
本文讲述sknet的核心部分:自适应性的注意力编码机制
SKNet 对不同输入使用的卷积核感受野不同,参数权重也不同,可以自适应的对输出进行处理
注:本人才疏学浅,文章难免有疏漏之处,仅给初学者阅读交流,大牛轻喷.
开始之前的题外话
说来也算有趣,最近读了几个关于CV领域的paper,有的号称其idea来源于神经科学,比如SIM-AM的三维特征推断(这个其实没怎么看懂),言归正传,我们看一看sknet吧

1.神经科学背景


比如说inception模型的'宽度'

于是提出了sknet,不同大小的感受视野(卷积核)对于不同尺度的目标会有不同的效果。尽管 Inception 这样的增加了多个卷积核来适应不同尺度图像,但是卷积核权重相同,参数就是被计算好的了.SKNet 对不同输入使用的卷积核感受野不同,参数权重也不同,可以自适应的对输出进行处理
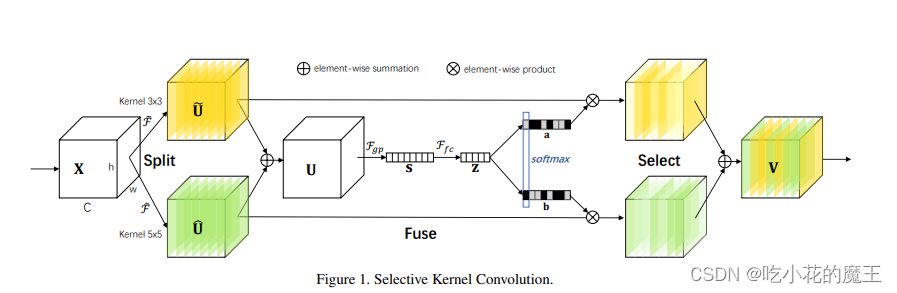
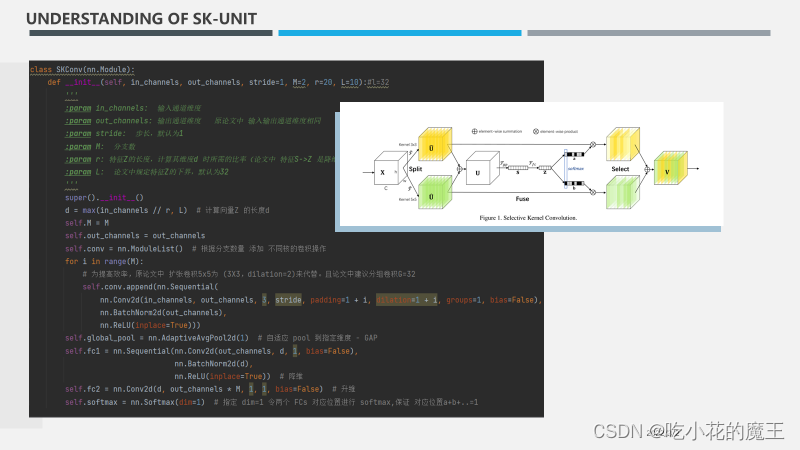
sknet网络主要由 Split、Fuse、Select 三部分组成。
原文:'为了使神经元能够自适应地调整它们的 RF 大小,我们提出了一种自动选择操作,即“选择性内核”(SK)卷积,在具有不同内核大小的多个内核中。具体来说,我们通过三个运算符实现 SK 卷积——Split、Fuse 和 Select,如图 1 所示,其中显示了两个分支的情况。因此在这个例子中,只有两个内核大小不同的内核,但是很容易扩展到多个分支的情况。'
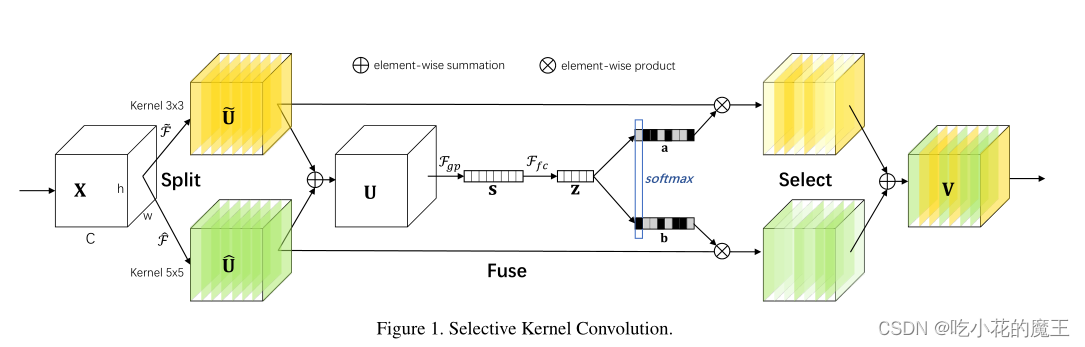
1.SPILT部分
'拆分:对于任何给定的特征图 X ∈ C H W,默认情况下,我们首先进行两个变换(其实就是卷积,对应图中的X到两个U)
细节:内核大小为 3和 5,分别。请注意,这里的卷积是有效的分组/深度卷积、批量归一化 和 ReLU 函数依次组成。为了进一步提高效率,具有 5×5 内核的传统卷积被替换为具有 3×3 内核和扩张大小 2 的扩张卷积。'
什么意思?
