
文章目录
一、使用RocketQA搭建端到端的问答系统
课程《RocketQA:预训练时代的端到端问答》、RocketQA开源项目、AI studio简单使用样例
1.1 问答系统介绍
- 应用举例
QA(Question Answering System,问答系统):是信息检索系统的一种高级形式,它能用准确、简洁的自然语言回答用户用自然语言提出的问题。QA有广泛的应用: 再举例一些具体场景:
再举例一些具体场景:
- 汽车说明书问答:买车都会附赠一本厚厚的汽车说明书,直接翻比较麻烦。如果有一个对话系统可以直接回答车主的提问,效率会更高。比如提问“如何打开后雾灯”

- 疫情政务问答:如果有一个智能对话系统,可以自动回答大量的疫情咨询,可以节省很多人力物力。 - 下图右侧是传统的基于关键词搜素引擎的系统,虽然匹配了很多关键词,但没有准确的答案,用户还需要点开每个页面进行查看,所以结果的相关性很差。- 左侧是基于对话系统,直接返回准确的答案,满足用户需求,体验更好。
 数据来自Datafountain疫情问答政务助手比赛
数据来自Datafountain疫情问答政务助手比赛
- 问答系统分类
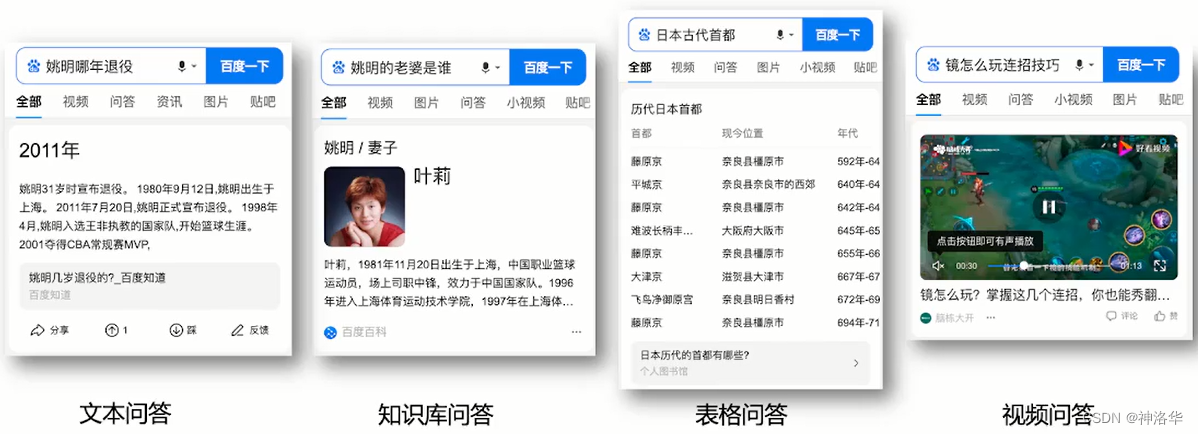
- 发展历程
- 统计学习时代:例如TREC QA这种三段式系统(问题处理、段落检索、答案处理),发展10年之后遇到瓶颈,还是无法实际落地。
- 检索式问答:深度学习时代,我们可以在大规模语料上进行深度学习,搭建两段式的检索问答系统。比如2017年提出的DrQA,在维基百科数据上进行训练,然后得到一个两段式结构的模型(先段落检索,筛选出与问题相关的候选语料,然后使用阅读理解得到最终答案)。
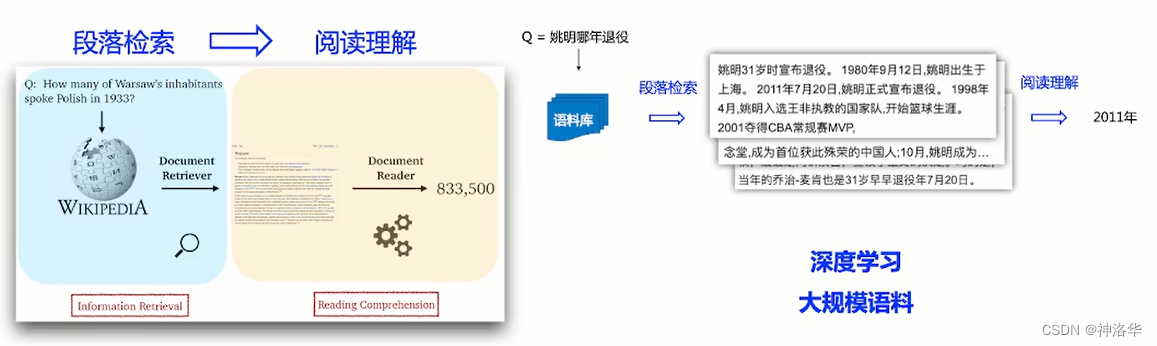
- 预训练时代(端到端):随着NLP领域BERT等预训练模型的提出,问答系统进入了端到端时代。 - 以前的问答系统是由多个模块组成的传统级联系统,每个模块独自优化学习,很难达到全局最优。- 预训练时代,我们可以获得更好的文本语义表示,将段落检索和阅读理解都变成一个可导的学习模块,最后得到一个端到端的系统。端到端的系统可以做全局优化,而且更容易部署。
1.2 RocketQA
1.2.1 检索式QA VS预训练时代QA
- 检索式问答

- 使用预训练模型- 双塔模型:分别计算问题和段落(语料)的文本向量表示,二者之间相似度最高的为匹配段落,然后从中抽取答案。可离线计算文档的向量并构建向量索引,使用成熟的向量检索工具(比如基于j近似近邻ANN)实时检索问答
 - 交互式单塔结构:将问题和段落拼在一起计算相似度,二者充分交互,匹配更加准确。缺点是推理时计算效率更低。
- 交互式单塔结构:将问题和段落拼在一起计算相似度,二者充分交互,匹配更加准确。缺点是推理时计算效率更低。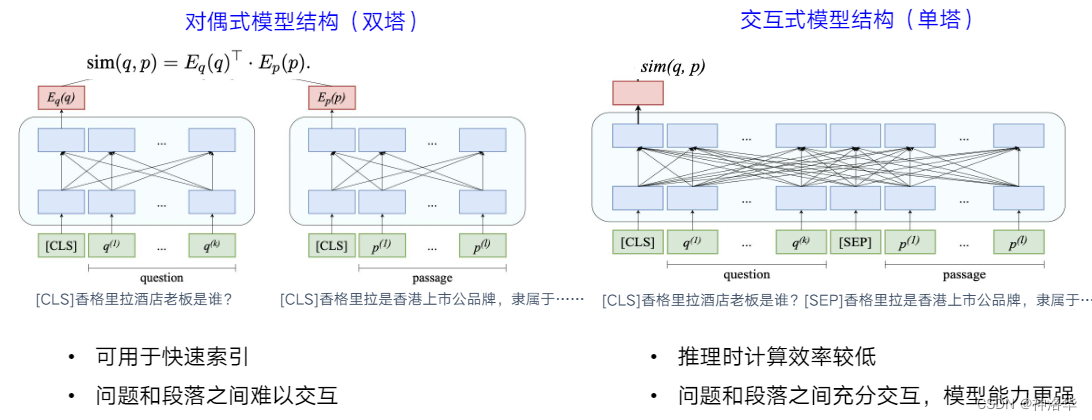
- RocketQA
- 离线计算好文档向量之后,在线问答时,先将问题转为Query向量,然后使用Faiss等向量检索工具,检索出候选文档,最后定位答案输出结果。
- 整个模型的搭建是比较复杂的,引入
Jina之后,主需要一行命令就可以搭建并启动RocketQA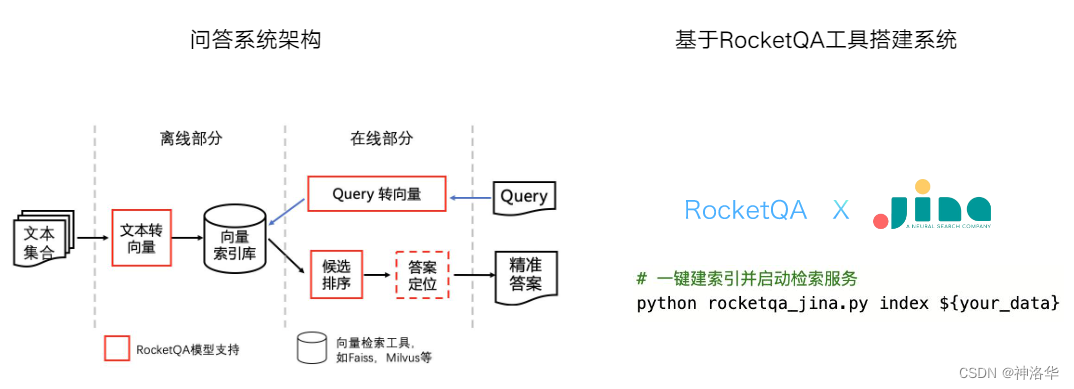
在工业级开源问答数据集上,
RocketQA
表现优异
下图第一段表示使用稀疏向量的检索式QA系统,第二段表示使用稠密向量的预训练模型表示的QA系统
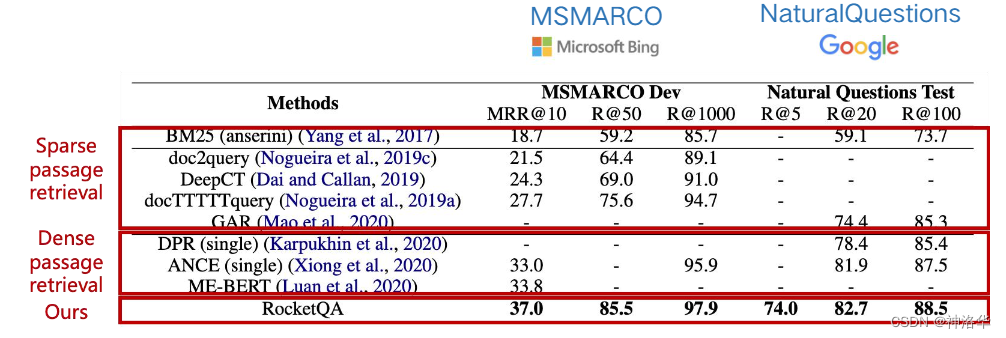
1.2.2 RocketQA简介
目前代表性的QA系统有:
- 百度RocketQA系列:RocketQA(2020)、PAIR(2021)、RocketQAv2(2021)
- 微软:DPR(2020)
- google:ORQA ( 2019)、REALM (2020)、ME-BERT (2020)
RocketQA开发工具:提供训练好的RocketQA模型和简单易用的模型预测api,提供基于RocketQA模型搭建问答系统的简单方案。
- 基于知识增强预训练模型
ERNIE和中文开源数据集DuReader进行训练 - 内置多个效果领先的中文、英文模型,具有强大的中文能力。

- 开发接口简单易用。 可以通过pip一键安装,同时也提供了装有所有依赖的docker镜像
1.3 使用RocketQA搭建问答系统
RocketQA开源项目、AI studio简单使用样例
