
一、GAN
1、应用
GAN的应用十分广泛,如图像生成、图像转换、风格迁移、图像修复等等。
2、简介
生成式对抗网络是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model,G)和判别模型(Discriminative Model,D)的互相博弈学习产生相当好的输出。
- 判别模型:判断一个实例是真实的还是由模型生成的
- 生成模型:生成一个假实例来骗过判别模型
两个模型相互对抗,最后达到一个平衡(纳什均衡),即生成模型生成的实例与真实的没有区别,判别模型无法区分输入数据是真实的还是由生成模型生成的。(G recovering the training data distribution and D equal to 1/2 everywhere)
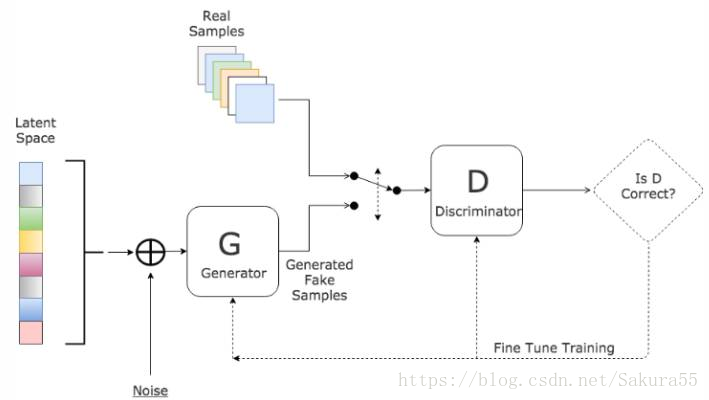
3、 GAN的损失函数

- z:随机噪声
:随机噪声z服从的概率分布
:生成器,输入为噪声z,输出为假图像
:真实数据服从的概率分布
:判别器,输入为图像,输出为该图像为真实图像的概率
上式可分为两部分来理解:给定G,找到使V最大化的D;另一部分是给定D,找到使V最小化的G
第一部分:给定G,找到使V最大化的D
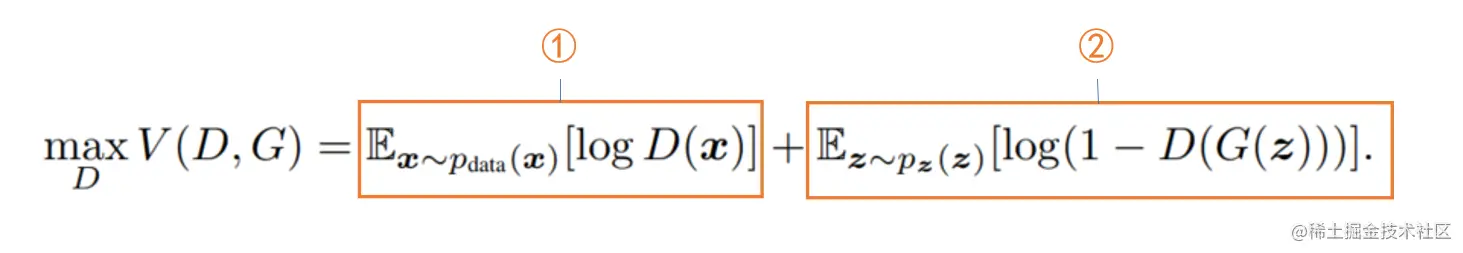
①部分,因为判别器此时的输入为x,是真实数据,EX∼Pdata[logD(X)]值越大表示判别器认为输入x为真实数据的概率越大,D能力越强,因此这一项的输出越大(越接近于1)越好。
②部分,此时判别器的输入是G(z),即输入为假图像,那么对于D(G(Z))来说这个值越小,表示判别器判定假图像为真实数据的概率越小,同样表示D能力越强。此时②为log(1-D(G(z))的期望,当D越强时,D(G(z))值越小,而Ez∼pz(z)[log(1−D(G(Z)))]越大。(①和②都想使给定G,D效果最好,都需要最大化V)
第二部分:给定D,找到使V最小化的G
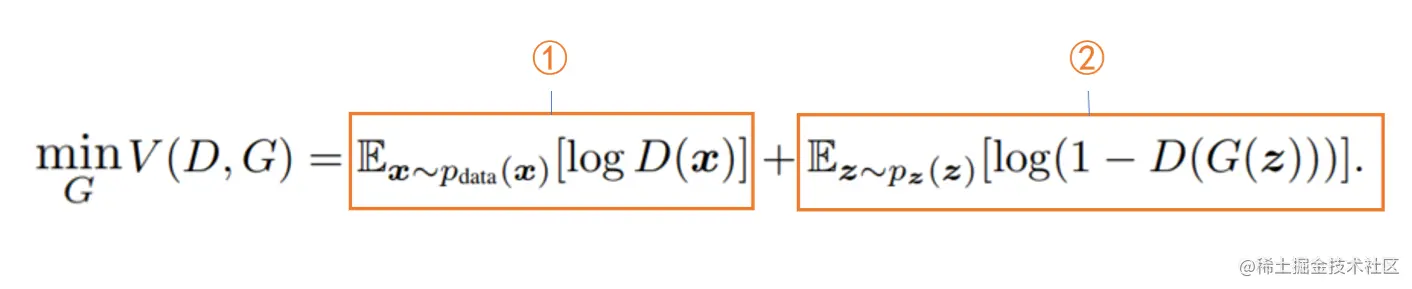
①部分,因为给定了D,①只与D有关,所以这部分是常量。
②部分,此时判别器D的输入为G(z),为假图像,但是我们期望的是生成器的效果好,即尽可能的瞒过D,也就是期望D(G(z))尽可能大,越大表示D判定假图像为真实数据的概率越大,也就表明生成器G生成的图像效果好,可以成功的骗过D。D(G(z))越大,Ez∼pz(z)[log(1−D(G(Z)))]越小,因此给定D ,找到最小化V的G会使生成器的效果最好。
4、GAN流程
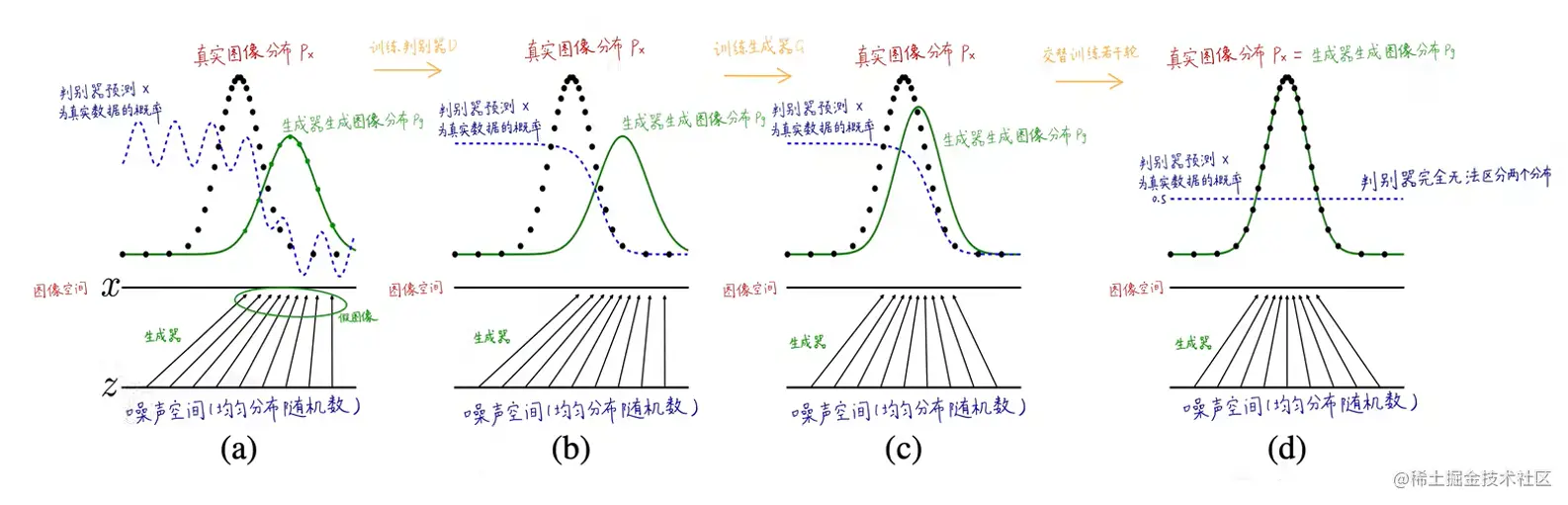
黑点表示真实图像的分布,绿点表示生成图像的概率分布,蓝点表示判别器预测x为真实数据的概率。
下图是GAN网络的伪代码:

注意:训练过程中,训练k次判别器,训练一次生成器(交替训练);训练生成器的过程中,去掉了第一项,因为固定了D,可省略。
在训练的时候,D(G(z))越大越接近于1,y越小,生成器生成的假图越被判别器误判为真图。但训练刚开始时,生成的图像太假,太容易被判别器识破,D(G(z))接近0,log(1-D(G(z)))饱和无梯度,所以将最小化log(1-D(G(z)))变为最大化log(D(G(z)))

5、GAN的特点以及优缺点
生成器G并不知道原始的数据分布Pg(x),它只是通过判别器的反馈(是否骗过判别器)来不断地更新自己
特点:
- 相比较传统的模型,他存在两个不同的网络,而不是单一的网络,并且训练方式采用的是对抗训练方式
- GAN中G的梯度更新信息来自判别器D,而不是来自数据样本
优点:
- GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了
反向传播,而不需要复杂的马尔科夫链 - 相比其他所有模型, GAN可以产生更加
