
作者:苍何,前大厂高级 Java 工程师,阿里云专家博主,CSDN 2023 年 实力新星,土木转码,现任部门技术 leader,专注于互联网技术分享,职场经验分享。
🔥热门文章推荐:
- (1)对程序员来说,技术能力和业务逻辑哪个更重要?
- (2)搭建GitHub免费个人网站(详细教程)
- (3)itchat实现微信聊天机器人
- (4)嗖嗖移动业务大厅(源码下载+注释全 值得收藏)

嗨,大家好!我是苍何。最近,AI界真是热闹非凡。看看国外,OpenAI 搞出来的 Sora 简直火到不行,而谷歌的 Gemini 1.5 也做得相当不错,精细到家了。回头看看咱们国内,AI也没闲着,尤其是阿里,动作频频,推了不少东西出来,效果挺好的。其中不少工具真的能大大提高我们的工作效率,可谓是隐藏的AI宝藏啊。
一、通义千问大模型
通义千问是阿里云自主研发的超大规模语言模型,它能够理解并生成人类的自然语言输入,从而在不同领域和任务中提供服务和帮助。这个模型不仅能创作文字,比如写故事、公文、邮件、剧本、诗歌等,还具备多轮对话、文案创作、逻辑推理、多模态理解和多语言支持等功能。通义千问已经在多个领域展现出其强大的能力,包括通用能力、创新能力、服务能力、平台能力、生态合作、电商行业应用等方面获得了高分评价。
此外,阿里云还把大模型开源了,供全社会免费商用,以降低大模型使用的门槛,让大模型技术更好地为每个企业和个人所用,这个必须点赞,要知道强如 ChatGPT 这样的大模型都是闭源的,开源就意味着会有一堆的场景能被挖掘出来。
除了能通过 web 使用大模型提效外,我们还可以使用通义千问大模型在以下方面做提效:
- 优化训练方法,采用Chat-ML格式进行训练
- 通过开源获取更多资源和工具,提高改造大模型的能力
- 在函数计算上运行时,调整模型参数、使用适当的硬件资源以及编写高效的代码
- 利用通义千问的预训练数据进行模型训练,以获得更好的效果
- 结合LLM大模型和文本向量生成等能力,打造基于垂直领域的问答服务
- 通过扩展的SQL与数据库交互,提升数据推理和交互效率
- 通过网页嵌入、API/SDK调用等方式,将模型能力集成到应用和服务中
以下是一些重要文档:
1、使用地址:https://tongyi.aliyun.com/
2、通义千问介绍文档 🔗:https://tongyi.aliyun.com/qianwen/blog/tsq0i7fyr9is4oeo
3、代码链接 🔗: https://github.com/QwenLM
4、论文链接 🔗: https://arxiv.org/abs/2309.16609
5、Discord🔗: https://discord.gg/z3GAxXZ9C
6、魔塔社区 🔗: https://modelscope.cn/organization/qwen
二、Animate Anyone
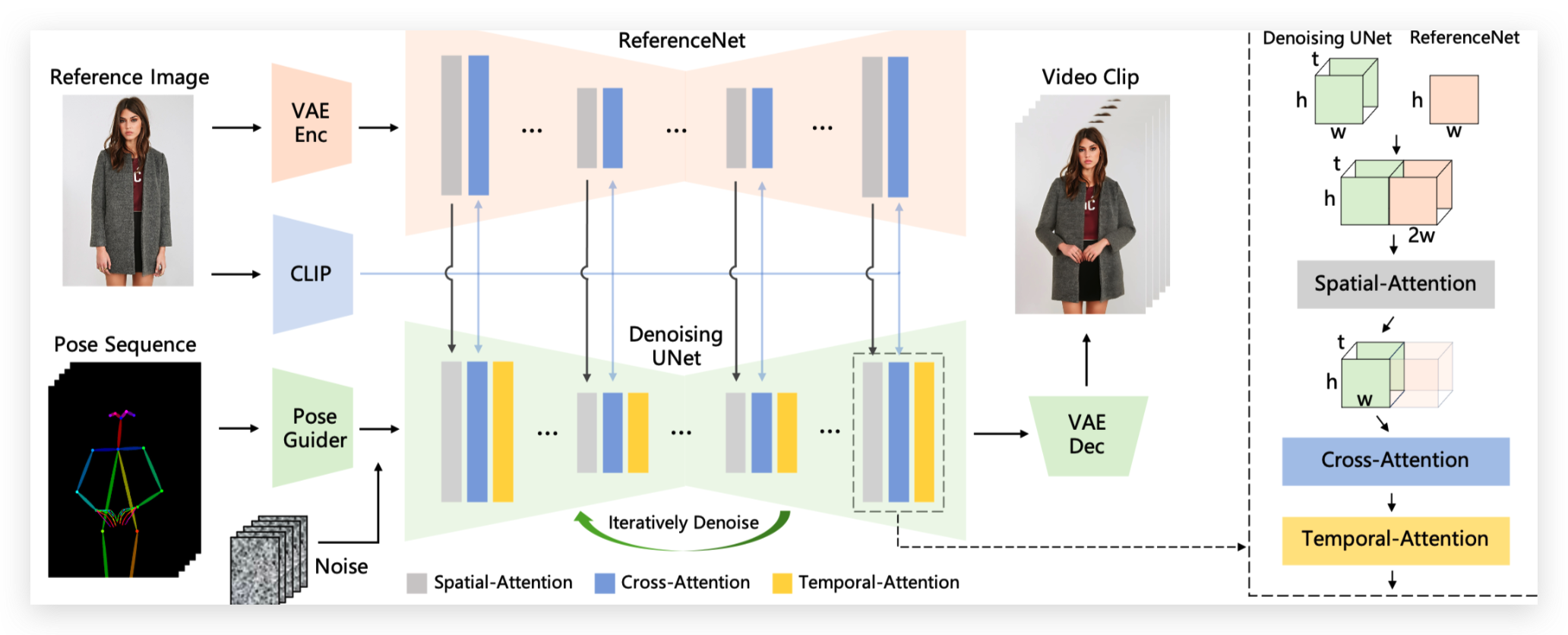
Animate Anyone 是阿里巴巴集团智能计算研究所开发的一个项目,能够从静态图像生成动态视频,能够将任意图像角色动画化。之前看到的很多兵马俑跳舞的视频就是这个做的。