下面根据AI studio简单使用样例,演示如何基于RocketQA搭建一套问答系统。
1.3.1 安装
# pip安装RocketQA工具包
!pip install rocketqa
查看
RocketQA
提供的预置模型
- V1和V2表示RocketQA和RocketQAv2的方法
- 中间字段表示使用的数据集
- de表示有检索和排序等能力的端到端的问答系统,ce表示只有排序功能的模型,排序能力比de强,但是效率上会很慢
import rocketqa
rocketqa_models = rocketqa.available_models()# 返回内置模型for m_name in rocketqa_models:print(m_name)
v1_marco_de
v1_marco_ce
v1_nq_de
v1_nq_ce
pair_marco_de
pair_nq_de
v2_marco_de
v2_marco_ce
v2_nq_de
zh_dureader_de
zh_dureader_ce
zh_dureader_de_v2
zh_dureader_ce_v2
1.3.2 使用预置模型完成预测
- 问答的定位是基于段落粒度的,而不是文档粒度。候选文档(段落)不是太长,使用
para_list表示。 RocketQA还支持输入para_gram所在的文档的标题title,加入标题通常会提高模型效果
# 使用RocketQA预置的模型做预测import rocketqa
query_list =["交叉验证的作用"]# 问题
para_list =["交叉验证(Cross-validation)主要用于建模应用中,例如PCR 、PLS回归建模中。在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。"]
title_list =["交叉验证的介绍"]# load model - RocketQA中文检索模型(de),在DuReader数据集中训练得到
dual_encoder = rocketqa.load_model(model="zh_dureader_de_v2")# cpu加载,此模型是在dureader上训练的中文双塔模型#dual_encoder = rocketqa.load_model(model="v1_marco_de", use_cuda=True, device_id=0, batch_size=16) # for gpu# 编码query & para得到其向量表示,title为可选项
q_embs = dual_encoder.encode_query(query=query_list)
p_embs = dual_encoder.encode_para(para=para_list, title=title_list)# 计算query representation和 para representation的点积相似度
dot_products = dual_encoder.matching(query=query_list, title=title_list, para=para_list)list(dot_products)
[419.8206787109375]# 未归一化的向量内积得分
这里生成的q_embs、p_embs、dot_products都是<generator object >格式,不能直接打印出数据。
1.3.3 搭建问答系统

- 离线部分,需要将待检索的文档转成向量,并建立向量索引。
- 在线部分,需要将查询语句转成向量,用向量从索引中检索相关内容(通常返回不止一条结果),再对相关内容进行更精细的排序,得到最佳答案。
1.3.3.1 使用Faiss搭建自己的问答系统
第一步:打开终端,安装依赖**
pip install faiss-cpu==1.5.3
git clone https://github.com/PaddlePaddle/RocketQA.git # 如果刚才已经pip安装了RocketQA,这一步就跳过
cd RocketQA/examples/faiss_example/
第二步:准备数据
按如下格式准备候选文档:
每一行是一条文档数据,包含文档标题和文档内容,标题与内容用\t分隔。如果没有标题,可用空字符串或’-'代替,例如:
广西壮族自治区新型冠状病毒感染的肺炎 \t 感谢社会各界对我区抗击新型冠状病毒感染的肺炎疫情所给予的关心和大力支持!...
