
AI大模型的战场:通用与垂直的较量
在人工智能的快速发展浪潮中,大模型技术已经站在了科技革命的前沿。随着技术的不断进步和应用场景的不断拓展,AI大模型的战场正在经历一场深刻的分化。本文将探讨这一现象,并分析通用大模型与垂直大模型在落地场景中的不同优势,以及它们在未来竞争中的潜在赛点。

1.引言
AI大模型,以其强大的计算能力和广泛的应用范围,已经成为推动各行各业智能化转型的关键力量。然而,随着市场和技术的不断发展,大模型的发展方向出现了分化:一方面是功能全面、应用广泛的通用大模型;另一方面是专注于特定领域、具有高效率和高精准度的垂直大模型。这两种模型各有千秋,它们在不同的场景下展现出各自的优势。
2.通用大模型的优势
2.1 概念
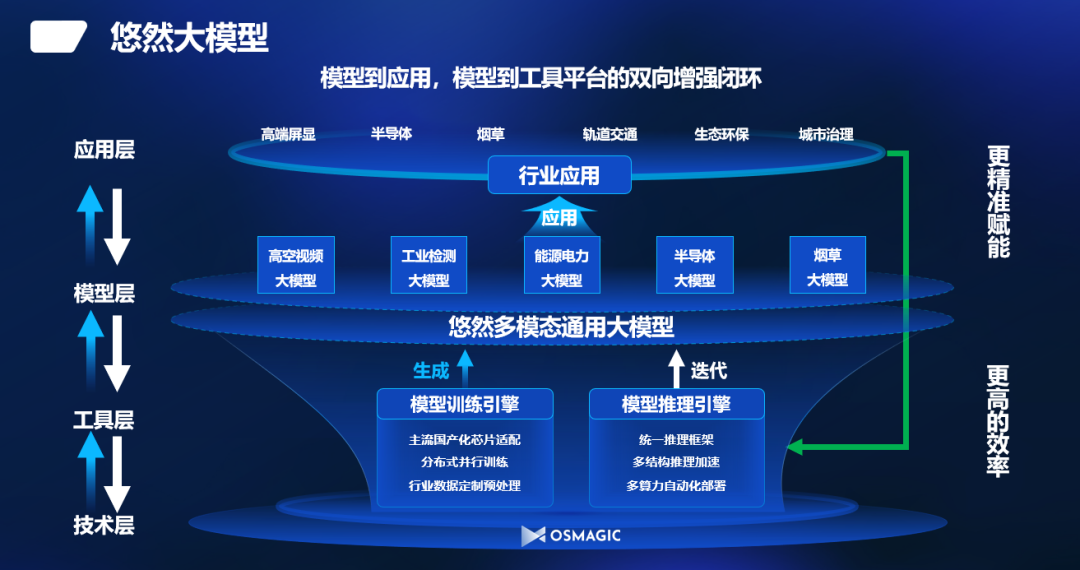
通用大模型,顾名思义,是指那些能够处理多种类型任务的AI模型。它们通常具有较高的灵活性和广泛的适用性,能够适应多变的市场需求和多样化的应用场景。
- 广泛的应用场景:通用大模型可以应用于从自然语言处理到图像识别,再到数据分析等多个领域,几乎涵盖了人工智能的所有应用范畴。
- 技术成熟度:由于长期的技术积累和大量的研究投入,通用大模型在算法和架构上更加成熟,能够提供稳定可靠的服务。
- 持续的创新能力:通用大模型由于其广泛的应用基础,能够吸引更多的研究者和开发者,推动技术的持续创新。
2.2 谷歌的BERT模型
背景:BERT(Bidirectional Encoder Representations from Transformers)是由谷歌在2018年提出的预训练语言表示模型,它在自然语言处理(NLP)领域取得了革命性的进展。

