
摘要:本文整理自蚂蚁集团高级技术专家、蚂蚁集团流计算平台负责人李志刚,在 Flink Forward Asia 2022 平台建设专场的分享。本篇内容主要分为四个部分:
- 主要挑战
- 架构方案
- 核心技术介绍
- 未来规划
点击查看直播回放和演讲 PPT
一、主要挑战
1.1 金融场景业务特点介绍
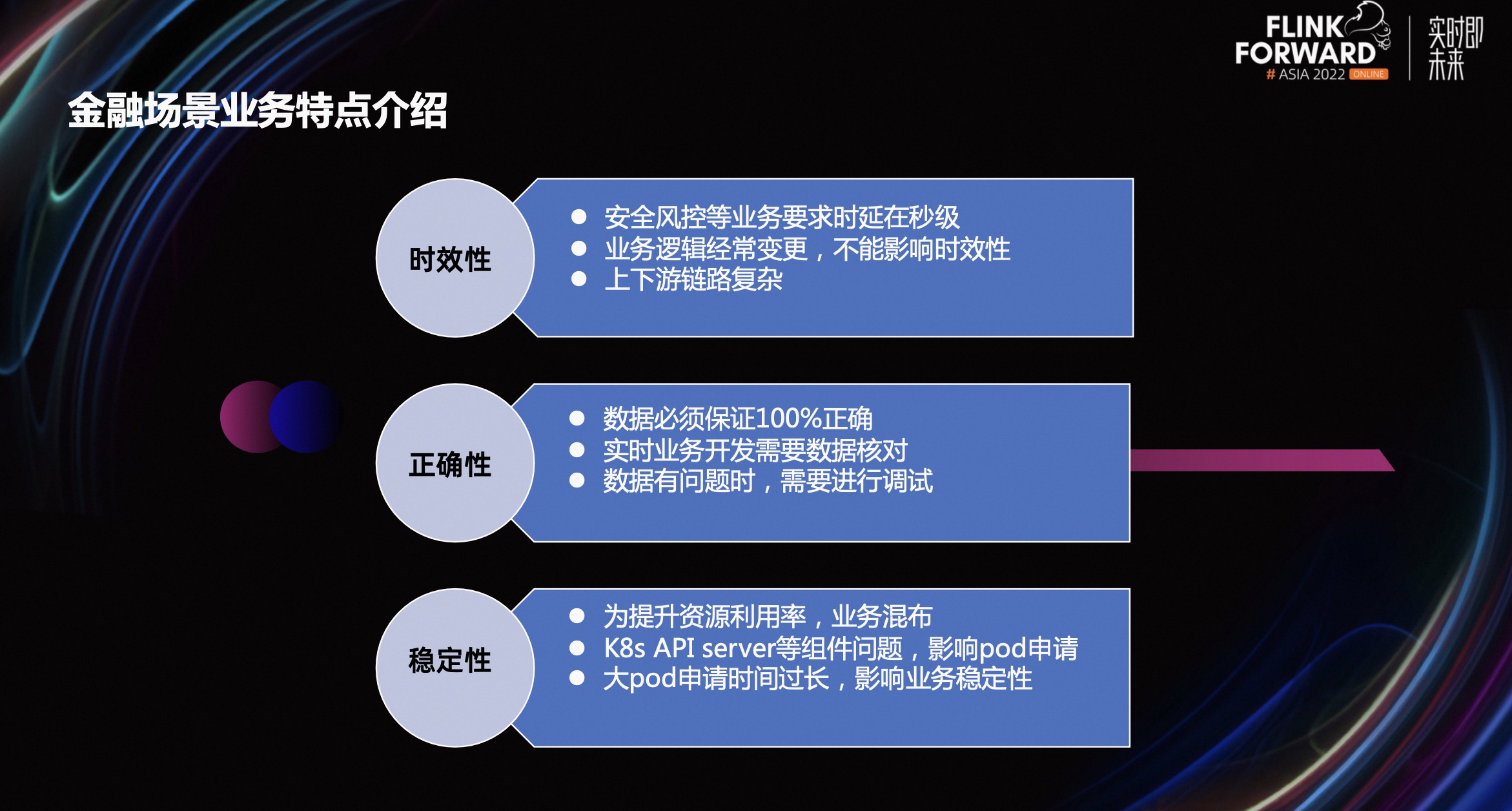
第一部分是时效性。金融场景追求时效性,特别是一些风控类的业务。首先,无论是宕机还是其他风险情况,对业务的影响需要在秒级以内。其次,业务逻辑经常变更,不能影响时效性。最后,金融业务上下游依赖特别复杂,需要保证时效性不受到影响。
第二部分是正确性。金融数据在任何情况下,计算出来数据必须保证 100%正确。不能因为出现任何故障或者其他问题导致数据出错,一旦数据出错业务是不可接受的。当前很多业务都是先开发一套离线的数据模型,然后再开发实时的数据模型,这两边如果使用了不同的引擎,就这会导致数据核对相当困难。如果数据出现问题,我们需要像写 JAVA 代码或者 C++代码一样,有比较方便的调试技术,发现问题所在,并进行修正。
