
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
目录
一、Pytorch搭建神经网络的简单步骤
二、LSTM网络
三、Pytorch搭建LSTM网络的代码实战

一、Pytorch搭建神经网络
PyTorch是一个基于Python的深度学习框架,提供了自动求导机制、强大的GPU支持和动态图等特性。PyTorch搭建神经网络的一般步骤:
1.导入必要的库和数据
import torch
import torch.nn as nn
import torch.optim as optim
# 加载数据并进行预处理
train_data = ...
test_data = ...
2.定义神经网络模型
# 建立Net网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 256) # 输入层到隐藏层
self.fc2 = nn.Linear(256, 10) # 隐藏层到输出层
def forward(self, x):
x = x.view(-1, 784) # 将样本拉平成一维向量
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
net = Net()
3.定义损失函数和优化器
# 使用交叉熵作为损失函数,适合分类问题
criterion = nn.CrossEntropyLoss()
# 使用随机梯度下降进行参数优化
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
4.训练模型
num_epochs =10 # 训练次数
for epoch in range(num_epochs):
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
5.测试模型
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total)
PyTorch搭建神经网络的具体步骤都是按照以上模板进行搭建的,大家可以记住以上步骤。
二、LSTM网络
LSTM网络是一种特殊的循环神经网络,它能够学习处理序列中的长期依赖性,而不会受到梯度消失或梯度爆炸的影响。LSTM中的关键组成部分是门控机制,它允许网络选择性地丢弃或保留信息。每个门控单元都包括一个sigmoid激活函数和一个逐元素乘积。
LSTM的内部状态由三个向量组成:记忆细胞状态、隐藏状态
和输入
。在每个时间步
,LSTM接收输入
和前一个时刻的记忆状态
和隐藏状态
。然后,它使用门控机制来计算以下内容:
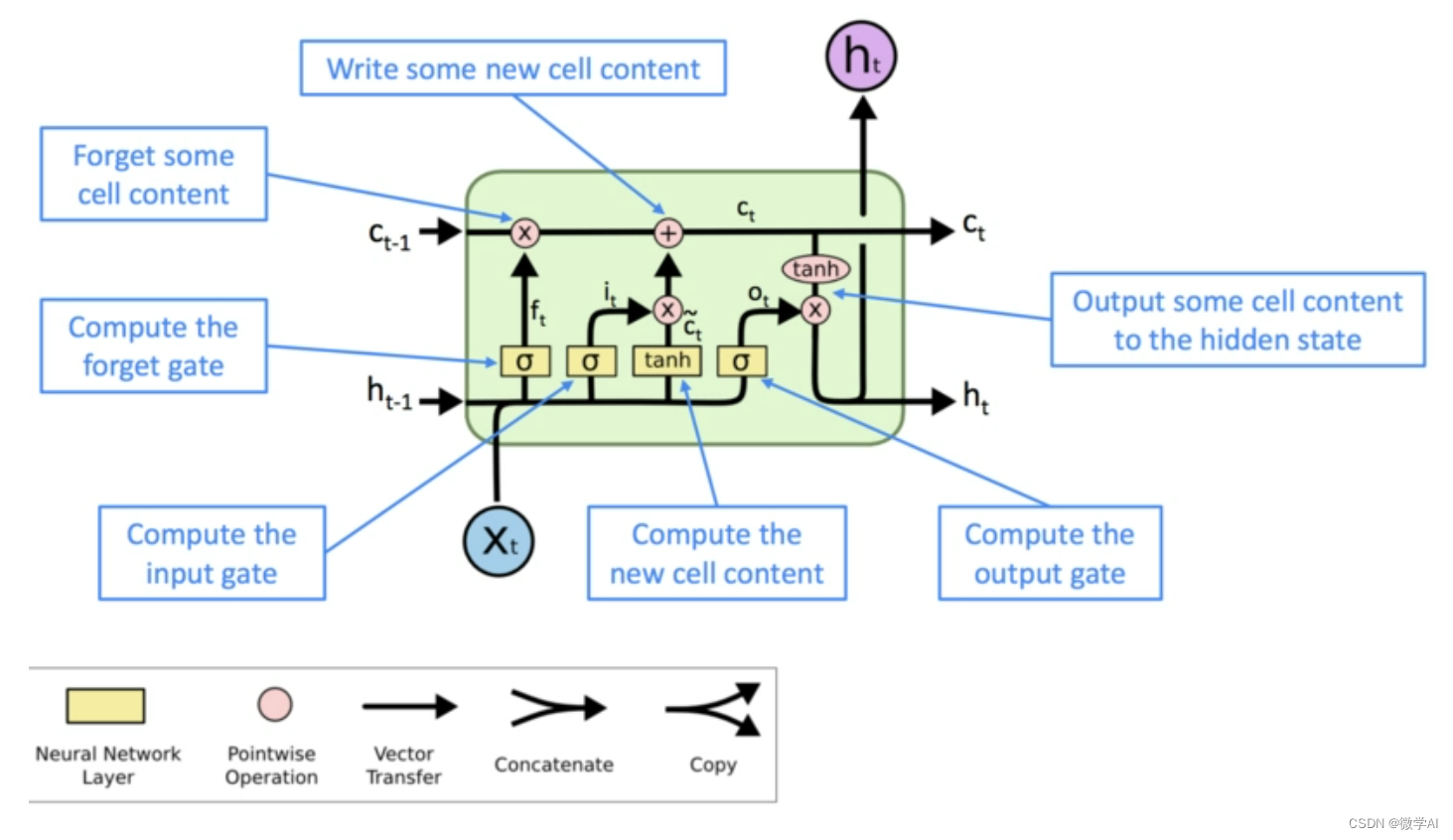
** 1.遗忘门**:决定从前一个时间步的记忆状态中删除哪些信息。
其中和
是遗忘门的权重和偏差,
是sigmoid激活函数。
2.输入门:决定将哪些新信息添加到记忆状态中。
3.候选记忆状态:包括新的候选信息。
4.更新记忆状态:根据遗忘门、输入门和候选记忆状态更新记忆状态
其中⊙表示逐元素乘积。
5.输出门:决定从记忆状态中输出哪些信息。
6.隐藏状态:根据输出门和记忆状态计算隐藏状态。
