
对于图像生成方向目前通常使用的方法是生成对抗网络或扩散模型。尽管这两种方法有的不同的特点,但是他们的一个共同点是模型训练对机器资源的要求很高,如果我们要以一种全新的风格创建一个图像,模型将需要从头开始训练,这可能需要更多的时间和资源,例如比较熟悉的StyleGan[3]是在拥有8个Tesla V100 gpu的NVIDIA DGX-1上训练了大约一周的时间。
但是,如果我们没有这样的硬件资源和时间怎么办?是否可以玩转图像生成? 在本文中,我们将描述一种图像生成方法,该方法无需额外的模型训练和昂贵的设备就可以在不同的图像风格之间切换。
目标
我们的主要目标是创建一个通用的嵌入提取器。 这个嵌入提取器用于比较图像和表情符号的各个部分。然后我们使用它来创建一个生成各种样式的图像的图像生成器。 在本文中,将考虑两种创建嵌入提取器的方法,这两种方法会在下面详细说明。 所以首先,我们为生成器和训练嵌入提取器准备一个数据集。
数据集
用到的数据集是包含了需要创建的头像各个部件,因为需要通过组合这些部件来生成图像。那么如何创建这个数据集呢,最直接的方法是可以手动创建每个单独的部件,但是这种方法太慢并且不灵活。所以这里选择了一个更加灵活和省时的方法:创建多个模板,并将这些模板相互组合。
我们可以创建五种类型的眼睛、嘴巴和脸型,通过组合可以为我们提供 125 种不同的表情符号。
所以这里我们准备了一个Python的脚本,来生成这些部件的模板,这些模板我们使用SVG格式保存。生成后模板以后,就需要从每个部件中提取嵌入,然后将它们保存为“avatar_part - embedding”对。通过这个配对,我们就能够在不同的艺术风格之间快速切换,而无需额外的模型训练。我们可以通过两种不同的方法来创建这个嵌入:1、通过预训练的 ResNet50 ;2、通过定制的自编码器。预训练ResNet50 不需要额外的训练,但自编码器则需要重新训练会花费一些时间。
为了达到更好的效果,对于预训练的ResNet50 可能还需要进一步的微调,但是无论使用那种方式我们都需要一些数据集进行训练或微调,所以还需要有一个数据集来支持这样工作。所以这里我们选择了 CELEBA 的数据集(这个应该算是最大的人脸数据集了)。使用脚本将数据集的人脸分割成段并将它们保存到文件夹中。现在,我们有了嘴巴数据集、眼睛数据集等。在这个脚本中使用 BiSeNet [1] 进行人脸分割,因为这些都是现成的不需要我们额外的工作。
模型架构
架构是通过一个输入层、一个输出层和三个隐藏层来表示。输入层获取一张图像,将它转换成306x306像素大小。
在第一个隐藏层中,通过BiSeNet[1]对人脸进行分段分割。
在第二个隐藏层中是嵌入提取模型,他返回每个部件的提取的特征
在第三个隐藏层中,我们将第二个隐藏层的的每一个输出与每个可能的表情符号部分进行比较。然后通过计算余弦相似度实现比较
第三个隐藏层的输出是与面部余弦相似度最大的表情符号。最后,输出层是一个创建表情函数,将这些部分进行组合生成完整的表情符号,整个流程如下:
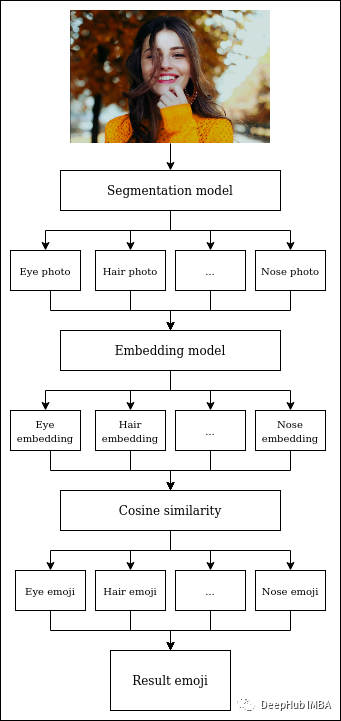
这个架构可以总结为三层:
分割模型,将一张自拍分成几个人脸片段。在这种情况下,分割模型[1]与人脸裁剪模型[2]一起工作
嵌入模型,将每个人脸段转换为嵌入空间。如前所述,可选ResNet50和自动编码器或其他的任意架构
余弦相似度,它将人脸嵌入与所有相同类型的部件嵌入进行比较
一些研究
虽然我们的模型是由几个神经网络组成的,但结构相并不复杂。正如在上面所写的,这个合成将最相似的头像部分与脸部片段通过余弦相似度对嵌入进行匹配,然后将它们组合。但这里也有一些主要问题需要确认:
1、如何才能准确地得到这些嵌入,从而使比较有意义?
如果选择使用ResNet50,则需要将获取分类头(最后一层)之外的特征,对于该模型只需要去掉最后一层。
对于自编码器,它是无监督解决方案,嵌入空间将是自动编码器中的压缩线性层,我们将在图像比较中使用它。
2、嵌入可视化
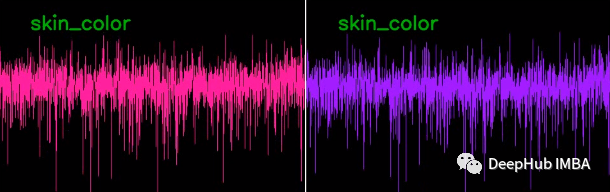
出于研究目的,我们还编写了一个用于嵌入可视化的脚本,该脚本获取一个视频文件作为输入,返回一个带有嵌入图形的视频文件作为输出。在这个脚本中,我们得到嵌入为每帧头像的每个部分和面部图像的图。 粉色代表人脸嵌入,紫色代表头像嵌入。
3、ResNet50的结果
我们使用通过预训练的 ResNet50 进行测试。 看看下面的结果:

测试对象什么也不做,但嵌入在每一帧都在变化。 由于嵌入彼此之间没有太大差异,并且它们的维度太多,因此无法清晰地生成头像。 即使测试对象的情绪发生变化(例如,他们的脸上出现微笑),嵌入仍然保持不变(见图)。

4、自编码器作为嵌入提取器
ResNet50的表现并不好,那么自编码器呢? 我们使用下面的架构:
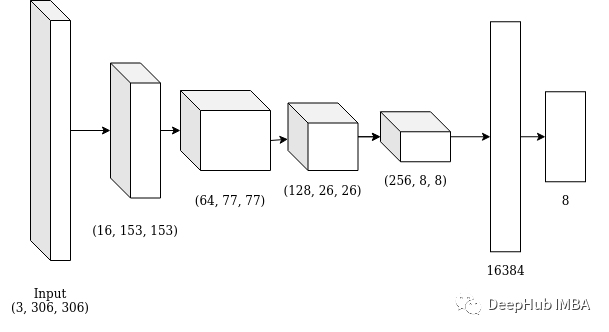
代码如下:
class FaceAutoencoder(nn.Module):
def __init__(self):
super(FaceAutoencoder, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 3, stride=2, padding=1),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 64, 3, stride=2, padding=1),
nn.ReLU(),
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 128, 5, stride=3, padding=2),
nn.ReLU(),
)
self.conv4 = nn.Sequential(
nn.Conv2d(128, 256, 5, stride=3, padding=1),
nn.ReLU(),
)
self.fc_conv = nn.Sequential(
nn.Flatten(1),
nn.Linear(16384, 8),
nn.ReLU(),
)
self.fc_deconv = nn.Sequential(
nn.Linear(8, 16384),
nn.ReLU(),
nn.Unflatten(dim=1, unflattened_size=[256, 8, 8])
)
self.deconv1 = nn.Sequential(
nn.ConvTranspose2d(256, 128, 5, stride=3, padding=0),
nn.ReLU(),
)
self.deconv2 = nn.Sequential(
nn.ConvTranspose2d(128, 64, 5, stride=3, padding=2, output_padding=1),
nn.ReLU(),
)
self.deconv3 = nn.Sequential(
nn.ConvTranspose2d(64, 16, 3, stride=2, padding=1, output_padding=0),
nn.ReLU(),
)
self.deconv4 = nn.Sequential(
nn.ConvTranspose2d(16, 3, 3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
)
def encode(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.fc_conv(x)
return x
def decode(self, x):
x = self.fc_deconv(x)
x = self.deconv1(x)
x = self.deconv2(x)
x = self.deconv3(x)
x = self.deconv4(x)
return x
def forward(self, x):
x = self.encode(x)
x = self.decode(x)
return x
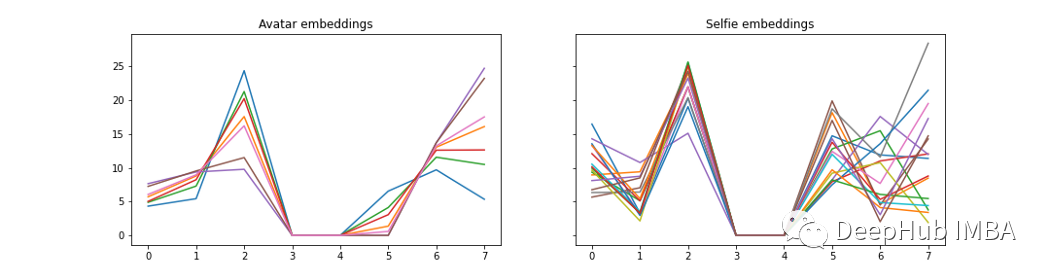
下面是来自 CELEBA 数据集的人脸片段和来自 avatar 数据集的人脸部分的嵌入图。 可以看到这些图表有一些相似之处。
我们来试试这个模型的结果:


使用自动编码器方法,嵌入更好一些,小干扰只会轻微影响最终结果。
总结
我们可以看到,通过这种方式,几乎不需要进行任何的大型训练就可以在不同风格之间进行切换,但这里的问题也很明显嵌入提取器(第二个隐藏层)还有很大的改进空间。
引用:
- https://github.com/zllrunning/face-parsing.PyTorch
- https://github.com/eladrich/pixel2style2pixel
- https://arxiv.org/abs/1812.04948
作者:Akvelon