而且目前已经集成在通义千问 APP 里面-全民舞王

该项目通过结合骨骼动画和扩散模型,能够生成高清晰度和逼真的角色细节,并在大幅度运动下保持与参考图像的时间一致性,同时在帧之间展现时间连续性。Animate Anyone的技术创新主要体现在设计了ReferenceNet、Pose Guider和Spatial-Attention等模块,这些模块共同确保了角色细节的保留、角色运动的控制以及帧间的平滑过渡。此外,Animate Anyone在UBC时尚视频数据集和TikTok数据集上进行了应用评估,取得了优于现有技术的状态结果。
体验地址和相关文档:
1、 体验地址 🔗:通义千问 APP 里面-全民舞王
2、代码链接 🔗:https://github.com/HumanAIGC/AnimateAnyone
**3、论文链接 🔗: **https://arxiv.org/pdf/2311.17117.pdf
**4、介绍地址 🔗: **https://humanaigc.github.io/animate-anyone/
三、AnyText
AnyText 是由阿里达摩院发布的一款AI图文融合工具。
随着 AIGC 技术变得越来越受欢迎,我们看到了很多厉害的应用,它们能创造出各种各样的图片。但是,当这些图片里要包含文字的时候,人工智能有时候就会露出破绽,主要是因为它们还不够擅长在图片中准确无误地放入文字。
虽然已经有一些应用,比如Ideogram AI,能够在图片中融合文字和图像,但这些技术主要是针对英文的。中文由于字体复杂,字符数量众多,要在图片中准确生成中文文字就显得更加困难了。
