
文章要点
🐚作者简介:苏凉(专注于网络爬虫,数据分析)
🐳博客主页:苏凉.py的博客
👑名言警句:海阔凭鱼跃,天高任鸟飞。
📰要是觉得博主文章写的不错的话,还望大家三连支持一下呀!!!
👉关注✨点赞👍收藏📂

🍺前言
上篇文章带着大家一起学习了在pandas中如何对excel表格的多表联合,数据可视化以及数据校验,还有一些基本的操作,接下来我们一起再深入的去了解pandas在excel中其他的一些有趣的操作吧!!
往期回顾:
1.python数据分析基础006 -利用pandas带你玩转excel表格(上篇)
2.python数据分析基础007 -利用pandas带你玩转excel表格(中上篇)
3.python数据分析基础008 -利用pandas带你玩转excel表格(中下篇)
💦(一)利用pandas对数据求和,算平均数
在excel中我们最常见的就是对整个表的数据进行求和以及计算平均数。接下来我们一起看看在excel和pandas是如何进行操作的吧!
实例:对下表中数据,计算出学生的总分,平均分,以及各个测试的平均分。
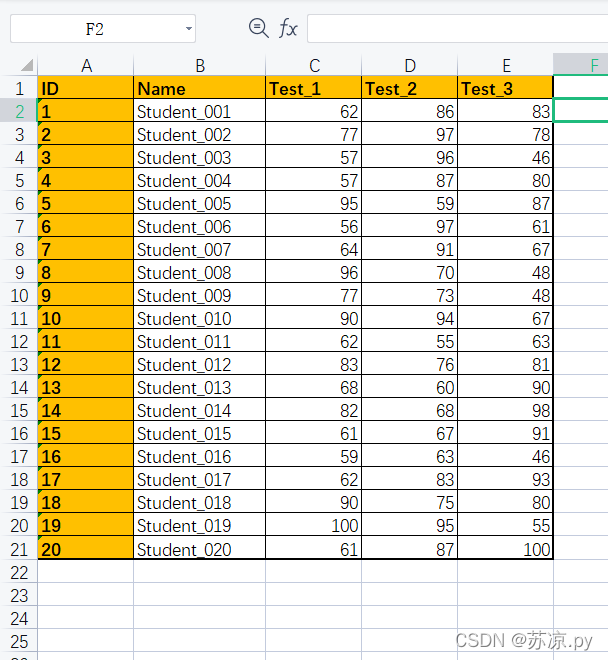
💨1. 在excel表格中实现
在excel中实现求总数和平均数需要用到,SUM(求总数),AVERAGE(求平均数)两个函数
=SUM(C2:E2) #求单个学生总分
=AVERAGE(C2:E2 )#求单个学生平均分
=AVERAGE(C2:C21 )#求单科平均分
结果: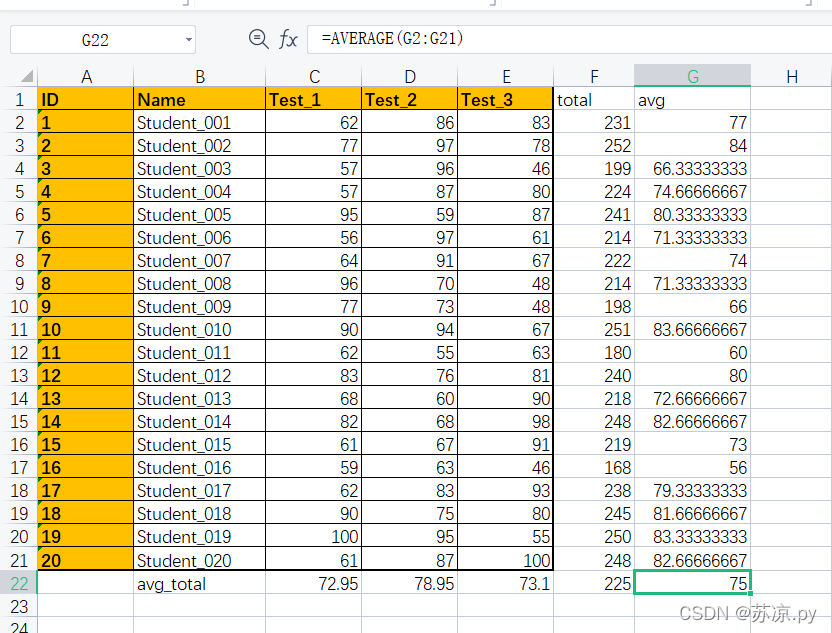
需要完成以上结果在pandas中又如何实现呢?
