
前言
PySpark系列的专栏文章目前的话应该只会比Pandas更多不会更少,可以用PySpark实现的功能太多了,基本上Spark能实现的PySpark都能实现,而且能够实现兼容python其他库,这就给了PySpark极大的使用空间,能够结合大数据集群实现更高效更精确的大数据处理或者预测。如果能够将这些工具都使用的相当熟练的话,那必定是一名优秀的大数据工程师。故2023年这一年的整体学习重心都会集中在这门技术上,当然Pandas以及Numpy的专栏都会更新。我将对PySpark专栏给予极大的厚望,能够实现从Pandas专栏过度到PySpark专栏零跨度学习成本,敬请期待。
文接上篇:
PySpark数据分析基础:核心数据集RDD原理以及操作一文详解(一)
这篇文章将主要将RDD核心函数功能展现出来,当然会有一些不常使用的函数这里不会做展示,若是有需求的可以去官网自行查阅。
1.cartesian(笛卡尔积计算)
RDD.cartesian(other: pyspark.rdd.RDD[U]) → pyspark.rdd.RDD[Tuple[T, U]]
返回此RDD与另一个RDD的笛卡尔积,即所有元素对(a,b)的RDD。可以理解为两个list作zip操作,但是十分简便:
rdd = sc.parallelize([1, 2])
rdd.cartesian(rdd).collect()
[(1, 1), (1, 2), (2, 1), (2, 2)]
如果两个为需要组合的list就可以一个函数搞定。
2.coalesce(缩减分区数)
RDD.coalesce(numPartitions: int, shuffle: bool = False) → pyspark.rdd.RDD[T]
返回缩减为numPartitions分区的新RDD。
sc.parallelize([1, 2, 3, 4, 5], 3).glom().collect()
[[1], [2, 3], [4, 5]]
sc.parallelize([1, 2, 3, 4, 5], 3).coalesce(1).glom().collect()
[[1, 2, 3, 4, 5]]
3.cogroup(对Key聚合计算)
RDD.cogroup(other: pyspark.rdd.RDD[Tuple[K, U]],
numPartitions: Optional[int] = None)
→ pyspark.rdd.RDD[Tuple[K, Tuple[pyspark.resultiterable.ResultIterable[V],
pyspark.resultiterable.ResultIterable[U]]]]
对于self或other中的每个键k,返回一个结果RDD,该RDD包含一个元组,其中包含self和other中该键的值列表。
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2)])
[(x, tuple(map(list, y))) for x, y in sorted(list(x.cogroup(y).collect()))]
[('a', ([1], [2])), ('b', ([4], []))]
4.collect(结果返回列表List)
RDD.collect() → List[T]
返回包含此RDD中所有元素的列表。
这个就不作展示了。
5.collectAsMap(作为字典返回)
RDD.collectAsMap() → Dict[K, V]
将此RDD中的键值对作为字典返回给master。只有当所有数据都加载到驱动程序的内存中时,预期生成的数据很小时,才应使用此方法。
m = sc.parallelize([(1, 2), (3, 4)]).collectAsMap()
m.keys()
dict_keys([1, 3])
6.combineByKey(Key聚合计算算子)
泛型函数,使用一组自定义聚合函数组合每个键的元素。该函数很关键,combineByKey的强大之处,在于提供了三个函数操作来操作一个函数。第一个函数,是对元数据处理,从而获得一个键值对。第二个函数,是对键值键值对进行一对一的操作,即一个键值对对应一个输出,且这里是根据key进行整合。第三个函数是对key相同的键值对进行操作,有点像reduceByKey,但真正实现又有着很大的不同。
对于“组合类型”C,将RDD[(K,V)]转换为RDD[K,C)]类型的结果。
需要提供三种函数运算逻辑作为算子:
RDD.combineByKey(createCombiner: Callable[[V], U],
mergeValue: Callable[[U, V], U],
mergeCombiners: Callable[[U, U], U],
numPartitions: Optional[int] = None,
partitionFunc: Callable[[K], int] = <function portable_hash>)
→pyspark.rdd.RDD[Tuple[K, U]]
- createCombiner:将V转换为C(例如,创建一个单元素列表)
- mergeValue:将V合并为C(例如,将其添加到列表末尾)
- mergeCombiners:将两个C组合成一个C(例如,合并列表)
为了避免内存分配,允许mergeValue和mergeCombiner修改并返回其第一个参数,而不是创建新的C。
此外,用户可以控制输出RDD的分区。
V和C可以不同——例如,可以将类型(Int,Int)的RDD分组为类型(Int,List[Int])的RDD。
x = sc.parallelize([("a", 1), ("b", 1), ("a", 2)])
def to_list(a):
return [a]
def append(a, b):
a.append(b)
return a
def extend(a, b):
a.extend(b)
return a
sorted(x.combineByKey(to_list, append, extend).collect())
[('a', [1, 2]), ('b', [1])]
7.count(统计元素)
RDD.count() → int
返回此RDD中的元素数。
sc.parallelize([2, 3, 4]).count()
3
8.countApprox(统计计数)
RDD.countApprox(timeout: int, confidence: float = 0.95) → int
count()的近似版本,即使不是所有任务都已完成,也会在超时内返回可能不完整的结果。
rdd = sc.parallelize(range(1000), 10)
rdd.countApprox(1000, 1.0)
1000
9.countApproxDistinct(返回RDD中不同元素的近似数量)
RDD.countApproxDistinct(relativeSD: float = 0.05) → int
返回RDD中不同元素的近似数量。所使用的算法基于streamlib实现的“HyperLogLog in Practice:Algorithmic Engineering of a State of The Art Cardinality Estimation algorithm”
n = sc.parallelize([i % 20 for i in range(1000)]).countApproxDistinct()
16 < n < 24
True
10.countByKey(计算每个键的元素数)
RDD.countByKey() → Dict[K, int]
计算每个键的元素数,并将结果作为字典返回给master。
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
sorted(rdd.countByKey().items())
[('a', 2), ('b', 1)]
11.countByValue(将此RDD中每个唯一值的计数作为(value,count)对的字典返回)
RDD.countByValue() → Dict[K, int]
将此RDD中每个唯一值的计数作为(value,count)对的字典返回。
sorted(sc.parallelize([1, 2, 1, 2, 2], 2).countByValue().items())