技术特点:
- BERT采用了Transformer架构,通过注意力机制来捕捉词与词之间的关系。
- 它能够理解语言的双向上下文,从而提供更准确的语言表示。
应用场景:
- 文本分类:如情感分析、主题分类等。
- 问答系统:BERT能够理解问题的上下文,并在大量文本中找到准确的答案。
- 机器翻译:通过预训练的模型,BERT能够提供高质量的翻译结果。
代码示例(使用Hugging Face的Transformers库):
from transformers import BertTokenizer, BertModel
# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 准备输入文本
text = "The quick brown fox jumps over the lazy dog"
encoded_input = tokenizer(text, return_tensors='pt')
# 通过模型获取输出
output = model(**encoded_input)
2.3 OpenAI的GPT模型
背景:GPT(Generative Pre-trained Transformer)是由OpenAI开发的一系列预训练语言模型,它们在文本生成方面表现出色。

技术特点:
- GPT模型基于Transformer架构,能够生成连贯且语义合理的文本。
- 它通过预训练大量文本数据,学习语言的模式和结构。
应用场景:
- 文本生成:如撰写文章、生成对话等。
- 内容推荐:根据用户的历史行为生成个性化的内容推荐。
代码示例(使用OpenAI的GPT库):
from openai.gpt_2_simple import start_finetuning
# 准备训练数据
training_data = [
"Here is some training data...",
"Here is some more training data...",
# ... 更多数据
]
# 开始微调GPT-2模型
start_finetuning(training_data)
2.4 微软的Visual Studio Code
背景:虽然Visual Studio Code不是一个AI模型,但它集成了多种AI功能,如代码补全、智能代码导航等,这些功能背后通常依赖于通用大模型。

技术特点:
- 集成了机器学习算法,能够根据用户的编码习惯提供个性化的代码建议。
- 支持多种编程语言和开发环境,具有高度的灵活性。
应用场景:
- 代码开发:帮助开发者快速编写代码,减少错误。
- 代码审查:自动检测潜在的代码问题,提高代码质量。
代码示例(使用Visual Studio Code的AI功能):
# 假设你正在使用Visual Studio Code进行Python开发
# 当你键入代码时,VS Code会提供智能补全建议
x = [1, 2, 3]
average = sum(x) / len(x) # VS Code会在这里提供len函数的补全建议
2.5 结论

通用大模型因其广泛的适用性和技术成熟度,在多个领域内都有着重要的应用。通过上述案例,我们可以看到它们在自然语言处理、文本生成和开发工具中的成功应用。随着技术的不断进步,我们可以预见通用大模型将在未来的AI领域扮演更加关键的角色。
3.垂直大模型的崛起
3.1 概念
与通用大模型相比,垂直大模型专注于特定领域或任务,它们在特定场景下的性能往往更为出色。
- 专业化优势:垂直大模型针对特定领域进行了优化,能够提供更加精准和高效的服务。
- 快速响应市场变化:由于专注于特定领域,垂直大模型能够更快地适应市场的变化和需求,实现快速迭代和优化。
- 成本效益:在某些情况下,垂直大模型由于其专注性,可能在成本上更具优势,尤其是在资源有限的情况下。
3.2 医疗影像分析的AI模型
背景:医疗影像分析是AI垂直领域中的一个重要应用,特别是在癌症检测和诊断方面。
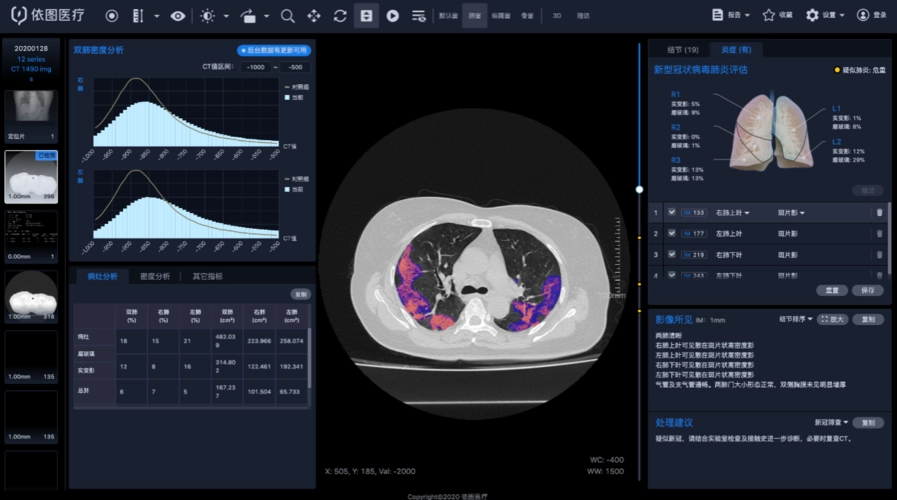
技术特点:
- 垂直大模型通常在大量医疗影像数据上进行训练,学习识别病变特征。
- 它们能够辅助医生进行更准确的诊断,提高诊断效率。
应用场景:
- 癌症检测:如乳腺癌、肺癌等的早期检测。
- 骨折诊断:快速识别骨折类型和位置。
代码示例(使用TensorFlow和Keras进行简单的图像分类模型训练):
import tensorflow as tf
from tensorflow.keras import layers, models
# 假设我们有一个医疗影像数据集
train_images = ...
train_labels = ...
# 构建一个简单的卷积神经网络模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(1) # 假设是二分类问题
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=10)
3.3 自动驾驶领域的AI模型
背景:自动驾驶是AI领域的另一个垂直应用,涉及到复杂的感知、决策和控制算法。