AnyText是一款基于扩散(Diffusion)模型的多语言视觉文本生成与编辑工具,旨在通过隐空间辅助模块和文本嵌入模块在图像中渲染准确且连贯的文本。它支持多种语言,包括中文、英文、日文、韩文等,能够生成或编辑图像中的文本,实现高质量的文字编辑效果,包括在不规整的掩码下也能保持毫无违和感的编辑效果129。此外,AnyText还提供了图片生成和图片编辑功能,允许用户根据用户描述来生成带有文字的图片,并帮助用户改变现有图片中的文字.
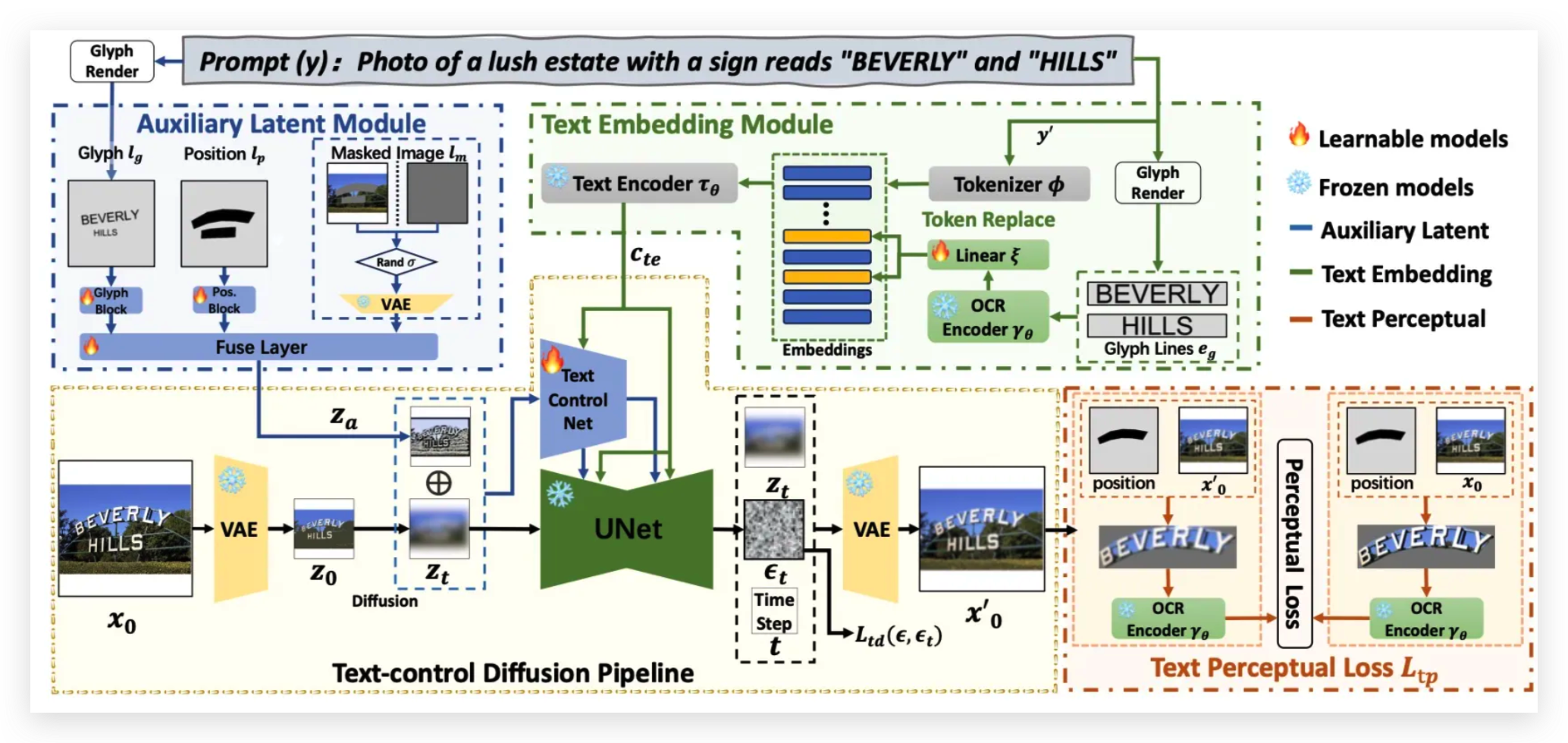
AnyText可应用于电商海报、Logo设计、创意涂鸦、表情包等场景。


1、代码链接 🔗:https://github.com/tyxsspa/AnyText
2、论文链接 🔗:https://arxiv.org/abs/2311.03054
3、目前AnyText还未上线专门的网页,用户可在魔搭社区中试用Demo,链接直达:https://modelscope.cn/studios/damo/studio_anytext/summary
四、Replace Anything
Replace Anything 是由阿里开发的一款 AI 图像内容替换框架,由阿里巴巴智能计算研究院推出。这款框架主要用于图像编辑和生成领域,其核心目标是在保持用户指定对象身份不变的同时生成新内容。Replace Anything 利用先进的人工智能技术,能够实现对照片或图像中物体的智能替换,用户可以通过简单的操作,只需框选想要保留的图像部分,输入提示词或描述来替换想要更改的图像区域,如更换人物发型、服装、背景等。
服装更换:
ReplaceAnything 的应用场景非常广泛,包括但不限于服装替换、证件照背景替换、电商领域的背景替换等。它不仅能够处理整体或局部替换,还能实现人体替换、服装替换、物体替换以及背景替换(渲染)等多种场景的替换。此外,Replace Anything 还支持上传自定义的背景图和遮罩图,以及人脸提示词,以满足需要更精确调整的场景需求。
证件照背景替换:

替换人物:

背景替换:

有了这个工具,可以替换掉要会员的美图秀秀以及繁琐的 PS 了。
1、HF 体验地址🔗:https://huggingface.co/spaces/modelscope/ReplaceAnything
2、魔塔社区体验地址🔗:https://www.modelscope.cn/studios/damo/ReplaceAnything/summary
3、项目介绍地址🔗:https://aigcdesigngroup.github.io/replace-anything/
4、代码地址🔗:https://github.com/AIGCDesignGroup/ReplaceAnything
五、Outfit Anyone
Outfit Anyone是阿里巴巴集团智能计算研究所开发的一项超高质量虚拟试穿技术,它旨在为任何服装和任何人提供虚拟试穿体验。

该技术采用双流条件扩散模型,通过处理模特、服装和文本提示,利用衣物图像作为控制因素实现更逼真的虚拟试穿效果。Outfit Anyone 不仅可以使用正常的服装,还可以结合不同的元素,如水果、漫画手绘等,为用户提供更加丰富和个性化的试穿体验。

有了这个项目,电商领域产品需要模特试穿的时代或许将会结束。他在电商、设计、甚至是购物都很方便,普通人在家里就可以体验新颖的衣物,随时随地,设计师也可以随时随地的看自己设计的衣服,搭配在不同人身上的效果,来做修改。还有电商模特的成本将会大大降低,将会加快超级个体的到来。


Outfit Anyone 目前还仅用于学术研究和效果演示,还不能用于任何商业行为,而且其中还涉及许多版权问题,想要取代电商模特们,恐怕还要等上一段时间。
1、 项目地址🔗:https://humanaigc.github.io/outfit-anyone/
2、 代码🔗:https://github.com/HumanAIGC/OutfitAnyone
3、 魔塔社区体验🔗:https://modelscope.cn/studios/DAMOXR/OutfitAnyone/summary
4、HF 体验🔗:https://huggingface.co/spaces/HumanAIGC/OutfitAnyone
六、FaceChain
FaceChain 是阿里达摩院推出的一个开源的人物写真和个人数字形象的AI生成框架,用户仅需提供最低一张照片或三张照片即可生成独属于自己的个人形象数字替身。