很简单,看代码:
无非就是在两个支路上运用了深度卷积和分组卷积,以及一个支路是33核,另一个是55核,不过被用了空洞卷积的3*3核代替了
注:空洞卷积,一样的参数,更大的感受野
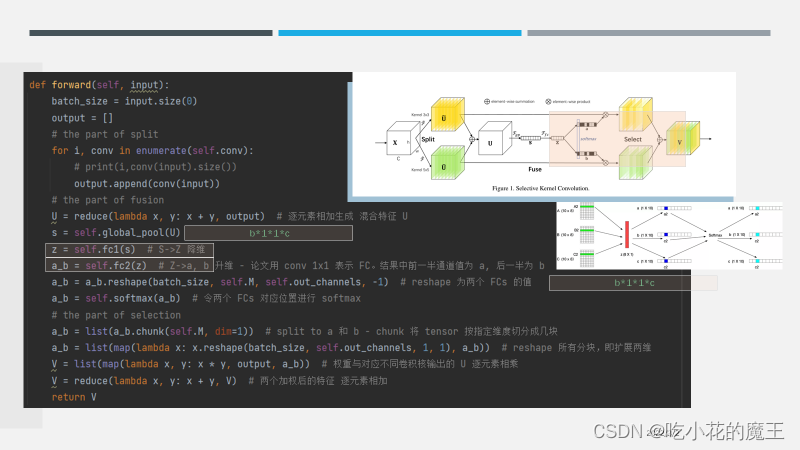
2.FUSE:特征融合
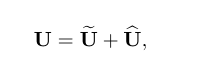
也就是说X.SHAPE = U.SHAPE
逐元素相加
再次经过一个GAP,对channels嵌入空间信息
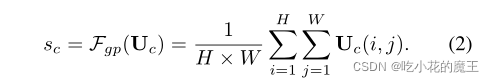
此外,还创建了一个紧凑的特征 z ∈ d×1,以实现精确和自适应选择的指导。这是通过一个简单的全连接 (fc) 层实现的,通过降低维度来提高效率:
这里的d是这样求出来的
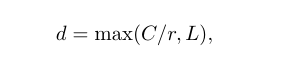
(这里有点像bottleneck结构)
什么是bottleneck结构?