第三部分是稳定性。蚂蚁业务混布在大的物理集群,有在线业务、离线业务、实时业务。在如此复杂、多变、混布的环境下,需要保证实时业务的稳定性,不能因为在云化环境下的 K8s 组件或者其他组件影响实时业务。在申请特别大的 Pod 资源时,时间会特别长,就满足不了实时业务的秒级标准。由于金融场景这些特点,我们提出创新的解决方案。
1.2 蚂蚁流计算业务的基本情况
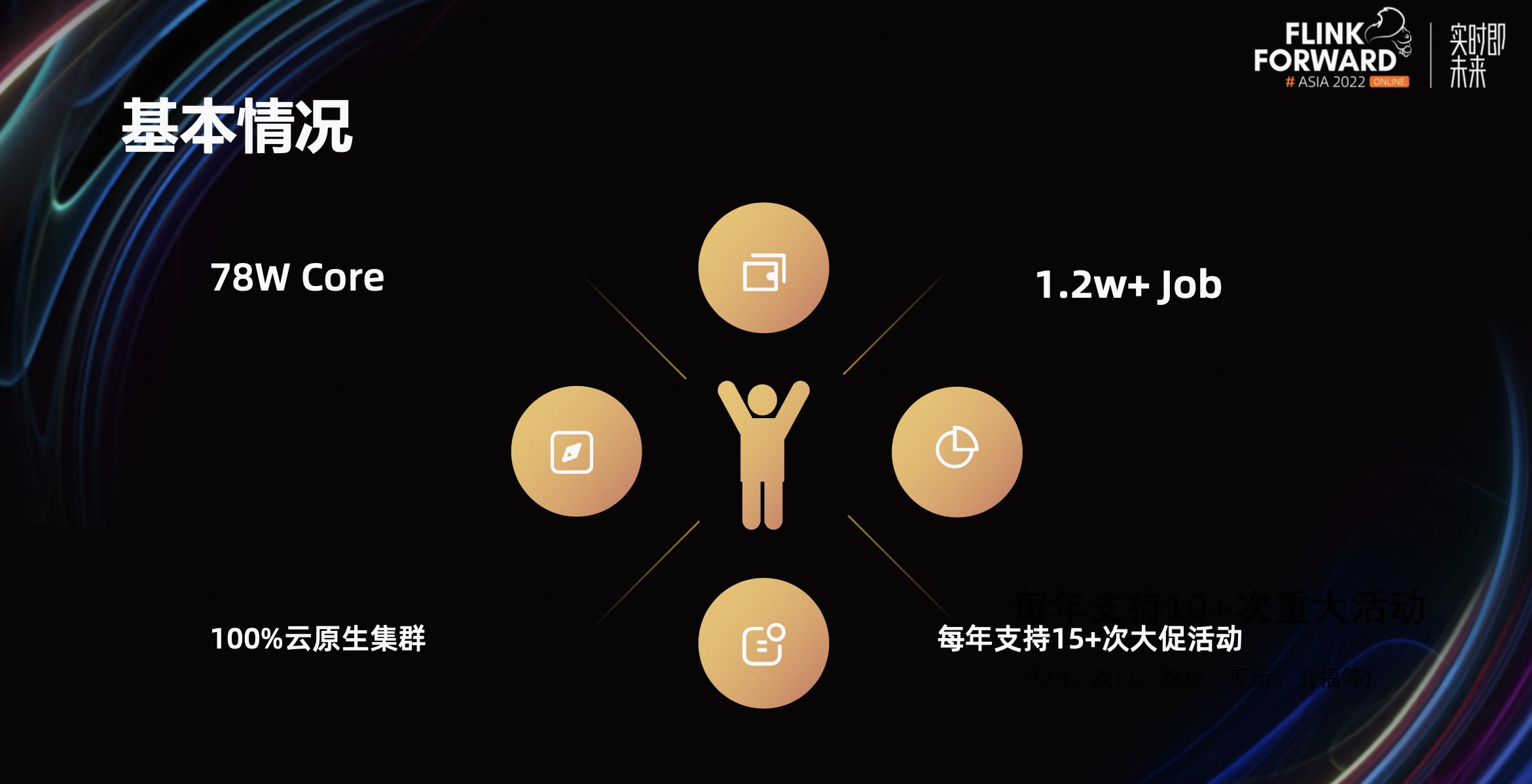
流计算规模大概在 78w Core,1.2w+个流作业,所有的集群都运行在云原生的集群上。我们每年支撑的大促活动特别多,支持 15 次以上的大促活动。由于大促业务会经常变化,需要动态的弹性计算能力。
1.3 流计算业务的主要挑战

近几年,实时计算的技术处于稳定期,在弹性方面的挑战有以下部分:
- 在大促常态化后,集群可以随时扩缩容。
- 在混布环境下,如何保证实时业务的稳定性。不能因为别的业务影响到实时计算稳定性。
- 流计算最核心的技术是优化状态的性能。如何极致优化状态性能,保证在任何大数据 Join 或者窗口的情况下没有性能问题。
在易用性方面的挑战有以下部分:
- 金融业务或者 BI 业务会随时进行变更。如何在变更的情况下,快速重启作业。
- 如何解决 SQL 作业调试难问题。
- 如何做到流批统一。
1.4 应对挑战的方法

在易用性方面,我们的解决方案是:
- 对实时计算平台进行改造,提出热启动技术,解决在云化环境下启动慢的问题。
- 调试 SQL 代码像在 IDEA 调试 JAVA 代码一样,解决排查数据困难的难题。
- 提出了基于 Flink 的流批统一的开发平台。
在弹性方面,因为大促活动非常多,需要随时扩缩容。所以我们的解决方案是:
- 基于 K8s 全面进行混布。
- 对 Flink 原生的 K8s 模式进行改造,提出云原生的 Flink 集群模式,避免由于 K8s 的问题导致影响实时业务稳定性。
二、架构方案

蚂蚁实时计算平台的架构图
最底层是 K8s 平台,上一层是 Flink runtime 流批一体,蚂蚁流计算的核心技术。提出了 K8s 集群模式,采用开源社区 DophinScheduler 来实现工作流的调度。
核心技术包括内存优化、窗口优化、复杂多变的云化环境下的智能诊断(如何发现问题,问题的定位等);调节流计算作业的参数困难,因此提出基于 AI 学习算法自动化解决调参问题;社区版本 RocksDB 状态在某些情况下性能不好,我们做了状态存储 AntKV,相比 RocksDB 性能有两倍的提升。
提出了调试 SQL,像调试 JAVA 代码一样方便的功能;热启动解决作业启动速度慢的问题;用户只要写一套 SQL 作业,指定跑流模式还是批模式,解决用户不用写两套代码和其他开发的问题。