💨2.在pandas中进行实现
注意: 在pandas中求和函数和excel中的一样为sum(),而求平均数的函数则为mean()
import pandas as pd
test = pd.read_excel('./excel/test008.xlsx',index_col="ID")
df = pd.DataFrame(test)# 求总和sum= df[['Test_1','Test_2','Test_3']].sum(axis=1)# 求平均值
avg = df[['Test_1','Test_2','Test_3']].mean(axis=1)
df['total']=sum
df['avg']= avg
# 求总计的平均值
T_avg = df[['Test_1','Test_2','Test_3','total','avg']].mean()
T_avg['Name']='avg_total'
df =df.append(T_avg,ignore_index=True)print(df)
在上篇文章内说到对dataframe中的值进行操作时,用axis=0表示对列进行操作,而axis=1表示对行进行操作
结果:
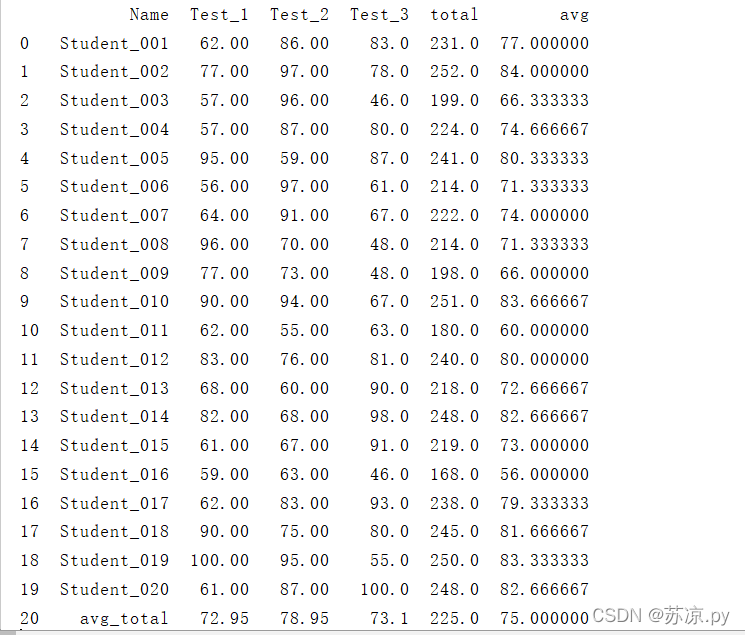
这样就实现了上述结果。
💦(二)消除重复数据
在excel中可能会因为种种原因出现重复的数据,此时是影响我们对数据进行分析的,这就需要我们把重复的数据进行删除。那再excel和pandas中又是如何操作的呢?
