
SpringBoot使用本地缓存——Caffeine
缓存,想必大家都用过,将常用的数据存储在缓存上能在一定程度上提升数据存取的速度。这正是局部性原理的应用。之前用的缓存大多是分布式的,比如Redis。使用Redis作为缓存虽然是大多数系统的选择,但是需要另起服务,且会增加一定的耗时在数据传输上。对于一些小型应用,用Redis就有点大材小用了,此时便可以使用本地缓存。
本地缓存的技术选型:
- 使用 ConcurrentHashMap 作为缓存这个是最简单的缓存使用,但是没有一定的内存淘汰策略,用作缓存来使用,功能比较单一。需要开发人员进行定制化开发。
- Guava CacheGuava是Google团队开源的一款 Java 核心增强库,包含集合、并发原语、缓存、IO、反射等工具箱,性能和稳定性上都有保障,应用十分广泛,强烈推荐。其中 Guava Cache 支持很多特性,比如:支持最大容量限制、支持两种过期删除策略(插入时间和访问时间)、支持简单的统计功能、基于LRU算法实现
- 本文将要介绍的Caffeine缓存Caffeine是一个高性能的Java本地缓存库,设计用于提供快速响应时间和高并发处理能力。它具有类似于Guava缓存的简单易用的API,同时也提供了许多额外的功能和性能优化。Caffeine支持缓存大小限制、缓存过期策略、异步加载数据等特性,可以帮助开发人员在应用程序中有效地管理和优化缓存。Caffeine还提供了可自定义的缓存策略和监听器,以帮助开发人员根据实际需求定制缓存行为。
- 基于Ehcache实现本地缓存Ehcache是一个流行的Java开源缓存框架,用于在应用程序中管理缓存数据。它被广泛用于提高应用程序性能,减少数据库访问频率,和减少网络开销。同Caffeine和Guava Cache相比,Ehcache的功能更加丰富,扩展性更强。
Caffeine本地缓存
在项目开发中,为提升系统性能,减少 IO 开销,采用本地缓存是必不可少的。最常见的本地缓存是 Guava 和 Caffeine。Caffeine 是基于 Google Guava Cache 设计经验改进的结果,相较于 Guava 在性能和命中率上更具有效率,你可以认为其是 Guava Plus版本。
使用步骤
步骤 1: 添加依赖
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>3.1.5</version><!-- 确保使用最新版本 --></dependency><!-- Spring Boot Cache 的依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency>
步骤 2: 配置 Caffeine 缓存管理器
packagecom.supermap.ai.agent.config;importcom.github.benmanes.caffeine.cache.Caffeine;importlombok.extern.slf4j.Slf4j;importorg.springframework.cache.CacheManager;importorg.springframework.cache.caffeine.CaffeineCacheManager;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importjava.util.concurrent.TimeUnit;/**
* @Author: wangrongyi
* @Date: 2024/7/8 14:02
* @Description: 缓配配置类
*/@Configuration@Slf4jpublicclassCaffeineConfig{@BeanpublicCacheManagercacheManager(){CaffeineCacheManager cacheManager =newCaffeineCacheManager();//Caffeine配置Caffeine<Object,Object> caffeine =Caffeine.newBuilder()//最后一次写入后经过固定时间过期.expireAfterWrite(600,TimeUnit.SECONDS)//maximumSize=[long]: 缓存的最大条数.maximumSize(1000);
cacheManager.setCaffeine(caffeine);
log.info("缓存配置 CacheManager 初始化");return cacheManager;}@BeanpublicCache<String,Object>caffeineCache(){
log.info("缓存配置 Cache 初始化");returnCaffeine.newBuilder()// 设置最后一次写入或访问后经过固定时间过期.expireAfterWrite(600,TimeUnit.SECONDS)// 初始的缓存空间大小.initialCapacity(1000)// 缓存的最大条数.maximumSize(1000).build();}}
Caffeine配置参数说明:
initialCapacity=[integer]: 初始的缓存空间大小
maximumSize=[long]: 缓存的最大条数
maximumWeight=[long]: 缓存的最大权重
expireAfterAccess=[duration]: 最后一次写入或访问后经过固定时间过期
expireAfterWrite=[duration]: 最后一次写入后经过固定时间过期
refreshAfterWrite=[duration]: 创建缓存或者最近一次更新缓存后经过固定的时间间隔,刷新缓存
weakKeys: 打开key的弱引用
weakValues:打开value的弱引用
softValues:打开value的软引用