第三步:建索引并启动检索服务
# 建立索引库# 使用index.py脚本将文档转为向量,再建立一个向量索引。# 这里zh表示刚刚的zh_dureader_de_v2模型,your_data是要建立索引的数据集,index_name是建立的索引文件名
python index.py zh ${your_data} ${index_name}# 启动检索服务# 使用rocketqa_service.py加载索引并启动问答服务,用户输入问题(query)就可以检索问答获取答案
python rocketqa_service.py zh ${your_data} ${index_name}&
演示:
- 在faiss_example文件件下运行
python index.py zh ../test_para test_index建立索引 - 运行
python rocketqa_service.py zh ../test_para test_index启动服务 - 三个参数分别是模型、建立索引的数据文件和索引文件名。两次模型要一致
下面简单看一下
index.py
:(Ctrl Z,bg命令转后台)
defbuild_index(encoder_conf, index_file_name, title_list, para_list):
dual_encoder = rocketqa.load_model(**encoder_conf)# 加载模型
para_embs = dual_encoder.encode_para(para=para_list, title=title_list)# 读取所有的para_gram
para_embs = np.array(list(para_embs))
indexer = faiss.IndexFlatIP(768)# 用fsiss建立向量索引
indexer.add(para_embs.astype('float32'))
faiss.write_index(indexer, index_file_name)
看一下
rocketqa_service.py
文件:
defpost(self):...# 调用encode_query函数将文本编码为向量
q_embs = self._dual_encoder.encode_query(query=[query])
q_embs = np.array(list(q_embs))# 调用faiss的search函数,返回匹配到的top k段落
search_result = self._faiss_tool.search(q_embs, topk)#
titles =[]
paras =[]
queries =[]for t_p in search_result:
queries.append(query)
t, p = t_p.split('\t')
titles.append(t)
paras.append(p)# 使用matching函数计算search_result和query的相似度
ranking_score = self._cross_encoder.matching(query=queries, para=paras, title=titles)
ranking_score =list(ranking_score)
final_result ={}for i inrange(len(paras)):
final_result[query +'\t'+ titles[i]+'\t'+ paras[i]]= ranking_score[i]# 根据相似度对结果进行排序
sort_res =sorted(final_result.items(), key=lambda a:a[1], reverse=True)for qtp, score in sort_res:
one_answer ={}
one_answer['probability']= score
q, t, p = qtp.split('\t')
one_answer['title']= t
one_answer['para']= p
output['answer'].append(one_answer)# 返回最终结果
result_str = json.dumps(output, ensure_ascii=False)
self.write(result_str)
在
def create_rocketqa_app
函数中可以修改模型,默认是zh(中文)使用zh_dureader_de_v2和h_dureader_ce_v2。
第四步:检索
python request.py

上图是输入
head -n 1 ../test_quety查看到第一个问题是“湖南省多少项目复工”,然后运行python query.py会提示输入问题,复制刚刚的问题,就得到了系统的结果(这里是返回一条结果,包含最后的相似度得分)
我自己运行老是报错Address already in use
1.3.3.2 使用Jina搭建自己的问答系统(更简单)
Jina是基于深度学习模型搭建搜索引擎的开源框架,将RocketQA模型嵌入Jina框架能更加便捷的搭建检索式问答系统。具体步骤如下:
第一步:安装依赖
git clone https://github.com/PaddlePaddle/RocketQA.git
cd RocketQA/examples/jina_example
pip install -r requirements.txt
安装时报错
parl 1.4.1 requires pyzmq==18.1.1, but you have pyzmq 23.2.1 which is incompatible.
,所以得装pyzmq18.1.1,否则第三步会报错。
第二步:准备数据
按如下格式准备候选文档:
每一行是一条文档数据,包含文档标题和文档内容,标题与内容用\t分隔。如果没有标题,可用空字符串或’-'代替
例如:
广西壮族自治区新型冠状病毒感染的肺炎 \t 感谢社会各界对我区抗击新型冠状病毒感染的肺炎疫情所给予的关心和大力支持!...