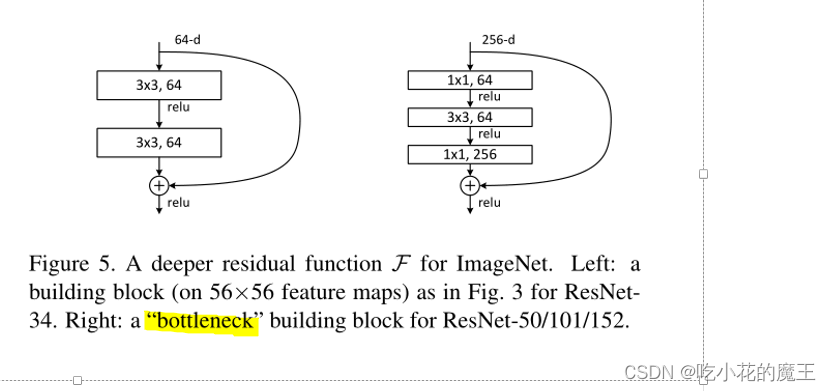
这里讲解的不错:
轻量级网络:Bottleneck结构(沙漏型结构)_那年聪聪-CSDN博客_bottleneck结构
3.SELECT
Select 部分是根据不同卷积核计算后 得到的新的feature map的perocess
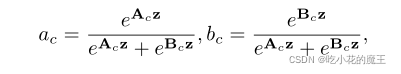
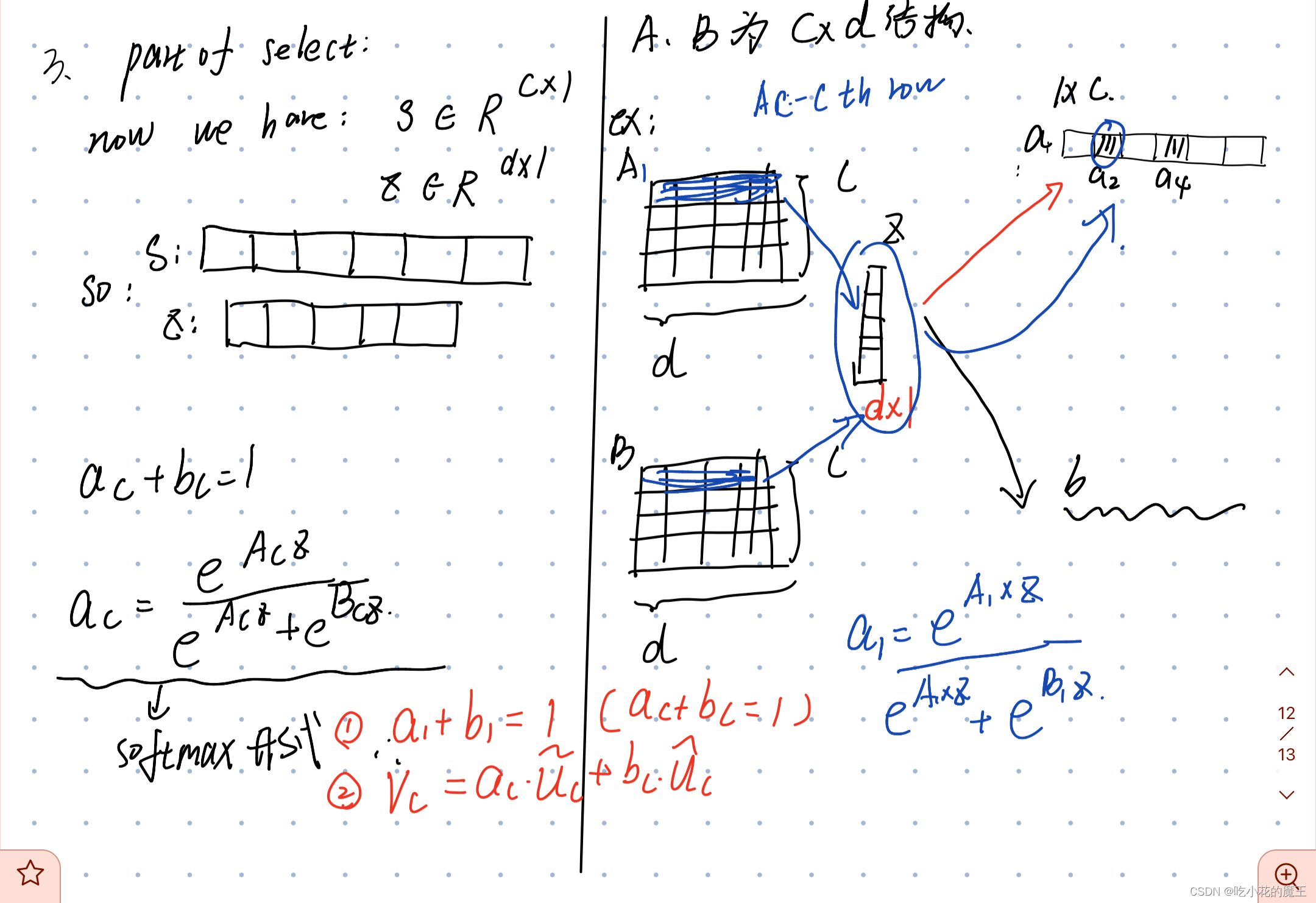
应该够清晰了
最后,附上代码截图
版权归原作者 吃小花的魔王 所有, 如有侵权,请联系我们删除。