清晰,真实的样本 - GAN采用的是一种
无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域
缺点:
- 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以
训练GAN是不稳定的 - GAN不适合处理离散形式的数据,比如文本
- GAN存在训练不稳定、梯度消失、模式崩溃的问题
文本数据相比较图片数据来说是离散的,因为对于文本来说,通常需要将一个词映射为一个高维的向量,最终预测的输出是一个one-hot向量,假设softmax的输出是(0.2, 0.3, 0.1,0.2,0.15,0.05)那么变为onehot是(0,1,0,0,0,0),如果softmax输出是(0.2, 0.25, 0.2, 0.1,0.15,0.1 ),one-hot仍然是(0, 1, 0, 0, 0, 0),所以对于生成器来说,G输出了不同的结果但是D给出了同样的判别结果,并不能将梯度更新信息很好的传递到G中去,所以D最终输出的判别没有意义。
三、WGAN
1、简介
WGAN全称为Wasserstein Generative Adversarial Networks,旨在解决GAN难train的问题。
2、GAN为什么训练困难
- GAN网络的损失函数

为了方便表述,对上述公式做调整:
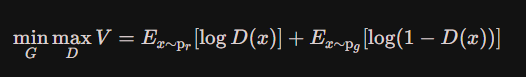
即把最后一项的G(z)用x来表示,x为生成器生成的分布。
现在期望求得生成器固定最大化判别器D:
- 首先,对于一个随机的样本,它可能是真实样本也可能是生成的样本,对于这个样本的损失为:
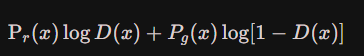
预求最大化的D,则对上式的D(x)求导,并让导函数为0,即:
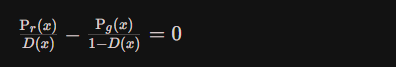化简上式,得到最优的D表达式为:

若表示x完全服从生成分布,是假图像,所以最优判别器D给出的概率为0;反之,x完全服从真实分布,是真图像,所以最优判别器D给出的概率为1;若
,表示x服从真实分布和服从生成分布的数据一样多,因此最优判别器D给出的概率为50%。
现已找到最大化的D,现要将其固定,寻找最小化的G
- 即求下式:
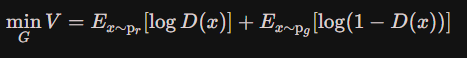
- 将最大化的D即D∗(x)带入上式得:
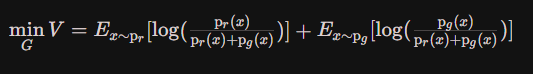
- 化简得:式1
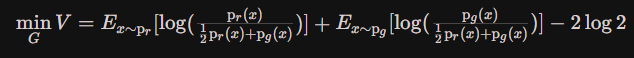
化简成上式,是为了和KL散度和JS散度相联系(散度可以理解为距离的意思)
- KL散度
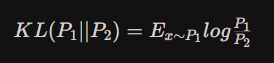
上式是用期望来表示KL散度的,也可以用积分或者求和的形式来表示,如下:

如图,大致解释一下KL散度含义:

- JS散度
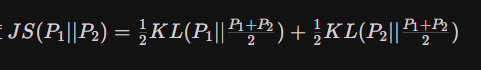
可以看出,JS散度是根据KL散度来定义的,它具有对称性。
根据JS散度,可以将式1变换成如下式:
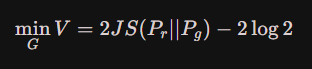
GAN中使用的就是JS散度的形式。GAN训练困难很大程度是JS散度的原因。
结论:根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布与生成分布之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化真实分布和生成分布之间的JS散度。
上述看似非常合理,只要我们不断训练,真实分布和生成分布越来越接近,JS散度越来越小,直到两个分布完全一致,此时JS散度为0.
