
大数据机器学习与深度学习——回归模型评估
回归模型的性能的评价指标主要有:MAE(平均绝对误差)、MSE(平均平方误差)、RMSE(平方根误差)、R2_score。但是当量纲不同时,RMSE、MAE、MSE难以衡量模型效果好坏,这就需要用到R2_score。
平均绝对误差(MAE Mean Absolute Error)
是绝对误差的平均值,能更好地反映预测值误差的实际情况。
均方误差(MSE mean-square error)
该统计参数是预测数据和原始数据对应点误差的平方和的均值。
根均方根误差(RMSE Root Mean Square Error)
求均方误差的根号
决定系数(R-Squared Score)
决定系数R2 score(coefficient of determination),也称判定系数或者拟合优度。它是表征回归方程在多大程度上解释了因变量的变化,或者说方程对观测值的拟合程度如何。拟合优度的有效性通常要求:自变量个数:样本数>1:10。
R2 决定系数,反映因变量的全部变异能通过回归关系被自变量解释的比例。
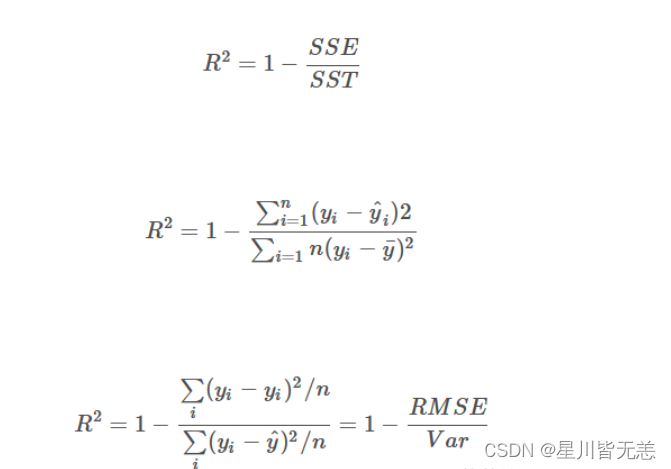
根据 R-Squared 的取值,来判断模型的好坏,其取值范围为[0,1]:
如果结果是 0,说明模型拟合效果很差;
如果结果是 1,说明模型无错误。
一般来说,R-Squared 越大,表示模型拟合效果越好。R-Squared 反映的是大概有多准,因为,随着样本数量的增加,R-Square必然增加,无法真正定量说明准确程度,只能大概定量。
所以要想决定系数R2越接近1,必须满足MSE越小,也就是真实值与预测值相差不大,也就是模型拟合程度高,同时var方差越大,也就是我们的样本离散程度大,对应的我们实际采样过程中,就是要求样本是随机性,以及全面性,覆盖度广。
注意
决定系数适用于线性回归,单变量或者多元线性;y=ax或者y=ax1+bx2…; - 拟合模型是非线性的,不能用决定系数来评价其拟合效果,例如:BP神经网络;
当拟合程度不行,可以调整参数或者权重-例如a,b,使预测值与真实值越接近。
其中,分子部分表示真实值与预测值的平方差之和,类似于均方差 MSE;分母部分表示真实值与均值的平方差之和,类似于方差 Var。
(R-Squared score)-深度研究
对于R-Squared score可以通俗地理解为使用均值作为误差基准,看预测误差是否大于或者小于均值基准误差。
R2_score = 1,样本中预测值和真实值完全相等,没有任何误差,表示回归分析中自变量对因变量的解释越好。
R2_score =0。此时分子等于分母,样本的每项预测值都等于均值。
R2_score不是r的平方,也可能为负数(分子>分母),模型等于盲猜,还不如直接计算目标变量的平均值。
# 根据公式,我们可以写出r2_score实现代码
1- mean_squared_error(y_test,y_preditc)/ np.var(y_test)
# 也可以直接调用sklearn.metrics中的r2_score
sklearn.metrics.r2_score(y_true, y_pred, sample_weight=None, multioutput='uniform_average')
# y_true:观测值
# y_pred:预测值
# sample_weight:样本权重,默认None
# multioutput:多维输入输出,可选‘raw_values’, ‘uniform_average’,‘variance_weighted’或None。默认为’uniform_average’;
# raw_values:分别返回各维度得分 uniform_average:各输出维度得分的平均
# variance_weighted:对所有输出的分数进行平均,并根据每个输出的方差进行加权。
r2_score: 0.47
r2_score偏小,预测效果一般。
注意事项
1、R-Squared score 一般用在线性模型中(非线性模型也可以用)
2、R-Squared score 不能完全反映模型预测能力的高低,某个实际观测的自变量取值范围很窄,但此时所建模型的R2 很大,但这并不代表模型在外推应用时的效果肯定会很好。
3、数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差,此时可以使用Adjusted R-Square (校正决定系数),能对添加的非显著变量给出惩罚
