
一、简介
2019年何凯明提出Focal Loss时为了验证Focal Loss的可行性,顺便(没错,就是顺便)提出了RetinaNet。RetinaFace是在RetinaNet基础上引申出来的人脸检测框架,所以大致结构和RetinaNet非常像。
主要改进:
1.MobileNet-0.25作为Backbone,当然也有ResNet版本。
2.Head中增加关键点检测。
3.Multi-task Loss
论文地址:https://arxiv.org/pdf/1905.00641.pdf
官方代码:https://github.com/deepinsight/insightface/tree/master/RetinaFace
官方代码是mxnet的,我将提供一个Pytorch版:oaifaye/retinafaceoaifaye/retinafaceoaifaye/retinaface
二、模型结构
先看模型整体结构,这里我们使用batch=1,size=640x640作为输入,图中每个块下面灰色的部分是输出。
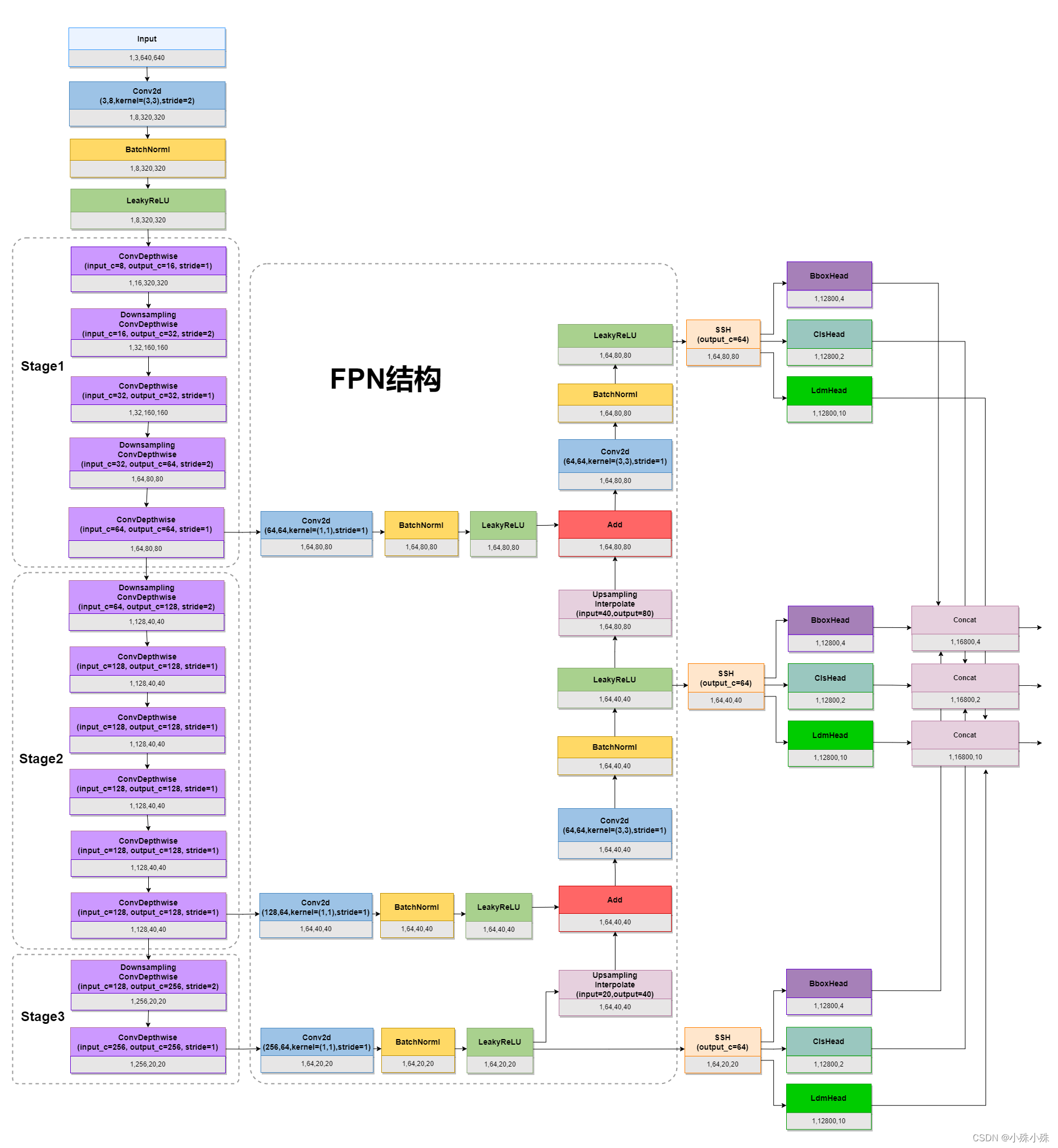
图1
1.MobileNet-0.25
图1中的ConvDepthwise指MobileNet中的Depthwise Separable Convolution(深度可分离卷积)。常规卷积在提取图像特征图内特征相关性的同时也提取特征图通道间特征相关性,这样参数多而且难以解释。ConvDepthwise将这两项工作分开来做,减少了参数而且提高了可解释性。ConvDepthwise结构如下:
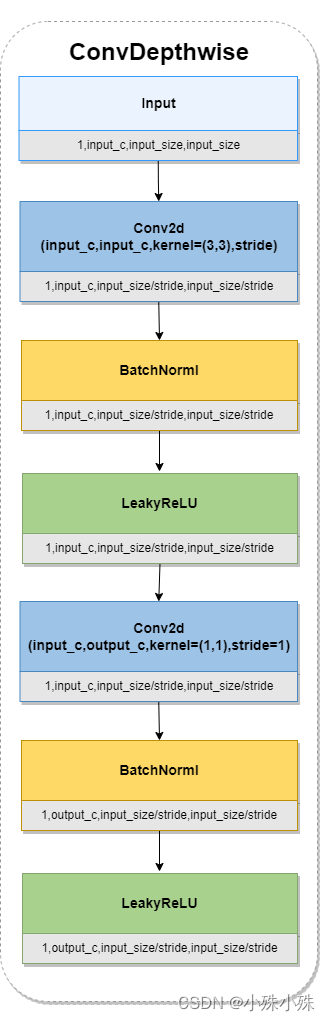
图2
先做3x3的卷积,并且groups设置成输入通道数,这组卷积核只负责提取每个特征图的特征,同时计算量大大减少。然后做1x1的卷积用于改变通道数,这组1x1的卷积核只提取通道间的特征相关性,同时参数大大减少。这么两组操作下来计算量和参数量都降下来了,而且可解释性也有所提升。
代码实现:
def conv_dw(inp, oup, stride = 1, leaky=0.1):
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.LeakyReLU(negative_slope= leaky,inplace=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.LeakyReLU(negative_slope= leaky,inplace=True),
)
2.FPN结构