三、核心技术介绍
3.1 热启动技术
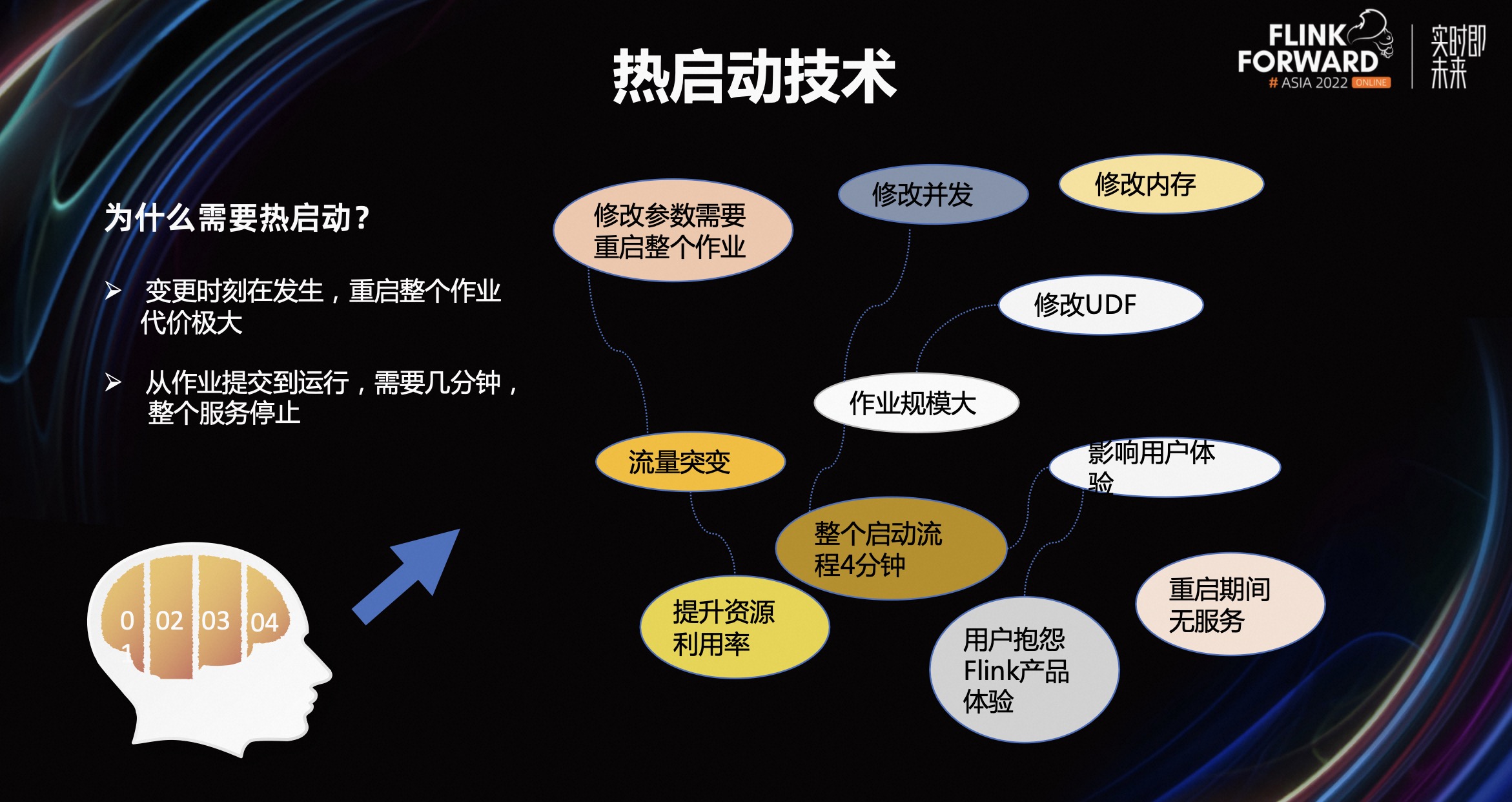
第一部分,为什么需要热启动技术?
首先,开发实时作业的人都知道,修改作业参数,比如内存、并发等,改完之后重启整个作业的时间特别长。特别在云原生环境下,提交作业、申请 Pod、Pod 发下来、拉起镜像等一系列流程,要花费几分钟。对于金融的实时业务来说很难接受。
其次是流量突变,在大促活动时,流量经常会发生变化。面对这种变化,我们需要快速适应它,改并发、内存、UDF 的情况经常发生。如果使用原生版本的 Flink,流程会特别长。从改,到提交,再到资源真正下来、作业跑起来等流程平均下来可能要四分钟。

我们要怎么解决呢?
我们提出了热启动技术,它的技术原理是用户在前端界面,会请求一个 rest 服务。然后我们把修改后的执行计划参数提供给 rest,会做一些前置校验。接着把前置校验后的参数和执行计划,提到已经在跑的那个作业上。当它拿到新的执行计划后,会把旧的暂停,然后 cancel 掉,恢复之后再慢慢创建出来。
总的来说,把新的执行计划提上去,把旧的暂停,然后根据新的执行计划生成新的部署模式。这么做的好处是,绕过了前面的 SQL 编译阶段,包括 SQL 下载 Jar 包等复杂的流程,节省了 Pod 申请的时间,作业重启操作在秒级完成。