但是JS散度并不会随着真实分布和生成分布越来越近而使其越来越小,而是保持log2不变
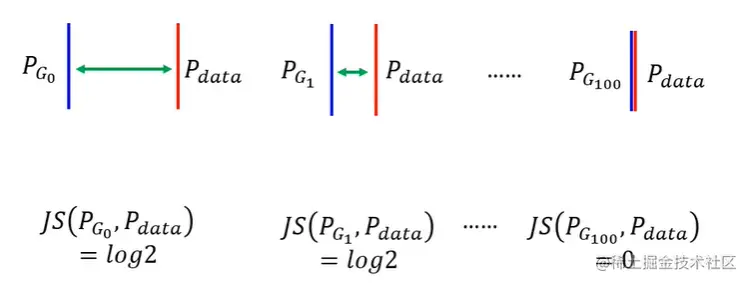
JS散度就一直是常数log2,也就是在训练过程中loss一直不发生变化,这也意味着生成器的梯度一直为0,即生成器产生了梯度消失的现象。
- 为什么两个分布不重叠,JS散度一直为log2?
证明:https://blog.csdn.net/Invokar/article/details/88917214
- 生成器梯度不再更新,为什么在训练GAN时还是得到一些比较好的结果呢?
3、Wasserstein
WGAN提出一种新的度量两个分布距离的标准-Wasserstein Metric,也叫Earth-Mover distance
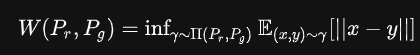
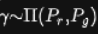 是Pr和Pg组合起来的所有可能的联合分布的集合,反过来说,
是Pr和Pg组合起来的所有可能的联合分布的集合,反过来说,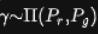 中每一个分布的边缘分布都是Pr和Pg。对于每一个可能的联合分布γ而言,可以从中采样(x,y)~γ得到一个真实样本x和一个生成样本y,并计算出这对样本的距离||x-y||,所以可以计算该联合分布γ下样本对距离的期望值E[||x-y||]。在所有可能的联合分布中能够对这个期望值取到的下界
中每一个分布的边缘分布都是Pr和Pg。对于每一个可能的联合分布γ而言,可以从中采样(x,y)~γ得到一个真实样本x和一个生成样本y,并计算出这对样本的距离||x-y||,所以可以计算该联合分布γ下样本对距离的期望值E[||x-y||]。在所有可能的联合分布中能够对这个期望值取到的下界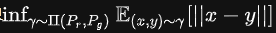
就定义为Wasserstein距离。
直观上可以把E[||x-y||]理解为在γ这个“路径规划”下把Pr这堆“沙土”挪到Pg“位置”所需的“消耗”,而W(Pr,Pg)就是“最优路径规划”下的“最小消耗”。参考下例:
https://juejin.cn/post/7150940183218061348
结论:Wasserstein距离是平滑的,不是像JS散度是突变的过程,这样在训练时,即使两个分布不重叠Wasserstein距离仍然可以提高梯度。
WGAN的实现
直接使用Wasserstein距离来定义生成器的损失是困难的,因为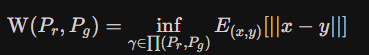
是难以直接求解的,因此作者用了一个已有的定理将它变换如下:公式14
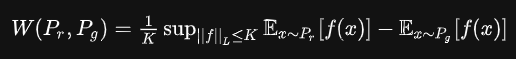
- Lipschitz连续:在一个连续函数f上面额外施加了一个限制,要求存在一个常数K≥0使得定义域内的任意两个元素x1和x2都满足 | f(x1)-f(x2) | <= K| x1-x2 |,此时称函数f的Lipschitz常数为K。很显然,lipschitz连续就限制了f的斜率的绝对值小于等于K,这个K称为Libschitz常数。
这样,我们只需要找到一个lipschitz函数,就可以计算Wasserstein距离了。
具体做法:用一组参数w来定义一系列可能的函数fw。把f用一个带参数的w的神经网络来表示。由于神经网络的拟合能力足够强大,这样定义出来的一系列fw虽然无法囊括所有,但可以高度近似。

总:可以构造一个含参数w,最后一层不是非线性激活函数层的判别器网络fw,在限制w不超过某个范围的条件下,使得:公式15
