
前言
前几篇都围绕着语言模型的decoding strategy来讲述,今天将进入进阶篇,在解码策略效果有限和提示词修改也无法满意的情况下如何提升模型的效果呢?这时我们需要对大语言模型进行fine-tune,即微调。一般我们用的大语言模型都是别人在通用的大数据集上训练过后的,或者已经在特殊领域微调过的,所以可能不适合我们当前所需要模型生成的内容。
本篇将以bloom-1b1模型为例,使用xturing库进行微调,由于微调是特别吃显存的,手里没有大显存卡的可以像我一样使用google的colab服务,保证16GiB及以上的显存。
可以通过命令行里输nvidia-smi查看,如下图所示有40960的MiB,也就是40个Gib。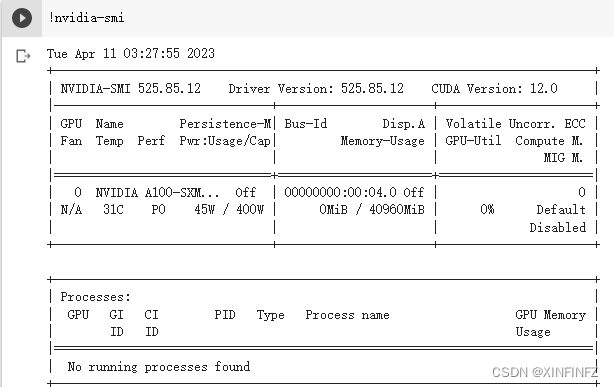
数据集准备

首先要准备一个json文件,里面是一个大list,包含了很多dict,字典的格式是{“instruction”:xxx,“input”:“”,“output”:xxx},instruction表示问题或者指导语,input表示输入,有的时候数学问题需要告诉变量数值,output表示输出,也即文字生成内容。
本例中用的是自己挖掘的中文问题回答数据集,在前一篇文章里有写,感兴趣的自己尝试,这里就不放出来了,而且因为封锁的很严,本例中只挖取了其中500多条问答内容,作为微调的示例。
准备好了json之后,先pip安装datasets库,然后通过如下的代码生成格式数据集:
import json
from datasets import Dataset, DatasetDict
defpreprocess_alpaca_json_data(alpaca_dataset_path:str):
alpaca_data = json.load(open(alpaca_dataset_path))
instructions =[]
inputs =[]
outputs =[]for data in alpaca_data:
instructions.append(data["instruction"])
inputs.append(data["input"])
outputs.append(data["output"])
data_dict ={"train":{"instruction": instructions,"text": inputs,"target": outputs}}
dataset = DatasetDict()# using your `Dict` objectfor k, v in data_dict.items():
dataset[k]= Dataset.from_dict(v)
dataset.save_to_disk(str("./alpaca_data"))
preprocess_alpaca_json_data('你的数据集.json')
调用函数生成完毕后会生成一个文件夹,内容如图所示:
代码
首先如果是在colab里运行,请先保证正确的运行时: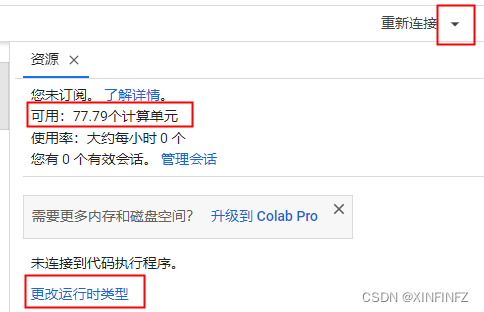
选择gpu-标准或者高级。每小时都会消耗计算单元,我这里是因为上个月开了colab的会员,所以有100个计算单元,普通没会员的用户大概只能用标准白嫖。
然后安装必要的库,这里推荐不用colab的也在linux下运行,除非你对Windows下VS的编译足够自信:
!pip install accelerate
!pip install xturing --upgrade
接下来就是顺风顺水的运行代码:
from xturing.datasets.instruction_dataset import InstructionDataset
from xturing.models.base import BaseModel
instruction_dataset = InstructionDataset("/content/alpaca_data")