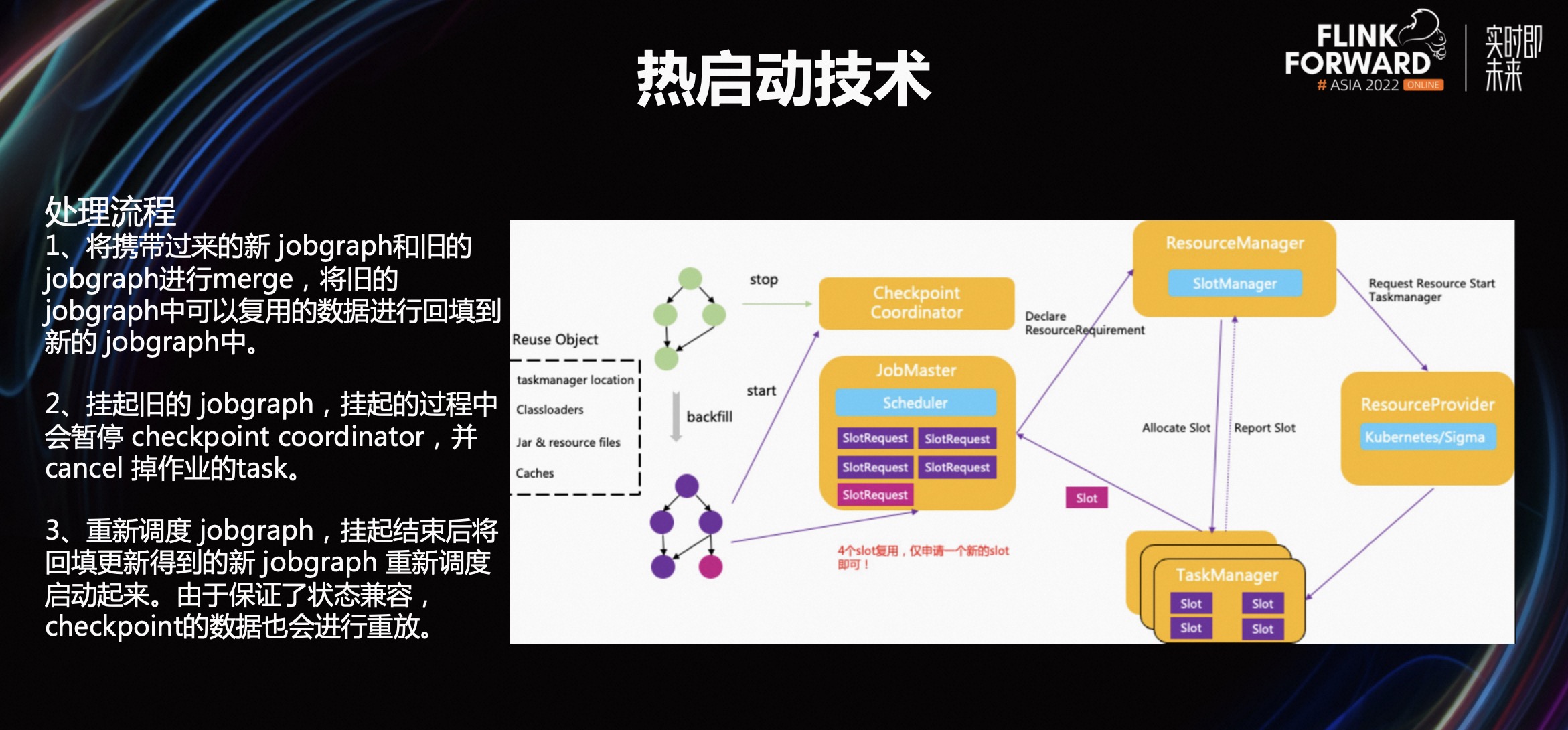
热启动技术处理流程
第一,将携带过来的新 JobGragh 和旧的 JobGragh 进行 merge,将旧的 JobGragh 中可以复用的数据进行回填到新的 JobGragh 中,包括 Jar 包、资源、文件等。
第二,新的执行计划生成后,把旧的 Task、中间的 Checkpoint Coordinator 中间的协调节点暂停掉。
第三,全部暂停后,把新的 JobGragh 调度起来,加载新的状态。如果新的执行计划调度失败,需要有回滚技术,回滚到上一个正常状态,保证用户操作体验的友好性。
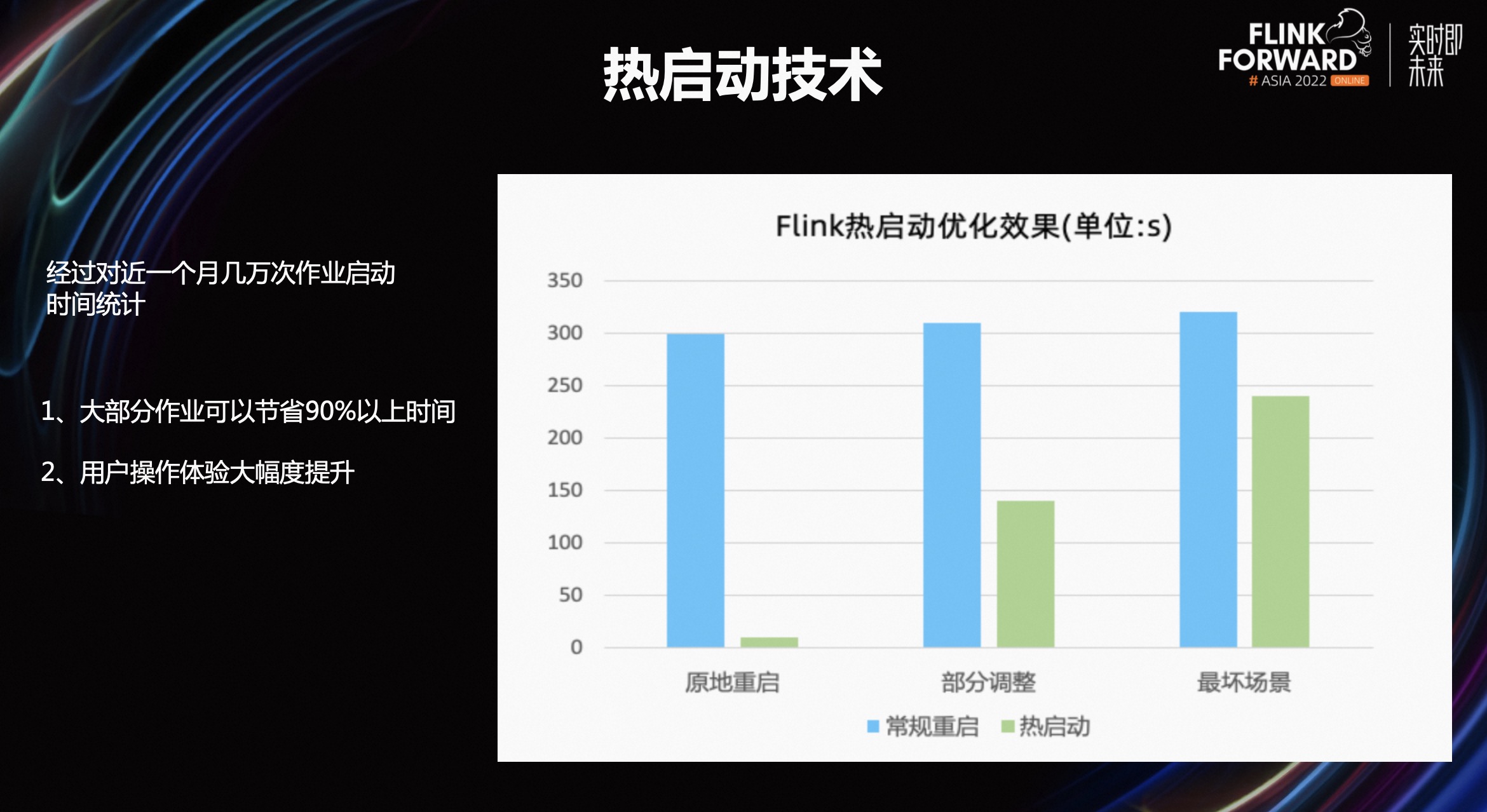
热启动效果
采用热启动技术,作业操作时间节省 90%以上。也就是说,原来大部分启动作业需要 300 秒,现在使用热启动技术只需要两秒,甚至一秒。
3.2 K8S 集群模式

第二部分,为什么需要 K8s 集群模式?
