
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。
考虑到 YOLOv8 的优异性能,MMYOLO 也在第一时间组织了复现,由于时间仓促,目前 MMYOLO 的 Dev 分支已经支持了YOLOv8的模型推理以及通过projects/easydepoly支持部署,我们将尽快发布可训练版本,敬请期待!
官方开源地址:****https://github.com/ultralytics/ultralytics
MMYOLO 开源地址:****https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov8/
按照官方描述,YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
不过 ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
总而言之,ultralytics 开源库的两个主要优点是:
- 融合众多当前 SOTA 技术于一体
- 未来将支持其他 YOLO 系列以及 YOLO 之外的更多算法
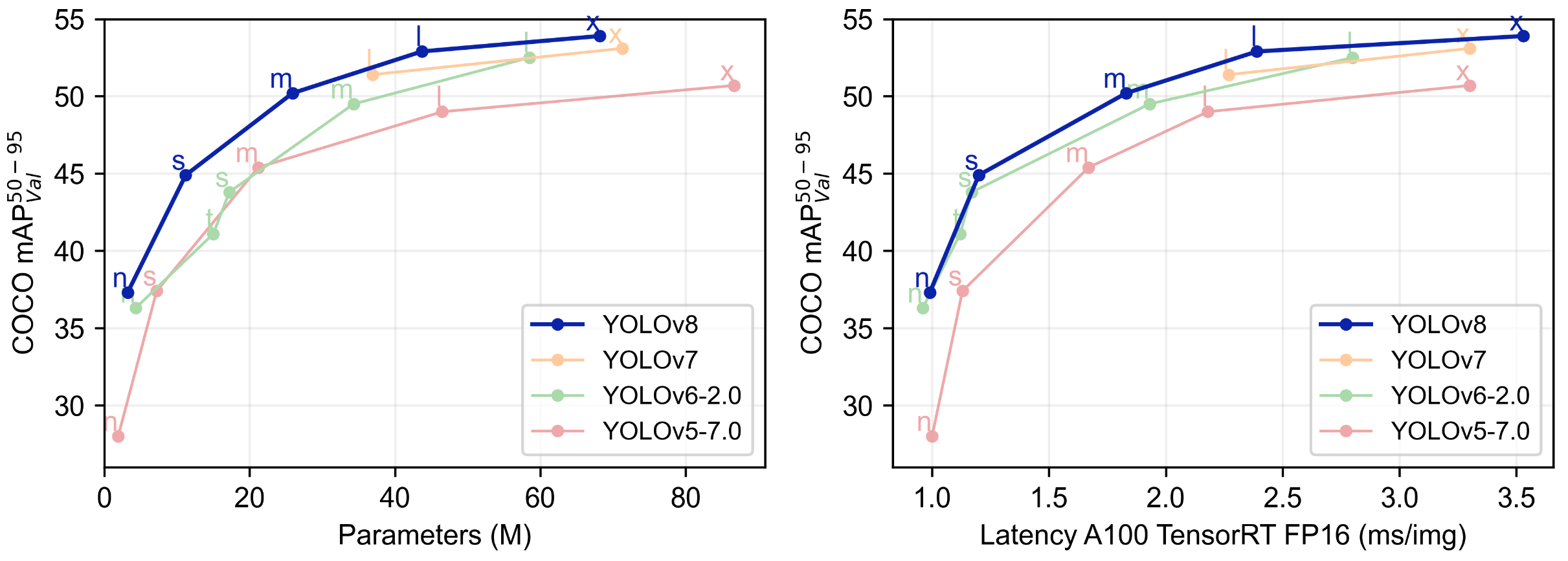
下表为官方在 COCO Val 2017 数据集上测试的 mAP、参数量和 FLOPs 结果。可以看出 YOLOv8 相比 YOLOv5 精度提升非常多,但是 N/S/M 模型相应的参数量和 FLOPs 都增加了不少,从上图也可以看出相比 YOLOV5 大部分模型推理速度变慢了。
