就没有提供额外的信息。假设英语的冗余度是75%,对于一条包含1000个单词的讯息,我们只保留250个单词,仍然可以表达原本的含义。中文也是如此,发一封电报说“家里老母亲过世,请赶快家”,长达12个字,用“母丧速归”4个字也能表达相同的含义,但长度缩减了 2/3。可见,字数越多并不代表信息量就越大,字数只代表了信息编码的长度。在信息论中,这属于编码有效性问题。
那么是否存在一种最短、最优的编码方式呢?
有的,最早由哈夫曼与1952年提出,哈夫曼编码是一种变长编码,它的编码方式是:一条信息编码的长度和它出现概率的对数成正比——经常出现的信息采用较短的编码,不常出现的信息采用较长的编码,以达到整体资源配置最优。在数学上可证明其是最优编码。
信息携带的信息量越大,它的编码就越短,这样做比采用相同码长的编码方法更高效。如果每条信息出现的概率相同,在哈夫曼编码中就是等长编码。平时使用的计算机文件压缩功能,其背后的算法原理通常就是哈夫曼编码,它是一种无损编码方法。
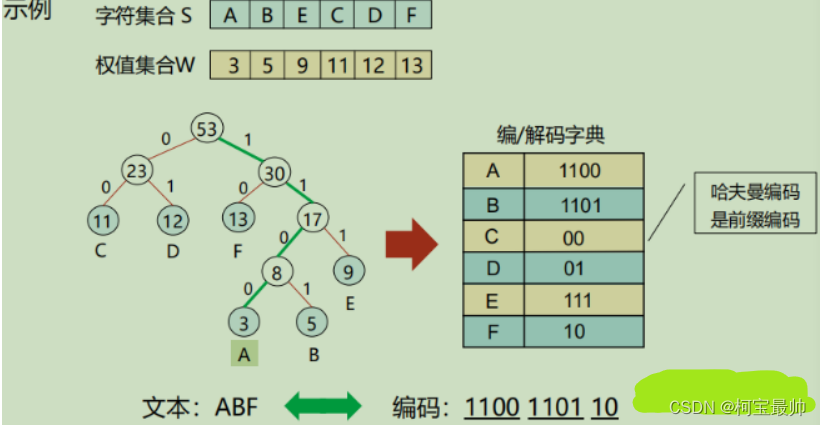
有人认为,对信息的编码越短越好,这样信息交换的成本最低,但实际情况并非如此,因为还要考虑到信息的辨认度和容错性。人类语言的信息编码就存在冗余,它并不是以效率优先的编码方式(人们更喜欢“啰嗦”的方式进行沟通),冗余的信息虽然在传递时消耗了更大的带宽和资源,但是他有更多的容错性,更易于理解,消除了歧义。当信息传递过程中出现了错误,信息冗余可以帮助我们恢复原来的内容。
就像在阅读中学习英语单词比直接被字典记忆得更清!
举一个有趣的信息编码的例子——老鼠实验:
假如实验室里有10只瓶子,其中9瓶装了普通的水,还有1瓶装了毒药,这瓶毒药无法根据气味或外观分辨出来。如果给小白鼠喝了毒药,一天后它就会死亡。假如你只有一天时间,请问至少需要儿只小白鼠,你才能检验出毒药?
如果我们有10 只小白鼠,给每只老鼠喝不同瓶中的水,则自然能检测出哪瓶是毒药,但这么做的效率不高。
让我们来换一种思路,看看用信息编码的方式,应该如何考虑这个问题。让小白鼠喝瓶子中的水,结果只会呈现出2种状态,要么活着、要么死亡。就是说,这只小白鼠可以提供—1og0.5=lbit的信息。我们要从100个瓶子中选出一瓶毒药,相当于需要—log2~9.97bit。也就是说,我们如果有10只小白鼠,提供10bit 的信息,就能找
到那瓶毒药。
具体的操作是这样的:我们先把100个瓶子用1到10编号,这个号码是二进制数,也就是说,每个
瓶子要用10个0或1的数字表示。比如,1号瓶是 000001;2号瓶是000010;以此类推,100号瓶就是11010。再把小白鼠用1到10来编号。现在我们取出一瓶水,查看上面的二进制编号,编号上对应位数是1的,就给相应编号的小白鼠喝下这瓶水。从第1瓶开始,重复这一动作,直到第100瓶。比如,1号瓶的二进制编号是 000001,只有最后一位是1,就给10号小白鼠喝下瓶中的水。2号瓶的二进制编号是0000010,就给9号小白鼠喝水。100号瓶的二进制编号是1110100,就要给1、2、3、4、5、7号小白鼠喝下瓶里的水。
一天以后,我们根据小白鼠的状态获得一个二进制数,0代表生存,1代表死亡。假设1、5、8、9号小白鼠死了,这个二进制数就是1001010,换算成十进制是50。也就是说,第50号瓶中装的是毒药。因此,10只小白鼠相当于一组编码,它能检测出哪瓶是毒药。
可以看到,信息编码并非只能用于信息交换,它还能用于科学研究和实验筛查,很多互联网公司利用信息编码进行分组测试,优化网站使用体验、邮件系统与云存储服务的高效存储、一个AI模型如果要做分布式训练,就要考虑信息编码的效率和安全。
四、信息的加密与解密