- 上图右侧是开源社区版本提供的原生 K8s 提交 Flink 作业方式。首先 K8s Client 找 K8s 的 API Server 申请 K8s Service,K8s 启动 K8s 的 deployment,然后拉起 Master 角色,再在 Master 里申请 Flink 需要的 Pod,在 Pod 启动 TaskManager 等流程。 这些复杂流程都依赖 K8s 组件,像 API Server、K8s Master,这就会导致单点。一旦 API Server 出现升级或者故障,就会影响作业的提交、运维等。在蚂蚁实践下来,历史上出现过很多问题,碰到 K8s 集群升级会导致实时作业不能提交、运维。
- 申请大的资源 Pod 时,时间就会特别漫长,甚至是五分钟级的,对用户体验特别糟糕。
- 申请大 Pod 32 核 64GB 的经常失败。
- 在实时业务大促活动时,不能动态的满足业务新增资源需求。
- K8s API Server 性能是有瓶颈的。如果一次大批量创建几百个 Pod,就会特别慢,容易超时。
为了解决以上问题,我们提出了 K8s 集群模式。

K8s 集群模式
基本思路是先通过 Operator 向 K8s 申请大量资源,然后 ClusterManager 会把资源 hold 住。之后提交作业,就不用去找 K8s 的 API Server 或者 Master 申请 Service、Deployment 等资源。
这样有什么好处呢?