模型YOLOv5params**(M)FLOPs@640 (B)YOLOv8params****(M)FLOPs@640 (B)**n28.0(300e)1.94.537.3 (500e)3.28.7s37.4 (300e)7.216.544.9 (500e)11.228.6m45.4 (300e)21.249.050.2 (500e)25.978.9l49.0 (300e)46.5109.152.9 (500e)43.7165.2x50.7 (300e)86.7205.753.9 (500e)68.2257.8
额外提一句,现在各个 YOLO 系列改进算法都在 COCO 上面有明显性能提升,但是在自定义数据集上面的泛化性还没有得到广泛验证,至今依然听到不少关于 YOLOv5 泛化性能较优异的说法。对各系列 YOLO 泛化性验证也是 MMYOLO 中一个特别关心和重点发力的方向。
阅读本文前,如果你对 YOLOv5、YOLOv6 和 RTMDet 不熟悉,可以先看下如下文档:
- YOLOv5 原理和实现全解析 https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/yolov5_description.html
- YOLOv6 原理和实现全解析 https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/yolov6_description.html
- RTMDet 原理和实现全解析 https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/rtmdet_description.html
1 YOLOv8 概述
具体到 YOLOv8 算法,其核心特性和改动可以归结为如下:
- 提供了一个全新的 SOTA 模型,包括 P5 640 和P6 1280 分辨率的目标检测网络和基于YOLACT的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
