
- 线性回归模型属于经典的统计学模型,该模型的应用场景是根据已知的变量(自变量)来预测某个连续的数值变量(因变量),线性回归通常可以应用在股价预测、营收预测、广告效果预测、销售业绩预测当中。
一元线性回归:
基本概念:
- 一元线性回归是分析只有一个自变量(自变量x和因变量y)线性相关关系的方法。一个经济指标的数值往往受许多因素影响,若其中只有一个因素是主要的,起决定性作用,则可用一元线性回归进行预测分析。数据集可以表示成{(x1,y1),(x2,y2),…,(xn,yn)}。其中,xi表示自变量x的第i个值,yi表示因变量y的第i个值,n表示数据集的样本量。当模型构建好之后,就可以根据其他自变量x的值,预测因变量y的值,该模型的数学公式可以表示成:
 ### python中展示:
### python中展示:- 导入我们需要的包和相关库
#引入sklearn库,使用其中的线性回归模块from sklearn import datasets,linear_model#引入train_test_split来把我们的数据集分为训练集和测试集from sklearn.model_selection import train_test_splitimport numpy as npimport pandas as pdimport matplotlib.pyplot as plt# 创建数据集 比如我们现在有10行2列数据,第一列是身高,第二列是体重,通常做法:将原始数据切分时,将原始数据的80%作为训练数据来训练模型,另外20%作为测试数据,通过测试数据直接判断模型的效果,在模型进入真实环境前不断改进模型;
data = np.array([[152,51],[156,53],[160,54],[164,55],
[168,57],[172,60],[176,62],[180,65],
[184,69],[188,72]])
# X,y分别存放特征向量和标签,这里边使用reshape的目的是data[:,0]是一个一维的数组,但后边模型调用的时候要求是矩阵的形式
X,y = data[:,0].reshape(-1,1),data[:,1]
# 训练集和测试集区分开
# train_size=0.8的意思就是随机提取80%的数据作为训练数据
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.8)
# 实现线性回归算法模型
regr = linear_model.LinearRegression()
# 拟合数据,训练模型
regr.fit(X_train,y_train)
# score得到的返回结果是决定系数R平方值
regr.score(X_train,y_train)
- 决定系数R的平方值 = 1-u/v
- u = (y的实际值-y的预期值)的平方的求和
- v = (y的实际值-y的实际值的平均值)的平方的求和--输出结果R的平方值=0.963944147932503
font = {'family':"SimHei",'size':20}plt.rc('font',**font)##训练数据plt.scatter(X_train,y_train,color='r')##画拟合线plt.plot(X_train,regr.predict(X_train),color='b')plt.scatter(X_test,y_test,color='black')# 测试数据plt.xlabel('身高')plt.ylabel('体重')plt.show()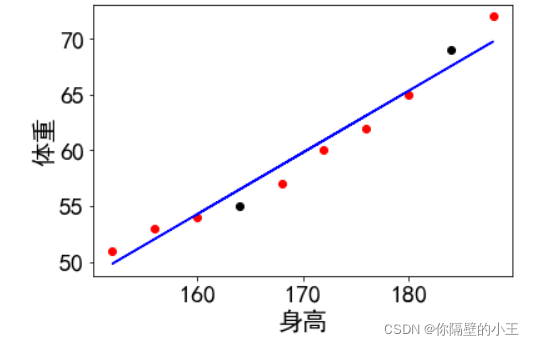 ** 下面让我们简单的做一个预测,加入身高是170的人,他的体重是多少那?**
** 下面让我们简单的做一个预测,加入身高是170的人,他的体重是多少那?**np.round(regr.predict([[170]]),1)``````**array([59.8]),可以看到170的人,经过我们的预测他的体重是59.8公斤。**
本文转载自: https://blog.csdn.net/weixin_43212535/article/details/122393250
版权归原作者 你隔壁的小王 所有, 如有侵权,请联系我们删除。
版权归原作者 你隔壁的小王 所有, 如有侵权,请联系我们删除。