首先,可以减少或者不需要和 API Server、Master 打交道。其次,Pod 已经申请在机器上,就不用每次提交作业的时候,再申请新的 Pod,可以节省大量时间。

从上图可以看到:由于 K8s 组件导致的问题,直接减少 95%。作业启动的时间,从以前的 100 秒以上,减少到现在的 50 秒,再加上热启动技术,一两秒就把作业启动起来。资源利用率提高了 5%。
3.3 流批一体技术

第三部分,为什么需要流批一体技术?
假如要开发 800 个指标的 BI 报表,后面发现了有 750 个要用离线开发,有 650 个要用 Flink 实时开发,中间还会有 500 个是重复的。重复的意思是离线也要做一套 SQL,实时也要做一套,但实际上它的业务逻辑是一模一样的。这样就会导致在数据开发的过程中,有很多重复工作。比如你用批引擎开发了一套,然后又用 Flink 实时引擎开发了一套,两边的 SQL 语法都不一样,核对起来就特别困难。为了解决当前业务开发的痛点,就提出了蚂蚁的流批一体技术。

如上图所示,流批一体技术底层也在 K8s 上。再上一层我们用的是 Flink runtime。
在往上一层是插件化 shuffle service、插件化调度、插件化状态。
- 插件化 shuffle service。shuffle service 在批计算非常重要,比如可以通过 shuffle service 解决在云化环境下本地盘很小的问题。
- 插件化调度。流和批的调度方式是不一样的,调度也可以插件化。
- 插件化状态。比如 RocksDB、内存、AntKV 型的状态类型。
最上面是平台的统一入口。用户在统一入口上可以选择统一写一套 SQL,然后指定跑流还是批,这样就解决了写两套 SQL 的难题。

Flink 调试技术
开发的时候可能要写一个批的 SQL 和流的 SQL。如果数据经常有问题,写 JAVA 代码、C++代码都知道,使用 IDE 或者 GDB 等工具,进行单步调试。我们提出了对 SQL 代码单步调试技术。方案有两种:第一种方案,修改在 Flink 代码里的所有算子,包括批的算子、流的算子。然后在入口处增加 trace 代码,即在入口处把输入数据打出来,在输出的地方把输出数据打出来。但这个方案有一个问题,会侵入原生的 Flink 引擎代码,导致代码很不优雅。第二种方案,字节码增强。
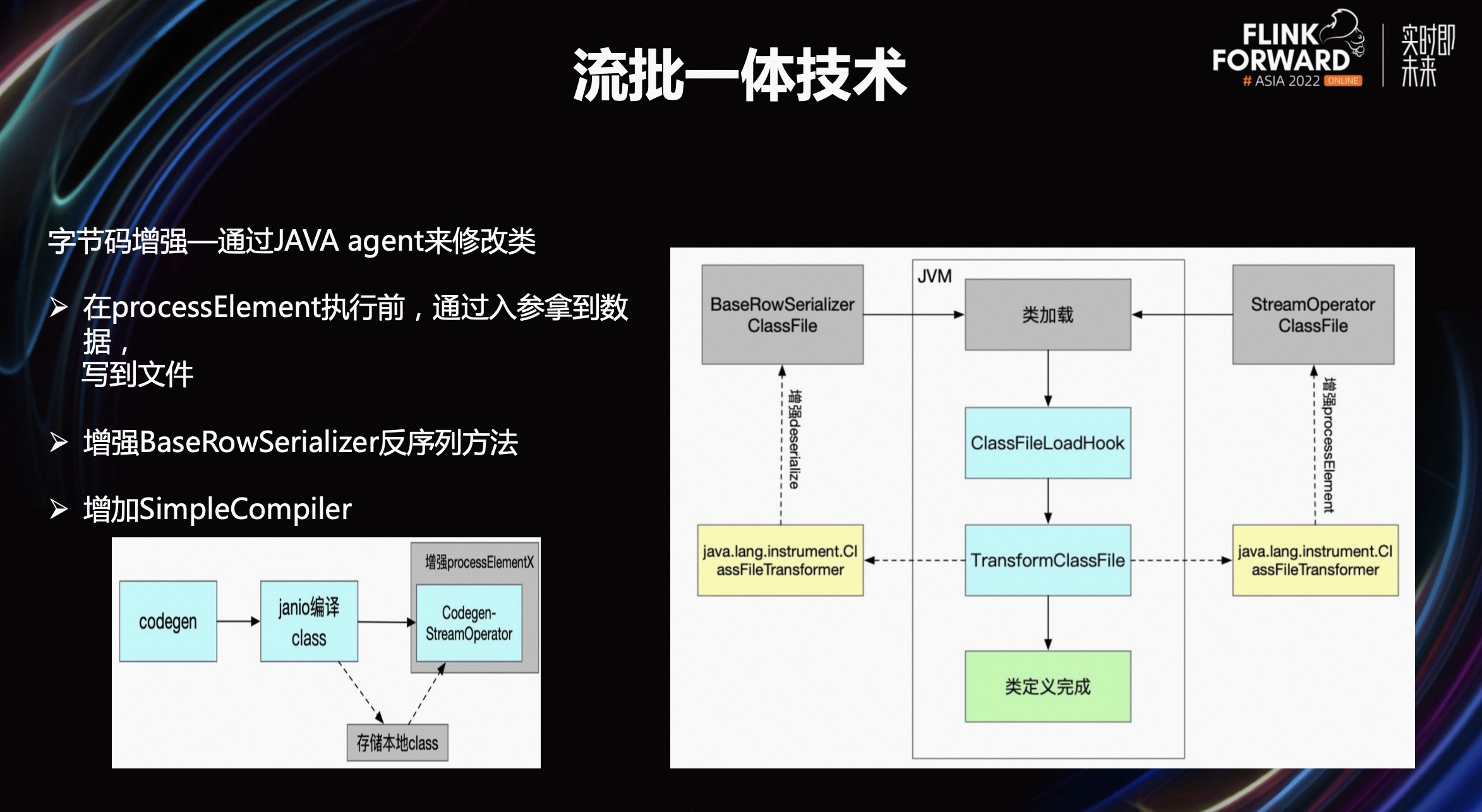