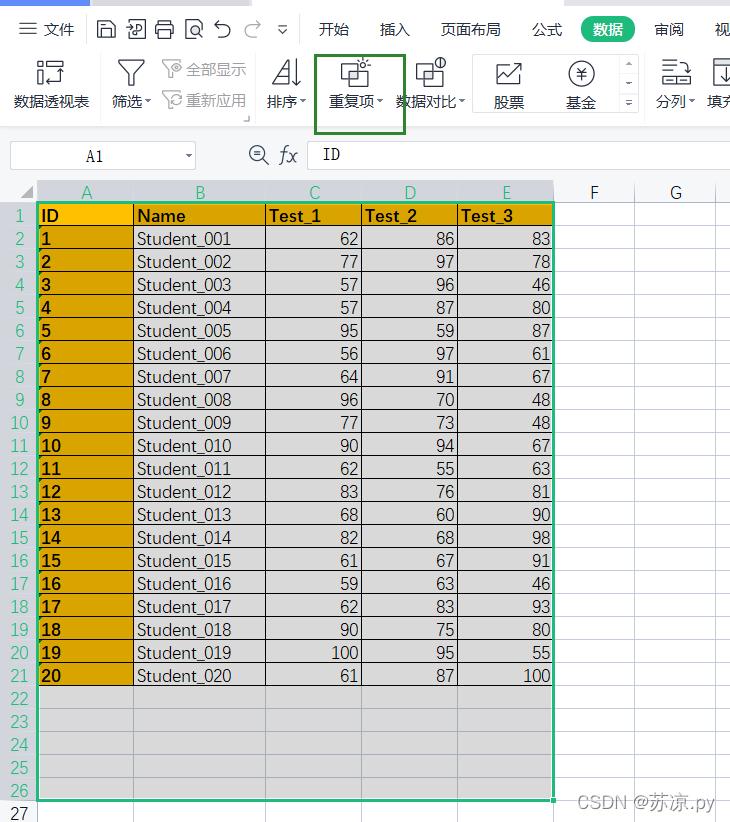
实例:将以下excel中重复的数据删除。
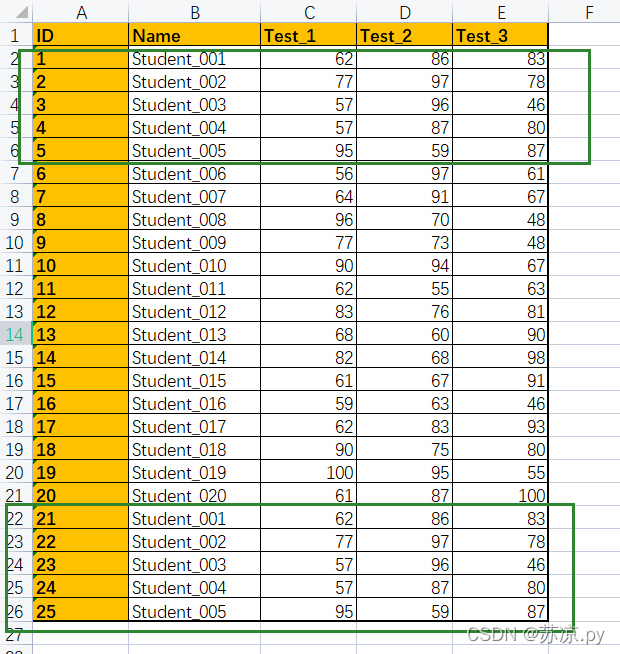
💨1.在excel中进行实现
在数据栏下点开重复项-删除重复项,选择列名即可。
需要实现以上结果,在pandas中要如何进行操作呢?pandas还有什么强大的功能呢,让我们一起来看看吧!
💨2.在pandas中实现
在pandas中调用drop_duplicates方法进行删除,在此可以用keep参数进行说明保留前者(first)还是后者(last)(重复的数据)
import pandas as pd
test = pd.read_excel('./excel/test009.xlsx')
df = pd.DataFrame(test)# 消除重复数据
df.drop_duplicates(subset='Name',inplace=True,keep='last')print(df)
结果: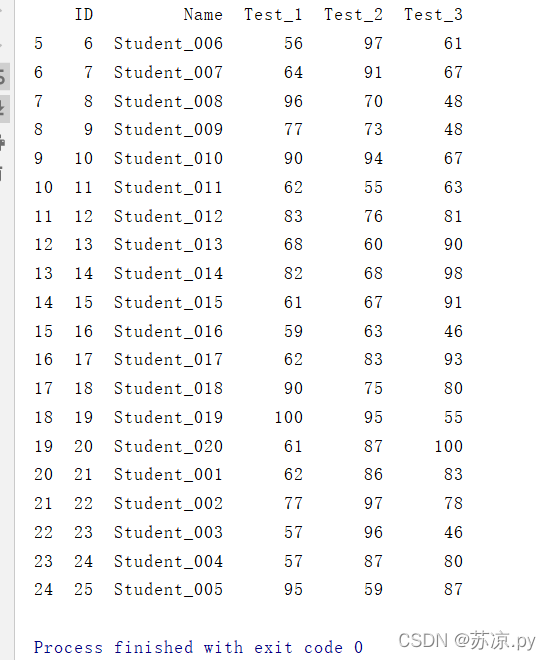
利用keep参数我们将前面重复的数据删除而保留了后面的数据,这就是pandas对比excel的一强大之处。而在此方面,pandas远不止于此,pandas还可以将重复的数据筛选出来。
💫2.1 利用pandas将重复的数据筛选出来
在pandas中即可以将重复的数据删除,也可以将重复的数据找出来。下面我们一起看看如何操作吧。
import pandas as pd
test = pd.read_excel('./excel/test009.xlsx')
df = pd.DataFrame(test)
re = df.duplicated(subset='Name')# 找出重复项