该工具基于扩散模型的图像生成能力,结合 LoRA 训练实现人像和风格融合,并叠加一系列后处理能力,实现兼具相似度、真实感、美观度的写真生成能力157。FaceChain支持在gradio的界面中使用模型训练和推理能力,也支持资深开发者使用python脚本进行训练推理25。此外,FaceChain还能够生成多种风格的个人写真,包括汉服风、工作照、芭比娃娃、校服风、圣诞风、绅士风、漫画风等,满足用户多样化的个性化需求。
魔塔社区🔗:https://www.modelscope.cn/brand/view/FaceChain
HF 地址🔗:https://huggingface.co/spaces/modelscope/FaceChain
论文🔗:https://arxiv.org/abs/2308.14256
代码🔗:https://github.com/modelscope/facechain/tree/main
七、VGen-XL
阿里的 VGen-XL 是一款由阿里通义实验室开发的开源视频生成模型和代码系列,它能够从单张图片生成高质量视频。和 Sora 不同的是,他目前必须是先有图片才能生成视频。 VGen-XL的特点包括高清(1280×720)、宽屏(16:9)、时序连贯和质感好的视频生成能力7。此外,VGen还支持根据用户输入的静态图像和文本生成目标接近、语义相同的视频,生成的视频具有高清(1280 * 720)、宽屏(16:9)、时序连贯、质感好等特点。
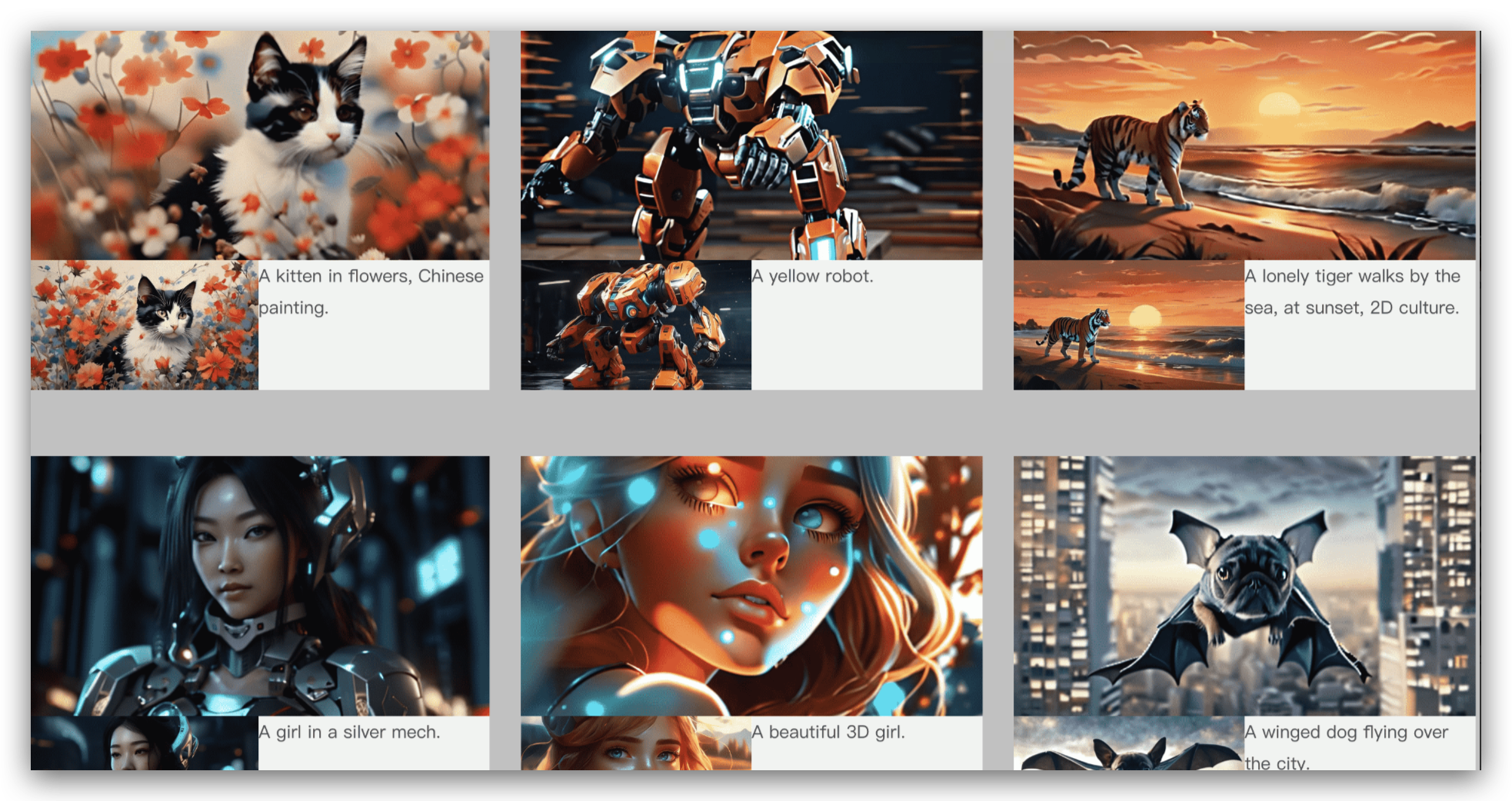
HF 地址:https://huggingface.co/spaces/modelscope/I2VGen-XL
魔塔社区 🔗:https://www.modelscope.cn/studios/damo/I2VGen-XL-Demo/summary
代码链接🔗:https://github.com/ali-vilab/i2vgen-xl
项目地址🔗:https://i2vgen-xl.github.io/
八、Animate 3D Motion
阿里的 Animate 3D Motion是一个** AI 角色动画模型,由阿里通义实验室XR实验室研发。它能够将视频中的角色替换为3D角色**,这些替换的3D角色能完整复刻原视频中人物的动作,保持动作一致。Animate 3D Motion的官方项目主页为:https://aigc3d.github.io/motionshop/。