recordStats:开发统计功能 注意:
expireAfterWrite和expireAfterAccess同事存在时,以expireAfterWrite为准。
maximumSize和maximumWeight不可以同时使用
weakValues和softValues不可以同时使用
注意: CacheManager 是使用注解形式时需要注入的Bean,Cache是在代码中显示使用时需要注入的,可以注入多个Bean,用名字区分,达到使用不通的缓存配置的效果。比如对过期时间有不通的要求,那么就可以注入两个过期时间不同的 CacheManager ,Bean的名字要做区分,在使用 @Cacheable 调用缓存时,便可以显示指定不同的 cacheManager。
步骤 3: 使用缓存
有两种使用缓存的方式:注解使用、代码显示使用
- 注解使用
// 获取缓存@GetMapping("/getCache")@Cacheable(value ="cache", key ="'key'")publicStringgetCache()throwsInterruptedException{Thread.sleep(3000);return"getCache";}// 设置缓存@GetMapping("/setCache")@CachePut(value ="cache", key ="'key'")publicStringsetCache()throwsInterruptedException{Thread.sleep(3000);return"setCache";}// 删除缓存@GetMapping("/delCache")@CacheEvict(value ="cache", key ="'key'")publicStringdelCache()throwsInterruptedException{Thread.sleep(3000);return"delCache";}注解使用说明:- @EnableCaching开启缓存功能,一般放在启动类上。- @CacheConfig当我们需要缓存的地方越来越多,你可以使用@CacheConfig(cacheNames = {“cacheName”})注解在 class 之上来统一指定value的值,这时可省略value,如果你在你的方法依旧写上了value,那么依然以方法的value值为准。- @Cacheable根据方法对其返回结果进行缓存,下次请求时,如果缓存存在,则直接读取缓存数据返回;如果缓存不存在,则执行方法,并把返回的结果存入缓存中。一般用在查询方法上。属性/方法名解释value缓存名,必填,它指定了你的缓存存放在哪块命名空间cacheNames与 value 差不多,二选一即可key可选属性,可以使用 SpEL 标签自定义缓存的keykeyGeneratorkey的生成器。key/keyGenerator二选一使用cacheManager指定缓存管理器cacheResolver指定获取解析器condition条件符合则缓存unless条件符合则不缓存sync是否使用异步模式,默认为false- @CachePut使用该注解标志的方法,每次都会执行,并将结果存入指定的缓存中。其他方法可以直接从响应的缓存中读取缓存数据。一般用在新增方法上。属性/方法名解释value缓存名,必填,它指定了你的缓存存放在哪块命名空间cacheNames与 value 差不多,二选一即可key可选属性,可以使用 SpEL 标签自定义缓存的keykeyGeneratorkey的生成器。key/keyGenerator二选一使用cacheManager指定缓存管理器cacheResolver指定获取解析器condition条件符合则缓存unless条件符合则不缓存- @CacheEvict使用该注解标志的方法,会清空指定的缓存。一般用在更新或者删除方法上。属性/方法名解释value缓存名,必填,它指定了你的缓存存放在哪块命名空间cacheNames与 value 差不多,二选一即可key可选属性,可以使用 SpEL 标签自定义缓存的keykeyGeneratorkey的生成器。key/keyGenerator二选一使用cacheManager指定缓存管理器cacheResolver指定获取解析器condition条件符合则缓存allEntries是否清空所有缓存,默认为 false。如果指定为 true,则方法调用后将立即清空所有的缓存beforeInvocation是否在方法执行前就清空,默认为 false。如果指定为 true,则在方法执行前就会清空缓存- @Caching该注解可以实现同一个方法上同时使用多种注解。可从其源码看出: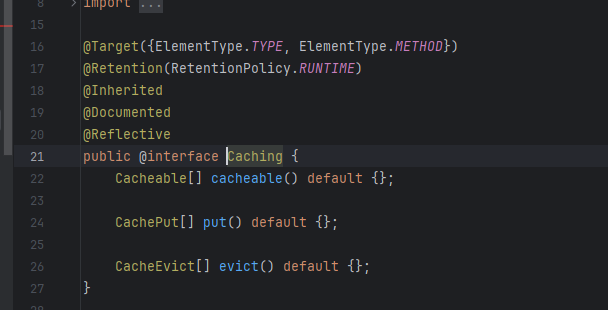
- 代码显示使用
@AutowiredprivateCache<String,Object> cache;@GetMapping("/getCacheInfo")publicvoidgetCacheInfo()throwsInterruptedException{String s =(String) cache.getIfPresent("key");if(s ==null){ cache.put("key","value");Thread.sleep(3000);} log.info("cache:{}", cache.getIfPresent("key"));}显示使用时需要注意处理并发读写,防止并发读写造成缓存不一致问题。
总结:使用Caffeine作为本地缓存能极大增加缓存数据的访问效率,提升读取性能。不过,本地缓存的使用受限于本地缓存的大小,所以面对缓存很大以及复杂的数据结构还是考虑用第三方的缓存服务,比如Redis。
关注不迷路。come on 
版权归原作者 老王不住隔壁、 所有, 如有侵权,请联系我们删除。