- 骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
- Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free
- Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
- 训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
从上面可以看出,YOLOv8 主要参考了最近提出的诸如 YOLOX、YOLOv6、YOLOv7 和 PPYOLOE 等算法的相关设计,本身的创新点不多,偏向工程实践,主推的还是 ultralytics 这个框架本身****。
下面将按照模型结构设计、Loss 计算、训练数据增强、训练策略和模型推理过程共 5 个部分详细介绍 YOLOv8 目标检测的各种改进,实例分割部分暂时不进行描述。
2 模型结构设计
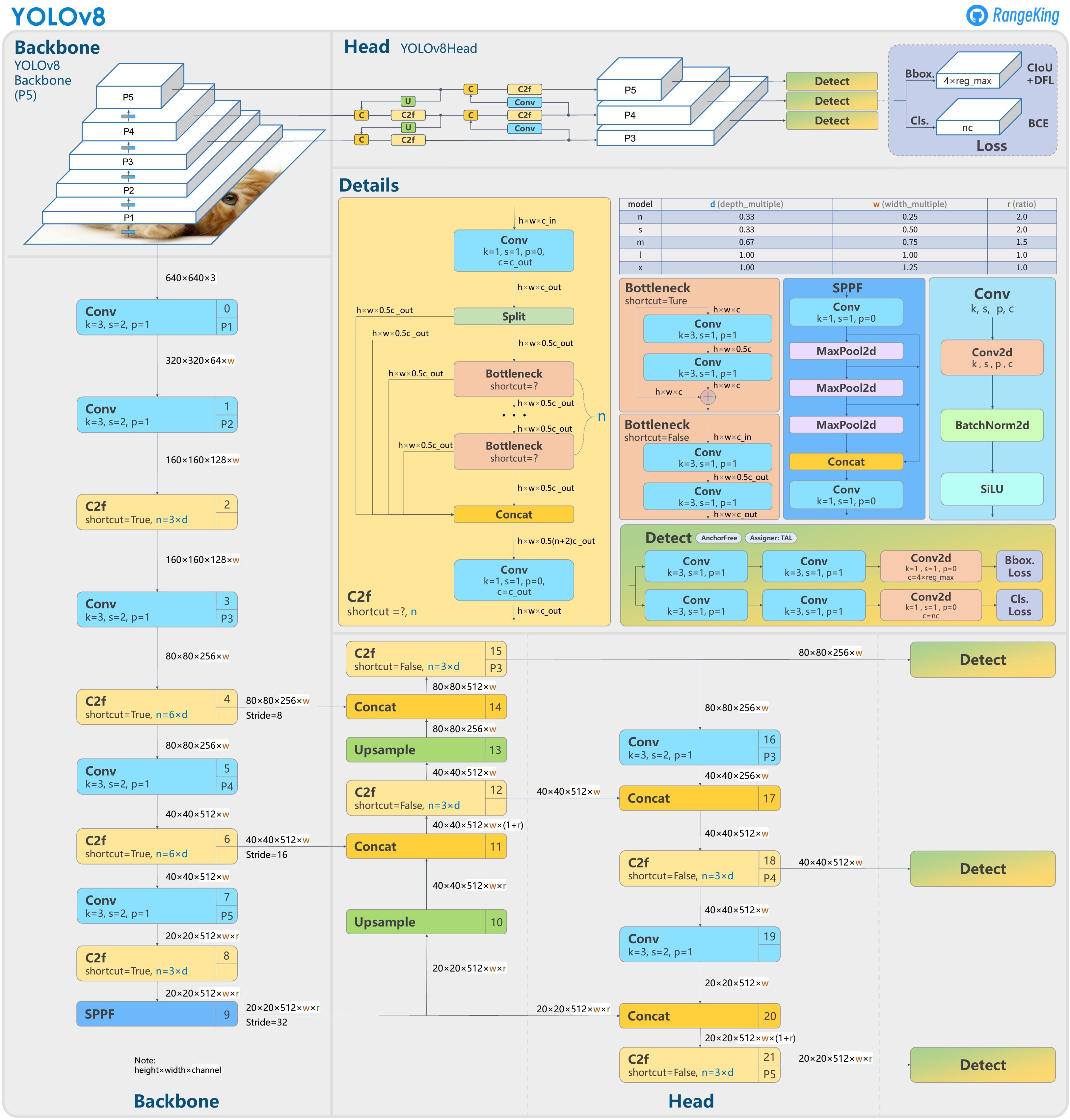
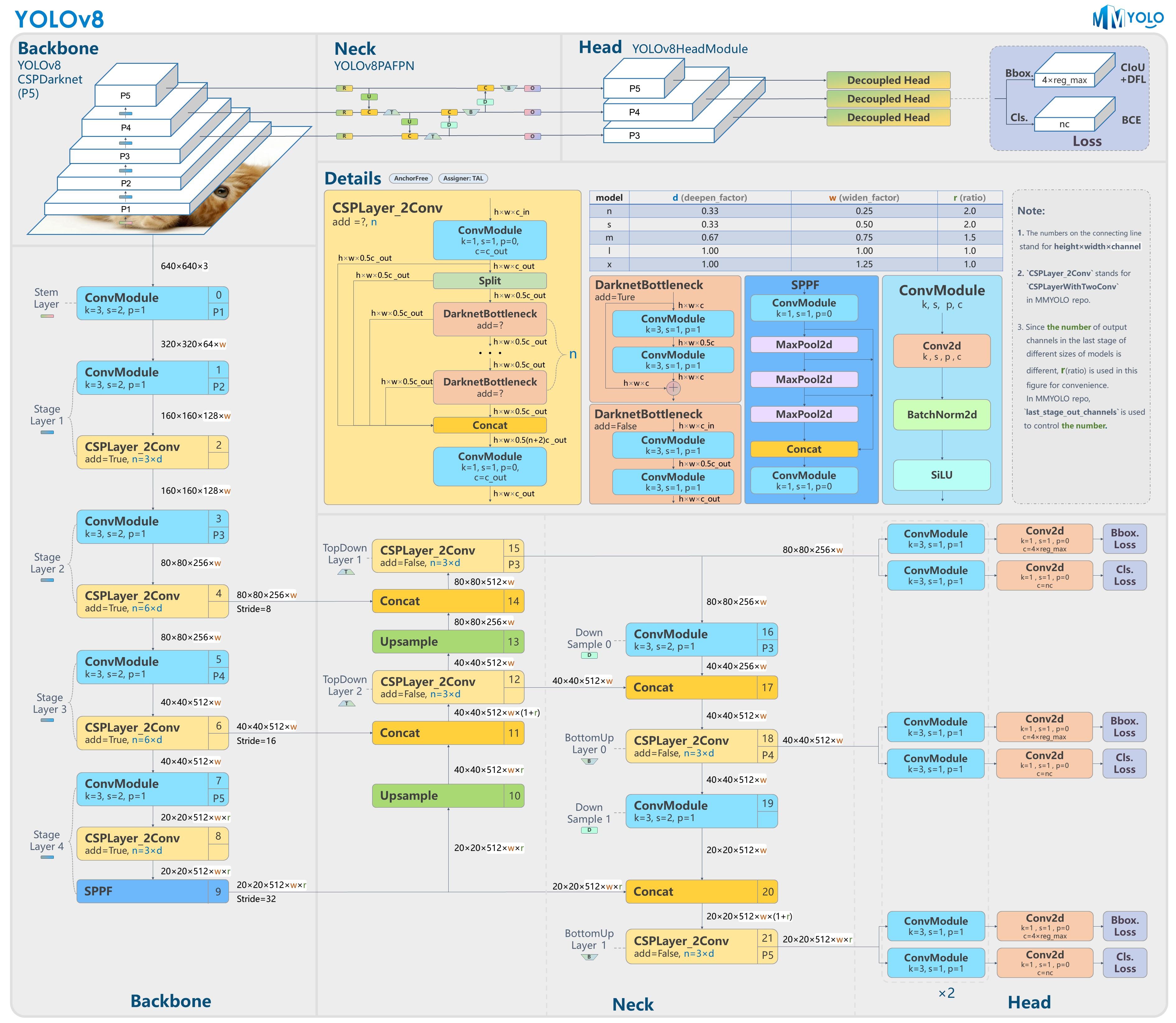
以上为基于 YOLOv8 官方代码所绘制的模型结构图。如果你喜欢这种模型结构图风格,可以查看 MMYOLO 里面对应算法 README 中的模型结构图,目前已经支持了 YOLOv5、YOLOv6、YOLOX、RTMDet 和 YOLOv8。MMYOLO 中重构的 YOLOv8 模型对应结构图如下所示:
详细地址为: https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov8/README.md
在暂时不考虑 Head 情况下,对比 YOLOv5 和 YOLOv8 的 yaml 配置文件可以发现改动较小。
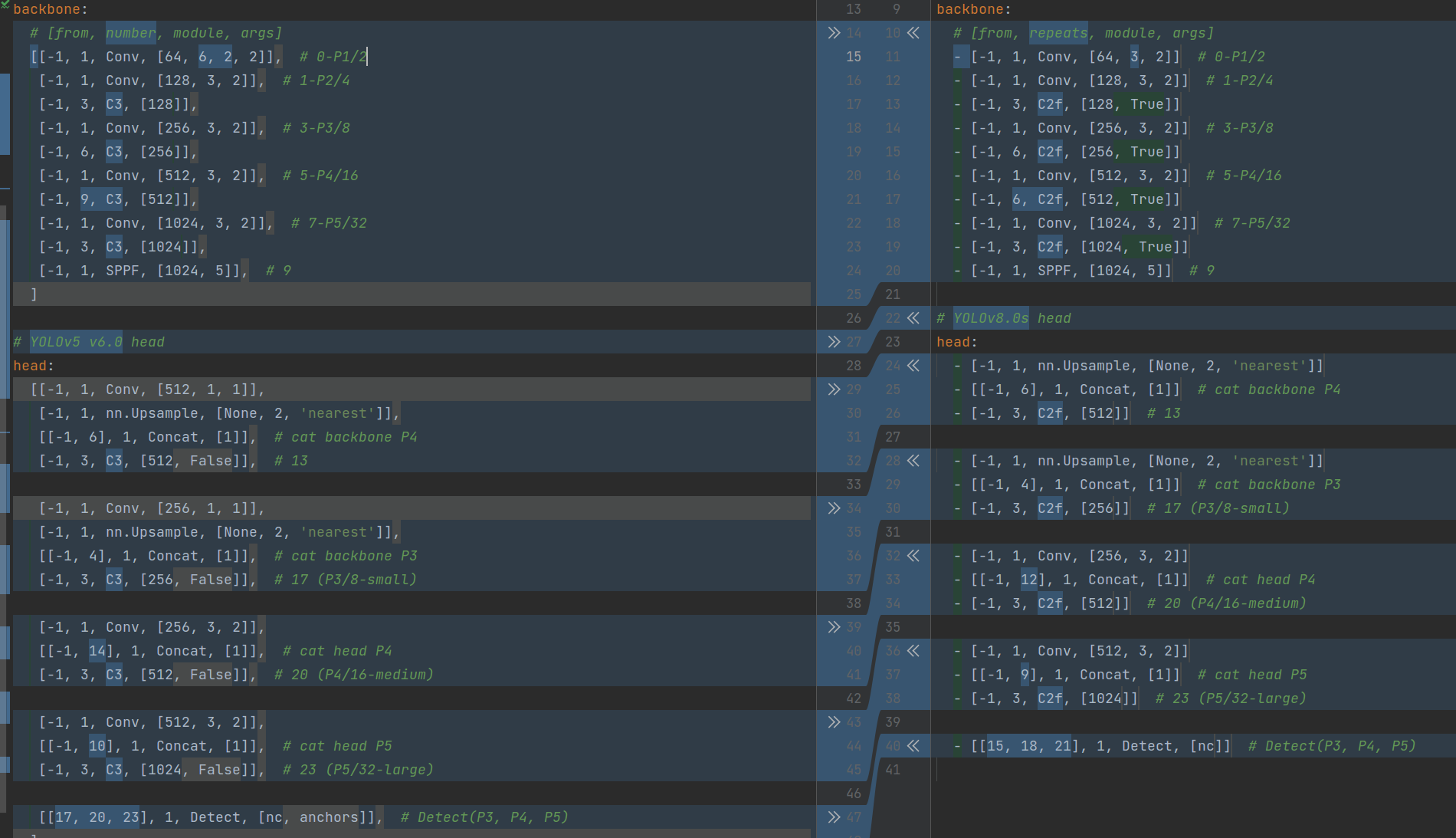
