
前言
相信大家对dpo都比较熟悉了,今天给大家介绍一篇dpo的变种step-dpo。
数学任务相比于其他任务有着明显的不同,其每一步step的推理都必须准确无误,不然一步错步步错,传统的dpo算法是以单个样本进行整体优化的,很难捕捉到每一步的推理细节,为此本篇文章提出了step-dpo,既然要进行dpo而且还是step级别的,那必然就需要相关的细粒度数据,作者也给出了相应的做数据pipeline。
其主要效果

论文链接:
https://arxiv.org/pdf/2406.18629
github链接:
https://github.com/dvlab-research/Step-DPO
方法
- STEP-WISE FORMULATION
dpo是直接将整个response作为chosen-rejected来进行优化的,但是这就可能导致一个问题那就是:假设rejected错样本推理步骤一共是4步,前三步其实都是正确的,只是最后一步出错了,那么被当作错样本优化时(最小化)前三步会被一并最小化,这显然是不合理的,而step的出发点就是去掉前三步的loss,只计算最后一步的loss。
dpo和step-dpo用公式来定义区别的话就是:
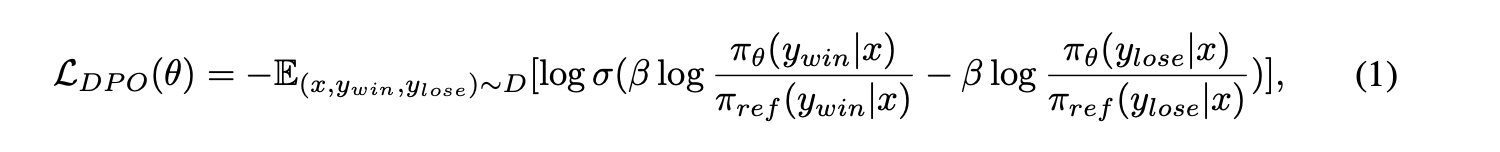
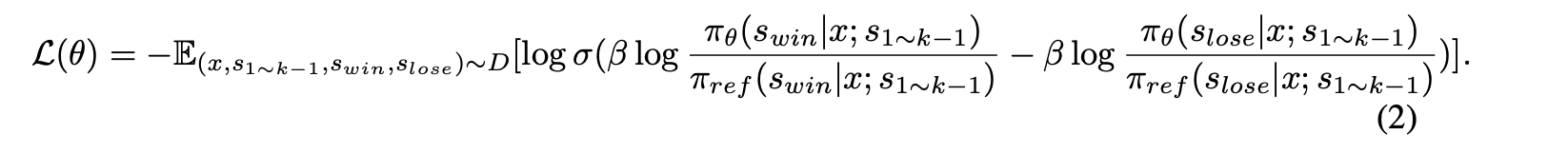
可以看到对于step-dpo,其前k-1 step之前都不计算loss了,只计算具体出错那一step。
举一个具体的例子就是:

其中initial_reasoning_steps就是前k-1步。
- IN-DISTRIBUTION DATA CONSTRUCTION
这里就是怎么来做step-dpo数据,如上一节图所示,其每一条样本是一个四元组(prompt, initial-reasoning-steps, preferred-reasoning-step, undesirable-reasoning-step)
具体来说其一共分为三步
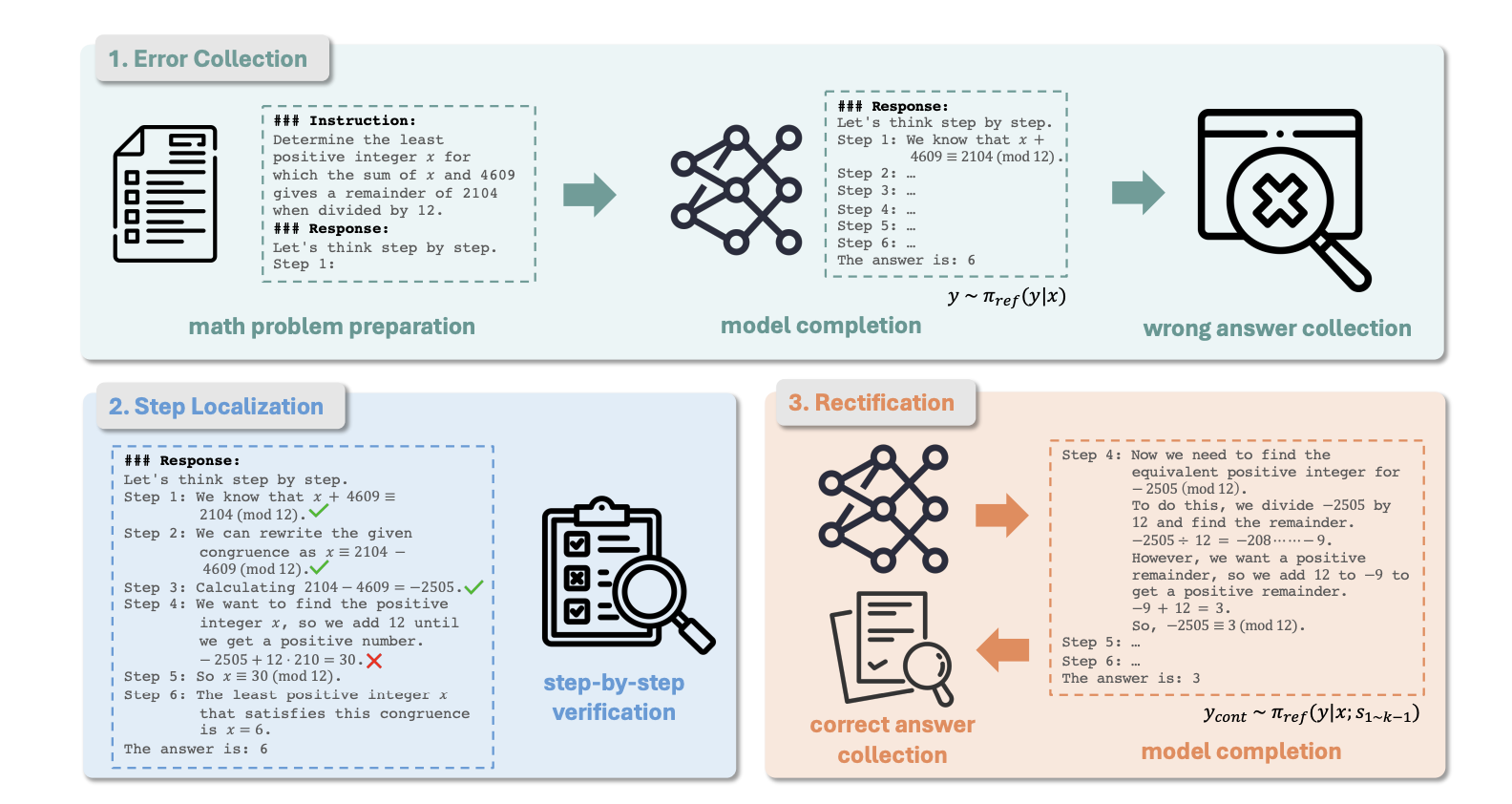
(1)Error collection
作者先使用ref model(待训练的模型)去推理训练数据中的prompt得到答案,为了得到和便于解析每一步的推理,这里使用了一个简单的提示工程"Let’s think step by step. Step 1:",这样就可以精确的得到一一步步推理了。然后选取最终答案和正确答案不一样的数据作为后续dpo的候选数据
(2) Step localization
通过上面,我们现在已经得到了错题样本集合,最终答案既然错了,必然其中是有一步推理是错了,这里可以通过人工或者gpt4来发现第一次出错的推理step。
(3) Rectification
现在有了(prompt, initial-reasoning-steps, undesirable-reasoning-step),还差一个对应的正确推理步骤即preferred-reasoning-step。作者采用的方案是使用prompt以及之前对的推理步骤作为新的上下文给到red model进行多次采样推理,从中筛选出最终答案对的作为preferred-reasoning-step。
同时作者也强调了说即使最终答案对了,也不一定代表当前的推理step就是对的,于是需要进一步使用人工或者gpt4进行一遍过滤。
同时作者也强调了在获得preferred-reasoning-step这里使用ref model自身的最好,因为这是in-distribution的,比直接使用gpt4或者人工这种out-of-distribution的会更好一些。
实验
先来一个全局直观图