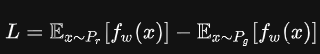
尽可能取到最大。此时L就会近似真实分布与生成分布之间的Wasserstein距离。注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器fw做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
接下来生成器要近似地最小化Wasserstein距离,可以最小化L,由于Wasserstein距离的优良性质,我们不需要担心生成器梯度消失的问题。再考虑到L的第一项与生成器无关,就得到了WGAN的两个loss。

公式15是公式17的反,可以指示训练进程,其数值越小,表示真实分布与生成分布的Wasserstein距离越小,GAN训练得越好。
WGAN与原始GAN形式相比,只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
WGAN本作引入了Wasserstein距离,由于它相对KL散度与JS散度具有优越的平滑特性,理论上可以解决梯度消失问题。接着通过数学变换将Wasserstein距离写成可求解的形式,利用一个参数数值范围受限的判别器神经网络来最大化这个形式,就可以近似Wasserstein距离。在此近似最优判别器下优化生成器使得Wasserstein距离缩小,就能有效拉近生成分布与真实分布。
二、CycleGAN

1、简介
CycleGAN全称:**
Unpaired Image-to-Image Translationusing Cycle-Consistent Adversarial Networks,即非成对图像
转换一致性网络。这里的非成对图像指的是训练样本是不相关的,因为成对的样本很难获取。
**
2、循环一致性对抗网络
现有两个域的图像,分别为域X和域Y,例如域X表示夏季图片,域Y表示冬季图片,现期望两个域的图片互相转换,即输入域X的夏季图片生成器输出域Y的冬季图片或者输入域Y的冬季图片生成器输出域X的夏季图片
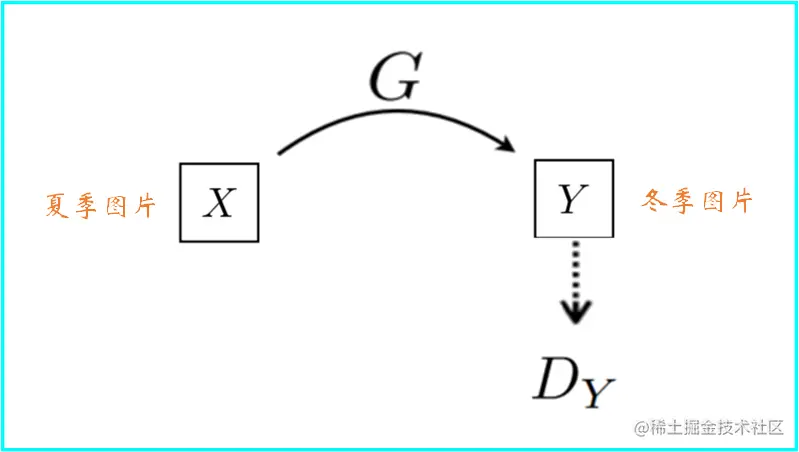
域X的图片经生成器不断生成图片G(X),而D鉴别生成的图片和域Y中的图片,这样就构成了一个GAN网络,这样域X中的图片不断向域Y转换,但是会出现如下效果:

上图确实是将域X中图片转换成了域Y中冬季图片风格,但是转换后的图片和原始图片没有任何关系,即GAN网络只学到了把一张夏季图片转化为冬季图片,但至于转换后的冬季图片和原始夏季图片有没有关系没有学习到,这样的话这个网络肯定是不符合实际要求的。那么CycleGAN就提出了循环一致性网络,如下图所示:
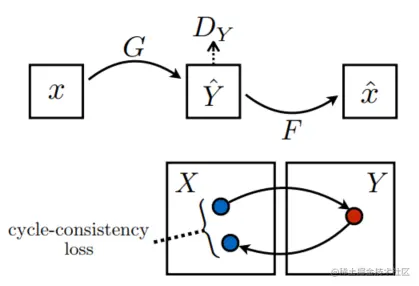
x表示域X中的图像数据,Y^表示x经生成器G生成的图片域,x^表示Y^中的图片经过生成器F生成的图片数据,DY表示判别器,用于判别图片是来自域Y还是G(x)。
上述循环一致性大致过程为 x --> G(x) -->F(G(x))≈x^,即设置损失让x和x^尽可能相似。
上述介绍完了从域X转域Y的过程,那么域Y转域X也是一样的。整体:
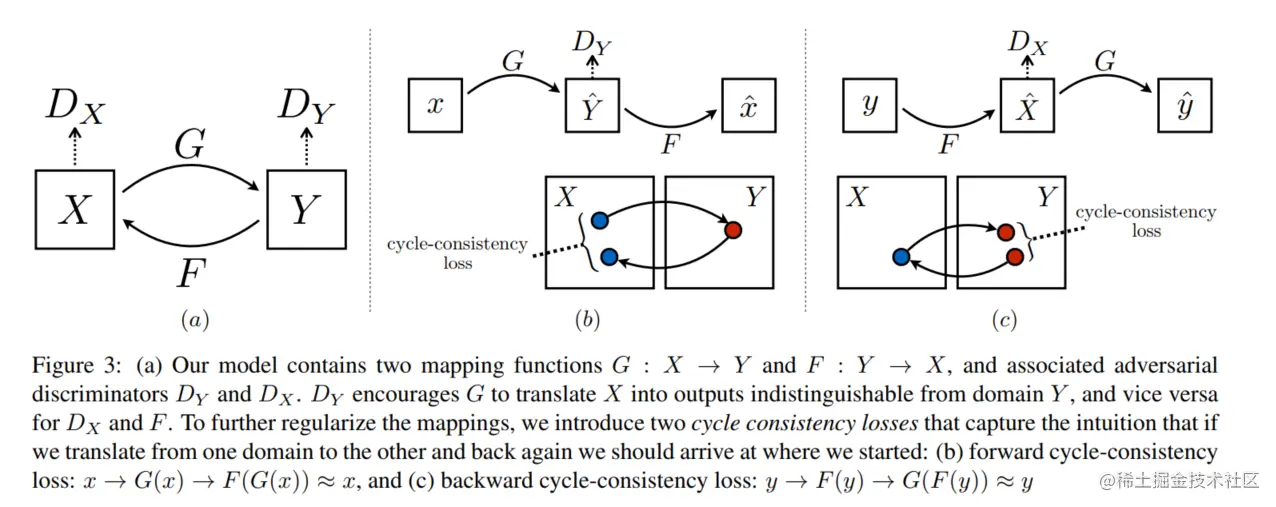
3、CycleGAN损失函数
损失函数由三部分组成,如下:
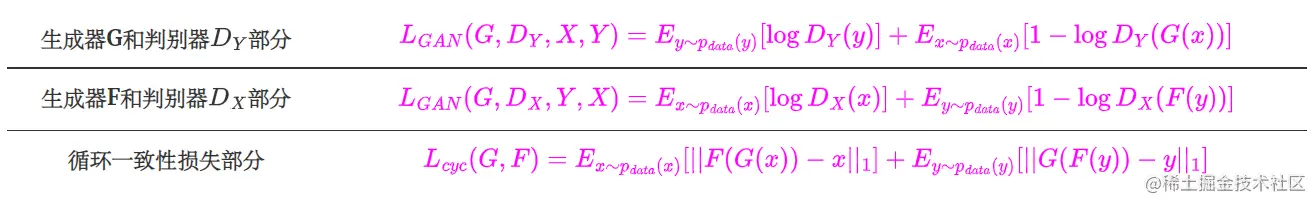
四、AnoGAN
1、简介
AnoGAN全称:Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery,指使用生成对抗网络实现异常检测。这篇论文解决的是医学影像中疾病的检测