左侧为 YOLOv5-s,右侧为 YOLOv8-s
骨干网络和 Neck 的具体变化为:
- 第一个卷积层的 kernel 从 6x6 变成了 3x3
- 所有的 C3 模块换成 C2f,结构如下所示,可以发现多了更多的跳层连接和额外的 Split 操作
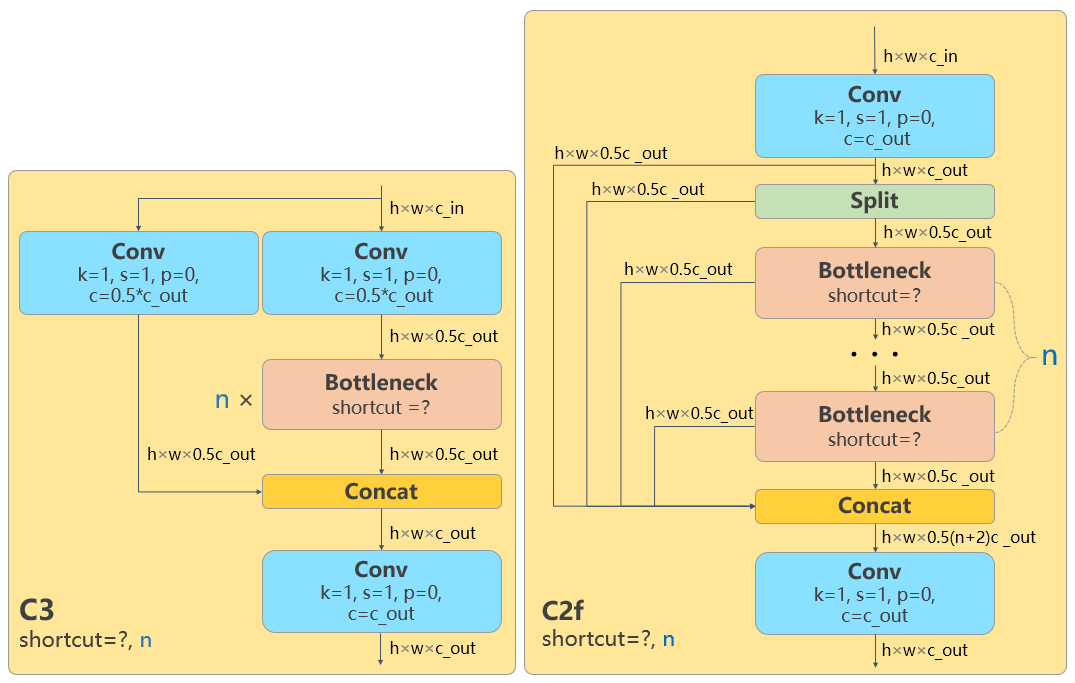
- 去掉了 Neck 模块中的 2 个卷积连接层
- Backbone 中 C2f 的block 数从 3-6-9-3 改成了 3-6-6-3
- 查看 N/S/M/L/X 等不同大小模型,可以发现 N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数。如此设计的原因应该是同一套缩放系数下的通道设置不是最优设计,YOLOv7 网络设计时也没有遵循一套缩放系数作用于所有模型
Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。其结构如下所示:
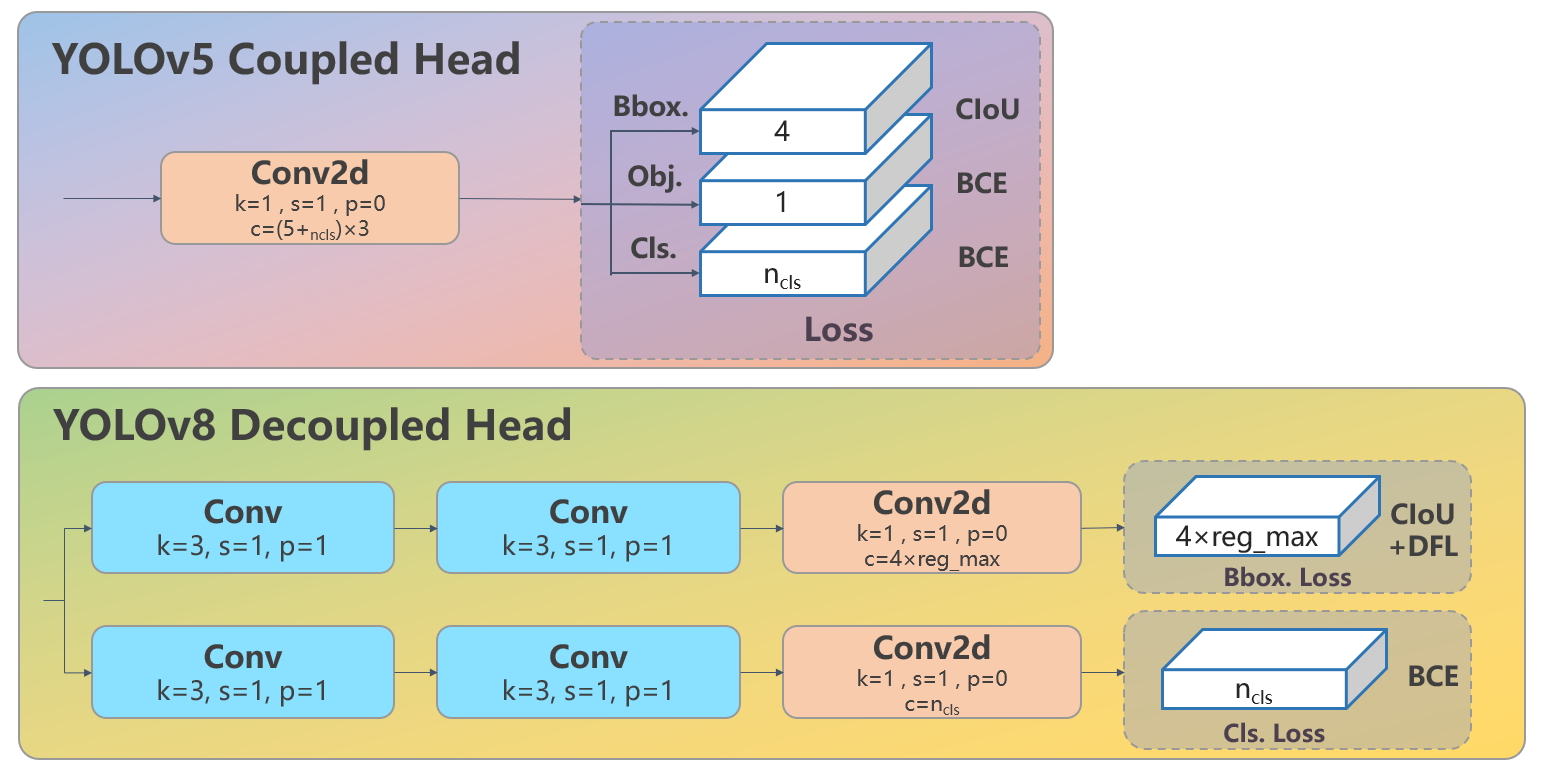
可以看出,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法, DFL 的描述见知乎推文:https://zhuanlan.zhihu.com/p/147691786。
3 Loss 计算
Loss 计算过程包括 2 个部分: 正负样本分配策略和 Loss 计算。
现代目标检测器大部分都会在正负样本分配策略上面做文章,典型的如 YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet 的 DynamicSoftLabelAssigner,这类 Assigner 大都是动态分配策略,而 YOLOv5 采用的依然是静态分配策略。考虑到动态分配策略的优异性,YOLOv8 算法中则直接引用了 TOOD 的 TaskAlignedAssigner。