第三步:建索引并启动检索服务
python rocketqa_jina.py index ${your_data}
这里演示就是使用toy_data下的test.tsv数据,所以运行
python rocketqa_jina.py index toy_data/test.tsv
。启动后显示:
第四步:检索
python rocketqa_jina.py query_cli
成功运行后显示:
虽然运行起来了,但总感觉哪里有问题,答案我都看不懂。
1.3.3.3 训练自己的模型
- 训练自己的模型
# 加载初始化模型
cross_encoder = rocketqa.load_model(model="zh_dureader_ce", use_cuda=False)# cross_encoder = rocketqa.load_model(model="zh_dureader_ce", use_cuda=True, device_id=0, batch_size=32)# 基于初始化模型,用自己的数据finetune。finetune模型的参数与初始化模型一致,# 相关配置文件可以在初始化模型的地址找到(~/.rocketqa/zh_dureader_ce)。建议用GPU机器
cross_encoder.train('./RocketQA/examples/data/cross.train.tsv',2,'ce_models', save_steps=1000, learning_rate=1e-5, log_folder='log_ce')
- 加载训练好的模型
import rocketqa
# 加载自己训练的模型,模型地址及相关配置写在config.json中
cross_encoder = rocketqa.load_model(model="./examples/ce_models/config.json", use_cuda=True, device_id=0, batch_size=16)
其中config.json的格式如下:
{"model_type":"cross_encoder","max_seq_len":384,# 与训练时的设置保持一致"model_conf_path":"zh_config.json",# 与训练(初始化模型)保持一致,文件可以在初始化模型的地址找到(~/.rocketqa/{初始化模型})"model_vocab_path":"zh_vocab.txt",# 与训练(初始化模型)保持一致,文件可以在初始化模型的地址找到(~/.rocketqa/{初始化模型})"model_checkpoint_path": ${YOUR_MODEL},# 模型地址"for_cn": true,# 中文设置为true,英文为false"share_parameter":0# 若初始化模型为pair系列模型,则设置为1;否则为0}
详情可访问RocketQA开源项目
1.4 课后问答
- RocketQA开源项目介绍:
- examples:搭建方案和样例,包括刚才的两个示例
- research:相关论文和最新进展
- rocketqa:RocketQA开源框架
- 检索和问答的区别 前者是返回多个候选答案的链接,后者直接返回最相似的结果
- RocketQA可以做多伦问答或者数学题之类的吗? RocketQA目前不支持多轮问答,而且主要是基于检索和抽取,还无法支持解题这种需要深度理解的场景。
- 段落长度最大是512,不支持粤语、繁体等,因为用的是简体中文数据集预训练的。
- 实际中如何部署 神经搜索框架Jina进行部署更简单,而生产中各种环境问题会很多,建议使用docker来实现(内置Jina和faiss)。
二、属性级情感分析
参考:《情感分类开源项目》、PaddleNLP打卡营教程、AI studio 实例:搭建评论观点抽取和情感分析系统
2.1 前言
- 背景:文本可以分为客观性文本和主观性文本。随着互联网的兴起,这方面的需求和应用也很普遍。


Taskflow进行情感分类的简单示例(基于
SKEP
模型)
from paddlenlp import Taskflow
senta= Taskflow('sentiment_analysis')
senta('昨天我买了一台新的iphone手机,它的触摸屏做的非常精致酷炫')[{'text':'昨天我买了一台新的iphone手机,它的触摸屏做的非常精致酷炫','label':'positive','score':0.969430685043335}]
2.2 SKEP
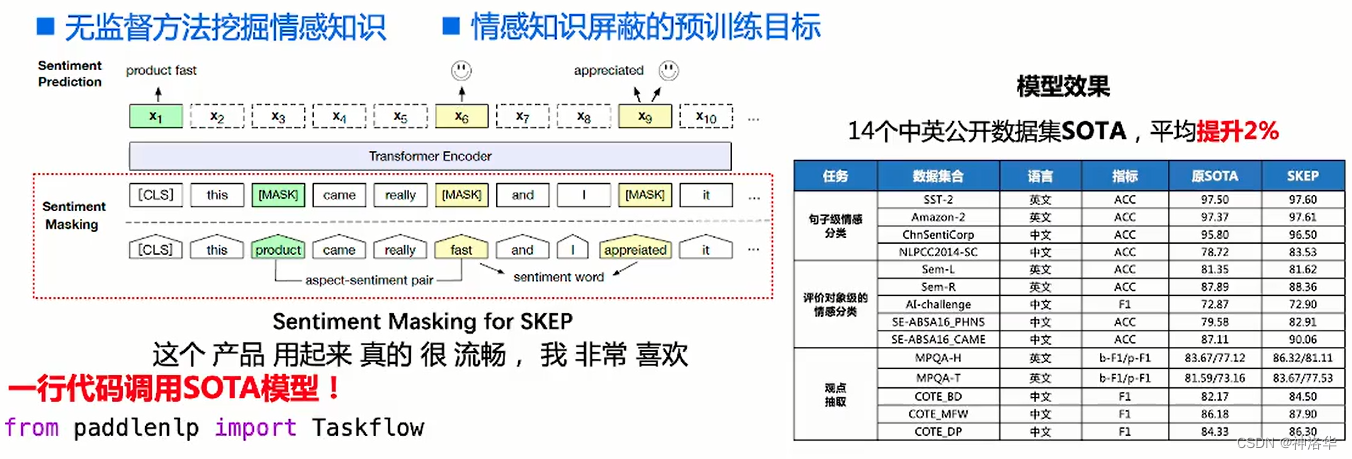
Taskflow使用百度2020年提出的情感增强知识模型SKEP(SentimentKnowledgeEnhancedPre-training)来做情感分析任务。SKEP通过MLM无监督的方式在海量的数据中挖掘大量的情感知识。
- 传统预训练主要使用事实型文本,如新闻、百科,可视化分析发现其倾向于捕捉事实性语义
- 情感分析更关注主观文本中蕴含的情感和观点,有必要专门训练情感语义表示模型
SKEP训练过程和效果:
2.3情感分析项目简介
2.3.1 项目简介
- 项目结构 传统的情感分类模型,是句子级的情感分类,在宏观上去分析整句话的感情色彩,粒度较粗。人们进行评论的时候,往往针对某一产品或服务进行多个属性的评论,对每个属性的评论可能也会褒贬不一,因此针对属性级别的情感分析在真实的场景中会更加实用,同时更能给到企业用户或商家更加具体的建议。 基于这样的考虑,本项目提出了一种细粒度的情感分析能力,对于给定的文本,首先会抽取该文本中的评论观点,然后分析不同观点的情感极性。项目流程如下图所示:

- 将文本传入评论观点抽取模型,抽取评论属性和对应的观点词,比如下图就抽出三个评论属性和对应的观点词
- 将抽取的属性-观点词对输入属性级情感分类模型,对每个属性进行情感分类。
- 项目特色: - 基于情感分析预训练模型
SKEP,效果好(SKEP在14个中英文公开情感分析数据集上取得SOTA效果)- 易使用- 支持轻量级的PP-MiniLM模型,大幅提升推理速度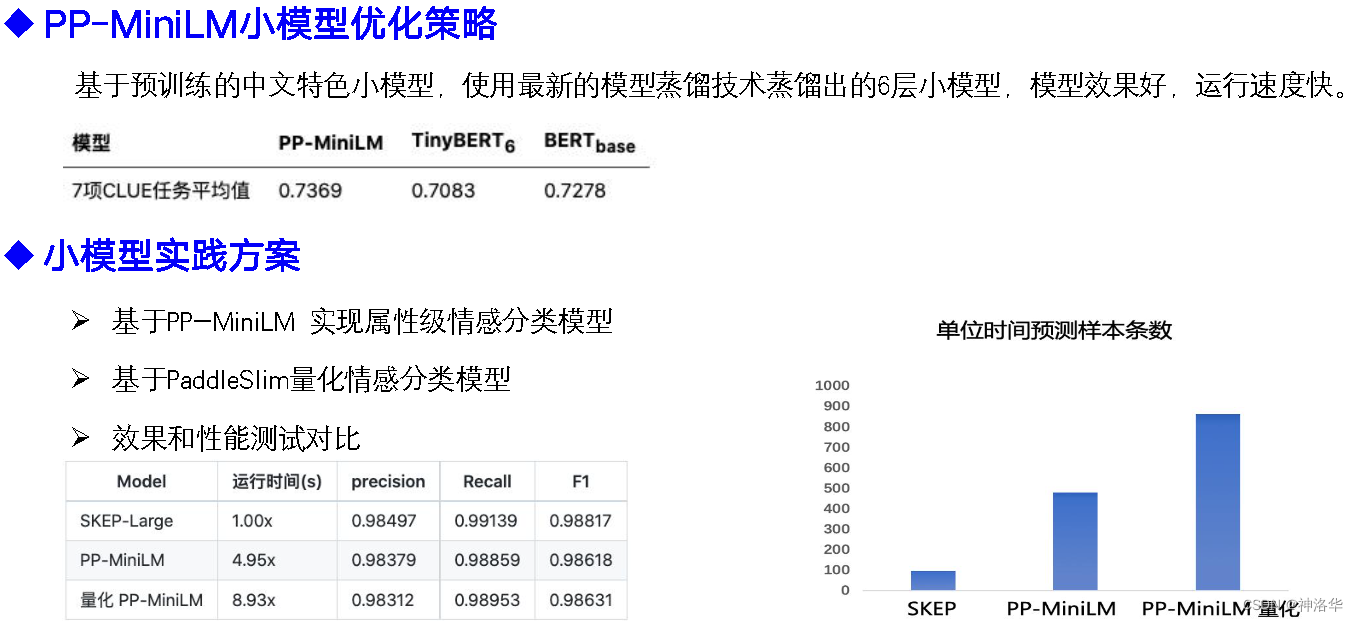
- 情感分析可视化

2.3.2 情感分析技术方案
2.3.2.1 评论观点抽取模型
- 训练: - 整个模型是用序列标注的方式进行训练的,同时抽取序列中的属性和对应的观点。- 比如下图例子中,两个属性分别是‘味道’和‘服务’,所以这两个词对应的BIO标签就是
Aspect(分为B-、I-);这两个属性对应的观点词分别是‘好’和‘棒’,这两个词对应的标签就是B-O。通过这种标注格式就可以训练模型了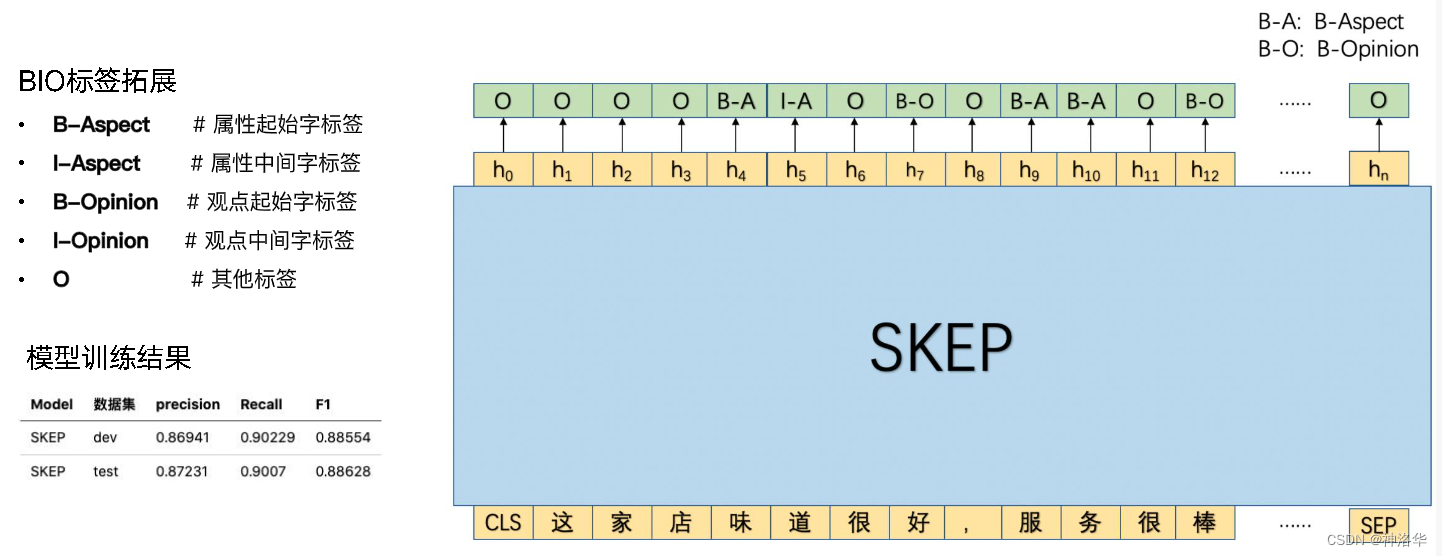
- 解码策略: - 同一个短句之内抽取的评论属性和观点词优先匹配- 短句中只有观点词,则优先匹配到前一个评论属性
- 示例:蛋糕不错,很好吃,店家很耐心,服务也很好,很棒 - aspect: 蛋糕, opinion: {‘好吃’, ‘不错’}- aspect: 店家, opinion: {‘耐心’}- aspect: 服务, opinion: {‘好’, ‘棒’}
