
本文是学习StarRocks的读书笔记,让你快速理解下一代高性能分析数据仓库的架构、数据存储及表设计。
1. 架构
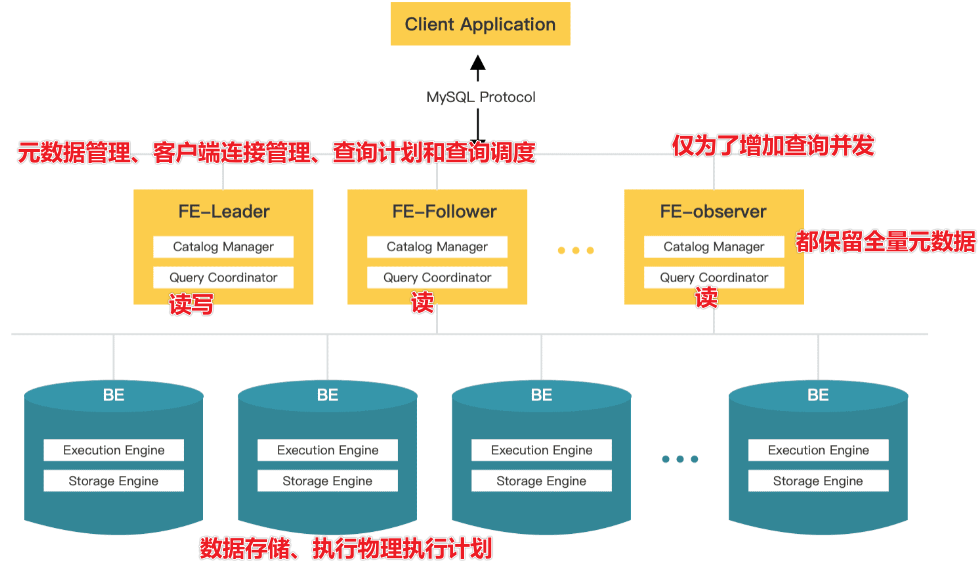
1.1. 整体架构
StarRocks的架构相对简单。
- 整个系统只包含两种类型的组件,前端(FE)和后端(BE),StarRocks不依赖任何外部组件,简化了部署和维护。
- FE和BE可以在不停机的情况下横向扩展。
- StarRocks具有元数据和服务数据的复制机制,这增加了数据的可靠性,并有效地防止单点故障(SPOFs)。
- 与MySQL协议兼容,并支持标准SQL。用户可以轻松地从MySQL客户端连接到StarRocks
1.2. 数据管理
2. 表设计
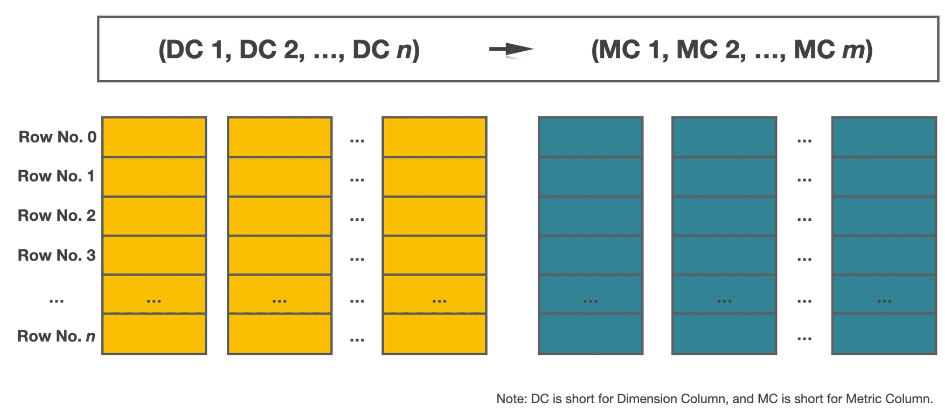
2.1. 列存储
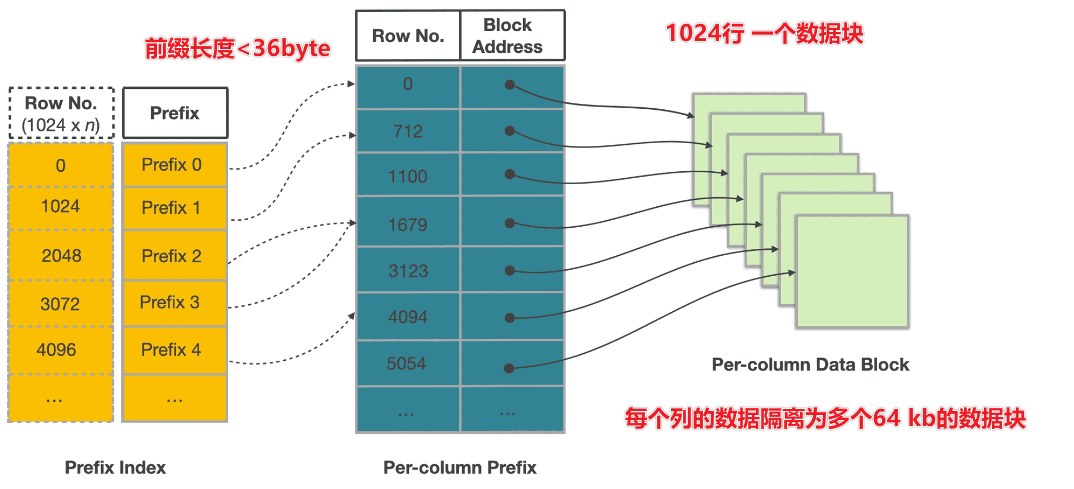
2.2.索引
2.3. 加速策略
- Pre-aggregation
- Partitioning and bucketing
- Materialized view: 物化视图的数据以与表数据相同的方式组织和存储。但是物化视图可以有自己的前缀索引。在为物化视图创建前缀索引时,可以指定适当的聚合粒度、列计数和维列顺序,以确保经常使用的查询条件能够命中物化视图前缀索引表中的预期条目。
- Per-column index - A Bloom filter : Bloom过滤器用于确定数据块是否包含要查询的值。- A zone map: 区域映射用于定位指定范围内的值。- A bitmap index: 位图索引用于查找ENUM数据类型列中满足指定查询条件的行。
3. Data models
StarRocks提供四种数据模型: Duplicate Key, Aggregate Key, Unique Key, and Primary Key
3.1. Duplicate Key model
适用场景:
- 分析原始数据,如原始日志和原始操作记录。
- 可以使用多种方法查询数据,不受预聚合方法的限制。
- 加载日志数据或时序数据。新数据以追加模式写入,现有数据不更新。
注意:
- 默认情况下,如果没有指定排序键列,StarRocks将使用前三列作为排序键【sort key】列
- 可以在表创建时创建索引,如BITMAP索引和Bloomfilter索引。
- 如果加载了两条相同的记录,将它们保留为两条记录,而不是一条
- 只能向表中追加数据。不能修改表中的现有数据。
CREATETABLEIFNOTEXISTS detail (
event_time DATETIMENOTNULLCOMMENT"datetime of event",
event_type INTNOTNULLCOMMENT"type of event",
user_id INTCOMMENT"id of user",
device_code INTCOMMENT"device code",
channel INTCOMMENT"")DUPLICATEKEY(event_time, event_type)DISTRIBUTEDBYHASH(user_id) BUCKETS 8;
3.2. Aggregate Key model
此模型有助于减少查询需要处理的数据量,从而加快查询速度。
适用场景:数据统计和分析场景
使用时有如下特点:
- 大多数查询是聚合查询,例如SUM、COUNT和MAX。