model = BaseModel.create("bloom_lora")
刚生成的文件夹路径填进去,然后.create方法里填bloom_lora,默认是bloom_1b1模型,用lora加速训练。
# Finetuned the model
model.finetune(dataset=instruction_dataset)
开始训练,默认是三轮,本例数据集大概用了六分钟就微调好了。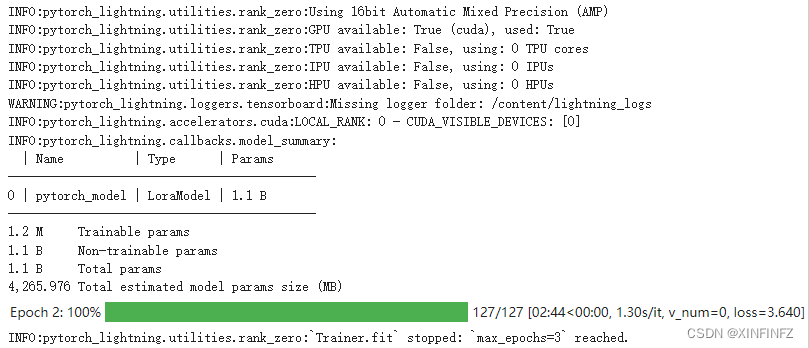
训练完了之后尝试生成,先改下generation_config,也就是解码策略:
generation_config = model.generation_config()
generation_config.top_k =50
generation_config.do_sample =True
generation_config.top_p =0.8
generation_config.max_new_tokens=512
拿今天的热搜问题试试:
# Once the model has been finetuned, you can start doing inferences
output = model.generate(texts=["第一视角进入风暴中心,是种什么体验?"])print("Generated output by the model: {}".format(output))
结果如下:
登陆后第一时间发现风有多狂,能感觉空气怎么突然就凉爽了。
在云层中翻滚,能感受到海面下风的肆虐,云层下也有很多小冰块在打滚。风会从上向下刮,就像是在刮雪一样,刮的特别猛烈,在云层下翻滚。
风暴中心,是风暴的终点,是整个风暴的中心,风向是逆着往复,风向逆着风向,风暴中心就会变成云层,然后刮的特别快,在云层下翻滚,最后消失。
风暴中心,是风暴的最顶端,风向是顺着往复,风向顺着风向,风暴中心就会变成云层,然后刮的特别快,在云层下翻滚,最后消失。
同样的问题使用一样的配置代码对比默认模型生成效果: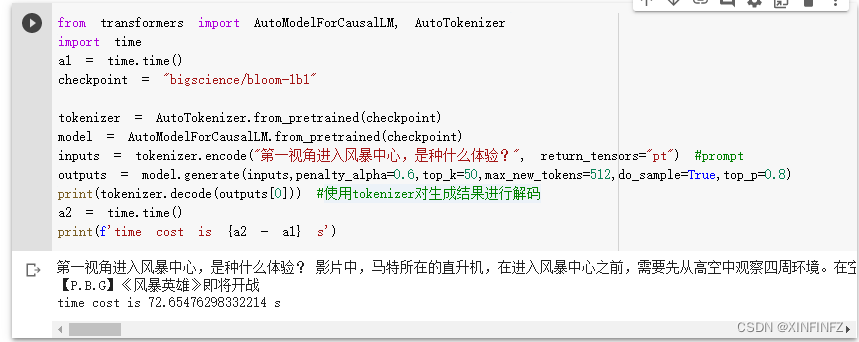
一视角进入风暴中心,是种什么体验?
影片中,马特所在的直升机,在进入风暴中心之前,需要先从高空中观察四周环境。
在空中,除了气象台、直升机、救援队伍,还有各种各样的设备,包括直升机吊舱、直升机降落伞、直升机加油机、直升机导航仪等。
这些设备中,最为核心的部分就是直升机吊舱,
因为直升机吊舱可以搭载直升机和飞机,直升机吊舱的重量相当于一架直升机的载荷,因此可以搭载更多直升机。
可以发现默认模型的中文全在谈直升飞机偏离主题了。。。效果提升明显。
再换个句子生成看看微调后的效果: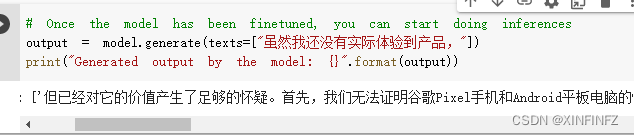
但已经对它的价值产生了足够的怀疑。
首先,我们无法证明谷歌Pixel手机和Android平板电脑的性能有多强。
第二,由于谷歌没有在手机上开发过操作系统,因此谷歌无法从Android平板电脑获得与谷歌Pixel类似的安全性能,即使谷歌Pixel手机使用安卓系统,但Android平板电脑的设备也可能使用非谷歌Android设备,例如,Windows系统。在Android平板电脑上,Android设备运行的是非谷歌Android设备。
第三,谷歌Android平板电脑的电池是无法在谷歌Android平板电脑上长期使用的。
默认模型:
虽然我还没有实际体验到产品,所以不敢给一个准确的答案。
但是从实际体验来说,这款产品确实是十分不错的,我个人觉得颜值和外观设计都是十分不错的,而且售价也确实是不错。
不过我还是建议大家在购买前先了解下这款产品的信息。</s>
从上面可以看出微调确实有效果,那么我该如何保存生成的模型呢?其实在目录下已经有了saved_model的文件夹,只要把它拖到谷歌硬盘里打包下载下来就行了。
版权归原作者 XINFINFZ 所有, 如有侵权,请联系我们删除。