
1、自动切图拼图预测
PaddleDetection/configs/smalldet at release/2.5 · PaddlePaddle/PaddleDetection (github.com)
将训练数据,按照网络输入的固定尺度进行切图,例如,网络输入是640x640,就按照从上到下,从左到右的方法,切割出一个个的640x640的子图(相互之间有交叉),然后基于子图做训练。
这样做的好处,就是相当远放大了小目标在图中的相对尺寸,从而可以提供更多的特征,否则,按照原始尺寸去学习,做一次resize后,本来就很小的目标就会变得更小,甚至在特征图中的激活几乎没有响应,因此难以学习。
基于子图训练好的模型,在预测的时候,将待测试的图片,按照相同的切图方法切分成多个子图,然后对多个子图做预测,然后,将多个子图的结果用nms的方法做过滤,nms计算时使用ios,也就是交小比来判断是否重合,去除掉重复的部分检测框。
优点:
- 对于很小的物体,有很明显的提升
缺点:
- 在重合部位做合并的时,可能会有类别判断错误或者边框预测不准的情况导致无法合并的情况。
- 由于一张图被切分成了多个块,一次推理也就变成了多次推理,因此推理速度成倍的增加,不太实用。
2、利用底层特征
对于类似yololo系列的多尺度特征融合做检测的网络来说,大部分为了兼顾速度和精度,基本都使用的是下采样1/8,1/16,1/32后的三个特征层来做特征融合和预测,
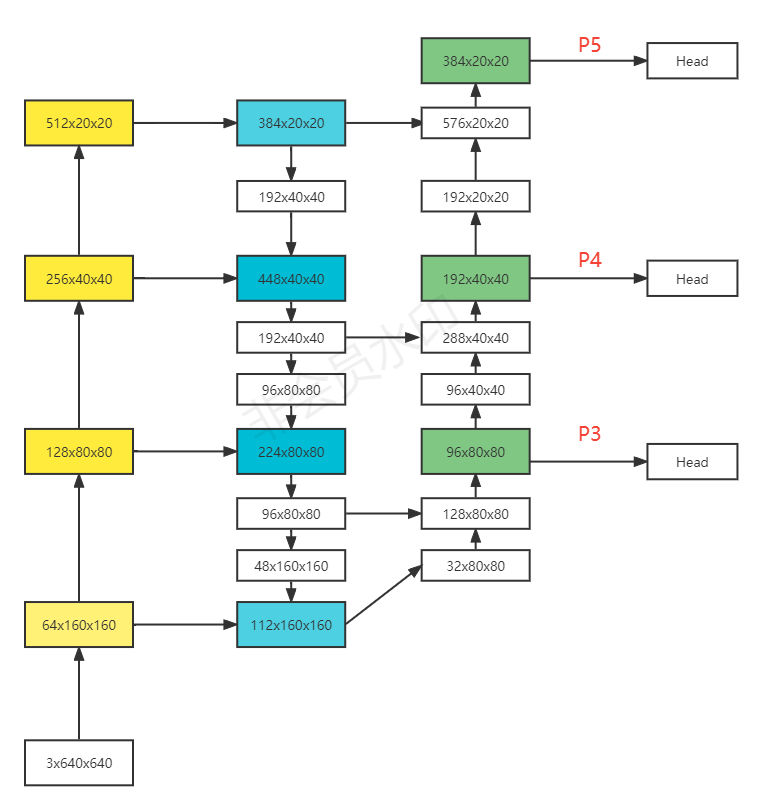
而从感受野的角度来考虑,越是底层的特征图上的感受野越小,底层特征也就越局部,尺寸较大的目标,因为感受野较小,根本学习不到大目标应该有的全局特征,
而尺寸较小的目标正好在底层的特征图上可以很好的保留和学习到,越往上层,小目标的特征越来越小,特征图上的响应越来越弱,甚至消失,
而高层特征图中能够响应的,也正好是经过多次下采样后留下来的尺度较大的目标,因此:
- 底层特征适合预测小目标
- 高层特征适合预测大目标
所以,在检测小目标时,应该将尺度最大的底层特征也加进来一起学习和预测,对应图中的160x160的这一层,命名为P2。
再实际测试ppyoloe的模型效果后,得出结论:
- 增加了P2特征层后,模型对于小目标的检测效果大幅提升。
- 对于比较轻量的模型,耗时增加很小。
2、SNIPER
PaddleDetection/README_cn.md at release/2.5 · PaddlePaddle/PaddleDetection (github.com)
版权归原作者 村民的菜篮子 所有, 如有侵权,请联系我们删除。