AnoGAN思想:通过GAN学习正常样本的分布,然后通过某种手段将带有缺陷的样本映射到隐变量,再由隐变量重构样本;由于GAN只学到了正常样本的分布,因此重构图像会在保留原有图像特点的基础上消除缺陷部分,最后通过重构图像与原图像的残差确定缺陷的位置
2、出发点
DCGAN(GAN)是将一个噪声或者说一个潜在变量映射成一张图片,在训练DCGAN时,都是使用某一种数据进行的,比如使用的数据都是人脸,那么这些数据都是正常数据,那么弄一个潜在变量经DCGAN后生成的图片应该也都是正常图像。
AnoGAN的想法:能否将一张图片M映射成某个潜在变量,但是是比较难做到的。但是可以在某个空间不断的查找一个潜在变量,使得这个潜在变量生成的图片与图片M尽可能的接近
3、过程
训练阶段:仅使用正常的数据训练GAN。如我们使用手写数字中的数字8作为本阶段的数据进行训练,那么8就是正常数据。训练结束后我们输入一个向量z,生成网络会将z变成8。【注意:训练阶段已经训练好GAN网络,后面的测试阶段GAN网络的权重是不再变换的】
测试阶段:训练阶段已经训练好一个GAN网络,这一阶段就是要利用训练好的网络进行缺陷检测。如现在我们有一个数据6,此为缺陷数据 【训练时使用8进行训练,这里的6即为缺陷数据】 。现在我们要做的就是搜索一个潜在变量并让其生成的图片与图片6尽可能接近,具体实现如下:
① 首先我们会定义一个潜在变量z,然后经过刚刚训练的好的生成网络,得到假图像G(z),接着 G(z)和缺陷数据6计算损失
② 这时候损失往往会比较大,我们不断的更新z值,会使损失不断的减少,在程序中我们可以设 置更新z的次数,如更新500次后停止,此时我们认为将如今的潜在变量z送入生成网络得到的 假图像已经和图片6非常像
③ 将z再次送入生成网络,得到G(z)。【注:由于潜在变量z送入的网络是生成图片8的,尽管通 过搜索使G(z)和6尽可能相像,但还是存在一定差距,即它们的损失较大】
** **④ 最后我们就可以计算G(z)和图片6的损失,并将这个损失作为判断是否有缺陷的重要依据。因 为如果此时测试阶段传入的不是缺陷数据,而是8,此时用相同的方法搜索潜在变量z,然后将 最终的z送入生成网络,得到G(z),然后计算G(z)与图片8的损失,这时损失很小。
通过以上分析, 我们可以发现当我们在测试阶段传入缺陷图片时最终的损失大,传入正常图片时的损失小,这时候我们就可以设置一个合适的阈值来判断图像是否有缺陷了。
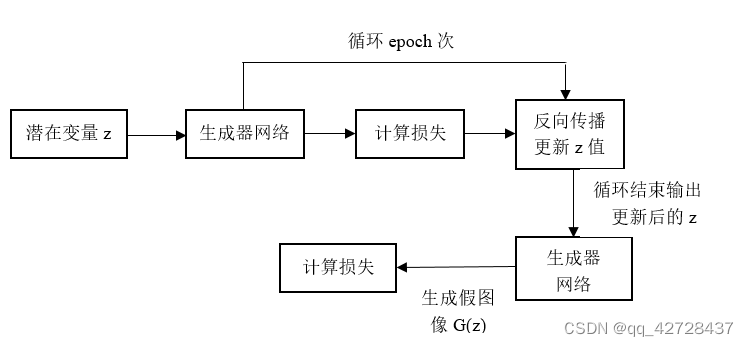
4、损失计算
文中损失函数分为两部分,分别为Residual Loss和Discrimination Loss:
- Residual loss
z表示潜在变量,G(z)表示生成的假图像,x表示输入的测试图片。上式表示生成的假图像与输入图片的之间的差距。
- Discrimination Loss
上式z表示潜在变量,G(z)表示生成的假图像,x表示输入的测试图片。f()表示将通过判别器,然后取判别器某一层的输出结果。 这里可以把判别器当作一个特征提取网络,我们将生成的假图片和测试图片都输入判别器,看它们提取到特征的差异。
求得R(z)和D(z)后,我们定义它们的线性组合作为最终的损失,如下:
五、EGBAD
1、简介
EGBAD全称:Efficient GAN-Based Anomaly Detection。
AnoGAN一个显而易见的劣势,即在测试阶段需要花费大量时间来搜索潜在变量z,这在很多应用场景中是难以接受的。本文针对上述所说缺点,介绍一种新的GAN网络——EGBAD,其在训练过程中通过一个巧妙的编码器实现对z的搜索,这样在测试过程中就可以节约大量时间。