12.distinct(返回包含此RDD中不同元素的新RDD)
RDD.distinct(numPartitions: Optional[int] = None) → pyspark.rdd.RDD[T]
返回包含此RDD中不同元素的新RDD。
sorted(sc.parallelize([1, 1, 2, 3]).distinct().collect())
[1, 2, 3]

13.filter( 返回仅包含满足条件的元素的新RDD)
RDD.filter(f: Callable[[T], bool]) → pyspark.rdd.RDD[T]
返回仅包含满足条件的元素的新RDD。
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd.filter(lambda x: x % 2 == 0).collect()

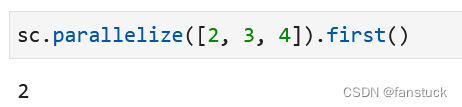
14.first(返回此RDD中的第一个元素)
RDD.first() → T
返回此RDD中的第一个元素。
sc.parallelize([2, 3, 4]).first()
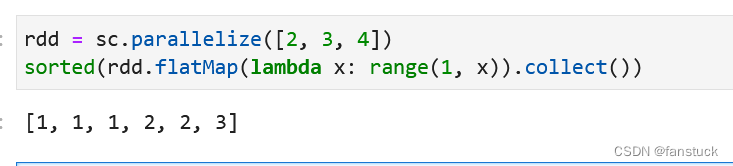
15.flatMap(逐个Map展开返回)
RDD.flatMap(f: Callable[[T], Iterable[U]], preservesPartitioning: bool = False)
首先将函数应用于此RDD的所有元素,然后将结果展平,从而返回新的RDD。
rdd = sc.parallelize([2, 3, 4])
sorted(rdd.flatMap(lambda x: range(1, x)).collect())
16.flatMapValues(逐个Key Map展开)
RDD.flatMapValues(f: Callable[[V], Iterable[U]]) → pyspark.rdd.RDD[Tuple[K, U]]
通过flatMap函数传递pariRDD中的每个值,而不更改键;这也保留了原始RDD的分区。
x = sc.parallelize([("a", ["x", "y", "z"]), ("b", ["p", "r"])])
def f(x): return x
x.flatMapValues(f).collect()

17.fold(折叠函数)
RDD.fold(zeroValue: T, op: Callable[[T, T], T]) → T
使用给定的关联函数和中性“zero value”聚合每个分区的元素,然后聚合所有分区的结果:
允许函数op(t1,t2)修改t1并将其作为结果值返回,以避免对象分配;然而,它不应该修改t2。
这与在Scala等函数语言中为非分布式集合实现的折叠操作有些不同。此折叠操作可以单独应用于分区,然后将这些结果折叠为最终结果,而不是按照某些定义的顺序将折叠顺序应用于每个元素。对于不可交换的函数,其结果可能与应用于非分布式集合的折叠结果不同。
from operator import add
sc.parallelize([1, 2, 3, 4, 5]).fold(2, add)
#理解x,y: x,它代指的是返回值,而y是对rdd各元素的遍历。所以,x+y表示对num中数据进行累加

要这么理解他的计算逻辑。
zeroValue: T为初始值,第二个为function功能函数,用于将T和迭代值合并。加法的初始值为0,乘法的初始值为1。例如这个函数计算过程为:
(0+2(初始值)+1)->flod(3+2)->(5+2(初始值)+2)->flod(9+2)>(11+2+3)->flod(16+2)->(18+2+4)->flod(24+2)->(26+2+5)=33
最终结果是 初始值*(节点数目+1) + Rdd各元素求和。
18.foldByKey(通过Key折叠)
RDD.foldByKey(zeroValue: V,
func: Callable[[V, V], V],
numPartitions: Optional[int] = None,
partitionFunc: Callable[[K], int] = <function portable_hash>)
→ pyspark.rdd.RDD[Tuple[K, V]]
使用关联函数“func”和中性“zeroValue”合并每个键的值,可以将其添加到结果中任意次数,且不得更改结果(例如,0表示加法,1表示乘法)。
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
from operator import add
sorted(rdd.foldByKey(0, add).collect())
[('a', 2), ('b', 1)]
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。