
前言
在机器学习库sklearn中,构建模型、生成随机数据集、拆分数据集时经常会看到random_state这个参数,例如:
data = make_blobs(n_samples=100, centers =2,random_state=9)//生成数据集时
X, y = make_regression(n_features=1,n_informative=1,noise=30,random_state=5)//构建模型
x_train, x_test, y_train,y_test=model_selection.train_test_split(x,y,test_size=0.2,random_state=0)//拆分数据集
一、设置随机种子作用
random_state 相当于随机数种子random.seed() 。random_state 与 random seed 作用是相同的。
1.未设置随机种子案例
下面两段代码完全相同都没有设置 random seed。它每次取的结果就不同,它的随机数种子与当前系统时间有关。
import random
for i in range(10):print(random.randint(1,100))
95 53 39 3 97 76 88 22 93
for i in range(10):print(random.randint(1,100))
60 82 36 69 87 100 55 36 8 40 44
2.设置随机种子案例
下面这两段代码设置了相同的 random seed(789),它们取的随机数就完全相同,多运行几次也是这样。
import random
random.seed(789)for i in range(10):print(random.randint(1,100))
62 91 82 5 63 18 51 69 40 68
random.seed(789)for i in range(10):print(random.randint(1,100))
62 91 82 5 63 18 51 69 40 68
设置了随机种子的值后,那么当别人重新运行你的代码的时候就能得到完全一样的结果,复现和你一样的过程。
二、randstate的应用
random_state可以用于很多函数,我比较熟悉的是用于以下三个地方:1、训练集测试集的划分 2、构建机器学习模型 3、生成数据集
1. 划分训练集和测试集的类train_test_split
随机数种子控制每次划分训练集和测试集的模式,其取值不变时划分得到的结果一模一样,其值改变时,划分得到的结果不同。若不设置此参数,则函数会自动选择一种随机模式,得到的结果也就不同。```c
ate_unverified_context
2.构建机器学习模型
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30,splitter="random")
其取值不变时,用相同的训练集建树得到的结果一模一样,对测试集的预测结果也是一样的;
其值改变时,得到的结果不同;
若不设置此参数,则函数会自动选择一种随机模式,每次得到的结果也就不同。
3.生成数据集
未设置random_state随机种子值的数据集,同一段代码连续执行两次结果如下图所示,可以看到两次生成不同的数据集。
#导入必要的库
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
#生成一个数据集
#根据给定的参数生成数据,主要用来测试代码性能(没有实际数据的情况下)
data =make_blobs(n_samples=100, centers =2)#没有设置随机种子
#将特征和标签赋值给X和y
X, y = data
#使用散点图进行可视化
plt.scatter(X[y==1,0], X[y==1,1], cmap=plt.cm.spring, edgecolor='k',marker='^')
plt.scatter(X[y==0,0], X[y==0,1], cmap=plt.cm.spring, edgecolor='k',marker='o')
#显示图像
plt.show()
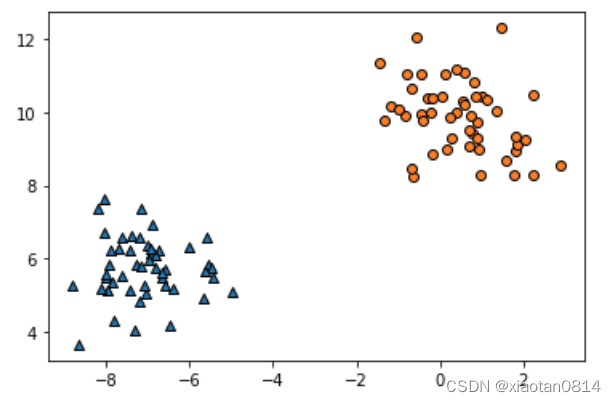
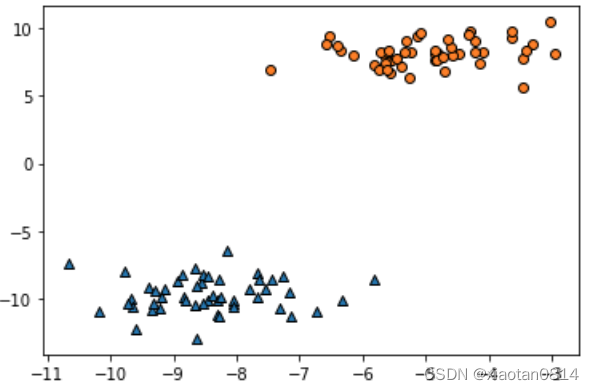
设置了random_state随机种子值的数据集,同一段代码连续执行两次结果如下图所示,可以看到两次生成相同的数据集。
#导入必要的库
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
#生成一个数据集
#根据给定的参数生成数据,主要用来测试代码性能(没有实际数据的情况下)
data =make_blobs(n_samples=100, centers =2,random_state=9)#设置随机种子random_state
#将特征和标签赋值给X和y
X, y = data
#使用散点图进行可视化
plt.scatter(X[y==1,0], X[y==1,1], cmap=plt.cm.spring, edgecolor='k',marker='^')
plt.scatter(X[y==0,0], X[y==0,1], cmap=plt.cm.spring, edgecolor='k',marker='o')
#显示图像
plt.show()
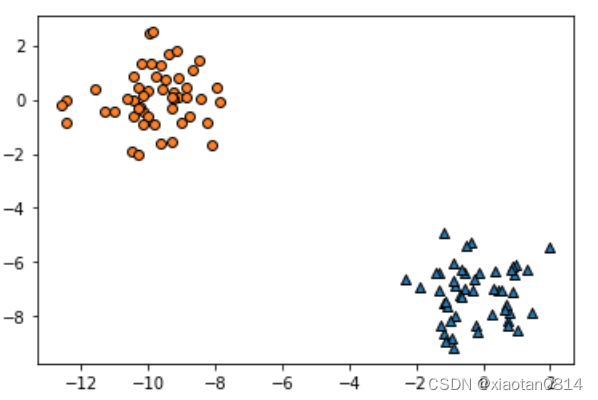
提示:这里random_state的值是随机选取的,没有固定规律,只要保证取值一致,就可以得到完全一样的结果。
总结
在需要设置random_state的地方给其赋一个值,当多次运行此段代码能够得到完全一样的结果,别人运行此代码也可以复现你的过程。若不设置此参数则会随机选择一个种子,执行结果也会因此而不同了。虽然可以对random_state进行调参,但是调参后在训练集上表现好的模型未必在陌生训练集上表现好,所以一般会随便选取一个random_state的值作为参数。
参考网址:
https://www.jianshu.com/p/4deb2cb2502f
https://www.shuzhiduo.com/A/RnJW4yYw5q/
版权归原作者 LoveLife_QL 所有, 如有侵权,请联系我们删除。