
1.SK Attention模块
链接:Selective Kernel Networks
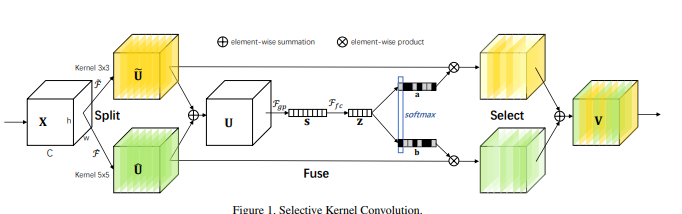
2.模型结构图:
3.论文主要内容
由于不同大小的感受野对于不同尺度的目标有不同的效果,论文目的是使得网络可以自动地利用对分类有效的感受野捕捉到的信息。为了解决这个问题,作者提出了一种新的深度结构在CNN中对卷积核的动态选择机制,该机制允许每个神经元根据输入信息的多尺度自适应地调整其感受野(卷积核)的大小。称为“选择性核(Selective Kernel)”,它可以更好地捕捉复杂图像空间的多尺度特征,而不会像一般的CNN那样浪费大量的计算资源。SKN的另一个优点是它可以聚合深度特征,使它更容易理解,同时也允许更好的可解释性。其灵感来源是,我们在看不同尺寸不同远近的物体时,视觉皮层神经元接受域大小是会根据刺激来进行调节的。具体是设计了一个称为选择性内核单元(SK)的构建块,其中,多个具有不同内核大小的分支在这些分支中的信息引导下,使用SoftMax进行融合。由多个SK单元组成SKNet,SKNet中的神经元能够捕获不同尺度的目标物体。
SKNet网络主要分为Split,Fuse,Select三个操作。Split算子产生多条不同核大小的路径,上图中的模型只设计了两个不同大小的卷积核,实际上可以设计多个分支的多个卷积核。fuse运算符结合并聚合来自多个路径的信息,以获得用于选择权重的全局和综合表示。select操作符根据选择权重聚合不同大小内核的特征图。
总的来说,SKN结构的优势是它可以更有效地捕捉图像空间。
4.代码案例
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDict
# 定义SKAttention类,继承自nn.Module类
class SKAttention(nn.Module):
# 定义初始化函数,channel参数为输入的特征通道数,kernels参数为卷积核的大小列表,reduction参数为降维比例,group参数为卷积组数,L参数为维度
def __init__(self, channel=512,kernels=[1,3,5,7],reduction=16,group=1,L=32):
super().__init__()
# 定义d参数,为L和channel除以reduction中最大值
self.d=max(L,channel//reduction)
# 定义一个nn.ModuleList,用于存放卷积层
#在输入图像上使用不同大小的卷积核卷积,获得多个不同尺寸的特征图;
self.convs=nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([ # 定义一个nn.Sequential,包含一个OrderedDict
('conv',nn.Conv2d(channel,channel,kernel_size=k,padding=k//2,groups=group)),
('bn',nn.BatchNorm2d(channel)),
('relu',nn.ReLU())
]))
)
self.fc=nn.Linear(channel,self.d)
self.fcs=nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d,channel))
self.softmax=nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs=[]
### 对输入input进行分割。使用kernels参数指定的不同卷积核大小,使用同一组卷积参数,对这个input进行卷积操作,从而得到k个不同特征;
for conv in self.convs:
conv_outs.append(conv(x))
feats=torch.stack(conv_outs,0)#k,bs,channel,h,w
### fuse融合层 将这k个特征直接相加,得到融合特征U
U=sum(conv_outs) #bs,c,h,w
### reduction channel 降维层 将这个融合特征U的每一个通道求平均值,得到降维的特征S,然后进行全连接运算
S=U.mean(-1).mean(-1) #bs,c
Z=self.fc(S) #bs,d
### calculate attention weight
weights=[]
#对于这个降维后的特征S,使用多个不同的全连接层fcs,
for fc in self.fcs:
weight=fc(Z)
weights.append(weight.view(bs,c,1,1)) #bs,channel
#把降维后的特征S转换为各个不同卷积核大小特征的权重,
attention_weughts=torch.stack(weights,0)#k,bs,channel,1,1
attention_weughts=self.softmax(attention_weughts)#k,bs,channel,1,1
### fuse 将权重与特征叠加求和,得到最终的融合特征V
V=(attention_weughts*feats).sum(0)
return V
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
本文转载自: https://blog.csdn.net/qq_38915354/article/details/129721180
版权归原作者 深度学习的学习僧 所有, 如有侵权,请联系我们删除。
版权归原作者 深度学习的学习僧 所有, 如有侵权,请联系我们删除。