
【Python】猎聘网招聘数据爬虫(Python网络爬虫课设简要)
注:
- 本文仅供学习交流使用!
- 合肥学院-20信管-20302211009
- 项目文件可自行前往博客主页下载或联系作者qq(3416252112)。
- 爬取数据耗时约50分钟!
1、背景介绍(废话)
随着全球经济的发展和全球化竞争的加剧,招聘人才对于企业的成功变得至关重要。同时,求职者也面临着日益激烈的就业竞争。在这样的背景下,招聘市场不断发展,招聘过程变得更加复杂和竞争激烈。
互联网的普及和技术的发展给招聘带来了新的机遇和挑战。互联网招聘平台的兴起为企业和求职者提供了更广泛的交流和信息渠道。企业可以在招聘平台上发布招聘信息,同时通过筛选和匹配算法更准确地找到符合要求的人才;求职者可以通过招聘平台查找和申请适合自己的工作岗位。这种高效便捷的招聘方式极大地提高了招聘效率和成功率。
作为国内领先的互联网招聘平台之一,猎聘网汇聚了众多企业和求职者。其庞大的企业用户群体和海量的招聘信息资源使得猎聘网成为了人力资源管理领域的重要参考和决策依据。因此,对于猎聘网招聘数据的爬取和可视化分析具有重要的研究和实践价值。
在接下来的报告中,我们将详细介绍猎聘网招聘数据的爬取与可视化方法,并探讨其在人力资源决策和市场分析中的应用。
2、研究内容与目标(废话)
招聘数据对于人力资源决策具有重要性。通过分析招聘数据,可以了解当前市场的人才需求情况、行业的就业趋势以及薪资水平的变化等信息。这些信息对企业在招聘岗位时可以更好地定位和吸引合适的人才,从而提高招聘的效率和成功率。同时,求职者可以利用招聘数据了解就业市场的动态,选择适合自己的岗位和行业,提升就业竞争力。
猎聘网作为一家知名的招聘平台,拥有庞大的招聘数据资源。理解和利用猎聘网的招聘数据,可以帮助我们深入了解不同行业的人才需求和就业趋势,为企业的人才战略提供有力支持。通过数据爬取和可视化的方法,我们可以将海量的数据转化为直观、易于理解的图表和图形,帮助决策者快速把握关键信息,做出准确的决策。
本报告的目的是介绍猎聘网招聘数据的爬取与可视化方法,通过对招聘数据的分析和可视化,为人力资源决策提供科学依据,提高招聘效率和成功率。同时,我们还希望能够推动数据爬取与可视化技术在招聘领域的应用和研究,促进人力资源管理的创新和发展。
3、爬取对象
爬取数据对象为[‘Java开发’, ‘数据挖掘’, ‘互联网产品经理’, ‘软件测试’, ‘图像算法工程师’],这五个关键字的检索结果,每个关键字共有四百条检索结果,总计2000条记录,最终成功爬取记录数为1581条,表结构如下图所示。

4、功能描述
本次课设数据爬虫功能主要包括以下几个方面:
- 数据收集:数据爬虫能够自动化地从目标网站上抓取数据。通过指定合适的URL和参数,爬虫可以访问网页并提取所需的信息,例如招聘信息、公司信息、职位要求、工作地点等。爬虫可以遍历多个页面或进行深度抓取,以获取更全面的数据。
- 数据解析:爬虫可以解析从网页中提取的原始数据,并提取出有用的信息。这包括对HTML、XML等页面结构的解析,以及对文本、图像、链接等内容的提取和分析。通过数据解析,爬虫能够将抓取的数据转化为结构化的格式,以便后续的处理和分析。
- 数据清洗:抓取的数据往往包含冗余、不完整或错误的信息。数据爬虫可以进行数据清洗,去除重复项、清理无效数据,并进行格式化和规范化,以确保数据的准确性和一致性。数据清洗可以提高后续数据处理和分析的效果。
- 数据存储:抓取到的数据需要进行存储,以便后续的使用和分析。数据爬虫可以将清洗后的数据保存到合适的存储介质中,如数据库、文件或云存储服务。爬虫还可以管理数据存储的结构和索引,以方便数据的检索和查询。
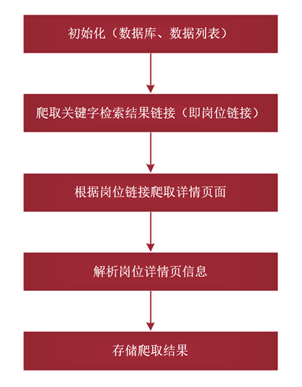
5、数据爬取及存储流程
数据爬取及存储业务流程共包含以下步骤:
- 初始化:创建数据库、创建表、创建全局的数据列表(用于暂时存储爬取结果);
- 使用selenium爬取关键字检索结果中的岗位信息链接,并存入txt文件中;
- 岗位链接爬取完成之后读取岗位链接,然后通过requests依次爬取岗位页面;
- 使用XPath对爬取到的页面进行解析并将解析结果添加到数据列表(同时将岗位的详细信息保存到txt文件中,以备生成词云图);
- 页面解析完成后,遍历数据列表,将取出的数据依次插入到数据库表中,最后结束爬取.
流程图如下:
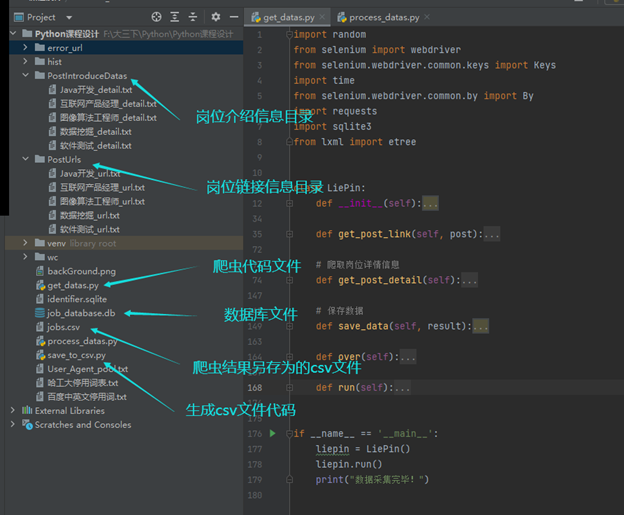