- 不需要检索原始的详细数据。
- 历史数据不经常更新。只追加新数据。
聚合时机:
- ingestion 阶段: 当数据批量加载到表中时,每个批量包含一个数据版本。生成数据版本后,StarRocks将在数据版本中具有相同排序键的数据进行聚合。
- compaction 阶段:将数据摄取时生成的多个数据版本的文件定期压缩成一个大文件时,StarRocks会在大文件中聚合具有相同排序键的数据。
- query 阶段:在返回查询结果之前聚合所有数据版本中具有相同排序键的数据。
注意:
- 如果AGGREGATE KEY关键字不包括所有维度列,则无法创建表。
- 如果没有使用AGGREGATE key关键字显式地定义排序键列,将选择除度量列之外的所有列作为排序键列
- 在运行查询时,排序键列在多个数据版本聚合之前被过滤,而度量列在多个数据版本聚合之后被过滤。
- 创建表时,不能在表的度量列上创建BITMAP索引或Bloom Filter索引
- 将数据加载到使用聚合键模型的表中时,只能更新表的所有列
CREATETABLEIFNOTEXISTS example_db.aggregate_tbl (
site_id LARGEINT NOTNULLCOMMENT"id of site",dateDATENOTNULLCOMMENT"time of event",
city_code VARCHAR(20)COMMENT"city_code of user",
pv BIGINT SUM DEFAULT"0"COMMENT"total page views")
AGGREGATE KEY(site_id,date, city_code)DISTRIBUTEDBYHASH(site_id) BUCKETS 8
PROPERTIES ("replication_num"="1");
3.3. Unique Key
适用场景:
- 需要频繁实时更新数据的业务场景,如在电子商务场景中,每天可以下数亿个订单,订单状态经常变化
注意:
- 主键必须创建在执行唯一约束且不能更改名称的列上 - 在运行查询时,主键列在多个数据版本聚合之前被过滤,而度量列在多个数据版本聚合之后被过滤- 在聚合过程中,StarRocks比较所有主键列。这很耗时,而且可能会降低查询性能。因此,不要定义大量的主键列
- 创建表时,不能在表的指标列上创建BITMAP索引或Bloom Filter索引。
- 不支持实体化视图。
- 将数据加载到使用唯一键模型的表中时,只能更新表的所有列
CREATETABLEIFNOTEXISTS orders (
create_time DATENOTNULLCOMMENT"create time of an order",
order_id BIGINTNOTNULLCOMMENT"id of an order",
order_state INTCOMMENT"state of an order",
total_price BIGINTCOMMENT"price of an order")UNIQUEKEY(create_time, order_id)DISTRIBUTEDBYHASH(order_id) BUCKETS 8;
3.4. Primary Key
基于StarRocks提供的一个新的存储引擎设计的
与Unique Key模型不同,Primary Key模型在查询期间不需要聚合操作,并支持谓词和索引的下推。因此,Primary Key模型可以提供较高的查询性能,尽管实时和频繁的数据更新。
