
- 🔗 运行环境:python3
- 🚩 作者:K同学啊
- 🥇 精选专栏:《深度学习100例》
- 🔥 推荐专栏:《新手入门深度学习》
- 📚 选自专栏:《Matplotlib教程》
- 🧿 优秀专栏:《Python入门100题》
大家好,我是K同学啊!
在上一篇文章中,我使用LSTM对电商评论做了一个较为复杂的情感分析,本文就继续上次的工作做进一部分的分析。**本次主要是在评价指标metrics处增加了
Precision
、
Recall
、
AUC
等值,实现了训练模型的同时记录这些指标,是实现方式上与以往也有所不同。与此同时,本次全连接层Dense的输出也被设置为1**,之前很少这样操作的,可以对这块针对性学习一下。
文章目录
一、前期工作
1. 导入数据
#源码内可阅读
df
evaluationlabel0用了一段时间,感觉还不错,可以正面1电视非常好,已经是家里的第二台了。第一天下单,第二天就到本地了,可是物流的人说车坏了,一直催...正面2电视比想象中的大好多,画面也很清晰,系统很智能,更多功能还在摸索中正面3不错正面4用了这么多天了,感觉还不错。夏普的牌子还是比较可靠。希望以后比较耐用,现在是考量质量的时候。正面.........4278一般,差强人意,还弄了点不愉快,投诉了好久才解决负面4279屏幕拐角明显暗,图像不到边。工程师上门尽然说没问题!退货还要收100元的开箱费,帮别人买的,...负面4280一分都不想给,京东这次让我太失望了,买的电视没有声音,说是退货上门取件,规定好的时间不去,一...负面4281新电视买回家不到十多天,底座支架因质量问题断裂,电视从桌子上摔坏,打售后电话,人员一直推脱不...负面4282一般般。这个价位也不会抱太多的期望。比某某TV还是好很多。负面
4283 rows × 2 columns
2. 数据分析
df.groupby('label')["evaluation"].count()
label
正面 1908
负面 2375
Name: evaluation, dtype: int64
df.label.value_counts().plot(kind='pie', autopct='%0.05f%%', colors=['lightblue','lightgreen'], explode=(0.01,0.01))
<AxesSubplot:ylabel='label'>

df['length']= df['evaluation'].apply(lambda x:len(x))
df.head()
evaluationlabellength0用了一段时间,感觉还不错,可以正面151电视非常好,已经是家里的第二台了。第一天下单,第二天就到本地了,可是物流的人说车坏了,一直催...正面972电视比想象中的大好多,画面也很清晰,系统很智能,更多功能还在摸索中正面333不错正面24用了这么多天了,感觉还不错。夏普的牌子还是比较可靠。希望以后比较耐用,现在是考量质量的时候。正面46
# 源码内可阅读
plt.show()

# 源码内可阅读
plt.show()
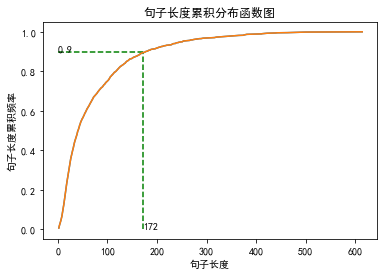
分位点为0.9的句子长度:172。
二、数据预处理
1. 打乱数据
将正面文本数据与负面文本数据进行打乱
df = df.sample(frac=1)
df.head()
evaluationlabellength2105电视不错,不过今年的价格比去年贵了……负面19996电视很清晰大品牌值得信赖正面124171电视不错,没有坏点,漏光也基本看不出来,看了下电视剧,有点拖影,网上换个接口就好了,暂时没试...负面1183206喇叭太差劲,有点小卡,界面不是很友好,与泰捷盒子差太远了,但播放效果色彩不错,漏光较多负面431748好,送货速度快,服务好。.3333333正面20
2. 分词处理
import jieba
word_cut =lambda x: jieba.lcut(x)
df['words']= df["evaluation"].apply(word_cut)
df.head()
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.442 seconds.