6、爬虫目录结构介绍
爬虫代码总体包含六个方法别为
__init__()
、
get_post_link()
、
get_post_detail()
、
save_data()
、
over()
、
run()
,具体功能如下:
__init__:该方法主要作用为创建全局信息(岗位列表、岗位链接列表、岗位数据列表)、创建数据库连接和表、读取用户标识库(User-Agent);get_post_link:该方法主要功能为使用selenium动态爬取关键字(岗位列表)检索结果的岗位链接,并将链接信息保存到同级目录下的“PostUrls”目录;get_post_detail:根据“PostUrls”目录下的url信息,使用requests依次爬取岗位详情页,并使用XPath对页面进行解析,将解析后的数据添加到岗位数据列表,以及将岗位详情字段保存到同级目录下得“PostIntroduceDatas”目录下以备生成岗位词云图;save_data:遍历岗位数据列表使用SQL语句依次将列表中的数据插入到job_database数据库的Jobs表中;over:该方法用于关闭数据库连接;run:运行方法,调用get_post_link()、get_post_detail()和over()方法,进行爬虫工作;
代码结构如下图:
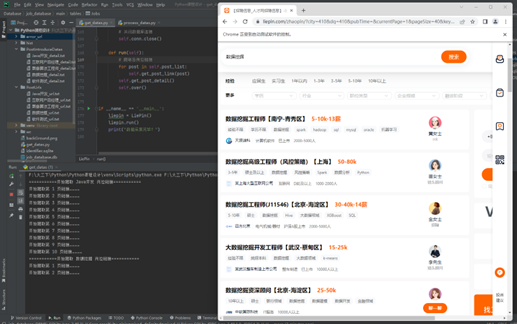
7、爬取过程截图
- 爬取岗位链接截图
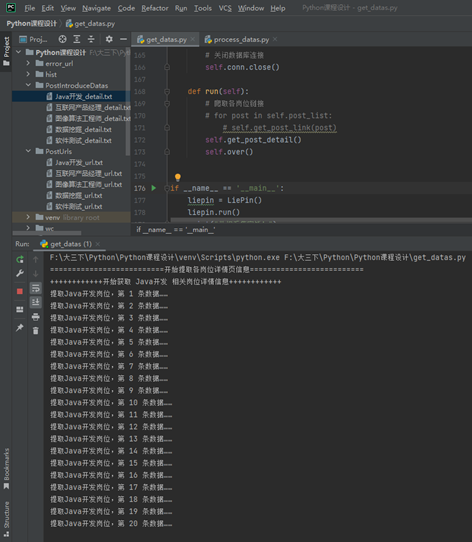
- 提取岗位数据截图
8、爬虫源代码
import random
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.by import By
import requests
import sqlite3
from lxml import etree
classLiePin:def__init__(self):# 岗位列表
self.driver =None
self.post_list =['Java开发','数据挖掘','互联网产品经理','软件测试','图像算法工程师']# 岗位链接列表
self.all_link =[]# 等待3三秒
time.sleep(3)# 随机用户(User_Agent)withopen('User_Agent_pool.txt','r', encoding='utf8')as fp:
self.user_Agent = fp.readlines()
self.user_Agent =[i.strip()for i in self.user_Agent]# 创建数据库连接对象
self.conn = sqlite3.connect('job_database.db')# 创建游标对象
self.cursor = self.conn.cursor()# 创建jobs表
self.create_table_sql ="CREATE TABLE Jobs (信息ID INTEGER PRIMARY KEY AUTOINCREMENT, 岗位链接 VARCHAR, 搜索岗位名 VARCHAR, 岗位名称 VARCHAR, " \
"企业名称 VARCHAR, 薪资区间 VARCHAR, 工作地点 VARCHAR, 工作经验 VARCHAR, 学历要求 VARCHAR, 岗位介绍 VARCHAR, 其他待遇 VARCHAR , 企业经营范围 VARCHAR)"
self.cursor.execute(self.create_table_sql)defget_post_link(self, post):# 创建浏览器对象
self.driver = webdriver.Chrome()# 打开网页
self.driver.get('https://www.liepin.com/zhaopin/')
time.sleep(3)print("===========开始爬取", post,"岗位链接===========")# 定位搜索框并输入关键词
search_box = self.driver.find_element(By.XPATH,"//div[@id='lp-search-bar-section']//input")
search_box.send_keys(post)
search_box.send_keys(Keys.RETURN)# 共爬取10页链接# 结果数据
