
每一个不曾起舞的日子都是对生命的辜负

C++之模板初阶
本节目标
- 1. 泛型编程
- 2. 函数模板
- 3. 类模板
1. 泛型编程
我们思考一下,如何实现一个通用的交换函数呢?
首先想到的就是函数重载,即:
voidSwap(int& left,int& right){int temp = left;
left = right;
right = temp;}voidSwap(double& left,double& right){double temp = left;
left = right;
right = temp;}voidSwap(char& left,char& right){char temp = left;
left = right;
right = temp;}......
事实上当然可以,然而函数重载却有几个不好的地方:
- 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数。
- 代码的可维护性比较低,一个出错可能所有的重载均出错
因此,为了防止并优化以上情况,我们引入了泛型的函数模板

如果在C++中,也能够存在这样一个模具,通过给这个模具中填充不同材料(类型),来获得不同材料的铸件(即生成具体类型的代码),那将会节省许多头发。巧的是前人早已将树栽好,我们只需在此乘凉。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段,模板是泛型编程的1基础。
2. 函数模板
2.1 函数模板的概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
因此,这里引入了一个新的关键字:
template
template<typename T>voidSwap(T& left, T& right){
T temp = left;
left = right;
right = temp;}intmain(){int a =1, b =2;Swap(a, b);char x ='a', y ='b';Swap(x, y);return0;}