Prefix dict has been built successfully.
evaluationlabellengthwords2105电视不错,不过今年的价格比去年贵了……负面19[电视, 不错, ,, 不过, 今年, 的, 价格比, 去年, 贵, 了, …, …]996电视很清晰大品牌值得信赖正面12[电视, 很, 清晰, 大, 品牌, 值得, 信赖]4171电视不错,没有坏点,漏光也基本看不出来,看了下电视剧,有点拖影,网上换个接口就好了,暂时没试...负面118[电视, 不错, ,, 没有, 坏点, ,, 漏光, 也, 基本, 看不出来, ,, 看, ...3206喇叭太差劲,有点小卡,界面不是很友好,与泰捷盒子差太远了,但播放效果色彩不错,漏光较多负面43[喇叭, 太, 差劲, ,, 有点, 小卡, ,, 界面, 不是, 很, 友好, ,, 与,...1748好,送货速度快,服务好。.3333333正面20[好, ,, 送货, 速度, 快, ,, 服务, 好, 。, ., 3333333]
3. 去除停用词
withopen("hit_stopwords.txt","r", encoding='utf-8')as f:
stopwords = f.readlines()
stopwords_list =[]for each in stopwords:
stopwords_list.append(each.strip('\n'))# 添加自定义停用词
stopwords_list +=["…","去","还","西","一件","月","年",".","都"]defremove_stopwords(ls):# 去除停用词return[word for word in ls if word notin stopwords_list]
df['去除停用词后的数据']=df["words"].apply(lambda x: remove_stopwords(x))
df["y"]= np.array([1if i=="正面"else0for i in df['label']])
df.head()
evaluationlabellengthwords去除停用词后的数据y2105电视不错,不过今年的价格比去年贵了……负面19[电视, 不错, ,, 不过, 今年, 的, 价格比, 去年, 贵, 了, …, …][电视, 不错, 今年, 价格比, 去年, 贵]0996电视很清晰大品牌值得信赖正面12[电视, 很, 清晰, 大, 品牌, 值得, 信赖][电视, 很, 清晰, 大, 品牌, 值得, 信赖]14171电视不错,没有坏点,漏光也基本看不出来,看了下电视剧,有点拖影,网上换个接口就好了,暂时没试...负面118[电视, 不错, ,, 没有, 坏点, ,, 漏光, 也, 基本, 看不出来, ,, 看, ...[电视, 不错, 没有, 坏点, 漏光, 基本, 看不出来, 看, 下, 电视剧, 有点, ...03206喇叭太差劲,有点小卡,界面不是很友好,与泰捷盒子差太远了,但播放效果色彩不错,漏光较多负面43[喇叭, 太, 差劲, ,, 有点, 小卡, ,, 界面, 不是, 很, 友好, ,, 与,...[喇叭, 太, 差劲, 有点, 小卡, 界面, 不是, 很, 友好, 泰捷, 盒子, 差太远...01748好,送货速度快,服务好。.3333333正面20[好, ,, 送货, 速度, 快, ,, 服务, 好, 。, ., 3333333][好, 送货, 速度, 快, 服务, 好, 3333333]1
4. Word2vec处理
Word2vec是一个用来产生词向量的模型。是一个将单词转换成向量形式的工具。 通过转换,可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度。
from gensim.models.word2vec import Word2Vec
x = df["去除停用词后的数据"]# 训练 Word2Vec 浅层神经网络模型
w2v = Word2Vec(vector_size=300,#是指特征向量的维度,默认为100。
min_count=10)#可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5。
w2v.build_vocab(x)
w2v.train(x,
total_examples=w2v.corpus_count,
epochs=20)# 保存 Word2Vec 模型及词向量
w2v.save('w2v_model.pkl')# 将文本转化为向量defaverage_vec(text):
vec = np.zeros(300).reshape((1,300))for word in text:try:
vec += w2v.wv[word].reshape((1,300))except KeyError:continuereturn vec
# 将词向量保存为 Ndarray
x_vec = np.concatenate([average_vec(z)for z in x])
y = df['y']
5. 划分训练集与测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(x_vec,y,test_size=0.2)
from keras.models import Sequential