FPN(特征金字塔),很成熟的结构了,多用于目标检测,因为目标有大有小,所以不同的特征层做融合有助于检测不同尺度的目标。
这里FPN取了三个关键特征层,然后将通道数都处理成64,这样三个关键特征层由浅到深分别是1,64,80,80、1,64,40,40、1,64,20,20。深层的关键特征层经过2x的Upsampling与浅层进行融合,最后三个融合后的分支分别输出到SSH结构。
3.SSH结构
SSH(Single Stage Headless)模块可以进一步增加感受野,进一步加强特征提取,是个锦上添花的模块。
SSH结构如下:

图3
可以看到,SSH利用的也是多尺度特征融合的思想,融合了三路不同深度的特征,最后cancat到一起,输出和输入尺寸不变。
代码实现:
class SSH(nn.Module):
def __init__(self, in_channel, out_channel):
super(SSH, self).__init__()
assert out_channel % 4 == 0
leaky = 0
if (out_channel <= 64):
leaky = 0.1
# 3x3卷积
self.conv3X3 = conv_bn_no_relu(in_channel, out_channel//2, stride=1)
# 利用两个3x3卷积替代5x5卷积
self.conv5X5_1 = conv_bn(in_channel, out_channel//4, stride=1, leaky = leaky)
self.conv5X5_2 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
# 利用三个3x3卷积替代7x7卷积
self.conv7X7_2 = conv_bn(out_channel//4, out_channel//4, stride=1, leaky = leaky)
self.conv7x7_3 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
def forward(self, inputs):
conv3X3 = self.conv3X3(inputs)
conv5X5_1 = self.conv5X5_1(inputs)
conv5X5 = self.conv5X5_2(conv5X5_1)
conv7X7_2 = self.conv7X7_2(conv5X5_1)
conv7X7 = self.conv7x7_3(conv7X7_2)
# 所有结果堆叠起来
out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1)
