
本文目的在于记录无监督光流估计如何构建损失函数。
主要用于自己的研究项目,并且因为处于刚入门的阶段,因此一些内容可能描述存在问题。(文内的公式可在参考文献处找到)
无监督光流估计损失函数的提出
关于光流估计的相关内容这里不再赘述,本文还是想从无监督的光流估计说起。
无监督光流估计推荐这篇文章:**《What Matters in Unsupervised Optical Flow》**[1]。我认为这篇论文很适合刚接触光流估计的研究者阅读。这篇文章来自2020年ECCV,整篇文章融合了综述与实验。系统地比较和分析了光监督光流中的关键组件:光度损失、遮挡处理、平滑化、自监督。后续的实验也选择了这些关键组件进行实验与比较,虽然这里我认为比较的不够全面,但依然是做了很充足的实验,并且其组合结果最终也达到了当年的最佳性能。

我对损失函数的相关兴趣也来源于这篇文章。这篇文章中提到了无监督光流估计中的两个关键要素:1、代理目标的定义 2、遮挡区域的处理。后者将在其他文章中详细介绍,代理目标其实指的就是损失函数。损失函数在深度学习中一直是很重要的组件,但在监督学习中这一项通常是不会改变的(起到了至关重要的作用)。而在无监督学习中,因为没有监督信号,所以这些损失函数对训练起到了引导作用,网络通常用于提取特征。损失函数是否有效直接影响了能否训练出想要的结果,在 [1] 中,作者也同样说明了目前无监督学习的一个瓶颈就在于损失函数。
首先来看下 [1] 得到的结论:
- 遮挡区域mask、自我监督(self-supervision)和平滑度(smoothness)都很重要
- level dropout 和 cost volume归一化可以改善性能
- census loss优于其他光度损失
- 基于距离图的遮挡估计需要梯度停止才能工作
- edge-aware smoothness 和 smoothness level非常重要
- 自我监督对KITTI的帮助更大
- 损失可能是现在性能的瓶颈
- 改变分辨率可以显著改善效果
- 数据增强和预训练很有帮助
上述9点为论文提出结论,紫色部分是与loss相关的内容,也是本文想要深入研究的。(自监督问题将暂不在本文涉及)
本文讨论的loss选自:**《Upflow: Upsampling pyramid for unsupervised optical flow learning》**[2]
光度损失 photometric loss
光度损失,也可以叫光度一致性(photometric consistency),通过惩罚光度差异来鼓励估计流以相似的外观对齐图像。例如下面一组图片,左侧图片是第一帧图像,右侧图片是将第二帧图像warping后得到的结果。如果估计流完全正确,那么右侧图像的每个像素光度都应该和左侧图像一样(除去无法对齐的区域)。上述就是光度损失的基本原理,基于此有了许多目标,例如Charbonnier loss, SSIM, Census loss等。这些损失也可以结合使用[1, 2]。


基本的光度损失
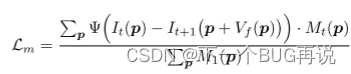
其中:是遮挡Mask,光度损失需要在未遮挡区域进行,这里的遮挡Mask可用向前向后检查估计,其中1表示非遮挡像素,0表示遮挡像素。
是鲁棒惩罚函数。其中
即表示光度差异,只不过后者是通过第二帧warping得到的。
指的是前向光流。
Charbonnier loss
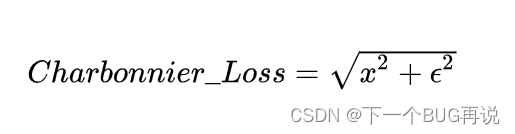
上式便是Charbonnier loss,其实可以看出这是一种提高鲁棒性的计算方式。那么我们在前面基本的光度损失中看到的其实就是这种Loss,只不过在 [2] 中把一些参数进行了一些调整。因此可以看出Charbonnier loss现在已经被广泛的应用。
SSIM
Structural similarity index (SSIM)翻译一下就是结构相似指数,描述的是两图像的结构相似性。该部分的说明来自**《Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation》**[3]。其实我第一次见这个loss是在深度估计里面了。好了,接下来说一下这个函数的具体形式:
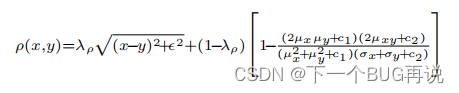
其中,加号后的第二部分才是SSIM,没错,SSIM通常不会单独使用,它一般是和基本的光度损失一起加权求和,可以理解为在光度损失上补充了一些内容(刚好我们可以看到这个公式的第一部分就是Charbonnier loss,很有意思)。 式中,是常数,用于调整和光度损失的权重。
和
是邻域像素的均值和方差。c也是常数。这个公式的原理就不详细阐述了。