Duplicate Key模型采用MoR策略。MoR简化了数据写入,但需要在线聚合多个数据版本。此外,Merge操作符不支持下推谓词和索引。结果,查询性能下降。
Primary Key模型采用删除+插入策略,确保每条记录都有唯一的主键。这样,主键模型就不需要合并操作。详情如下:
- 对记录进行更新操作时,它通过搜索主键索引来定位该记录,将该记录标记为已删除,并插入一条新记录。换句话说,StarRocks将更新操作转换为删除操作加上插入操作。
- 对记录进行删除操作时,它通过搜索主键索引来定位记录,并将记录标记为已删除
适用场景:
- 数据需要经常实时更新 - 实时流数据从交易处理系统到StarRocks,这简化了数据同步,并提供比使用唯一键模型的MoR (Merge on Read)表高3到10倍的查询性能- 通过对单个列执行更新操作来连接多个流:这些场景中的上游数据可能来自各种应用程序,如购物app、物流app和银行app,或者来自机器学习系统。主键模型非常适合这些场景,因为它支持对单个列的更新。每个应用程序或系统只能更新在自己的服务范围内保存数据的列
- 主键占用的内存【memory occupied by the primary key 】是可控的 - 当将数据加载到表中时,StarRocks将主键索引加载到内存中。因此Primary Key模型需要比其他三个数据模型更大的内存容量。StarRocks将组成主键的字段的总长度限制为编码后的127字节- 表包含快速变化的数据和缓慢变化的数据。快速变化的数据经常在最近几天更新,而缓慢变化的数据很少更新,如订单表,按天分区,在运行数据加载作业时,主键索引不会加载到内存中,只有最近更新的订单的索引项才会加载到内存中。- 表是一个由数百或数千列组成的平面表。主键只包含表数据的一小部分,并且只消耗少量内存。如user status or profile table,表的列太多,但只有几千万到几亿条
注意:
- 必须在强制执行唯一约束的列上创建主键,并且不能更改主键列的名称。
- 主键列可以是以下任何数据类型:BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、LARGEINT、STRING、VARCHAR、DATE和DATETIME。但是,主键列不能定义为NULL。
- 分区列和桶列必须参与主键。
- the memory occupied by the primary key index 的计算公式: (主键长度+9) x 记录数量 x 副本数 x 1.5 = 占用内存大小 - 9是每行不可变的开销,1.5是每个哈希表的平均额外开销
enable_persistent_index:主键索引可以持久化到磁盘并存储在内存中,以避免占用太多内存。- 从2.3.0版本开始, indicator column现在支持BITMAP、HLL数据类型。
- 创建表时,不能在表的 metric columns 上创建BITMAP索引或Bloom Filter索引。
- 从2.4.0版本开始,可以基于主键表创建异步物化视图
createtable orders (
dt dateNOTNULL,
order_id bigintNOTNULL,
user_id intNOTNULL,
merchant_id intNOTNULL,
good_id intNOTNULL,
good_name string NOTNULL,
price intNOTNULL,