from keras.layers import Dense,LSTM,Bidirectional,Embedding
import tensorflow as tf
#定义模型
model = Sequential()
model.add(Embedding(100000,100))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
METRICS =[
tf.keras.metrics.TruePositives(name='tp'),
tf.keras.metrics.FalsePositives(name='fp'),
tf.keras.metrics.TrueNegatives(name='tn'),
tf.keras.metrics.FalseNegatives(name='fn'),
tf.keras.metrics.BinaryAccuracy(name='accuracy'),# 注意需要根据loss改变
tf.keras.metrics.Precision(name='precision'),
tf.keras.metrics.Recall(name='recall'),
tf.keras.metrics.AUC(name='auc'),
tf.keras.metrics.AUC(name='prc', curve='PR'),# precision-recall curve]
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=METRICS)
model.summary()
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 100) 10000000
_________________________________________________________________
lstm (LSTM) (None, 100) 80400
_________________________________________________________________
dense (Dense) (None, 1) 101
=================================================================
Total params: 10,080,501
Trainable params: 10,080,501
Non-trainable params: 0
_________________________________________________________________
epochs =30
batch_size =64
history = model.fit(X_train,
y_train,
epochs=epochs,
batch_size=batch_size,
validation_split=0.2)
Epoch 1/30
43/43 [==============================] - 40s 879ms/step - loss: 0.6343 - tp: 691.0000 - fp: 397.0000 - tn: 1132.0000 - fn: 520.0000 - accuracy: 0.6653 - precision: 0.6351 - recall: 0.5706 - auc: 0.6972 - prc: 0.6335 - val_loss: 0.5641 - val_tp: 194.0000 - val_fp: 76.0000 - val_tn: 304.0000 - val_fn: 112.0000 - val_accuracy: 0.7259 - val_precision: 0.7185 - val_recall: 0.6340 - val_auc: 0.7814 - val_prc: 0.7354
......
Epoch 29/30
43/43 [==============================] - 37s 869ms/step - loss: 0.4196 - tp: 985.0000 - fp: 279.0000 - tn: 1250.0000 - fn: 226.0000 - accuracy: 0.8157 - precision: 0.7793 - recall: 0.8134 - auc: 0.8859 - prc: 0.8316 - val_loss: 0.4754 - val_tp: 244.0000 - val_fp: 74.0000 - val_tn: 306.0000 - val_fn: 62.0000 - val_accuracy: 0.8017 - val_precision: 0.7673 - val_recall: 0.7974 - val_auc: 0.8592 - val_prc: 0.8097
Epoch 30/30