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
s 是标注类别对应的预测分值,u 是预测框和 gt 框的 iou,两者相乘就可以衡量对齐程度。
- 对于每一个 GT,对所有的预测框基于 GT 类别对应分类分数,预测框与 GT 的 IoU 的加权得到一个关联分类以及回归的对齐分数 alignment_metrics
- 对于每一个 GT,直接基于 alignment_metrics 对齐分数选取 topK 大的作为正样本
Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。
- 分类分支依然采用 BCE Loss
- 回归分支需要和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss
3 个 Loss 采用一定权重比例加权即可。
4 训练数据增强
数据增强方面和 YOLOv5 差距不大,只不过引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作。假设训练 epoch 是 500,其示意图如下所示:
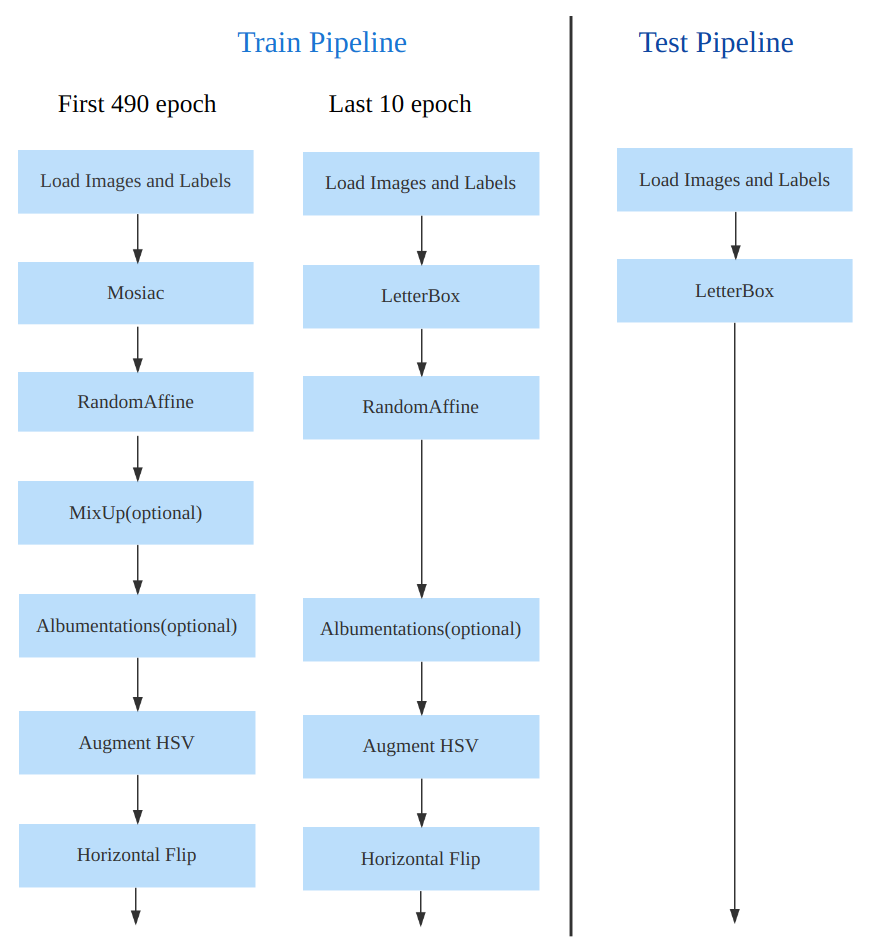
考虑到不同模型应该采用的数据增强强度不一样,因此对于不同大小模型,有部分超参会进行修改,典型的如大模型会开启 MixUp 和 CopyPaste。数据增强后典型效果如下所示:

上述效果可以运行 https://github.com/open-mmlab/mmyolo/blob/dev/tools/analysis_tools/browse_dataset.py 脚本得到