技术特点:
- 垂直大模型在自动驾驶中用于处理车辆感知、路径规划和驾驶决策。
- 它们能够实时处理传感器数据,做出快速反应。
应用场景:
- 车辆感知:识别行人、车辆、交通信号等。
- 路径规划:根据实时交通状况规划最佳行驶路线。
代码示例(使用TensorFlow进行车辆检测模型的训练):
import numpy as np
import cv2
# 加载预训练的模型,这里以YOLO为例
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
# 加载图像
image = cv2.imread("image.jpg")
# 使用模型进行车辆检测
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(416, 416), mean=(0, 0, 0))
net.setInput(blob)
outs = net.forward()
# 处理检测结果
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5:
# 绘制检测框等
pass
3.4 金融风控模型
背景:金融风控是AI垂直领域的另一个重要应用,涉及到信用评分、欺诈检测等。
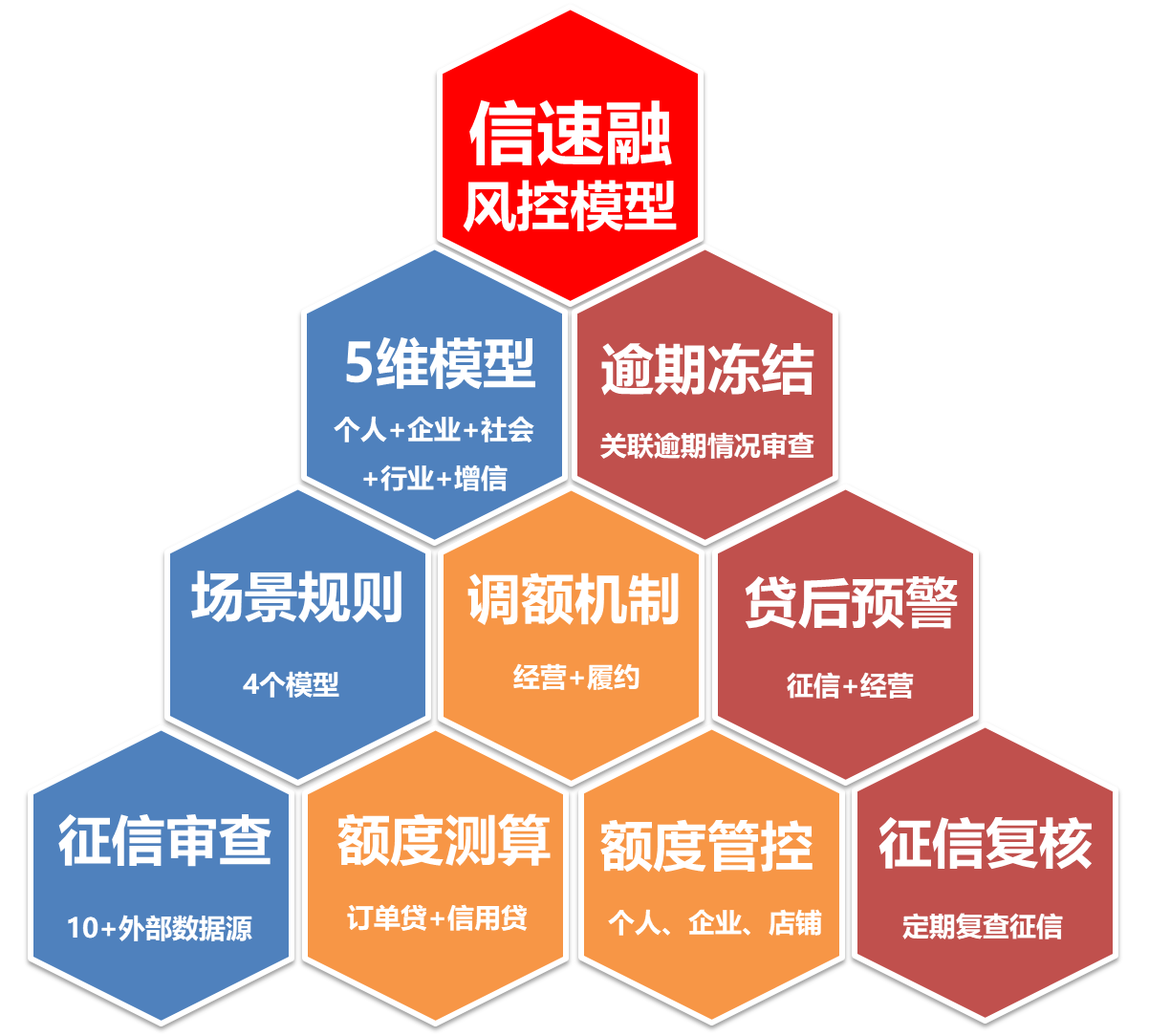
技术特点:
- 垂直大模型在金融风控中用于分析用户行为、交易模式等,以识别潜在的风险。
- 它们能够处理大量的交易数据,提供实时的风险评估。
应用场景:
- 信用评分:评估用户的信用风险。
- 欺诈检测:识别异常交易行为。
代码示例(使用scikit-learn进行简单的信用评分模型训练):
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 假设我们有一个金融风控数据集
X = ... # 特征数据
y = ... # 目标变量,例如是否违约
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林分类器
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
# 评估模型
score = clf.score(X_test, y_test)
print(f"Model accuracy: {score}")
3.5 结论
垂直大模型以其专业化优势、快速的市场响应能力和成本效益,在特定领域展现出了卓越的性能。通过上述案例,我们可以看到它们在医疗影像分析、自动驾驶和金融风控等领域的成功应用。随着技术的不断进步和市场对专业化服务需求的增加,垂直大模型将在未来的AI领域扮演越来越重要的角色。

