
在当今大数据时代,数据处理和分析已成为各行各业的核心任务之一。为了有效地处理海量数据并实现高性能的分布式计算,Apache Spark作为一款强大而灵活的开源框架崭露头角。Spark的成功不仅源于其卓越的性能和易用性,更在于其开放源代码的本质,为研究者、工程师和开发者提供了深入学习的机会。
Spark源码的学习可谓是解锁这一分布式计算框架内在奥秘的关键之一。理解Spark的底层实现细节,深入研究其核心组件和算法,不仅有助于更好地利用Spark提供的丰富功能,还能为解决实际业务问题提供定制化的解决方案。
为了更好的应对工作挑战,我们将探讨学习Spark源码的重要性,以及通过深入挖掘其内部机制,如何更好地理解和优化分布式计算任务。通过追溯Spark的发展历程和深入分析其源代码,我们将揭示其中蕴含的设计哲学和工程思想,为读者打开通往高级分布式计算的大门。
本文中,我们将结合spark2.2源码部分详细讲解spark on yarn运行时架构的源码细节及实现,下面让我们结合下图和源码一起学习Spark on Yarn的执行流程。
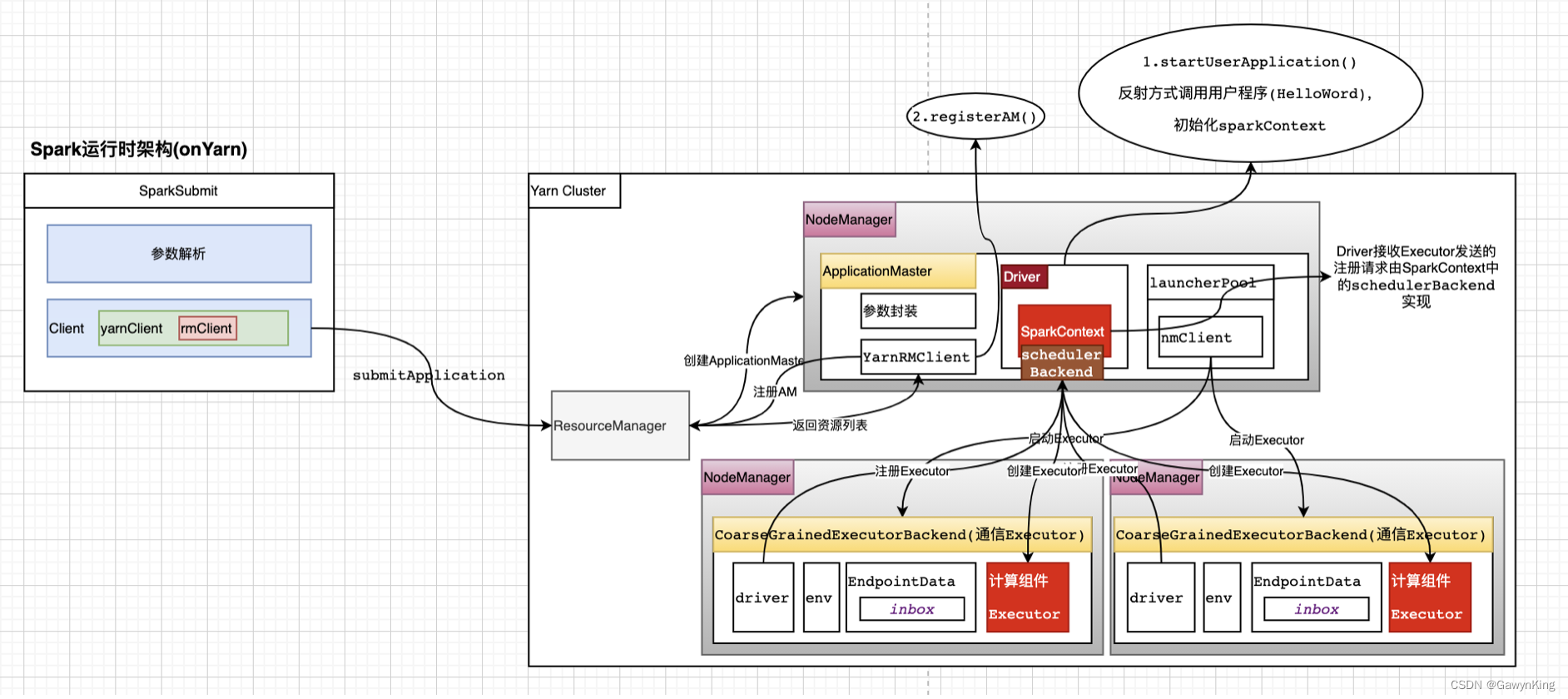
一 名词解释:
** Application**:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个Driver 功能的代码和分布在集群中多个节点上运行的Executor代码;
** Driver**:Spark中的Driver即运行上述Application的main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Drive;
** Executor**:Application运行在Worker 节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,类似于Hadoop MapReduce中的YarnChild。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数了;
二 Spark on Yarn任务提交流程
spark-submit脚本提交spark应用程序;
if [ -z "${SPARK_HOME}" ]; then source "$(dirname "$0")"/find-spark-homefi# disable randomized hash for string in Python 3.3+export PYTHONHASHSEED=0exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"``````通过源码可知,调用了org.apache.spark.deploy.SparkSubmit进行任务执行;跟踪SparkSubmit.main方法
override def main(args: Array[String]): Unit = { val appArgs = new SparkSubmitArguments(args) if (appArgs.verbose) { // scalastyle:off println printStream.println(appArgs) // scalastyle:on println } appArgs.action match { case SparkSubmitAction.SUBMIT => submit(appArgs) case SparkSubmitAction.KILL => kill(appArgs) case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs) } }通过代码可知,这里通过new SparkSubmitArguments(args)对命令行参数进行解析,然后调用submit(appArgs)提交应用执行;在submit方法内部,首先准备执行环境,然后执行runMain进行任务执行:
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)... ...runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)在prepareSubmitEnvironment(args)方法内部,由于我们跟踪yarn集群模式,所以跟踪到参数childMainClass=org.apache.spark.deploy.yarn.Client,然后根据runMain方法进行任务调度执行;在runMain方法内部,通过环境准备阶段获取到的childMainClass=org.apache.spark.deploy.yarn.Client,针对childMainClass使用反射技术调用执行org.apache.spark.deploy.yarn.Client.main方法:
......mainClass = Utils.classForName(childMainClass)......val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)......mainMethod.invoke(null, childArgs.toArray)在这里我们跳转到org.apache.spark.deploy.yarn.Client.main方法,继续跟踪任务:
......val args = new ClientArguments(argStrings)new Client(args, sparkConf).run()......this.appId = submitApplication()这里我们可以看到,首先对执行参数进行了封装,然后创建了Client对象,在Client对象内部我们可以发现创建了yarnClient对象(private val yarnClient = YarnClient.createYarnClient),在yarnClient对象内部又创建了rmClient对象,rmClient用来和yarn的ResourceManager进行交互,最后调用Client.run方法执行客户端对象,run方法的主要作用是提交应用程序到集群。在submitApplication()源码如下:
......yarnClient.start()......val containerContext = createContainerLaunchContext(newAppResponse)val appContext = createApplicationSubmissionContext(newApp, containerContext)......yarnClient.submitApplication(appContext)通过源码可知,首先启动了yarnClient对象,与ResourceManager建立连接;然后通过createContainerLaunchContext(newAppResponse)方法组织java执行命令,其中集群执行对象org.apache.spark.deploy.yarn.ApplicationMaster,然后通过createApplicationSubmissionContext(newApp, containerContext)方法封装执行环境,最后通过yarnClient.submitApplication(appContext)提交任务到集群执行,这里提交到集群上的任务本质上是一段java脚本,类似/bin/java org.apache.spark.deploy.yarn.ApplicationMaster。任务提交到集群后,首先执行org.apache.spark.deploy.yarn.ApplicationMaster.main方法:
def main(args: Array[String]): Unit = { ...... val amArgs = new ApplicationMasterArguments(args) ...... SparkHadoopUtil.get.runAsSparkUser { () => master = new ApplicationMaster(amArgs, new YarnRMClient) System.exit(master.run()) } } run(){ ...... runDriver(securityMgr) ...... }在main方法内部,首先进行参数封装,然后创建了ApplicationMaster对象;最后通过调用ApplicationMaster.run内调用runDriver(securityMgr)继续执行。下面进入runDriver()方法:
......userClassThread = startUserApplication() // 反射方式执行启动执行用户程序(HelloWord),创建SparkContext对象......registerAM(sc.getConf, rpcEnv, driverRef, sc.ui.map(_.webUrl), securityMgr)......在runDriver()方法内部首先通过startUserApplication()方法通过反射方式执行启动执行用户程序(HelloWord),创建SparkContext对象,然后调用registerAM()注册appMaster到ResourceManager,以申请资源等后续工作。下面进入两个分支进行环境创建和任务执行,让我们进入startUserApplication()和registerAM()方法内部具体跟踪实现细节:
分支1:startUserApplication():......val mainMethod = userClassLoader.loadClass(args.userClass).getMethod("main", classOf[Array[String]])......val userThread = new Thread { mainMethod.invoke(null, userArgs.toArray) ......}......userThread.setContextClassLoader(userClassLoader)userThread.setName("Driver")userThread.start()......在代码内部通过反射方式调用用户代码(HelloWorld),其中args.userClass参数表示spark-submit脚本参数--class指定的用户启动类;并且创建新的线程用于执行用户应用程序,在最后设置执行线程名:Driver,这里的Driver就是Spark架构中的Driver概念,但在源码中本质上Driver是一个线程。分支2:下面让我们跟踪registerAM()方法:......allocator = client.register(driverUrl, driverRef, yarnConf, _sparkConf, uiAddress, historyAddress, securityMgr, localResources)allocator.allocateResources()......这里的client对象是YarnRMClient实例,即ResouceManager连接对象实例,用来在appMaster内与RM交互。在这里首先通过client.register()方法想RM注册,根据注册响应进行资源分配(allocator.allocateResources())。- 下面让我们跟踪资源(allocator.allocateResources())分配细节:......val allocateResponse = amClient.allocate(progressIndicator)val allocatedContainers = allocateResponse.getAllocatedContainers()......handleAllocatedContainers(allocatedContainers.asScala)......