cnt intNOTNULL,
revenue intNOTNULL,
state tinyintNOTNULL)PRIMARYKEY(dt, order_id)PARTITIONBY RANGE(`dt`)(PARTITION p20210820 VALUES[('2021-08-20'),('2021-08-21')),PARTITION p20210821 VALUES[('2021-08-21'),('2021-08-22')),...PARTITION p20210929 VALUES[('2021-09-29'),('2021-09-30')),PARTITION p20210930 VALUES[('2021-09-30'),('2021-10-01')))DISTRIBUTEDBYHASH(order_id) BUCKETS 4
PROPERTIES("replication_num"="3","enable_persistent_index"="true");createtable users (
user_id bigintNOTNULL,
name string NOTNULL,
email string NULL,
address string NULL,
age tinyintNULL,
sex tinyintNULL,
last_active datetime,
property0 tinyintNOTNULL,
property1 tinyintNOTNULL,
property2 tinyintNOTNULL,
property3 tinyintNOTNULL,....)PRIMARYKEY(user_id)DISTRIBUTEDBYHASH(user_id) BUCKETS 4
PROPERTIES("replication_num"="3","enable_persistent_index"="true");
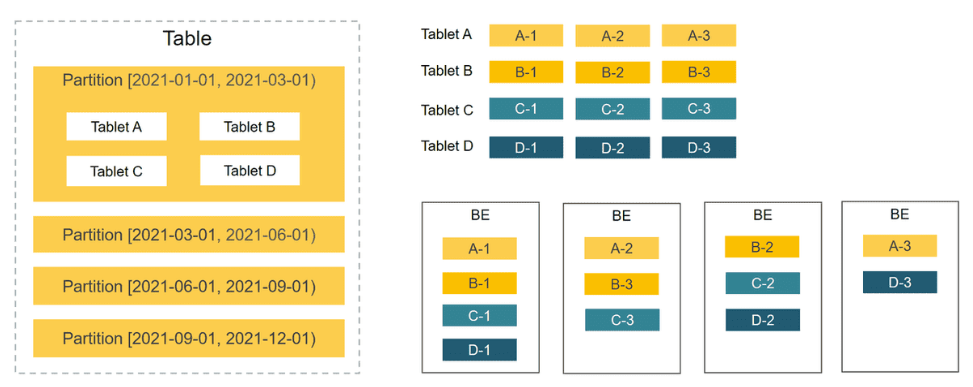
4. 数据分布 Data distribution
4.1. 基本概念
- 分区: - 在分区时,可以设置分区的存储策略,包括副本数量、热数据或冷数据的存储策略、存储介质等。- StarRocks允许在集群中使用多个存储介质。例如,将最新数据保存在SSD硬盘上,可以提高查询性能;将历史数据保存在SATA硬盘上,可以降低存储成本。
- 分桶: - 分桶是将一个分区划分为多个更易于管理的部分即tablet,tablet是使用和分配的最小存储单元- bucket列中具有相同哈希值的数据被分布到同一tablet中- StarRocks为每个tablet创建多个副本(默认为三个),以防止数据丢失。这些副本由单独的本地存储引擎管理。创建表时必须指定bucket列。
4.2. 分区方法
- Round-robin: distributes data across different nodes in a cyclic.
- Range: distributes data across different nodes based on the value range of partitioning columns.
- List: distributes data across different nodes based on the discrete values of partitioning columns, such as age.
