
一.验证二叉搜索树的前序序列
- 验证前序遍历序列二叉搜索树 - 力扣(LeetCode) (leetcode-cn.com)
题目描述:

解题思路:
- BST的性质是左子树小于root,右子树大于root,所以校验这个性质即可。
- 首先找到数组开始位置大的值即找到比根节点大的那个值,如果所给序列是二叉搜索树的前序序列,那么往后的序列都是根的右子树,也就必须满足后面的树都有大于根节点。如果不满足则肯定不是二叉搜索树,如果满足我们则将整个序列分成两部分递归子子树部分和右子树部分如果这两个部分满足那么这个序列就是二叉搜索树的前序序列。
对应代码:
class Solution { public: bool verifyPreorder(vector<int> &preorder) { return checkBSTPreorder(preorder, 0, preorder.size() - 1); } bool checkBSTPreorder(vector<int> &preorder, int begin, int end) { if (begin >= end) { return true; } int index = begin; while (index <= end && preorder[index] <= preorder[begin]) //找到第一个小于preorder[left] //的数 { index++; } //检查后面是否有小于根节点值如果有说明不是二叉搜索树的前序序列 int tmp = index; while (tmp <= end) { if (preorder[tmp] <= preorder[begin]) { return false; } tmp++; } //检查左子树和右子树是不是 return checkBSTPreorder(preorder, begin + 1, index - 1) && checkBSTPreorder(preorder, index, end); } };
但是很遗憾时间复杂度太高了超时。下面介绍另外一种方法
方法二:单调栈
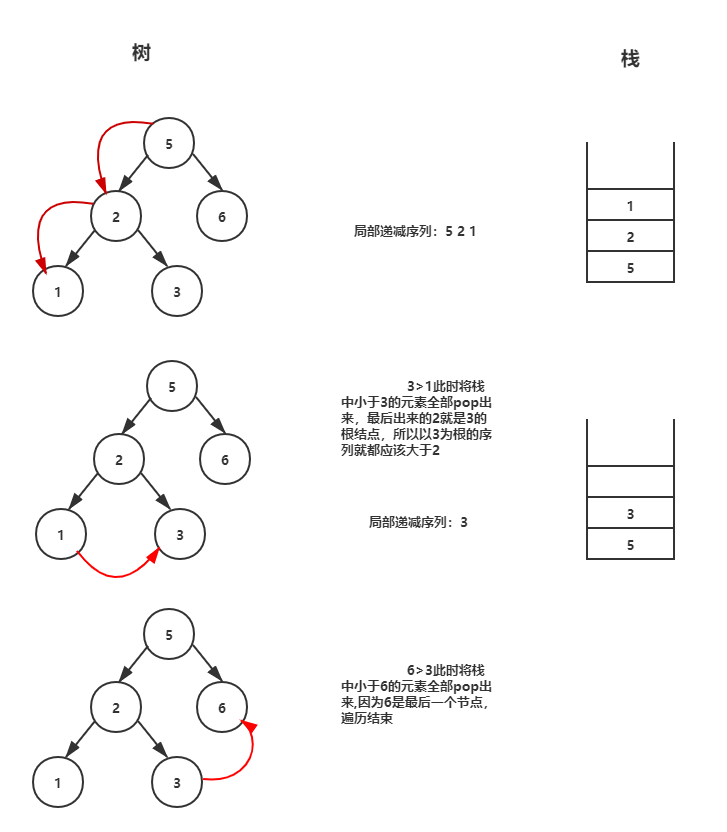
二叉搜索树是left < root < right的,先序遍历又是root->left->right的,基于这样的性质和遍历方式,我们知道越往左越小,这样,就可以构造一个单调递减的栈,来记录遍历的元素。
为什么要用单调栈呢,因为往左子树遍历的过程,value是越来越小的,一旦出现了value大于栈顶元素value的时候,就表示要开始进入右子树了(如果不是,就应该继续进入左子树,不理解的请看下二叉搜索树的定义),但是这个右子树是从哪个节点开始的呢?
单调栈帮我们记录了这些节点,只要栈顶元素还比当前节点小,就表示还是左子树,要移除,因为我们要找到这个右孩子节点直接连接的父节点,也就是找到这个子树的根,只要栈顶元素还小于当前节点,就要一直弹出,直到栈顶元素大于节点,或者栈为空。栈顶的上一个元素就是子树节点的根。
接下来,数组继续往后遍历,之后的右子树的每个节点,都要比子树的根要大,才能满足,否则就不是二叉搜索树。
对应代码:
class Solution { public: bool verifyPreorder(vector<int>& preorder) { int Min=INT_MIN;//最小值 stack<int>stk; for(int i=0;i<preorder.size();i++) { // 右子树元素必须要大于递减栈被top访问的元素,否则就不是二叉搜索树 if(preorder[i]<Min)//不满足搜索二叉树的性质 { return false; } while(!stk.empty()&&preorder[i]>stk.top()) { // 数组元素大于单调栈的元素了,表示往右子树走了,记录下上个根节点 // 找到这个右子树对应的根节点,之前左子树全部弹出,不在记录,因为不可能在往根节点的左子树走了 Min=stk.top();//更新最小值 stk.pop(); } stk.push(preorder[i]);//入栈; } return true;//说明是二叉搜索树的前序遍历 } };
二.前序遍历还原二叉搜索树
- 前序遍历构造二叉搜索树 - 力扣(LeetCode) (leetcode-cn.com)
题目描述:

解题思路:
题目给我们的是二叉搜索树的先序遍历,那么毫无疑问第一个元素就是整颗树的根结点。而二叉搜索又有如下性质:
1.左子树的所有节点的值小于根节点。
2.右子树的所有节点的值大于根节点。
所以我们可以遍历这个数组找到第一个比根节点大的元素,那么从这个元素开始往后都是右子树部分。这样我们就可以将数组划分为[左子树]根[右子树].在递归把左子树和右子树构建好即可。以[8,5,1,7,10,12]为例,8是根节点,比8小的[5,1,7]是他左子树上的值,比他大的[10,12]是他右子树上的值。所以可以参照二分法查找的方式,把数组分为两部分,他是这样的:
然后左边的[5,1,7]我们再按照上面的方式拆分,5是根节点,比5小的1是左子节点,比5大的7是右子节点。同理右边的[10,12]中10是根节点,比10大的12是右子节点,这样我们一直拆分下去,直到不能拆分为止,所以结果是下面这样:


对应代码:
class Solution { public: TreeNode* bstFromPreorder(vector<int>& preorder) { return buildTree(preorder,0,preorder.size()-1); } TreeNode*buildTree(vector<int>&preorder,int left,int right) { if(left>right) return nullptr;//区间不存在说明没有数了 int index=left;//从开始位置查找第一个比preorder[left]大的数 //将其划分为[left+1,index-1]左子树[left]根[inde,right]//右子树 while(index<=right&&preorder[index]<=preorder[left]) { index++; } //[left+1,index-1]左子树[left]根[inde,right] TreeNode*root=new TreeNode(preorder[left]);//根节点 root->left=buildTree(preorder,left+1,index-1);//构建左子树 root->right=buildTree(preorder,index,right);//构建右子树 return root; } };
本题是否可以优化呢?我们发现我们每一次都要去找右边比他大并且离他最近的那一个元素这样的时间复杂度为O(N^2)。而这不正好是单调栈干的事情吗?所以我们可以使用单调栈提前预处理优化掉这个遍历操作。让时间复制度降为O(N)。对应代码
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { public: TreeNode* bstFromPreorder(vector<int>& preorder) { int N=preorder.size(); vector<int>nearBig(N,-1);//用于存储一个元素右边比他大并且离他最近位置的小标 //全部先设置为-1是为了提前解决结算阶段,栈中元素右边没有比他大的了 stack<int>stk; for(int i=0;i<N;i++) { while(!stk.empty()&&preorder[stk.top()]<preorder[i]) { nearBig[stk.top()]=i; stk.pop(); } stk.push(i); } return buildTree(preorder,0,preorder.size()-1,nearBig); } TreeNode*buildTree(vector<int>&preorder,int left,int right,vector<int>&nearBig) { if(left>right) return nullptr;//区间不存在说明没有数了 //将其划分为[left+1,index-1]左子树[left]根[inde,right]//右子树 /* while(index<=right&&preorder[index]<=preorder[left]) { index++; }*/ int index=nearBig[left]==-1?right+1:nearBig[left]; //[left+1,index-1]左子树[left]根[inde,right] TreeNode*root=new TreeNode(preorder[left]);//根节点 root->left=buildTree(preorder,left+1,index-1,nearBig);//构建左子树 root->right=buildTree(preorder,index,right,nearBig);//构建右子树 return root; } };
三.二叉搜索树的后序遍历
剑指 Offer 33. 二叉搜索树的后序遍历序列 - 力扣(LeetCode) (leetcode-cn.com)
题目描述:

解题思路:
本题解题思路和上题基本一莫一样,先找到根节点然后从右往左找到第一个比根节点小的数然后将其划分为左子树和右子树,在判断左子树中是否有比根节点大的数如果有说明不是二叉搜索树的后序遍历,如果都比根节点要小就递归左子树和右子树。左子树和右子树同时满足那么就满足。下面以[3,5,4,10,12,9]为例:
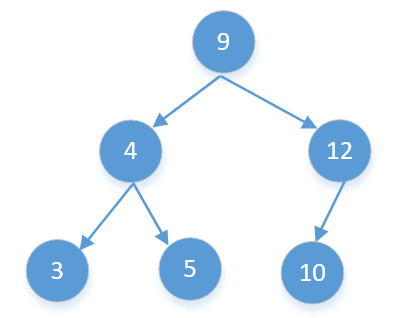
我们知道后续遍历的最后一个数字一定是根节点,所以数组中最后一个数字9就是根节点,我们从前往后找到第一个比9大的数字10,那么10后面的[10,12](除了9)都是9的右子节点,10前面的[3,5,4]都是9的左子节点,后面的需要判断一下,如果有小于9的,说明不是二叉搜索树,直接返回false。然后再以递归的方式判断左右子树。
再来看一个,他的后续遍历是[3,5,13,10,12,9]。
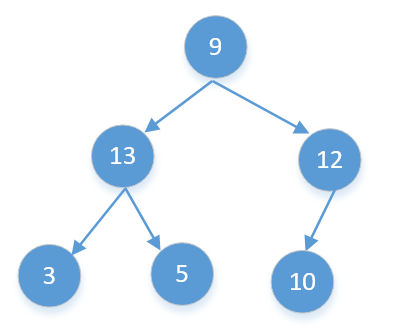
们来根据数组拆分,第一个比9大的后面都是9的右子节点[13,10,12]。然后再拆分这个数组,12是根节点,第一个比12大的后面都是12的右子节点[13,10],但我们看到10是比12小的,他不可能是12的右子节点,所以我们能确定这棵树不是二叉搜索树。搞懂了上面的原理我们再来看下代码。
class Solution { public: bool verifyPostorder(vector<int>& postorder) { return checkBSTPost(postorder,0,postorder.size()-1); } bool checkBSTPost(vector<int>&nums,int left,int right) { if(left>=right) return true; int index=right;//找到第一个比根节点小的树那么前面的及它自己都是左子树部分 while(index>=left&&nums[index]>=nums[right]) { index--; } int tmp=left;//检查前面的左子树部分是否有大于根节点 while(tmp<index) { if(nums[tmp]>nums[right]) { return false; } tmp++; } //递归检查左子树和右子树 return checkBSTPost(nums,left,index)&&checkBSTPost(nums,index+1,right-1); } };
解法二:单调栈
我们都知道后序遍历是左右根如果我们将其倒过来看是不是就变成根右左。此时我们就可以使用单调栈(右侧递增)。
观察一下二叉搜索树的结构,将后序遍历进行倒序查看,后序遍历倒序: [ 根节点 | 右子树 | 左子树 ]
从根节点到右子树到右子树的右子树...是一个递增的序列,如6, 8, 9
当不再递增时意味着出现了某个子树的左子树节点,如7
我们将连续递增的节点放入一个栈中,当出现不再递增的节点时,对栈中节点依次出栈,直到栈中没有比它大的节点存在。
那么最后一次出栈的节点就是他的父节点,不断更新父节点的值,每次判断当前节点是否大于父节点值,如果大于肯定是错误的。

对应代码:
class Solution { public: bool verifyPostorder(vector<int>& postorder) { int Max=INT_MAX; stack<int>stk; for(int i=postorder.size()-1;i>=0;i--) { if(postorder[i]>Max) { return false; } while(!stk.empty()&&postorder[i]<stk.top()) { Max=stk.top(); stk.pop(); } stk.push(postorder[i]); } return true; } };
版权归原作者 一个山里的少年 所有, 如有侵权,请联系我们删除。