首先存在足够可以分配的Container,代码会进入handleAllocatedContainers(allocatedContainers.asScala)进行资源分配- 在分配资源后启动资源:......runAllocatedContainers(containersToUse)......- 启动资源进入源码runAllocatedContainers(containersToUse)......launcherPool.execute(new Runnable { override def run(): Unit = { try { new ExecutorRunnable( Some(container), conf, sparkConf, driverUrl, executorId, executorHostname, executorMemory, executorCores, appAttemptId.getApplicationId.toString, securityMgr, localResources ).run() updateInternalState() } catch { case e: Throwable => numExecutorsStarting.decrementAndGet() if (NonFatal(e)) { logError(s"Failed to launch executor $executorId on container $containerId", e) // Assigned container should be released immediately // to avoid unnecessary resource occupation. amClient.releaseAssignedContainer(containerId) } else { throw e } } }})......launcherPool:ApplicationMaster中维护的线程池;线程池创建ExecutorRunnable对象并维护与Executor映射关系,在ExecutorRunnable对象中实例化nmClient,用来与启动Executor的NodeManager进行交互创建Executor。- ExecutorRunnable.run源码如下:def run(): Unit = { logDebug("Starting Executor Container") nmClient = NMClient.createNMClient() nmClient.init(conf) nmClient.start() startContainer() }源码提示创建了nmClient,并且启动了容器。- startContainer()内进入创建Executor流程:......val ctx = Records.newRecord(classOf[ContainerLaunchContext]).asInstanceOf[ContainerLaunchContext]val env = prepareEnvironment().asJava......val commands = prepareCommand()......nmClient.startContainer(container.get, ctx)......实例化Executor对象的上下文对象ctx和执行环境env,然后准备启动Executor对象的java脚本命令,这里主要启动Executor对象的类是:org.apache.spark.executor.CoarseGrainedExecutorBackend,然后通过nmClient.startContainer(container.get, ctx)启动CoarseGrainedExecutorBackend后台对象。- 通过org.apache.spark.executor.CoarseGrainedExecutorBackend.main方法进入Exector创建流程:......run(driverUrl, executorId, hostname, cores, appId, workerUrl, userClassPath)......在准备好执行环境信息后,调用run方法;下面让我们跟踪run方法细节:......env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))......设置CoarseGrainedExecutorBackend对象名称为Executor,这里即创建了Executor进程;同时设置了driver信息和env信息。方法setupEndpoint是抽象的,我们跟踪实现类NettyRpcEnv.setupEndpoint()方法
override def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef = { dispatcher.registerRpcEndpoint(name, endpoint)}
dispatcher.registerRpcEndpoint(name, endpoint)说明要注册Executor终端;
- 我们继续跟踪代码dispatcher.registerRpcEndpoint()