result =[]for page inrange(10):print("开始爬取第", page +1,"页链接…………")# 等待页面加载完成
time.sleep(3)# 读取当前页岗位数量
divs = self.driver.find_elements(By.XPATH,"//div[@class='content-wrap']//div[@class='job-list-box']/div")for i inrange(1,len(divs)+1):# print(i)
link = self.driver.find_element(By.XPATH,f"//div[@class='job-list-box']/div[{i}]//a").get_attribute("href")# 存储岗位链接信息
result.append(str(link))# print("测试", result[0])
time.sleep(3)# 爬取下一页if page ==9:break
self.driver.find_element(By.XPATH,"//div[@class='list-pagination-box']//li[""@class='ant-pagination-next']/button").click()# 将链接列表保存至文件
self.all_link.append(result)withopen(f'PostUrls/{post}_url.txt','a', encoding='utf-8')as fp:for item in result:
fp.write(item +'\n')# 爬取岗位详情信息defget_post_detail(self):print("==========================开始提取各岗位详情页信息==========================")for post in self.post_list:print("++++++++++++开始获取", post,"相关岗位详情信息++++++++++++")withopen(f'PostUrls/{post}_url.txt','r', encoding='utf-8')as fp:
urls = fp.readlines()withopen(f'PostIntroduceDatas/{post}_detail.txt','a', encoding='utf-8')as fp:
index =0
result =[]for url in urls:
index +=1print(f"提取{post}岗位,第", index,"条数据……")
time.sleep(1)try:# 发送GET请求
response = requests.get(url=url, headers={"User-Agent": random.choice(self.user_Agent)})
html_str = etree.HTML(response.text)# 岗位链接
post_link =str(url)# 搜索岗位名
search_name = post
# 岗位名称
post_name = html_str.xpath("//body/section[3]//div[@class='name-box']/span[1]")[0].text
# 企业名称
enterprise_name = html_str.xpath("//aside//div[@class='company-info-container']//div[""contains(@class,'name')]")[0].text
# 企业经营范围
enterprise_scope = html_str.xpath("//aside//div[@class='register-info']/div[contains(@class,""'ellipsis-4')]/span[2]")[0].text
# 薪资区间
post_salary = html_str.xpath("//body/section[3]//div[@class='name-box']/span[@class='salary']")[0].text
# 工作地点
post_location = html_str.xpath("//body/section[3]//div[@class='job-properties']/span[1]")[0].text