校正决定系数(Adjusted R-Square)是多元线性回归模型中用于评估模型拟合优度的一种统计指标。它对决定系数(R-Square)进行了修正,考虑了模型中使用的自变量的数量。
决定系数(R-Square)用于衡量模型对因变量变异性的解释程度,其取值范围在0到1之间,越接近1表示模型对数据的解释越好。然而,当模型中增加自变量时,R-Square的值可能会增加,即使新加入的变量对模型的解释并不显著。为了解决这个问题,引入了校正决定系数。
校正决定系数
计算公式如下:

其中:
( R^2 ) 是决定系数。
( n ) 是样本数量。
( k ) 是模型中自变量的数量。
校正决定系数考虑了模型的自由度,通过对决定系数进行修正,避免了在模型中增加自变量时导致模型拟合度提高的情况。因此,校正决定系数通常对模型的泛化能力提供更准确的评估。
在实际应用中,分析人员通常会综合考虑决定系数和校正决定系数,以全面评估模型的拟合质量和适应性。
其中,n 是样本数量,p 是特征数量。
Adjusted R-Square 抵消样本数量对 R-Square的影响,做到了真正的 0~1,越大越好。
python中可以直接调用。
统计学理论
方差(variance):
计算公式:S2=1/n [(x1-X)2+(x2-X)2+(x3-X)2+…(xn-X)2] (X表示平均数)
方差在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。
概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。
统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。
代码实现
sklearn库调用模型评估
#导入相应的函数库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
import numpy as np
import pandas as pd
# 使用sklearn调用衡量线性回归的MSE 、 RMSE、 MAE、r2
from math import sqrt
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
print("mean_absolute_error:", mean_absolute_error(y_test, y_predict))
print("mean_squared_error:", mean_squared_error(y_test, y_predict))
print("rmse:", sqrt(mean_squared_error(y_test, y_predict)))
print("r2 score:", r2_score(y_test, y_predict))
原生实现
# 衡量线性回归的MSE 、 RMSE、 MAE、r2
from math import sqrt
mse = np.sum((y_test - y_predict)**2)/ len(y_test)
rmse = sqrt(mse)
mae = np.sum(np.absolute(y_test - y_predict)) / len(y_test)
r2 =1-mse/ np.var(y_test)#均方误差/方差
print(" mae:",mae,"mse:",mse," rmse:",rmse," r2:",r2)
应用
y_test1=np.array(Y_true_3[:,0:1])y_predict1=np.array(predict[:,0])y_test2=np.array(Y_true_3[:,1:2])y_predict2=np.array(predict[:,1])
print("ROP : R2:%.4f"% r2_score(y_test1, y_predict1), " MSE:%.4f"% mean_squared_error(y_test1, y_predict1), "RMSE:%.4f" % calc_rmse(y_test1, y_predict1))
print("Torque: R2:%.4f"% r2_score(y_test2, y_predict2), "MSE:%.4f"% mean_squared_error(y_test2, y_predic
版权归原作者 星川皆无恙 所有, 如有侵权,请联系我们删除。