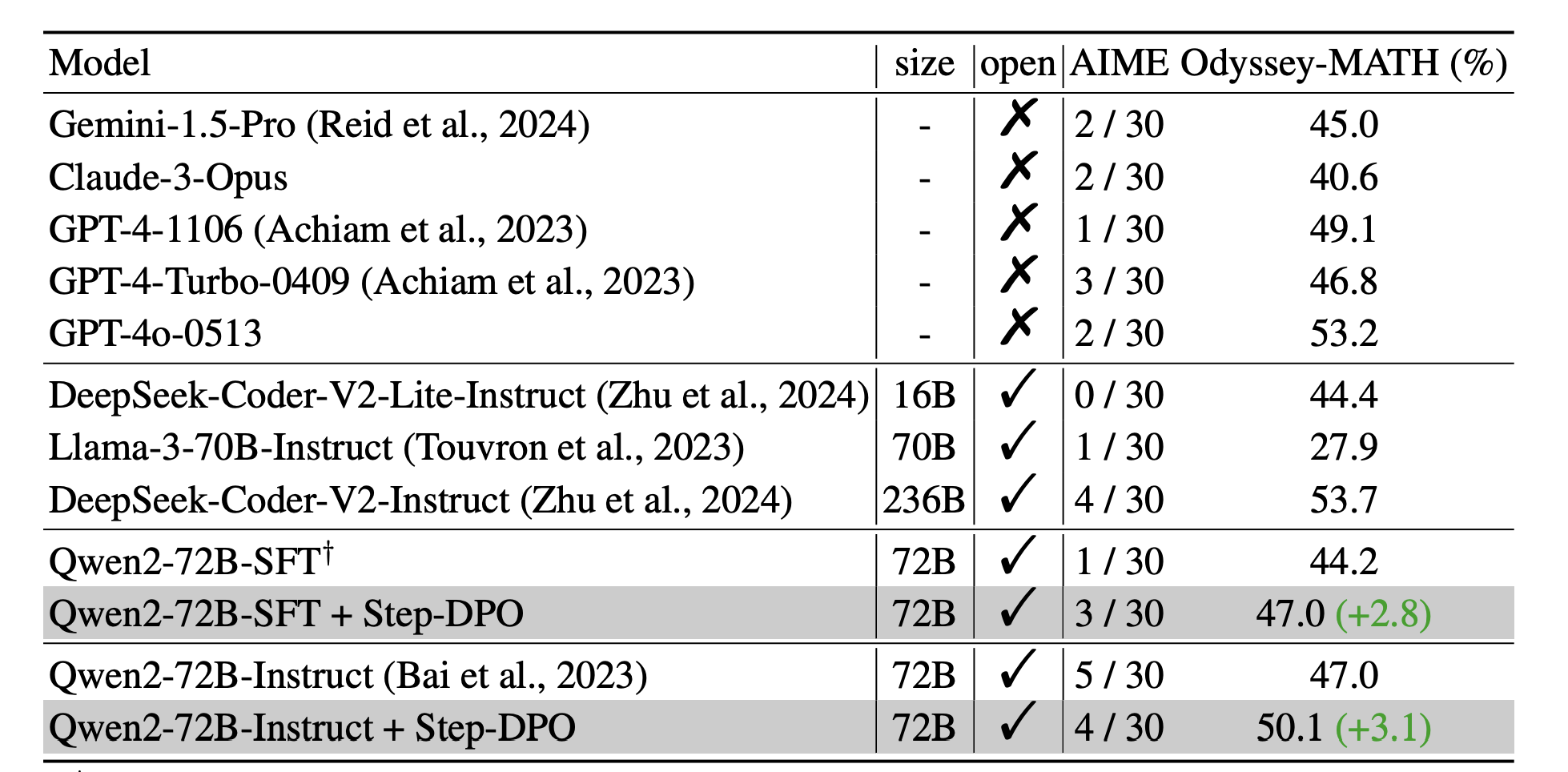
同时作者也消融了一下和dpo的对比

可以看到在越大的size模型规模上,step-dpo带来的增益越大

也做了一个in-distribution和out-of-distribution的对比,可以看到in-distribution还是稍微好一些。
不过从所有指标来看,提升其实不是特别特别大。
总结
(1) 对于需要长cot思维链且每一步都至关重要的任务,step-dpo相比于其他的dpo算法应该是能更好发挥其性能的,因为其主打的就是step,天然这么设计的,所以在代码领域理论上也应该适合step-dpo,因为每一步code都不允许出错。就文章实现来说其实就是把更多的response放到了prompt里面,只训练局部loss。
(2) 可以看到带来一部分收益的同时,也付出了相比于dpo更精细化做数据的pipline,相比于sft,dpo等系列算法就目前来看带来的收益其实不是非常质的提升,不光光是在数学方面,最起码其不是那么容易,不像做sft,随便一做都能快速看到效果。
(3) 对于这些offline的rl算法,不论是dpo还是dpo的各种变种(比如ropo、simpo以及今天介绍的step-dpo等等),其实核心的工作是怎么做pair数据,怎么做出当前你自己业务或者任务的pair数据是最值得思考的。你自己的场景什么是good case,什么是bad case甚至说怎么挖掘好难样本都是值的思考的。同理对于RLHF这些online算法最难的就是reward model怎么训练。所以说做大模型强化学习核心的难点或者核心壁垒是:清晰定义出当前什么是好和坏,然后思考怎么进一步来对其挖掘或者量化。做不好这个工作,基本上没啥效果。
关注
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号
版权归原作者 weixin_42001089 所有, 如有侵权,请联系我们删除。