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = { val addr = RpcEndpointAddress(nettyEnv.address, name) // 通信地址 val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv) // 通信引用 synchronized { if (stopped) { throw new IllegalStateException("RpcEnv has been stopped") } if (endpoints.putIfAbsent(name, new EndpointData(name, endpoint, endpointRef)) != null) { throw new IllegalArgumentException(s"There is already an RpcEndpoint called $name") } val data = endpoints.get(name) endpointRefs.put(data.endpoint, data.ref) receivers.offer(data) // for the OnStart message } endpointRef }new EndpointData(name, endpoint, endpointRef):创建终端数据容器,在内部创建了收件箱val inbox = new Inbox(ref, endpoint);receivers.offer(data)代表向自己发送OnStart消息,这里自己指的是命名为Executor的CoarseGrainedExecutorBackend对象,当Executor向自己发送OnStart消息后,CoarseGrainedExecutorBackend.onStart()方法就可以接收消息进行处理。 - 下面进入CoarseGrainedExecutorBackend.onStart()方法继续跟踪
override def onStart() { logInfo("Connecting to driver: " + driverUrl) rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref => // This is a very fast action so we can use "ThreadUtils.sameThread" driver = Some(ref) ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls)) }(ThreadUtils.sameThread).onComplete { // This is a very fast action so we can use "ThreadUtils.sameThread" case Success(msg) => // Always receive `true`. Just ignore it case Failure(e) => exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false) }(ThreadUtils.sameThread) }这里driver = Some(ref),在Executor内部获取driver引用对象,接着向driver发送了注册请求RegisterExecutor(executorId, self, hostname, cores, extractLogUrls); - Executor向Driver发送注册请求后,Driver要接收消息并执行相应处理,Driver端接收任务在SparkContext.schedulerBackend实现,该方法是个抽象方法,我们需要找到它的实现类CoarseGrainedSchedulerBackend.receiveAndReply实现。
......val data = new ExecutorData(executorRef, executorRef.address, hostname,cores, cores, logUrls)......executorRef.send(RegisteredExecutor) // 向Executor回复注册成功消息......makeOffers()CoarseGrainedSchedulerBackend.receiveAndReply接收Exector消息并且注册成功后,会向Executor(executorRef.send(RegisteredExecutor))发送一个注册成功消息,CoarseGrainedSchedulerBackend.receive()方法接收Driver回复注册成功消息后会执行以下代码创建真正的Executor:......executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)......至此,计算组件Executor创建完成了,那么需要注意的上边命名为Executor的CoarseGrainedSchedulerBackend对象属于通信组件。 - 下面该启动用户代码任务了,在上边注册ApplicationMaster.registerAM方法时阻塞了用户程序执行,组件完成后该通知用户程序执行了。阻塞用户进程代码在SparkContext如下代码:
_taskScheduler.postStartHook()......override def postStartHook() { waitBackendReady()}......阻塞用户线程执行。 - 让我们继续跟踪代码
private def waitBackendReady(): Unit = { if (backend.isReady) { return } while (!backend.isReady) { // Might take a while for backend to be ready if it is waiting on resources. if (sc.stopped.get) { // For example: the master removes the application for some reason throw new IllegalStateException("Spark context stopped while waiting for backend") } synchronized { this.wait(100) } } }
至此,程序唤醒后可以继续执行用户应用程序。
版权归原作者 GawynKing 所有, 如有侵权,请联系我们删除。