不错和蛋糕在一个短句中,优先匹配。很好吃这个短句没有属性,就往前匹配。
2.3.2.2 属性级情感分类模型
此模块使用语句拼接策略进行训练。如下图所示,将属性-观点对拼接在一起成为一个短句(下图中的‘味道好’),然后再和整个句子拼接,一起训练。最终以CLS token位置对应的输出情感的极性,作为属性的情感极性。
2.3 情感分析项目搭建
完整项目参考:评论观点抽取与情感倾向性分析开源项目
2.3.1 开源项目简介
本项目提供全流程预测功能,会自动将抽取的属性和观点传递给情感分类模型,然后经过后处理,得到下图格式的最终输出结果。项目还有以下特点:

- 快速体验- 下载项目后,新建目录
data和checkpoints,分别用于存放数据和保存模型;- 下载评论观点抽取模型ext_model、属性级情感分类模型cls_model,分别放入./checkpoints/ext_checkpoints和./checkpoints/cls_checkpoints中- 输入sh run_demo.sh一行代码,就可以开始进行交互式体验,输入文本输出情感分析结果。 - 文本预测- 如果有一批文本,要进行批量预测。可将测试集文件命名为
test.txt, 然后放入./data目录下。测试集文件每行均为一个待预测的语句,例如:
蛋糕味道不错,很好吃,店家很耐心,服务也很好,很棒
酒店干净整洁,性价比很高
酒店环境不错,非常安静,性价比还可以
房间很大,环境不错
- 运行
sh run_predict.sh,便可进行批量预测,默认放在与输入文件相同的目录下,结果文件名为sentiment_results.json。
- 线上部署高性能预测、自定义模型训练、数据标注说明、小模型优化策略,请参考项目详情。
2.3.2 AI studio 实例
AI studio项目地址
此demo包含:
- 数据集构造、数据预处理(加载dataloadr)
- 评论观点抽取模型搭建和训练
- 属性级情感分类模型搭建和训练
- 全流程推理
- PP-MiniLM实现。
- 评论观点抽取模型,就是一个SKEP为backbone的序列标注模型:
模型输入,可以看出是 一个标准的序列标注格式的输入
for example in train_ds[9:11]:print(example){'text':['不','过','只','要','效','果','好','也','值','了'],'label':['O','O','O','O','B-Aspect','I-Aspect','B-Opinion','O','O','O']}{'text':['口','感','不','错',',','很','好','喝','蛋','挞','和','好','吃'],'label':['B-Aspect','I-Aspect','B-Opinion','I-Opinion','O','B-Opinion','I-Opinion','B-Aspect','B-Aspect','I-Aspect','O','B-Opinion','I-Opinion']}
构造模型:
classSkepForTokenClassification(paddle.nn.Layer):def__init__(self, skep, num_classes=2, dropout=None):# 实例化时类别为5,因为有五种标签super(SkepForTokenClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout isnotNoneelse self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], num_classes)defforward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
sequence_output, _ = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)return logits
实例化模型,配置好训练参数之后开始训练。
# 实例化模型
skep = SkepModel.from_pretrained(model_name)
model = SkepForTokenClassification(skep, num_classes=len(label2id))
- 属性级情感分类
模型输入格式:每个样本包含三列,分别是情感标签、,评论属性-观点、原文。如下所示。
1 口味清淡 口味很清淡,价格也比较公道
模型构建:构造一个基于SKEP的句子分类模型,判断整个句子的极性。
classSkepForSequenceClassification(paddle.nn.Layer):def__init__(self, skep, num_classes=2, dropout=None):super(SkepForSequenceClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout isnotNoneelse self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], num_classes)defforward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
_, pooled_output = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)return logits
实例化模型,配置好训练参数之后开始训练。
skep = SkepModel.from_pretrained(model_name)
model = SkepForSequenceClassification(skep, num_classes=len(label2id))
- 全流程推理 上面训练好的模型是基于demo数据集,可以拿来用,也可以下载百度开源的预训练模型,效果肯定更好。
defpredict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512):# 加载好的两个模型设置为推理模式
ext_model.eval()
cls_model.eval()# processing input text
encoded_inputs = tokenizer(list(input_text), is_split_into_words=True, max_seq_len=max_seq_len,)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])# extract aspect and opinion words
logits = ext_model(input_ids, token_type_ids=token_type_ids)# 得到抽取模型输出