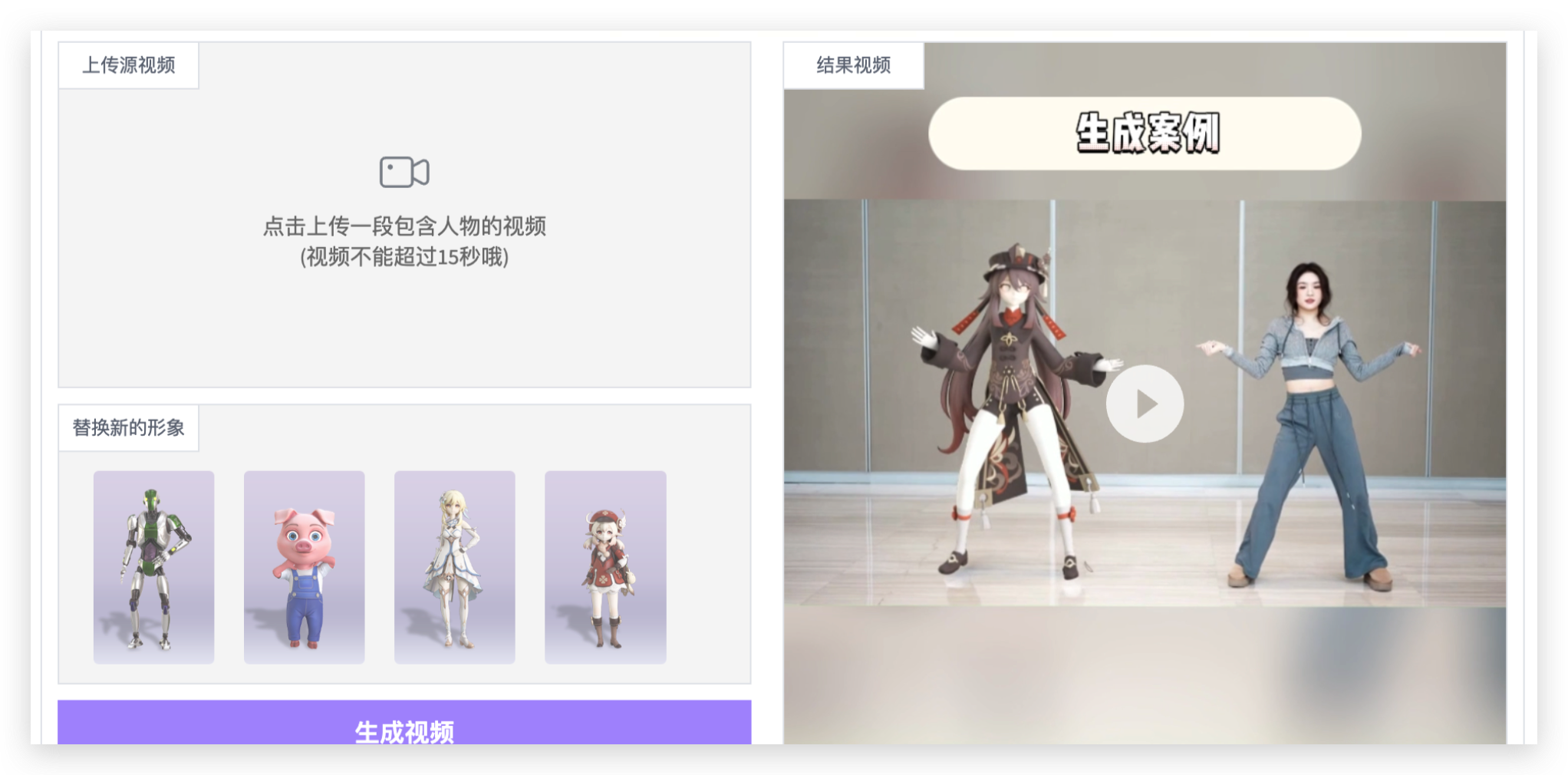
项目地址🔗:https://aigc3d.github.io/motionshop/
魔塔社区🔗:https://www.modelscope.cn/studios/Damo_XR_Lab/motionshop/summary
真没想到阿里一下子推出了这么多实用的 AI 工具,虽然国外的 AI 发展速度更快,但我相信,国内的领军企业如阿里,定能承担起推进国内 AI 发展的重任,加速其发展步伐。
如果你也喜欢 AI,如果你也关注提效,欢迎关注苍何,加入免费知识星球:,一同交流 AI,探讨提效。

创作不易,如果本文对你有帮助,欢迎点赞、收藏加关注,你的支持和鼓励,是我创作的最大动力。

版权归原作者 程序员苍何 所有, 如有侵权,请联系我们删除。