- Hash: distributes data across different nodes based on a hash algorithm. 为了实现更灵活的数据分布,可以根据业务需求组合以上四种分区方法,例如hash-hash, range-hash, and hash-list。StarRocks提供了以下两种分区方法:
# 整个表只有一个分区,并按site_id分桶CREATETABLE site_access(
site_id INTDEFAULT'10',
city_code SMALLINT,
user_name VARCHAR(32)DEFAULT'',
pv BIGINT SUM DEFAULT'0')
AGGREGATE KEY(site_id, city_code, user_name)DISTRIBUTEDBYHASH(site_id) BUCKETS 10;# 先按日期分区,再按site_id分桶CREATETABLE site_access(
event_day DATE,
site_id INTDEFAULT'10',
city_code VARCHAR(100),
user_name VARCHAR(32)DEFAULT'',
pv BIGINT SUM DEFAULT'0')
AGGREGATE KEY(event_day, site_id, city_code, user_name)PARTITIONBY RANGE(event_day)(PARTITION p1 VALUES LESS THAN ("2020-01-31"),PARTITION p2 VALUES LESS THAN ("2020-02-29"),PARTITION p3 VALUES LESS THAN ("2020-03-31"))DISTRIBUTEDBYHASH(site_id) BUCKETS 10;
4.3. 分区、分桶列的选择
- 分区列的选择 - 只有DATE、DATETIME或INT类型的列可以用作分区列,- 分区列要求:低基数、在查询中经常用作筛选器的列、每个分区的数据量必须小于100GB。
- 分桶列的选择 - 分桶列的要求:高基数列如ID、在查询中经常用作筛选器的列,列值不能更新- 分桶列最多为三个,不能太多- 分桶列在指定后不能被修改。- tablet反映了StarRocks中数据文件的组织方式。从StarRocks 2.5开始,创建表时不需要设置桶数,StarRocks会自动设置桶数。- 建议每个tablet包含大约10GB的原始数据- 要在tablet上启用并行扫描,请确保启用了
GLOBAL enable_tablet_internal_parallel。
CREATETABLE site_access(
event_day DATE,
site_id INTDEFAULT'10',
city_code VARCHAR(100),
user_name VARCHAR(32)DEFAULT'',
pv BIGINT SUM DEFAULT'0')
AGGREGATE KEY(event_day, site_id, city_code, user_name)PARTITIONBY RANGE(event_day)(PARTITION p1 VALUES LESS THAN ("2020-01-31"),PARTITION p2 VALUES LESS THAN ("2020-02-29"),PARTITION p3 VALUES LESS THAN ("2020-03-31"))DISTRIBUTEDBYHASH(site_id) BUCKETS 10;CREATETABLE site_access(
site_id INTDEFAULT'10',
city_code SMALLINT,
user_name VARCHAR(32)DEFAULT'',
pv BIGINT SUM DEFAULT'0')
AGGREGATE KEY(site_id, city_code, user_name)DISTRIBUTEDBYHASH(site_id,city_code);--do not need to set the number of buckets
管理分区
- 建表时指定分区
CREATETABLE site_access( datekey DATE, site_id INT, city_code SMALLINT, user_name VARCHAR(32), pv BIGINTDEFAULT'0')ENGINE=olapDUPLICATEKEY(datekey, site_id, city_code, user_name)PARTITIONBY RANGE (datekey)(START("2019-01-01")END("2021-01-01") EVERY (INTERVAL1YEAR),START("2021-01-01")END("2021-05-01") EVERY (INTERVAL1MONTH),START("2021-05-01")END("2021-05-04") EVERY (INTERVAL1DAY))DISTRIBUTEDBYHASH(site_id) BUCKETS 10PROPERTIES("replication_num"="1"); - 修改、删除、恢复、查看分区
ALTERTABLE site_accessADDPARTITION p4 VALUES LESS THAN ("2020-04-30")DISTRIBUTEDBYHASH(site_id) BUCKETS 20;ALTERTABLE site_access DROPPARTITION p1;RECOVER PARTITION p1 FROM site_access;SHOW PARTITIONS FROM site_access;
5. 数据压缩
StarRocks支持四种数据压缩算法:LZ4、Zstandard(或zstd)、zlib和Snappy。
这些数据压缩算法在压缩比和压缩/解压缩性能上存在差异。
压缩比:zlib > Zstandard > LZ4 > Snappy.
特别是LZ4和Zstandard具有良好的压缩比和解压性能
如果对更小的存储空间没有特定的要求,建议使用LZ4或Zstandard。
只能在创建表时为表指定数据压缩算法,不能在创建后更改。
CREATETABLE`data_compression`(`id`INT(11)NOTNULLCOMMENT"",`name`CHAR(200)NULLCOMMENT"")ENGINE=OLAP
UNIQUEKEY(`id`)COMMENT"OLAP"DISTRIBUTEDBYHASH(`id`) BUCKETS 7
PROPERTIES ("compression"="ZSTD");
本文转载自: https://blog.csdn.net/penriver/article/details/130037739
版权归原作者 enjoy编程 所有, 如有侵权,请联系我们删除。
版权归原作者 enjoy编程 所有, 如有侵权,请联系我们删除。