这里觉得有意思的一个点是,会发现光度损失是在一点点提升改进的,相互之间是可以融合的。当然是不是越多越好这可能还需要去实验(虽然最近的论文是加的越来越多了)。
Census loss
Census loss首次被提出用于光流估计是**《Unflow: Unsupervised learning of optical flow with a bidirectional census loss》**[4]。Census loss其实也是在基本的光度损失上进行改进,但它不像SSIM对光度损失增加修正项。而是考虑了亮度恒定在现实情况下不完全遵守,即照明也是可能会变化的。该论文使用了三元普查变换对图像进行变换,从而为现实图像提供了一个更可靠的恒定假设。
这里我就不给出公式了,因为它是一种对图像的变换形式。是对局部像素强度排序进行编码的局部二进制模式。其实 [4] 中也没有给出具体形式。其实看完这几种光度损失后可以发现他们的本质就是一种,依然就是光度损失,只是让光度损失越来越符合实际情况。那么可以得到一个初步结论,多种光度损失可以混合使用。(有待进一步验证)
平滑损失 smooth loss
如果说光度损失是光流估计的总指挥,那平滑损失就是就是副指挥。顾名思义,平滑损失可以让图像变得更丝滑,即不会出现相邻像素光流估计值差异过大的情况。平滑损失其实和光度损失一样,在图像领域是被广泛应用的(例如深度估计),其原理也较为简单,即尽量最小化像素与邻域的梯度。
光流估计中的平滑度损失相对麻烦一些,因为运动边界通常与图像边界重合。这里的平滑度损失类似于边缘感知公式,因为被遮挡区域无法使用光度损失指导,只能通过平滑损失(其实后续还有自监督或伪标签的方法,但本文暂不考虑),通过使用边缘感知的平滑惩罚,封闭区域中的光流将与外观最近的邻域中的值相似。下面给出一阶和二阶平滑损失的形式:
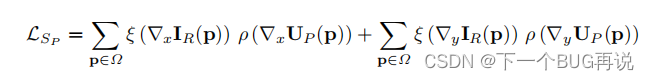
其中,用来降低对比度敏感权重。该公式为一阶平滑损失。
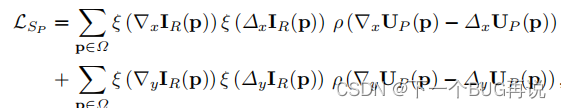
该公式为二阶平滑损失。
这里为什么不对公式内的其余符号详细说明呢?因为每篇论文的框架不同,具体表示形式根据各自特点会有不同,例如 [1] 中的形式如下(一阶):
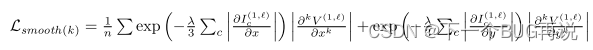
其中V的角标是(1,l),因为该论文将平滑损失使用在了特征提取的中间层。因此没必要对每篇论文的公式形式细究。这个公式其实是边缘感知的平滑损失,而再往上的则是普通版的。这里谈一谈为什么还给出了二阶的形式,因为 [1] 实验二阶形式的平滑损失在KITTI数据集上的训练效果更好,但其余公开数据集则是一阶更好,作者没有给出原因,我目前也没有理解原因。
增强正则化损失 augmentation regularization loss
这个损失很有意思,但它属于自监督(自监督内容太多了,全写在这里太长了,懒得写)的一种,因此本文就不多说了。这里给出相应的论文,感兴趣的研究者可以先自行阅读:**《 Learning by analogy: Reliable supervision from transformations for unsupervised optical flow estimation》** [5]。
边缘扩张翘曲损失 boundary dilated warping loss
这个损失函数提出于:**《Occinpflow: Occlusion-inpainting optical flow estimation by unsupervised learning》**[6]。这篇论文更强调于对遮挡区域的修复,但他们的做法很直接,直接估计外观流(appearance flow)**,**这种流通常应用于图像修复。到这里就可以反应过来,遮挡区域的光流估计可以从另一个角度理解为图片的缺失破损,因此也可以修复。
其实这个损失函数的核心在于提出了边缘扩张翘曲来代替普通的翘曲方法。在我的其他博文中会有对遮挡区域的介绍,但其实遮挡区域除了图像内因移动引起的遮挡外,还存在因相机移动和图像大小导致的边界遮挡。而该论文就是提出了一种新的翘曲方法用来解决后一种情况。首先,该网络在训练时是将图像裁减后反馈至网络的。下面是裁减图像与原始图像的对应关系,其中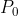是裁剪区域在原始图像中的左上角坐标。
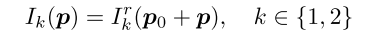
另外需要保证裁减图像总是被原始图像覆盖,就好像原始图像时裁减图像的扩张版本。因此引入了边缘扩张翘曲。在之后计算其余损失时均使用边缘扩张翘曲。
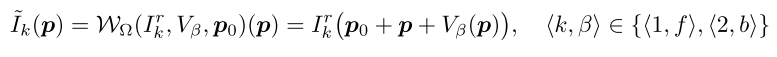