2、过程
AnoGAN分为训练和测试两个阶段,训练阶段使用正常数据训练一个GAN网络,在测试阶段,固定训练阶段的网络权重,不断更新潜在变量z,使得由z生成的假图像尽可能接近真实图片。
EGBAD的提出就是为了解决AnoGAN时间消耗大的问题。具体做法:EGBAD也分为训练和测试两个阶段进行。在训练阶段,不仅要训练生成器和判别器,还会定义一个编码器(encoder)结构并对其训练,encoder主要用于将输入图像通过网络转变成一个潜在变量,最后再将潜在变量送入生成器,生成假图像。EGBAD没有在测试阶段搜索潜在变量,而是直接通过一个encoder结构将输入图像转变成潜在变量,大大节省了时间成本。
3、EGBAD训练过程模型示意图
可以看出判别器的输入有两个,一个是生成器生成的假图像x',另一个是编码器生成的z'。

六、GANomaly
1、简介
GANomaly全称:Semi-Supervised Anomaly Detection via Adversarial Training。是实现缺陷检测的。
2、GANomaly结构
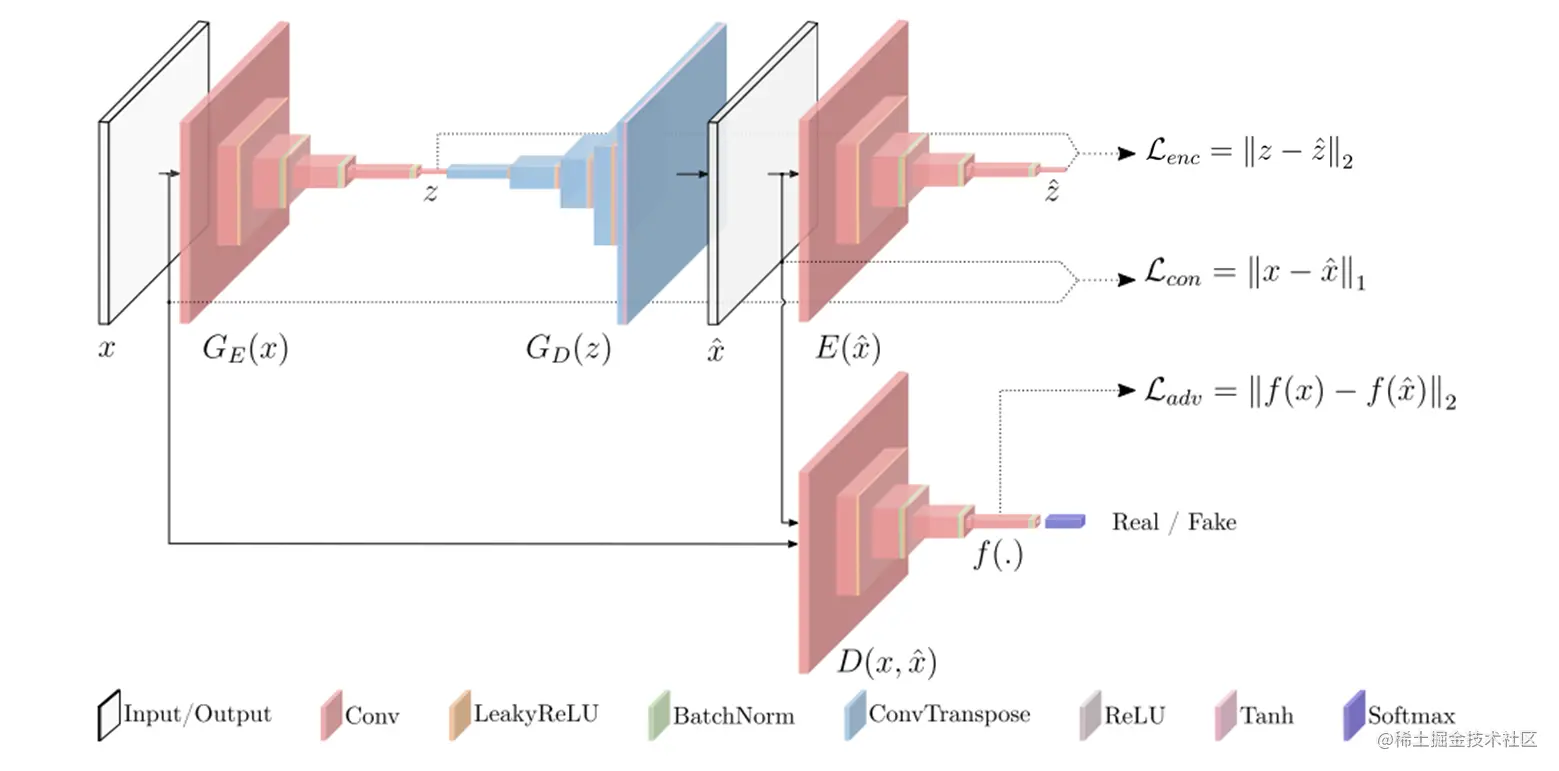
如上图红色的为Encoder结构,蓝色的为Decoder结构。Encoder主要是降维的作用,将一张张图片数据压缩成一个个潜在向量;Decoder就是升维作用,将一个个潜在向量重建成一张张图片。
按照结构来分,可以分为三个子结构:生成器网络G,编码器网络E和判别器网络D
七、f-AnoGAN
1、简介
f-AnoGAN全称:f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks
2、过程
训练主要分两步进行,第一步是训练一个生成对抗网络,第二步利用第一步生成对抗网络的权重,训练一个encoder编码器

论文给出了三种训练E的结构:ziz结构,izi结构和izif结构
八、StyleGAN
1、简介
StyleGAN全称:A Style-Based Generator Architecture for Generative Adversarial Networks
StyleGAN中的“style”是指数据集中人脸的主要属性,比如人物的姿态等信息,而不是风格转换中的图像风格,这里Style是指人脸的风格,包括了脸型上面的表情、人脸朝向、发型等等,还包括纹理细节上的人脸肤色、人脸光照等方方面面。
不同的参数可以控制人脸的不同“style”。StyleGAN用风格(style)来影响人脸的姿态、身份特征等,用噪声(noise)来影响头发丝、皱纹、肤色等细节部分。
2、背景
- GAN所生成的图像在分辨率和质量上都得到了飞速发展,但是之前的很多研究工作仍然把生成器当成黑箱子,也就是对生成器进行图像生成过程的理解,例如图像多样性中的随机特征是如何控制的,潜在空间的性质也是知之甚少。
- 受风格迁移启发,StyleGAN重新设计了生成器的网络结构,并试图来控制图像生成的过程:生成器从学习到的常量输入开始,基于潜码调整每个卷积层的图像“风格”,从而直接控制图像特征;另外,结合直接注入网络的噪声,可以更改所生成图像中的随机属性(例如雀斑、头发)。StyleGAN可以一定程度上实现无监督式地属性分离,进行一些风格混合或插值的操作。
3、StyleGAN模型架构
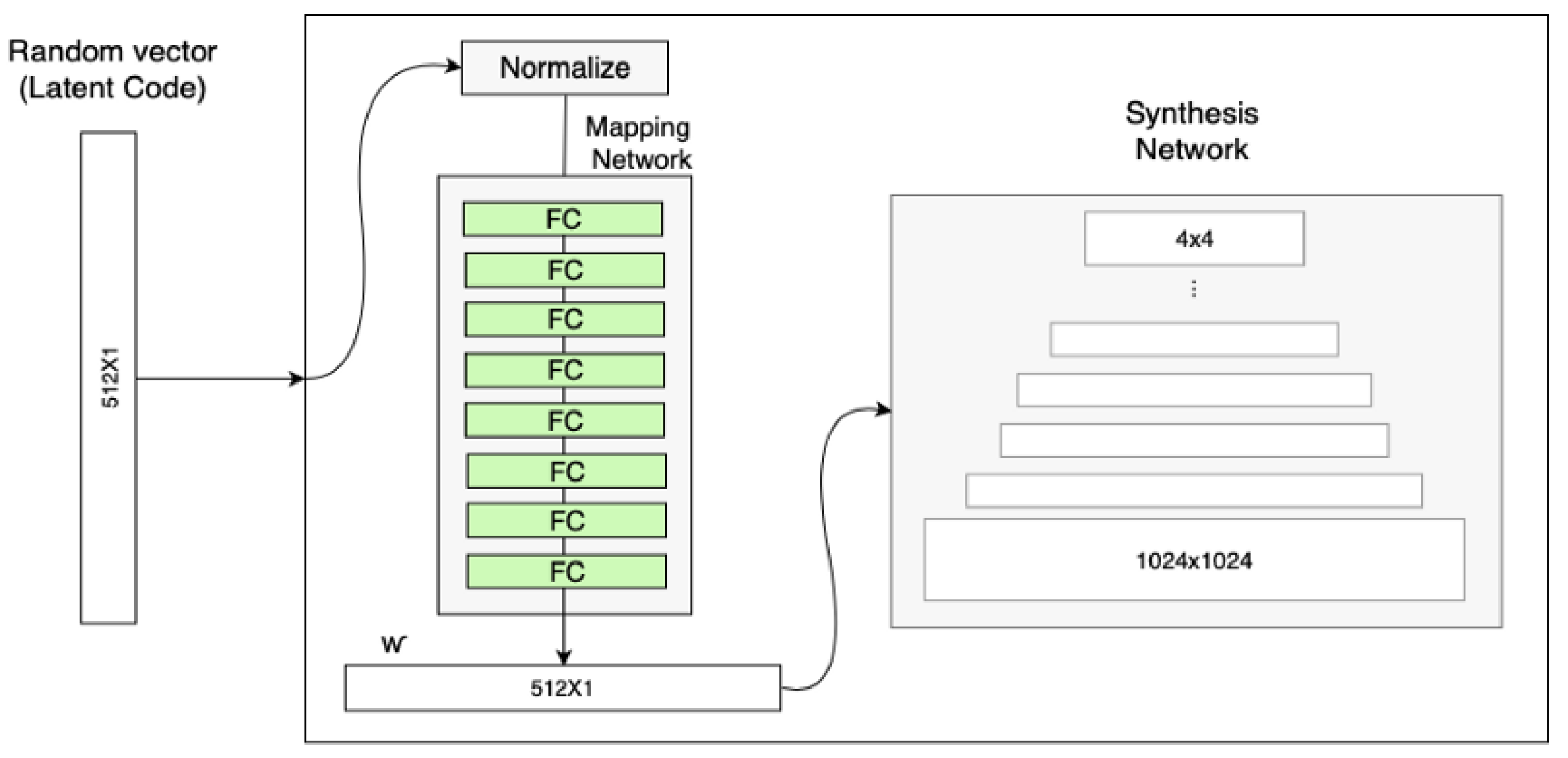
StyleGAN的网络结构包含两个部分,第一个是Mapping network,即下图左部分,由隐藏变量z生成中间隐藏变量w的过程,这个w就是用来控制生成图像的style,即风格。第二个是Synthesis network,它的作用是生成图像,创新之处在于给每个子网络都输入了A和B,A是由w转换得到的仿射变换,用于控制生成图像的风格,B是转换后的随机噪声,用于丰富生成图像的细节。