predictions = logits.argmax(axis=2).numpy()[0]
tag_seq =[ext_id2label[idx]for idx in predictions][1:-1]
aps = decoding(input_text, tag_seq)# 解码出属性-观点对# predict sentiment for aspect with cls_model
results =[]for ap in aps:
aspect = ap[0]# 属性
opinion_words =list(set(ap[1:]))# 观点,一个属性可能包含多个观点
aspect_text = concate_aspect_and_opinion(input_text, aspect, opinion_words)# 将属性-观点对和原始文本拼接
encoded_inputs = tokenizer(aspect_text, text_pair=input_text, max_seq_len=max_seq_len, return_length=True)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
logits = cls_model(input_ids, token_type_ids=token_type_ids)# 拼接后的文本输入情感分类模型
prediction = logits.argmax(axis=1).numpy()[0]# 输出情感分类结果
result ={"aspect": aspect,"opinions": opinion_words,"sentiment": cls_id2label[prediction]}# 结果后处理
results.append(result)# print results
format_print(results)
推理测试:
max_seq_len =512
input_text ="环境装修不错,也很干净,前台服务非常好"
predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
- PP-MiniLM实现 - PP-MiniLM方案中使用了很多性能优化策略,需要安装 Paddle Inference 预测库- 推荐在 NVIDA Tensor Core GPU(如 T4、A10、A100) 上进行测试。若在 V 系列 GPU 卡上测试,由于其不支持 Int8 Tensor Core,将达不到预期的加速效果。- 此部分详见《PP-MiniLM 中文小模型》
整个AI studio实例就大致讲完了,有需要可参考原项目。
三、通用信息抽取技术:UIE
B站课程视频、AI Studio项目《三行代码实现开放域信息抽取》、UIE GitHub地址、信息抽取应用
3.1 信息抽取简介
信息抽取是指自动从无结构或半结构的文本中抽取出结构化信息的任务, 主要包含的任务包含了实体识别、关系抽取、事件抽取、情感分析、评论抽取等任务。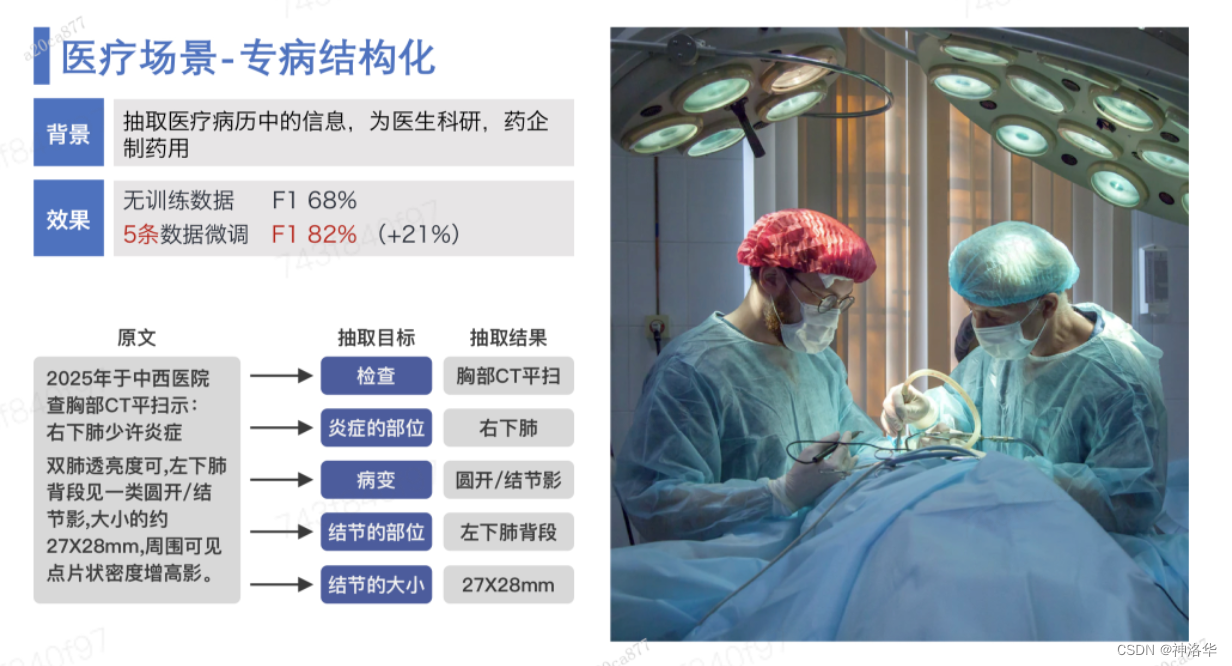

信息抽取难点:
- 需求跨领域跨任务:领域之间知识迁移难度高,如通用领域知识很难迁移到垂类领域,垂类领域之间的知识很难相互迁移;存在实体、关系、事件等不同的信息抽取任务需求。
- 定制化程度高:针对实体、关系、事件等不同的信息抽取任务,需要开发不同的模型,开发成本和机器资源消耗都很大。
- 训练数据无或很少:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高。
针对以上难题,中科院软件所和百度共同提出了一个大一统诸多任务的通用信息抽取技术
UIE
(Unified Structure Generation for Universal Information Extraction),发表在ACL22。
UIE
在实体、关系、事件和情感等4个信息抽取任务、13个数据集的全监督、低资源和少样本设置下,均取得了SOTA性能。
3.2 Taskflow UIE
3.2.1 使用示例
- 信息抽取 人力资源入职证明信息抽取
from paddlenlp import Taskflow
schema =['姓名','毕业院校','职位','月收入','身体状况']
ie = Taskflow('information_extraction', schema=schema)
ie.set_schema(schema)
ie('兹证明凌霄为本单位职工,已连续在我单位工作5 年。学历为嘉利顿大学毕业,目前在我单位担任总经理助理 职位。近一年内该员工在我单位平均月收入(税后)为 12000 元。该职工身体状况良好。本单位仅此承诺上述表述是正确的,真实的。')
[{'姓名':[{'text':'凌霄','start':3,'end':5,'probability':0.9042383385504706}],'毕业院校':[{'text':'嘉利顿大学','start':28,'end':33,'probability':0.9927952662605009}],'职位':[{'text':'总经理助理','start':44,'end':49,'probability':0.9922470268350594}],'月收入':[{'text':'12000 元','start':77,'end':84,'probability':0.9788556518998917}],'身体状况':[{'text':'良好','start':92,'end':94,'probability':0.9939678710475306}]}]
医疗病理分析
schema =['肿瘤部位','肿瘤大小']
ie.set_schema(schema)
ie('胃印戒细胞癌,肿瘤主要位于胃窦体部,大小6*2cm,癌组织侵及胃壁浆膜层,并侵犯血管和神经。')
[{'肿瘤部位':[{'text':'胃窦体部','start':13,'end':17,'probability':0.9601818899487213}],'肿瘤大小':[{'text':'6*2cm','start':20,'end':25,'probability':0.9670914301489972}]}]
英文模型调用示例:
from pprint import pprint
from paddlenlp import Taskflow
schema =['Person','Organization']
ie_en = Taskflow('information_extraction', schema=schema, model='uie-base-en')