# 工作经验
work_experience = html_str.xpath("//body/section[3]//div[@class='job-properties']/span[3]")[0].text
# 学历要求
educational_requirements = html_str.xpath("//body/section[3]//div[""@class='job-properties']/span[5]")[0].text
# 其他待遇
about_treatment =''for sub in html_str.xpath("//body/section[4]//div[@class='labels']/span"):
about_treatment +=' '+ sub.text
# 岗位介绍
post_introduce = html_str.xpath("//main//dl[1]/dd")[0].text
# 保存数据# self.save_data(post_link, )
detail ={"岗位链接": post_link,"搜索岗位名": search_name,"岗位名称": post_name,"企业名称": enterprise_name,"薪资区间": post_salary,"工作地点": post_location,"工作经验": work_experience,"学历要求": educational_requirements,"岗位介绍": post_introduce,"其他待遇": about_treatment,"企业经营范围": enterprise_scope
}# 添加至总结果列表
result.append(detail)# print(detail)# 将岗位介绍信息写入txt文件,以备提取词云
fp.write(detail['岗位介绍']+'\n\n')except Exception as e:withopen('error_url/error_message.txt','a', encoding='utf-8')as f:
f.write("爬取失败url:"+ url)# 将数据存入数据库print(f"+++++开始将{post}岗位数据存入数据库+++++")
self.save_data(result)# 保存结果数据# self.save_data(result)# 保存数据defsave_data(self, result):print("==========开始将数据存入数据库=========")print("共",len(result),"条数据,开始存入数据库…………")for item in result:try:
insert_sql =f"INSERT INTO Jobs(岗位链接, 搜索岗位名, 岗位名称, 企业名称, 薪资区间, 工作地点, 工作经验, 学历要求, 岗位介绍, 其他待遇, 企业经营范围) " \
f"VALUES('{item['岗位链接']}', '{item['搜索岗位名']}', '{item['岗位名称']}', '{item['企业名称']}', '{item['薪资区间']}', '{item['工作地点']}', '{item['工作经验']}', '{item['学历要求']}', '{item['岗位介绍']}', '{item['其他待遇']}', '{item['企业经营范围']}')"
self.cursor.execute(insert_sql)except Exception as e:print("当前记录异常,忽略……")# 提交事务
self.conn.commit()print("数据存储完毕!")defover(self):# 关闭数据库连接
self.conn.close()defrun(self):# 爬取各岗位链接for post in self.post_list:
self.get_post_link(post)
self.get_post_detail()
self.over()if __name__ =='__main__':
liepin = LiePin()
liepin.run()print("数据采集完毕!")
版权归原作者 Etui۹(・༥・´)و ̑̑ 所有, 如有侵权,请联系我们删除。