3.1 映射网络Mapping Network
Mapping Network 要做的事就是对隐藏空间(latent space)进行解耦
latent code:为了更好的对数据进行分类或者生成,需要对数据特征进行表示,但是数据有很多特征,这些特征之间相互关联,耦合性较高,导致模型很难弄清楚它们之间的联系,使得学习效率低下,因此需要寻找这些表面特征下隐藏的深层次的关系,将这些关系进行解耦,得到的隐藏特征,即latent code。由latent code组成的空间就是latent space
StyleGAN的第一点改进是,给Generator的输入加上了由8个全连接层组成的Mapping Network,并且 Mapping Network 的输出 W' 与输入层(512×1)的大小相同。
为什么需要将latent code z变成w?
因为z是符合均匀分布或者高斯分布的随机变量,所以变量之间的耦合性比较大。举个例子,比如特征:头发长度和男子气概,如果按照z的分布来说,那么这两个特征之间就会存在交缠紧密的联系,头发短了你的男子气概会降低或者增加,但其实现实情况来说,短发男子、长发男子都可以有很强的男子气概。所以我们需要将latent code z进行解耦,才能更好的后续操作,来改变其不同特征。
为什么加入Mapping Network?
添加Mapping Network的目标是将输入向量编码为中间向量,并且中间向量后续会传给生成网络得到控制向量,使得该控制向量的不同元素能够控制不同的视觉特征。为何要加 Mapping Network 呢?因为如果不加这个 Mapping Network 的话,后续得到的控制向量之间会存在特征纠缠的现象——比如说我们想调节 88 分辨率上的控制向量(假设它能控制人脸生成的角度),但是我们会发现 3232 分辨率上的控制内容(譬如肤色)也被改变了,这个就叫做特征纠缠。所以 Mapping Network 的作用就是为输入向量的特征解缠提供一条学习的通路。
为什么Mapping Network能够学习到特征解缠?
如果仅使用输入向量来控制视觉特征,能力比较有限,因为它必须遵循训练数据的概率密度。例如,如果黑头发的人的图像在数据集中更常见,那么更多的输入值将会被映射到该特征上。因此,该模型无法将部分输入(向量中的元素)映射到特征上,这就会造成特征纠缠。然而,通过使用另一个神经网络,该模型可以生成一个不必遵循训练数据分布的向量,并且可以减少特征之间的相关性。
3.2 样式模块(AdaIN)
StyleGAN的第二点改进是,将特征解缠后的中间变量W'变换为样式控制向量,从而参与影响生成器的生成过程。

生成器由于从44,变换到88,并最终变换到1024*1024,所以它由9个生成阶段组成,而每个阶段都会受两个控制向量(A)对其施加影响,影响的方式都是采用AdaIN(自适应实例归一化)。因此,中间向量W'总共被变成18个控制向量传给生成器。其中 AdaIN 的具体实现过程如上右图所示。
为什么用IN而不用BN?
BN是对一个Batch样本的特征统计进行标准化,而不是对单个样本进行标准化。因此可以直观地理解为将一批样本标准化为以单一风格为中心。但是我们希望是多种风格图像传输到相同的内容中,BN就不可取。
另一反面,IN可以将每个单独实例的风格标准化为目标风格,丢弃了原始风格的信息,网络的其他部分可以专注于匹配内容的操作。
IN通过将特征统计量标准化来实现一种风格的标准化
如何自适应(实现任意风格的转换)?