pprint(ie_en('In 1997, Steve was excited to become the CEO of Apple.'))[{'Organization':[{'end':53,'probability':0.9985840259877357,'start':48,'text':'Apple'}],'Person':[{'end':14,'probability':0.999631971804547,'start':9,'text':'Steve'}]}]
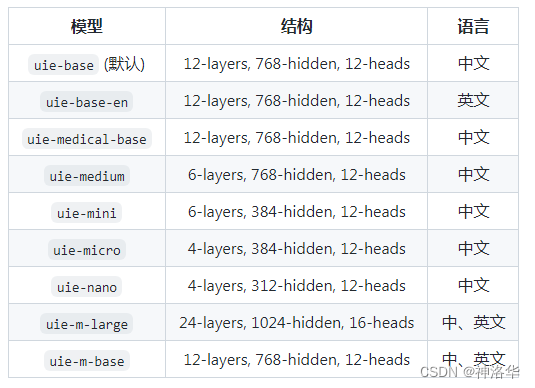
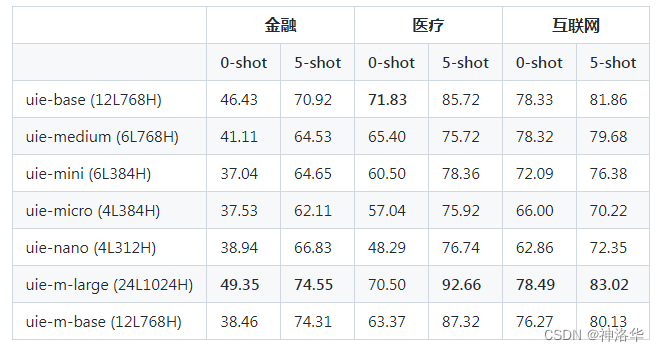
2. 实体抽取、关系抽取、事件抽取、情感分类、观点抽取
# 实体抽取
schema =['时间','赛手','赛事名称']
ie.set_schema(schema)
ie('2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!')[{'时间':[{'text':'2月8日上午','start':0,'end':6,'probability':0.9857379716035553}],'赛手':[{'text':'中国选手谷爱凌','start':24,'end':31,'probability':0.7232891682586384}],'赛事名称':[{'text':'北京冬奥会自由式滑雪女子大跳台决赛','start':6,'end':23,'probability':0.8503080086948529}]}]
# 关系抽取
schema ={'歌曲名称':['歌手','所属专辑']}
ie.set_schema(schema)
ie('《告别了》是孙耀威在专辑爱的故事里面的歌曲')[{'歌曲名称':[{'text':'告别了','start':1,'end':4,'probability':0.629614912348881,'relations':{'歌手':[{'text':'孙耀威','start':6,'end':9,'probability':0.9988381005599081}],'所属专辑':[{'text':'爱的故事','start':12,'end':16,'probability':0.9968462078543183}]}},{'text':'爱的故事','start':12,'end':16,'probability':0.28168707817316374,'relations':{'歌手':[{'text':'孙耀威','start':6,'end':9,'probability':0.9951415104192272}]}}]}]
# 事件抽取
schema ={'地震触发词':['地震强度','时间','震中位置','震源深度']}# 事件需要通过xxx触发词来选择触发词
ie.set_schema(schema)
ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。')[{'地震触发词':[{'text':'地震','start':56,'end':58,'probability':0.9977425555988333,'relations':{'地震强度':[{'text':'3.5级','start':52,'end':56,'probability':0.998080217831891}],'时间':[{'text':'5月16日06时08分','start':11,'end':22,'probability':0.9853299772936026}],'震中位置':[{'text':'云南临沧市凤庆县(北纬24.34度,东经99.98度)','start':23,'end':50,'probability':0.7874014521275967}],'震源深度':[{'text':'10千米','start':63,'end':67,'probability':0.9937974422968665}]}}]}]
# 情感倾向分类
schema ='情感倾向[正向,负向]'# 分类任务需要[]来设置分类的label
ie.set_schema(schema)
ie('这个产品用起来真的很流畅,我非常喜欢')[{'情感倾向[正向,负向]':[{'text':'正向','probability':0.9990024058203417}]}]
# 评价抽取
schema ={'评价维度':['观点词','情感倾向[正向,负向]']}# 评价抽取的schema是固定的,后续直接按照这个schema进行观点抽取
ie.set_schema(schema)# Reset schema
ie('地址不错,服务一般,设施陈旧')[{'评价维度':[{'text':'地址','start':0,'end':2,'probability':0.9888139270606509,'relations':{'观点词':[{'text':'不错','start':2,'end':4,'probability':0.9927845886615216}],'情感倾向[正向,负向]':[{'text':'正向','probability':0.998228967796706}]}},{'text':'设施','start':10,'end':12,'probability':0.9588298547520608,'relations':{'观点词':[{'text':'陈旧','start':12,'end':14,'probability':0.928675281256794}],'情感倾向[正向,负向]':[{'text':'负向','probability':0.9949388606013692}]}},{'text':'服务','start':5,'end':7,'probability':0.9592857070501211,'relations':{'观点词':[{'text':'一般','start':7,'end':9,'probability':0.9949359182521675}],'情感倾向[正向,负向]':[{'text':'负向','probability':0.9952498258302498}]}}]}]
# 跨任务跨领域抽取
schema =['寺庙',{'丈夫':'妻子'}]# 抽取的任务中包含了实体抽取和关系抽取
ie.set_schema(schema)
ie('李治即位后,让身在感业寺的武则天续起头发,重新纳入后宫。')[{'寺庙':[{'text':'感业寺','start':9,'end':12,'probability':0.9888581774497425}],'丈夫':[{'text':'李治','start':0,'end':2,'probability':0.989690572797457,'relations':{'妻子':[{'text':'武则天','start':13,'end':16,'probability':0.9987625986790256}]}}]}]
3.2.2 Taskflow UIE使用技巧
- schema设置可以多尝试,有惊喜!