信息论首次把信息的加密、交换以及信息本身三者联系在一起,对于信息交换的过程除了有效的编码外,还需要考虑信息安全——这是一个庞大的话题,包含密码学、安全攻势、隐私保护等。
有关信息加密解密的学科就是密码学,它以强大的数学理论为基础,广泛用于用户身份鉴别、网络通信、数据存储、访问控制等方面。密码学中把要传输出去的信息称为明文,把伪装信息以及隐藏真实含义的过程称为加密,加密后的信息是密文,把密文还原成明文的过程称为解密。

1、密码学的发展
19世纪以前的密码学称为古典密码,以手工加解密的形式为主。主流的编码形式有2种:置换、代换。置换就是把信息的字符重新排列组合,代换是通过特定规则使用新的字符替换原来的字符,如凯撒大帝发明的“凯撒密码”。两者也可组合使用,增加破译难度。
19世纪随着通信技术的发展,出现了摩斯电码,这是一种密码系统,当时的研究大多用于政治军事,十分保密。
直到20世纪70年代,密码学才进入大众视野被应用到各领域,后来公钥密码思想的提出,成为密码学发展中重要的里程碑。现代密码学有个显著特点——密码算法的加解密过程可以公开。算法安全依赖于密钥的长短,即使对手知道密码算法的内部机理,如果不知道密钥,则仍然很难破译密文或者要花难以接受的时间,这类算法的细节会公布以接受大众检验和挑战。
密码学界流行这样一种观点:如果密码算法公开后,在相当长时间内没有找到有效的破解算法,就可以认为算法是安全的。体现了柯克霍夫原则——必须考虑密码系统在最坏情况下的安全性,即我们设计加密算法时,要认为对方已经知道算法实现的全部细节。
2、可以被公开的密钥
根据加密、解密过程使用密钥的情况,通常可把加密方法分为:对称加密、非对称加密。
①对称加密,它是一个单钥系统。对称加密在加解密时使用相同的密钥,如古典密码学中的“凯撒密码”就是对称密码算法,特点是计算量小,加密速度快,但如何安全地保管密钥是一个挑战。
它发展较早也称传统密码算法,典型的对称密码算法:DES算法(数据加密标准)、AES算法(高级密码标准)、IDEA算法(国际数据加密算法)等。
它硬件容易实现,适用于大批量数据加密,例如在银行、政府、军队中,当网络之间要传输大量重要数据时会部署网络加密机,这种设备就是使用对称加密传输数据的。
②非对称加密,有两把成对的密钥,即公钥(公开密钥)和私钥(私有密钥)。公钥是公开和共享的,公钥加密的数据只能通过唯一配对的私钥进行解密,对用户来说只需要保管好自己的私钥。安全性更好,但是加解密的速度慢很多。
加密算法主要用来解决消息保密性问题,防止出现信息被窃听的风险,为了确保信息的完整性、真实性和不可否认性,可使用散列函数(如MD5、SHA等)、消息鉴别码(MAC)和算法签名来解决。

拓展:现代密码学正受到量子计算的挑战,量子的特性可能使得量子计算在提高运算速度、确保信息安全、增大
增大信息容量等方面突破现有计算机的能力极限。量子计算机负责计算的元件不是开关和电路,而是微观粒子,
它们没有确定的状态,只能用概率解释其行为,与传统计算机完全不同,他就像变出无数分身去并行解决问题,
然后想办法统计所有结果的概率分布。他擅长并行计算,碾压传统计算机,例如密码学中非对称加密算法RSA的安全性是基于“大数的质因数分解非常困难”这一前提,要破解常见的RSA密文,最好的超级计算机要花60万年,但用量子计算机只需3小时,如果技术成熟或许只需1秒。
五、信息中的噪声
信息在传递的时候有一个不可忽视且无法避免的干扰因素——噪声。信息论中,信噪比一般指有用的信号和干扰信号的比值,这里的信号可理解为信息的载体,由于噪声的存在,信息越多并不代表结果越准确,有时反而会带来更多的问题。——可能会随着层级的提升,噪声被逐级放大,就像王牌对王牌一群人壁画动作向下传递信息一样,越往后越曲解!
噪声也并不是完全不好,正是有了噪声的干扰,那些应对噪声的模型才会变得更加健壮,泛用性更强!