out = F.relu(out)
return out
4.Head结构
Head分三种:
BboxHead:框的回归预测结果用于对先验框进行调整获得预测框,即解码前的bounding box的中心点偏移量和宽高。
ClsHead:分类预测结果用于判断先验框内部是否包含脸。
LdmHead:解码前的五官关键点坐标。
每个单元的使用两个1:1比例的Anchor(anchor_num=2),三个Head结构如下图。
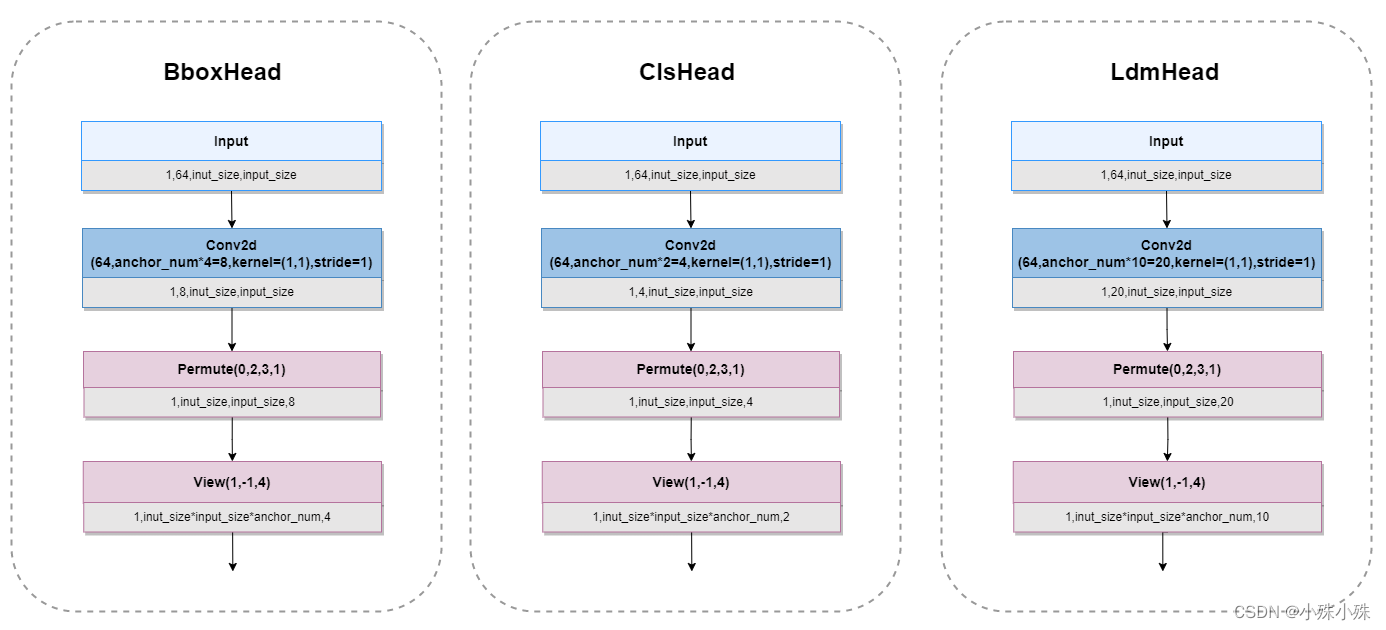
图4
代码如下:
class ClassHead(nn.Module):
def __init__(self,inchannels=512,num_anchors=2):
super(ClassHead,self).__init__()
self.num_anchors = num_anchors
self.conv1x1 = nn.Conv2d(inchannels,self.num_anchors*2,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.permute(0,2,3,1).contiguous()
return out.view(out.shape[0], -1, 2)
class BboxHead(nn.Module):
def __init__(self,inchannels=512,num_anchors=2):
super(BboxHead,self).__init__()
self.conv1x1 = nn.Conv2d(inchannels,num_anchors*4,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.permute(0,2,3,1).contiguous()
out = out.view(out.shape[0], -1, 4)
return out
class LandmarkHead(nn.Module):
def __init__(self,inchannels=512,num_anchors=2):
super(LandmarkHead,self).__init__()
self.conv1x1 = nn.Conv2d(inchannels,num_anchors*10,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.permute(0,2,3,1).contiguous()
return out.view(out.shape[0], -1, 10)
三、Anchor的编解码

图5.