schema =['才人']
ie.set_schema(schema)
ie('李治即位后,让身在感业寺的武则天续起头发,重新纳入后宫。')[{}]
schema =['妃子']
ie.set_schema(schema)
ie('李治即位后,让身在感业寺的武则天续起头发,重新纳入后宫。')[{'妃子':[{'text':'武则天','start':13,'end':16,'probability':0.9976319401117237}]}]
- 调整batch_size、使用UIE-Tiny模型,提升预测效率
from paddlenlp import Taskflow
schema =['费用']
ie.set_schema(schema)
ie = Taskflow('information_extraction', schema=schema, batch_size=2,model='uie-tiny')
ie(['二十号21点49分打车回家46块钱','8月3号往返机场交通费110元','2019年10月17日22点18分回家打车46元','三月三0号23点10分加班打车21元'])
3.2.3 小样本训练及UIE部署
对于简单的抽取目标可以直接使用paddlenlp.Taskflow实现零样本(zero-shot)抽取,对于细分场景我们推荐使用轻定制功能(标注少量数据进行模型微调)以进一步提升效果。(UIE的建模方式主要是通过 Prompt 方式来建模, Prompt 在小样本上进行微调效果非常有效)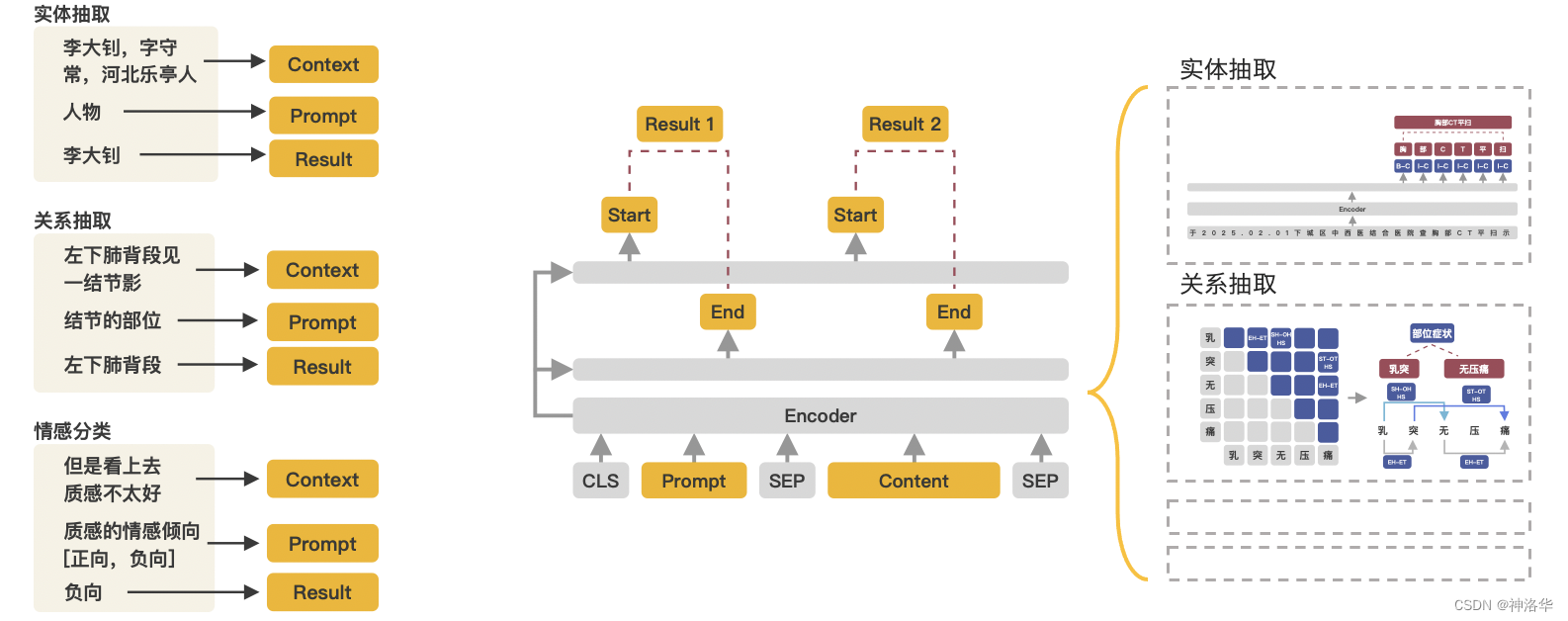
具体的训练过程和模型部署,请参考《三行代码实现开放域信息抽取》或UIE GitHub地址。
四、ERNIE3.0产业应用实践
五、文档智能技术
参考《ERNIE-Layout》、《文档智能应用》
六、NLP流水线搭建检索问答系统
参考《NLP 流水线系统 Pipelines 》
版权归原作者 神洛华 所有, 如有侵权,请联系我们删除。