1、AI如何处理噪声
例子①:有关语音识别的问题,如何解决信息失真问题呢?简单来说,计算机要对声源进行定位,增强说话人方向的信号,抑制其他方向的噪声信号。
在嘈杂的晚会人群中,人类想要只与面前的人对话并不难,人具有分辨信息和噪声的能力,但这对机器却很难。计算机要想实现这样的声音分辨,就要对信息和噪声进行处理,当前的语音技术很难在很多人同时说话时表现出高精度,这涉及信息处理理论,如如何提取信息、如何过滤噪声、如何避免信息失真等。
例子②:有关AI模型训练,实现AI的模型主要有人工神经网络模型,网络层次越多,可抽取的特征层次越丰富。但是一个问题存在了很长时间,层数过多,在使用梯度下降方法进行反向传播时,会出现梯度消失的现象。——形象来说,模型通过大量数据进行训练时,优化和修正的“意愿”会逐层向前传递,效果越来越差,由于学习率越来越低到最后可能“意愿”消失,导致模型学习停止。——换种说法,在网络内部通信过程中,噪声被层层放大,最后干扰到了正常信息的传递。
为解决上述问题,方法①:对模型权重做预训练,再进行微调;方法②:优化关于信息传递的函数,如更换网络结构中每层用于判断信息传递的激活函数;方法③:改进模型结构,如直接用新的网络结构,让噪声传递层数逐渐减少。
任何一个智能系统,都会尽可能保留有效的信息忽略噪声,如一个用于人机交互场景的语音识别,它可识别的声音只被设定在特定频率段,很多降噪耳机也是这个原理!
2、模型的泛化能力
泛化能力:模型对全新样本的适应能力,这需要模型可有效的判别信息和噪声。泛化能力可用:偏差、方差、噪声等来评价:
偏差代表了模型的预测期望与真实结果的偏离程度。方差代表了数据变动所导致的模型性能变化,刻画了数据变化所造成的影响。噪声代表了任何模型所能达到的期望泛化误差的下界,刻画了待解决问题本身的难度。——泛化能力是由模型、数据、问题本身的难度共同决定的。
训练模型时,为了使得模型表现更好,就要让模型预测的偏差尽量小;为了充分利用数据,需要想办法让模型预测的方差尽量小。理想情况下,模型的预测结果应该尽量靠近正确值(偏差小),而且表现稳定(方差小),但是由于偏差会随着模型复杂度的增加而降低,方差会随着模型复杂度的增加而增加,因此要在方差和偏差之间找到最优平衡点,使得模型总体的错误表现尽可能小。
3、欠拟合和过拟合
人们曾想在通信系统中完全过滤噪声,但是发现这种绝对理想的情况几乎不可实现。如今普遍认识是,信息和噪声是共存的,信息中有噪声是一种常态。例如,如果要设计一个人脸识别系统,挑战不是完全去除干扰噪声,而是考虑在有噪声的情况下尽可能提高识别准确率,这需要很好的平衡并处理好信息和噪声的关系。这涉及描述模型表现得重要概念——过拟合和欠拟合。
拟合:指统计模型和已知的观察结果相吻合的程度。
过拟合:将噪声误认为是信息的行为,标准太过严苛,难以适应新的情况。
欠拟合:将信息误认为是噪声的行为,学习不到位,原因可能是样本数据不够多或模型本身太简单。

误差:模型的实际预测与样本的真实情况之间的差异。
训练误差/经验误差:模型在训练集上的误差。
测试误差/泛化误差:模型在新样本上的误差。
很明显,我们最后需要的是泛化误差尽量小的模型,但是我们事先并不知道新的样本是怎样的,所以只能努力使经验误差最小化。机器学习常见的是过拟合,原因如样本干扰过多、模型过于复杂、模型参数太多等,解决过拟合常见的方法有:获取额外数据进行交叉验证、重新清洗数据或加入正则化项,简单来说就是对数据做进一步处理,或者增加限制条件。
因此在训练模型时,为了对抗噪声,就要考虑降低模型的复杂度,适当简化模型。如上面叶子的例子,模型无须对照叶子的每个纹路去匹配另一片叶子,但是要识别出叶子的大致轮廓。
总结
当我们用统计方法描述事物变化时,才发现这个世界远比想象中复杂的多,难点在于把模糊、不具体的因素量化,用数字表达就有计算和比较的前提,才能用数学方法预测和决策。信息论让人可以定量化信息和噪声,计算出信息传输的极限等,AI的很多应用都可用信息论去理解——如智能汽车上的激光雷达,会主动探测道路和周边环境,根据电磁波的反射信号来定位目标。
有了前3章的统计学和信息论,人类才真正开启研究AI的大门,现在的问题是:“如何创造出具有‘经验’和‘知识’的AI?”
往期精彩:
【AI底层逻辑】——篇章3(上):数据、信息与知识&香农信息论&信息熵
【机器学习】——续上:卷积神经网络(CNN)与参数训练
【AI底层逻辑】——篇章1&2:统计学与概率论&数据“陷阱”
版权归原作者 柯宝最帅 所有, 如有侵权,请联系我们删除。