那么字节码增强技术是怎么做的呢?大家可能知道,平时从 IDE 里调试 JAVA 代码或别的代码时,实际上底层是通过 JAVA agent 技术进行调试的。JAVA agent 是一门技术,通过这个技术可以把类代理掉。也就是在执行类之前 mock 掉新的类,然后自己控制这个新的类的行为。所以 JAVA agent 是通过把跑的类代理掉,然后通过代理跑真正要跑的类。从上图右侧可以看出,底层 Flink 引擎的代码是不会改的。所以通过代理的方式,在类加载之前通过 JAVA agent 代理出改写的新类。
新类主要分为两部分,第一部分是 Stream Operator。在执行完 Stream Operator 后,会插入输入、输出的方法,这样就可以把算子的输入数据和输出数据打印出来,即通过 Byte Buddy 来实现类的改写。
这里有一个问题,Flink 代码中有很多 codegen 代码,运行的时候会自动生成一些动态代码,就是把一些函数调用合成一个函数来执行的。但通过 JAVA agent 的 Byte Buddy 改写类的时候,如果调用的是内部方法就会有问题。
从上图可以看出,通过 JAVA agent 技术对 codegen 进行类的重写。先把 codegen 代码下载一份到本地存储起来,再通过 Byte Buddy 把它改写,之后再插入输入输出代码,这样就可以看到算子的输入输出。就像调试 JAVA 代码一样,输入是什么、输出是什么、下节点的输入是什么、下节点的输出是什么,都可以详细的打印出来。
四、未来规划

第一,优化 Flink 批性能、支持全向量化计算。业界也有很多引擎在做全向量化计算,通过一些开源技术,比如 Databricks 公司的全向量化计算引擎,它的性能提升了两倍以上。
第二,基于机器学习的自动化调优。由于流计算里的参数较多,用户用起来有些门槛,我们将通过机器学习的方法来解决自动化调参数问题。
第三,发展基于 Flink 的湖仓技术。流批统一后,存储、计算、平台都会统一,这样一个入口就能解决用户批、流、AI、学习等所有计算需求。
第四,云化环境下智能化诊断。云化环境比较复杂,出现问题很难排查到具体问题。我们提出了一个智能化诊断工具,它可以诊断到底层云化环境的情况,比如机器、IP、机器负载等一系列情况,帮助用户快速发现问题。
第五,流批混合部署下分时调度,提升利用率。流批不仅是引擎的统一,统一之后还要进一步提升资源的利用率,我们将在提升利用率的方向上继续努力。
点击查看直播回放和演讲 PPT
版权归原作者 Apache Flink 所有, 如有侵权,请联系我们删除。