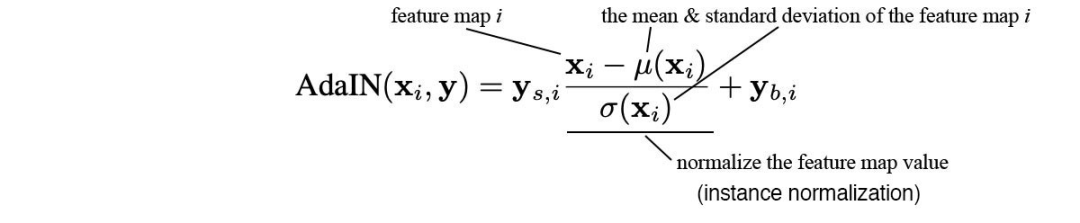
给定输入,以每个样本为单位,计算在不同特征通道上的均值μ和方差σ,可以得到IN的公式如下
上面式子中γ和β是IN层的仿射参数,在训练时由网络来学习调节。IN可以将输入图像标准化为由仿射参数 γ 和 β指定的风格。当输入内容图像c和风格图像s的时候,使网络实现任意风格的转换:
- step1: 将c输入到encoder中得到特征f(c),将s输入到encoder中得到特征f(s)
- step2: 根据均值和方差公式算出f(c)、f(s)在每个样本上的每个特征通道上的μ和σ
- step3:对于IN(f(c))中的γ和β,不再让网络学习,直接设γ为f(s)对应的σ,设β为f(s)对应的μ。这就是AdaIN的做法。
3.3 删除最开始进入4*4的输入A,并用常量代替
StyleGAN 生成图像的特征是由𝑊′和 AdaIN 控制的,那么生成器的初始输入可以被忽略,并用常量值替代。这样做的理由是:
- 避免初始输入取值不当而生成不正常的照片
- 有助于减少特征纠缠
3.4 在AdaIN模块之前向每个通道添加一个噪声
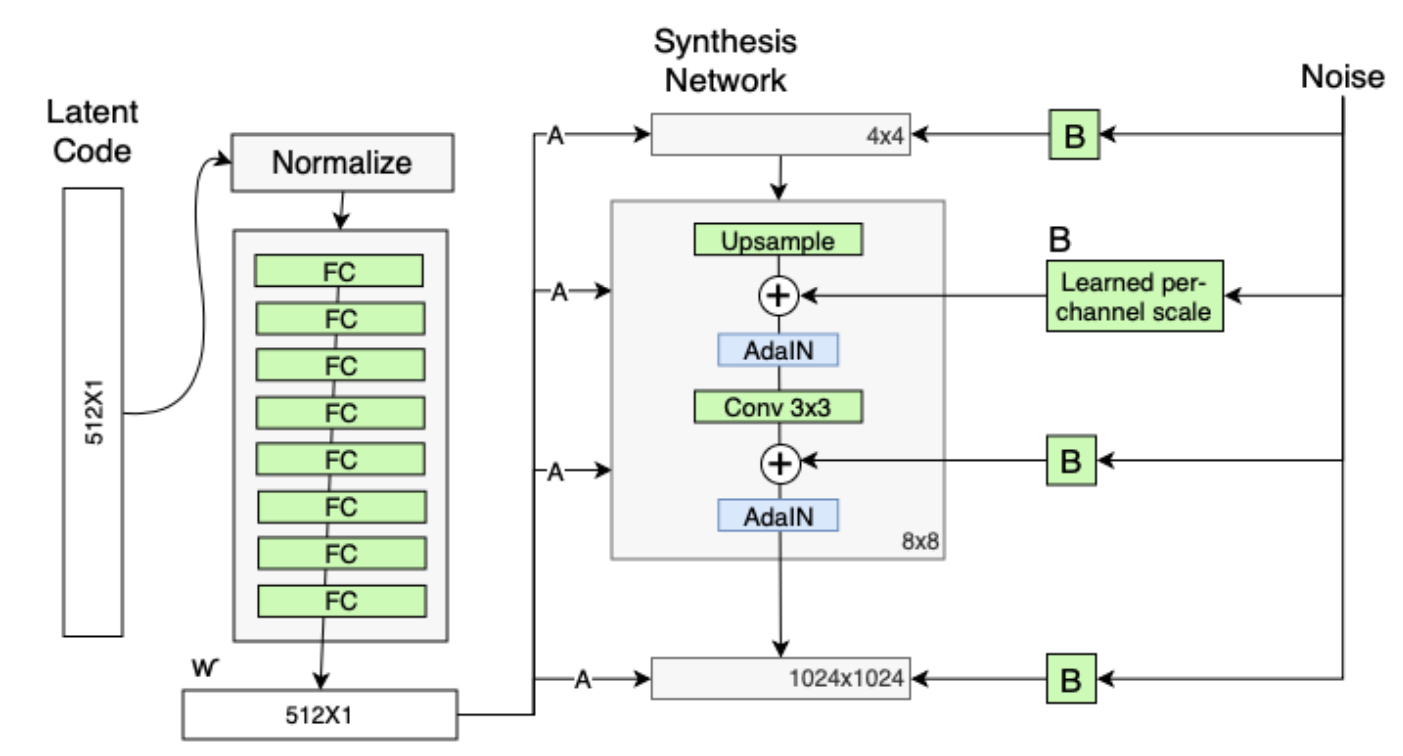
这里添加的噪声是一个单通道的图像级别的噪声图(每一个卷积层后添加一个噪声图,通道为1,B表示可学习的权重系数)
人们脸上有许多小的特征,可以看做是随机的,例如:雀斑、发髻线的准确位置、皱纹、使图像更逼真的特征以及各种增加输出的变化。将这些小特征插入 GAN 图像的常用方法是在输入向量中添加随机噪声。为了控制噪声仅影响图片样式上细微的变化,StyleGAN 采用类似于 AdaIN 机制的方式添加噪声,即在 AdaIN 模块之前向每个通道添加一个缩放过的噪声,并稍微改变其操作的分辨率级别特征的视觉表达方式。加入噪声后的生成人脸往往更加逼真与多样。
版权归原作者 qq_42728437 所有, 如有侵权,请联系我们删除。