借用SSD中的一个图,图2中的SSH输出其实是将原图分割成80x80、40x40、20x20的单元格,图5中每个单元有4个Anchor(两个等比例两个不等比例),与之不同的是,我们每个单元的使用两个等比例的Anchor。
模型训练的时候会用的Anchor编码,将ground truth映射到每个单元格的中心偏移和宽高。
代码如下:
def encode(matched, priors, variances):
# 进行编码的操作
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]
# 中心编码
g_cxcy /= (variances[0] * priors[:, 2:])
# 宽高编码
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1]
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
def encode_landm(matched, priors, variances):
matched = torch.reshape(matched, (matched.size(0), 5, 2))
priors_cx = priors[:, 0].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
priors_cy = priors[:, 1].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
priors_w = priors[:, 2].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
priors_h = priors[:, 3].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
priors = torch.cat([priors_cx, priors_cy, priors_w, priors_h], dim=2)
# 减去中心后除上宽高
g_cxcy = matched[:, :, :2] - priors[:, :, :2]
g_cxcy /= (variances[0] * priors[:, :, 2:])
g_cxcy = g_cxcy.reshape(g_cxcy.size(0), -1)
return g_cxcy
预测的时候使用Anchor解码,将模型的输出还原为预测框。
代码如下:
def decode(loc, priors, variances):
boxes = torch.cat((priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
boxes[:, :2] -= boxes[:, 2:] / 2
boxes[:, 2:] += boxes[:, :2]
return boxes
def decode_landm(pre, priors, variances):
landms = torch.cat((priors[:, :2] + pre[:, :2] * variances[0] * priors[:, 2:],
priors[:, :2] + pre[:, 2:4] * variances[0] * priors[:, 2:],
priors[:, :2] + pre[:, 4:6] * variances[0] * priors[:, 2:],
priors[:, :2] + pre[:, 6:8] * variances[0] * priors[:, 2:],
priors[:, :2] + pre[:, 8:10] * variances[0] * priors[:, 2:],
), dim=1)
return landms
四、Multi-task Loss
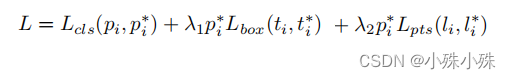
如上图,损失函数分为三个部分:
Face classification loss:是否是人脸的交叉熵loss。
Face box regression loss:预测框的中心偏移、宽高和ground truth的smooth_l1_loss
Facial landmark regression loss:预测的人脸关键点的smooth_l1_loss
代码实现:
class MultiBoxLoss(nn.Module):
def __init__(self, num_classes, overlap_thresh, neg_pos, variance, cuda=True):
super(MultiBoxLoss, self).__init__()
#----------------------------------------------#
# 对于retinaface而言num_classes等于2
#----------------------------------------------#
self.num_classes = num_classes
#----------------------------------------------#
# 重合程度在多少以上认为该先验框可以用来预测
#----------------------------------------------#
self.threshold = overlap_thresh
#----------------------------------------------#
# 正负样本的比率
#----------------------------------------------#
self.negpos_ratio = neg_pos
self.variance = variance
self.cuda = cuda
def forward(self, predictions, priors, targets):
#--------------------------------------------------------------------#
# 取出预测结果的三个值:框的回归信息,置信度,人脸关键点的回归信息
#--------------------------------------------------------------------#
loc_data, conf_data, landm_data = predictions
#--------------------------------------------------#
# 计算出batch_size和先验框的数量
#--------------------------------------------------#
num = loc_data.size(0)
num_priors = (priors.size(0))
#--------------------------------------------------#
# 创建一个tensor进行处理
#--------------------------------------------------#
loc_t = torch.Tensor(num, num_priors, 4)