43/43 [==============================] - 37s 855ms/step - loss: 0.4189 - tp: 992.0000 - fp: 301.0000 - tn: 1228.0000 - fn: 219.0000 - accuracy: 0.8102 - precision: 0.7672 - recall: 0.8192 - auc: 0.8852 - prc: 0.8336 - val_loss: 0.4716 - val_tp: 247.0000 - val_fp: 73.0000 - val_tn: 307.0000 - val_fn: 59.0000 - val_accuracy: 0.8076 - val_precision: 0.7719 - val_recall: 0.8072 - val_auc: 0.8589 - val_prc: 0.8040
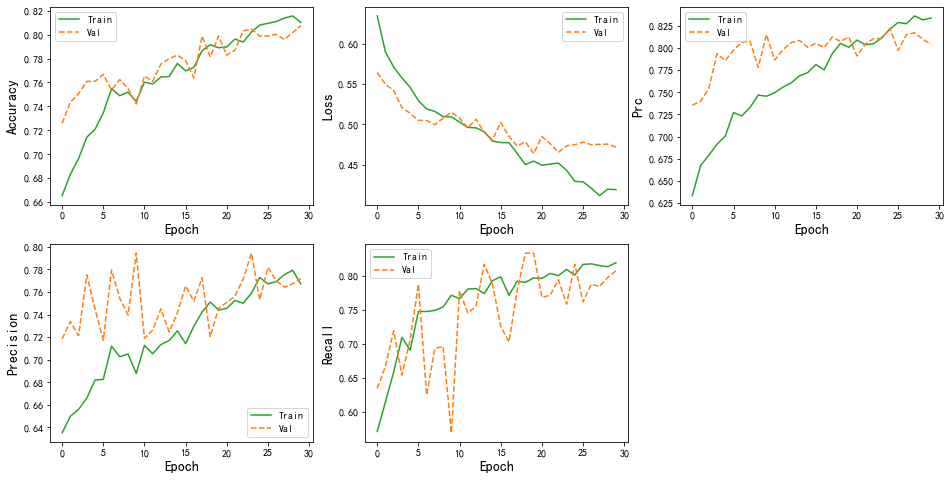
三、结果分析
import matplotlib as mpl
mpl.rcParams['figure.figsize']=(16,8)
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']defplot_metrics(history):
metrics =['accuracy','loss','prc','precision','recall']for n, metric inenumerate(metrics):
name = metric.replace("_"," ").capitalize()
plt.subplot(2,3,n+1)
plt.plot(history.epoch, history.history[metric], color=colors[2], label='Train')
plt.plot(history.epoch, history.history['val_'+metric],color=colors[1], linestyle="--", label='Val')
plt.xlabel('Epoch',fontsize=14)
plt.ylabel(name,fontsize=14)
plt.legend()
plot_metrics(history)
四、情感预测
# 读取 Word2Vec 并对新输入进行词向量计算defaverage_vec(words):# 读取 Word2Vec 模型
w2v = Word2Vec.load('w2v_model.pkl')
vec = np.zeros(300).reshape((1,300))for word in words:try:
vec += w2v.wv[word].reshape((1,300))except KeyError:continuereturn vec
# 对电影评论进行情感判断defmodel_predict(string):# 对评论分词
words = jieba.lcut(str(string))
words_vec = average_vec(words)# 读取支持向量机模型# model = joblib.load('svm_model.pkl')
result = np.argmax(model.predict(words_vec))# 实时返回积极或消极结果ifint(result)==1:# print(string, '[积极]')return"积极"else:# print(string, '[消极]')return"消极"
comment_sentiment =[]# 用10条数据做测试for index, row in df.iloc[:10].iterrows():print(row["evaluation"],end=" | ")
result = model_predict(row["去除停用词后的数据"])
comment_sentiment.append(result)print(result)#将情绪结果与原数据合并为新数据
merged = pd.concat([df, pd.Series(comment_sentiment, name='用户情绪')], axis=1)# 储存文件
pd.DataFrame.to_csv(merged,'comment_sentiment.csv',encoding="utf-8-sig")print('done.')
电视不错,不过今年的价格比去年贵了…… | 消极
电视很清晰大品牌值得信赖 | 消极
电视不错,没有坏点,漏光也基本看不出来,看了下电视剧,有点拖影,网上换个接口就好了,暂时没试。京东的预约客服真的要给差评,没经过我同意擅自把送货时间改到星期五,害送货大哥白跑趟。这里要给送货大哥好评,30几度的天气,大中午把电视扛到5楼 | 消极
喇叭太差劲,有点小卡,界面不是很友好,与泰捷盒子差太远了,但播放效果色彩不错,漏光较多 | 消极
好,送货速度快,服务好。.3333333 | 消极
买的第一台微鲸电视 感觉很不错 系统很流畅 清晰度也可以 就是个人感觉遥控的时候会有短暂的延迟 外观各方面还是感觉挺好的 这个价位性价比还可以 | 消极
6.18买的,活动力度大,画面感有待提高,目前没有质量问题,待观察 | 消极
挺好的,看久了下面底部很热,售后安装220元,被兜售一个HIDMI高清线99元,还有58元的有线电视线,一共花了快400块钱,有点被售后忽悠了,后来网上一看两根线最多40快!线上给你优惠,线下想法搞你! | 消极
挺好的 就是开发票太慢了 催了好久到现在还没到呢 | 消极
图电视剧的尺寸大性价比较高,最主要的就是搞活动的时候价格也不是太高啦 | 消极
done.
版权归原作者 K同学啊 所有, 如有侵权,请联系我们删除。