LSTM通过门控机制实现了选择性地保留或丢弃信息,从而学习处理长序列的能力。在训练过程中,LSTM网络通过反向传播算法自动调整门控单元的参数,使其能够更好地适应数据。
三、Pytorch搭建LSTM网络的代码实战
import torch
import torch.nn as nn
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(1), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(1), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[-1, :, :])
return out
# 准备数据
input_size = 10 # 输入特征数
hidden_size = 20 # 隐藏层特征数
num_layers = 2 # LSTM层数
output_size = 2 # 输出类别数
batch_size = 3 # 批大小
sequence_length = 5 # 序列长度
# 随机生成一些数据
x = torch.randn(sequence_length, batch_size, input_size)
y = torch.randint(output_size, (batch_size,))
# 定义优化器和损失函数
model = LSTM(input_size, hidden_size, num_layers, output_size)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 开始训练
num_epochs = 100
for epoch in range(num_epochs):
outputs = model(x)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
# 预测新数据
with torch.no_grad():
test_x = torch.randn(sequence_length, batch_size, input_size)
outputs = model(test_x)
_, predicted = torch.max(outputs.data, 1)
print(predicted)
运行结果:
Epoch [10/100], Loss: 0.0209
Epoch [20/100], Loss: 0.0007
Epoch [30/100], Loss: 0.0002
Epoch [40/100], Loss: 0.0002
Epoch [50/100], Loss: 0.0001
Epoch [60/100], Loss: 0.0001
Epoch [70/100], Loss: 0.0001
Epoch [80/100], Loss: 0.0001
Epoch [90/100], Loss: 0.0001
Epoch [100/100], Loss: 0.0001
tensor([0, 0, 0])
Process finished with exit code 0
版权归原作者 微学AI 所有, 如有侵权,请联系我们删除。