由于每个 pipeline 都是比较常规的操作,本文不再赘述。如果想了解每个 pipeline 的细节,可以查看 MMYOLO 中 YOLOv5 的算法解析文档 https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/yolov5_description.html#id2
5 训练策略
YOLOv8 的训练策略和 YOLOv5 没有啥区别,最大区别就是模型的****训练总 epoch 数从 300 提升到了 500,这也导致训练时间急剧增加。以 YOLOv8-S 为例,其训练策略汇总如下:
配置YOLOv8-s P5 参数optimizerSGDbase learning rate0.01Base weight decay0.0005optimizer momentum0.937batch size128learning rate schedulelineartraining epochs500warmup iterationsmax(1000,3 * iters_per_epochs)input size640x640EMA decay0.9999
6 模型推理过程
YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox,后续计算过程就和 YOLOv5 一样了。
以 COCO 80 类为例,假设输入图片大小为 640x640,MMYOLO 中实现的推理过程示意图如下所示:
暂时无法在飞书文档外展示此内容
其推理和后处理过程为:
(1) bbox 积分形式转换为 4d bbox 格式
对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式
(2) 维度变换
YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。
将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
(3) 解码还原到原图尺度
分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。
(4) 阈值过滤
遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
(5) 还原到原图尺度和 nms
基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。
有一个特别注意的点:YOLOv5 中采用的 Batch shape 推理策略,在 YOLOv8 推理中暂时没有开启,不清楚后面是否会开启,在 MMYOLO 中快速测试了下,如果开启 Batch shape 会涨大概 0.1~0.2。
7 特征图可视化
MMYOLO 中提供了一套完善的特征图可视化工具,可以帮助用户可视化特征的分布情况。
以 YOLOv8-s 模型为例,第一步需要下载官方权重,然后将该权重通过 https://github.com/open-mmlab/mmyolo/blob/dev/tools/model_converters/yolov8_to_mmyolo.py 脚本将去转换到 MMYOLO 中,注意必须要将脚本置于官方仓库下才能正确运行,假设得到的权重名字为 mmyolov8s.pth。
假设想可视化 backbone 输出的 3 个特征图效果,则只需要
cd mmyolo # dev 分支
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean
需要特别注意,为了确保特征图和图片叠加显示能对齐效果,需要先将原先的 test_pipeline 替换为如下:
test_pipeline = [
dict(
type='LoadImageFromFile',
file_client_args=_base_.file_client_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]

从上图可以看出不同输出特征图层主要负责预测不同尺度的物体。
我们也可以可视化 Neck 层的 3 个输出层特征图:
cd mmyolo # dev 分支
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean --target-layers neck

从上图可以发现物体处的特征更加聚焦。
总结
本文详细分析和总结了最新的 YOLOv8 算法,从整体设计到模型结构、Loss 计算、训练数据增强、训练策略和推理过程进行了详细的说明,并提供了大量的示意图供大家方便理解。
简单来说 YOLOv8 是一个包括了图像分类、Anchor-Free 物体检测和实例分割的高效算法,检测部分设计参考了目前大量优异的最新的 YOLO 改进算法,实现了新的 SOTA。不仅如此还推出了一个全新的框架。不过这个框架还处于早期阶段,还需要不断完善。
由于时间仓促且官方代码在不断完善中,如果有不对的地方,欢迎批评和指正。MMYOLO 会尽快地跟进并复现该算法,敬请期待!
MMYOLO 开源地址: https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov8/README.md
MMYOLO 算法解析教程:https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/index.html#id2
版权归原作者 OpenMMLab 所有, 如有侵权,请联系我们删除。