landm_t = torch.Tensor(num, num_priors, 10)
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
# 获得真实框与标签
truths = targets[idx][:, :4].data
labels = targets[idx][:, -1].data
landms = targets[idx][:, 4:14].data
# 获得先验框
defaults = priors.data
#--------------------------------------------------#
# 利用真实框和先验框进行匹配。
# 如果真实框和先验框的重合度较高,则认为匹配上了。
# 该先验框用于负责检测出该真实框。
#--------------------------------------------------#
match(self.threshold, truths, defaults, self.variance, labels, landms, loc_t, conf_t, landm_t, idx)
#--------------------------------------------------#
# 转化成Variable
# loc_t (num, num_priors, 4)
# conf_t (num, num_priors)
# landm_t (num, num_priors, 10)
#--------------------------------------------------#
zeros = torch.tensor(0)
if self.cuda:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
landm_t = landm_t.cuda()
zeros = zeros.cuda()
#------------------------------------------------------------------------#
# 有人脸关键点的人脸真实框的标签为1,没有人脸关键点的人脸真实框标签为-1
# 所以计算人脸关键点loss的时候pos1 = conf_t > zeros
# 计算人脸框的loss的时候pos = conf_t != zeros
#------------------------------------------------------------------------#
pos1 = conf_t > zeros
pos_idx1 = pos1.unsqueeze(pos1.dim()).expand_as(landm_data)
landm_p = landm_data[pos_idx1].view(-1, 10)
landm_t = landm_t[pos_idx1].view(-1, 10)
loss_landm = F.smooth_l1_loss(landm_p, landm_t, reduction='sum')
pos = conf_t != zeros
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, reduction='sum')
#--------------------------------------------------#
# batch_conf (num * num_priors, 2)
# loss_c (num, num_priors)
#--------------------------------------------------#
conf_t[pos] = 1
batch_conf = conf_data.view(-1, self.num_classes)
# 这个地方是在寻找难分类的先验框
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# 难分类的先验框不把正样本考虑进去,只考虑难分类的负样本
loss_c[pos.view(-1, 1)] = 0
loss_c = loss_c.view(num, -1)
#--------------------------------------------------#
# loss_idx (num, num_priors)
# idx_rank (num, num_priors)
#--------------------------------------------------#
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
#--------------------------------------------------#
# 求和得到每一个图片内部有多少正样本
# num_pos (num, )
# neg (num, num_priors)
#--------------------------------------------------#
num_pos = pos.long().sum(1, keepdim=True)
# 限制负样本数量
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
#--------------------------------------------------#
# 求和得到每一个图片内部有多少正样本
# pos_idx (num, num_priors, num_classes)
# neg_idx (num, num_priors, num_classes)
#--------------------------------------------------#
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
# 选取出用于训练的正样本与负样本,计算loss
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1,self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, reduction='sum')
N = max(num_pos.data.sum().float(), 1)
loss_l /= N
loss_c /= N
num_pos_landm = pos1.long().sum(1, keepdim=True)
N1 = max(num_pos_landm.data.sum().float(), 1)
loss_landm /= N1
return loss_l, loss_c, loss_landm
总的来说RetinaFace和RetinaNet很像,还有SSD的影子,确实提供了一个可用的高效的人脸检测框架,可改进的地方也有很多,需要大家自己动手实验了。
本文转载自: https://blog.csdn.net/xian0710830114/article/details/124689722
版权归原作者 小殊小殊 所有, 如有侵权,请联系我们删除。
版权归原作者 小殊小殊 所有, 如有侵权,请联系我们删除。