这一部分准确来讲应该叫外观损失。这个损失函数更多的关注物体的边界,从前面的讲述中可以发现,其实图像的每一个像素都会影响光度损失,再加上平滑loss的引导。另外由于计算光度损失时是需要warping的,边界会有扩张效应。因此该函数目的在于在边界处让光流更精细。下面给出具体的形式:
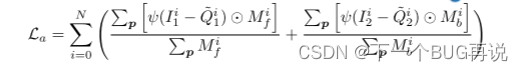
其中和
分别是前向和后向的遮挡区域掩码,
是利用外观流warping得到。这个公式和基本的光度损失公式太像了,相信如果仔细看了前面内容的研究者看到这里可以瞬间理解。
最后谈一下我对这个函数的看法,可以用但不一定必要。是否使用这个损失函数要根据具体任务需要,该loss的关注点在于边界处的精细程度,具体效果对比可以看原文。如果你的任务对细节要求很高,那么我推荐使用这个函数(毕竟水平还是很高的,很适合提高公开数据集用来打榜的指标)。如果不追求极限的性能,其实没必要用,因为这个函数对整体的光流估计结果影响不会太大,当然最主要的原因是还需要使用外观流,需要耗费更多的资源(原文使用了2块2080Ti,训练了48 hours)。如果你的资源非常丰富,当然可以使用,如果资源相对紧张,可根据任务需要自行决定。
到这里就算结束了,其实还有很多光流估计的无监督损失函数,但想全部写完还是太难了。总结一下其实目前大致有这几个方向的损失函数:
- 光度损失:无监督光流估计的总指挥,目前依然在不断完善中,新提出的大部分内容可以相互融合。
- 平滑损失:无监督光流估计的副指挥,概念和公式基本已经固定,虽然有阶数的不同,但整体很少有人考虑改进提高该函数(也可能我没看到)。
- 自监督损失:无监督光流估计的特色副指挥,其实我认为它起到的作用和平滑损失是差不多大的,这在 [1] 中也提到了,但加了个“特色”,是因为不同人使用的方法是不同的(提创新点的好来源)。该部分内容我后续会单独写一篇博客。
- 其余损失:无监督光流估计的将军,之所以叫这一类“将军”,是因为这些损失函数不会起到决定性的作用,但它们会提高光流估计的精度。其实目前光流估计的主流网络结构已经基本固定(提一嘴监督学习的RAFT,做出了很大创新改进),都能大体上估计出光流了,那么要做的就是让光流更精细,在细枝末节上继续提升。
参考文献
[1] Jonschkowski R, Stone A, Barron J T, et al. What matters in unsupervised optical flow[C]//European Conference on Computer Vision. Springer, Cham, 2020: 557-572.
[2] Luo K, Wang C, Liu S, et al. Upflow: Upsampling pyramid for unsupervised optical flow learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1045-1054.
[3] Ranjan A, Jampani V, Balles L, et al. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 12240-12249.
[4] Meister S, Hur J, Roth S. Unflow: Unsupervised learning of optical flow with a bidirectional census loss[C]//Proceedings of the AAAI conference on artificial intelligence. 2018, 32(1).
[5] Liu L, Zhang J, He R, et al. Learning by analogy: Reliable supervision from transformations for unsupervised optical flow estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 6489-6498.
[6] Luo K, Wang C, Ye N, et al. Occinpflow: Occlusion-inpainting optical flow estimation by unsupervised learning[J]. arXiv preprint arXiv:2006.16637, 2020.
光流估计我目前研究也没有非常深刻,另外是第一次写博客,如果有问题或建议欢迎指出讨论!
边缘扩张翘曲损失已于2022/10/29日修正部分内容!
版权归原作者 下一个BUG再说 所有, 如有侵权,请联系我们删除。