4.大模型的赛点:谁将占据优势?
在AI大模型的战场上,通用与垂直的较量已经展开。第一个赛点,即谁能先形成绝对优势,目前还没有明确的答案。以下是几个可能的赛点:
- 技术突破:无论是通用还是垂直大模型,技术上的突破都可能成为决定性的因素。谁能在算法效率、模型精度或能耗优化上取得重大进展,谁就可能占据优势。
- 市场接受度:用户和市场对于大模型的接受度也是关键。模型的易用性、成本效益和实际效果将直接影响其市场表现。
- 生态系统建设:围绕大模型构建的生态系统,包括开发者社区、合作伙伴和应用案例,也是竞争中的重要方面。
5.结语
AI大模型的战场正在分化,通用与垂直的较量才刚刚开始。无论是通用大模型的广泛适用性,还是垂直大模型的专业优势,它们都在推动着人工智能技术的发展和应用。作为观察者和参与者,我们更应关注这场竞争背后的技术创新和市场动态,以期把握未来的发展趋势。
在这个充满变数的赛点上,我个人更倾向于看好那些能够快速适应市场变化、提供定制化解决方案的垂直大模型。它们在特定领域的深耕,可能会带来更加精准和高效的服务,从而在竞争中占据一席之地。然而,这并不意味着通用大模型没有优势,它们在技术成熟度和创新能力上仍然具有不可小觑的潜力。
最终,无论是通用还是垂直,AI大模型的发展都将深刻影响我们的生活和工作方式。让我们拭目以待,这场技术革命将如何塑造我们的未来。

版权归原作者 正在走向自律 所有, 如有侵权,请联系我们删除。