re = re[re ==True]# re.index 找出重复数据的索引print(df.iloc[re.index])
结果: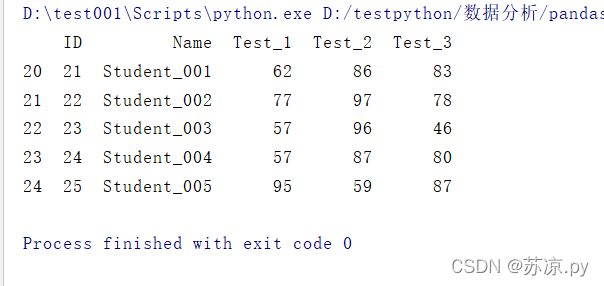
对上面两点,足以说明pandas在对excel数据进行操作时还是比excel更胜一筹的。
💦(三)数据转置
在excel表中,有些数据需要转置看起来才更明了,更直观。那么在excel和pandas中要如何操作呢?
实例:将下列数据进行转置
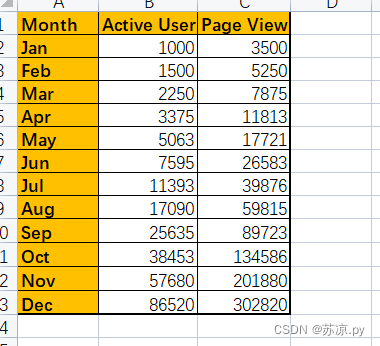
💨1.在excel中进行实现
这个操作还是比较简单的,选中表格复制,粘贴后选择转置即可。
结果:
那在pandas中又如何操作呢?是否更快捷更简单呢?
💨2.在pandas中进行操作
在pandas中转置数据也是很简单的,只需要加入transpose方法即可。
注意:在转置前还需设置索引,否则转置时会将索引一起转置。
import pandas as pd
test = pd.read_excel('./excel/test010.xlsx',index_col="Month")
df = pd.DataFrame(test)# 将数据转置
table = df.transpose()# 显示所有数据,若不设置则中间数据不显示
pd.options.display.max_columns =100print(table)
结果: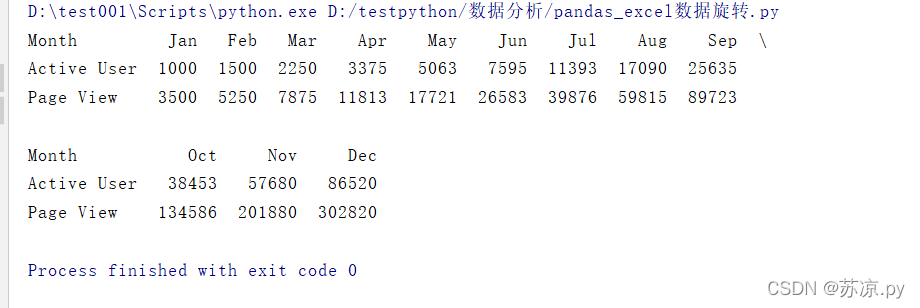
这样就实现了上述结果,pandas相对来说处理数据更方便快捷!!
🍻结语
今天的内容就到这里啦,希望看到此文的小伙伴能有所收获,另外pandas在excel中还有很多操作需要探索,关注我,咱们下期再见!!

版权归原作者 苏凉.py 所有, 如有侵权,请联系我们删除。