通过
template<typename T>
就可以将T设置成泛型,即传入哪种参数就可以变为哪种参数。
注意:
typename是用来定义模板参数关键字,也可以使用
class
2.2 函数模板的原理
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器
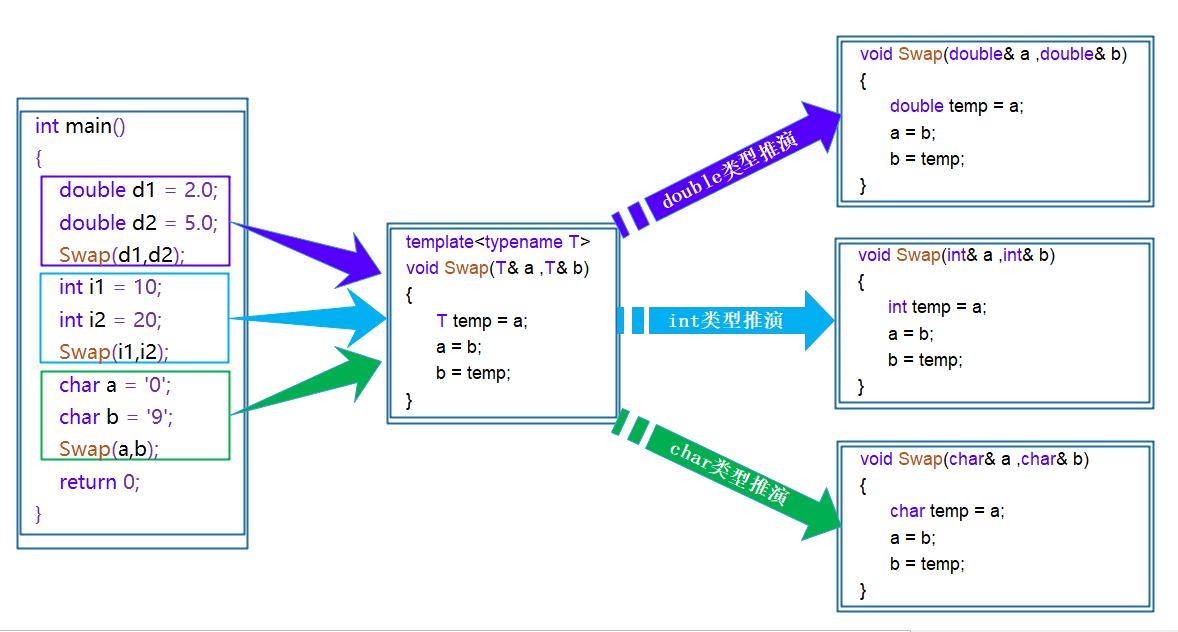
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
template<typename T>voidSwap(T& left, T& right){
T temp = left;
left = right;
right = temp;}intmain(){int a =1, b =2;Swap(a, b);char x ='a', y ='b';Swap(x, y);int m =1, n =2;Swap(m, n);return0;}
那么对于相同类型的参数,会不会重新建立栈帧呢?
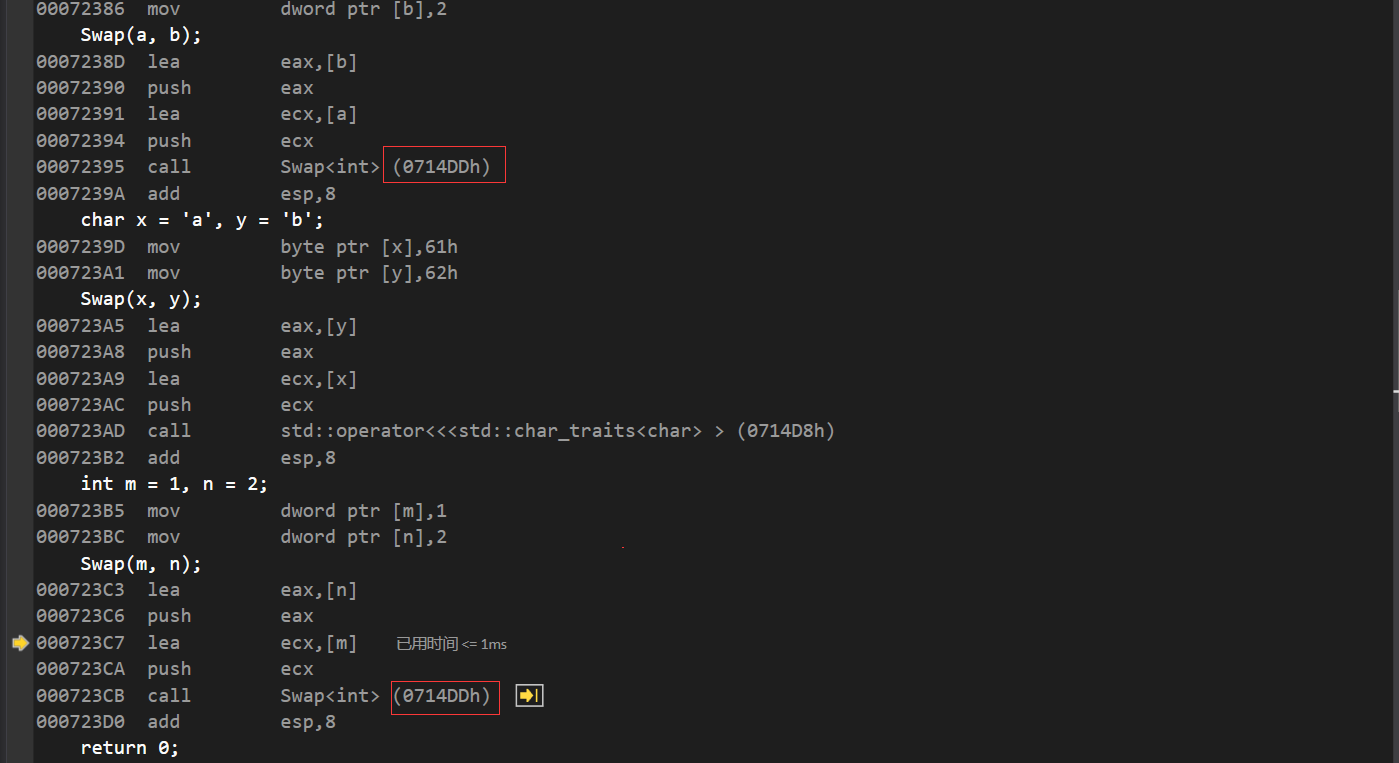
当我们转到反汇编,发现两次调用的int类型的Swap都是同一个地址,这就意味着在第一次模板调用完int类型的Swap之后,此类型的Swap并没有被销毁,仍然是之前的地址,所以我们发现,通过模板建立的函数与正常的函数调用是相同的:
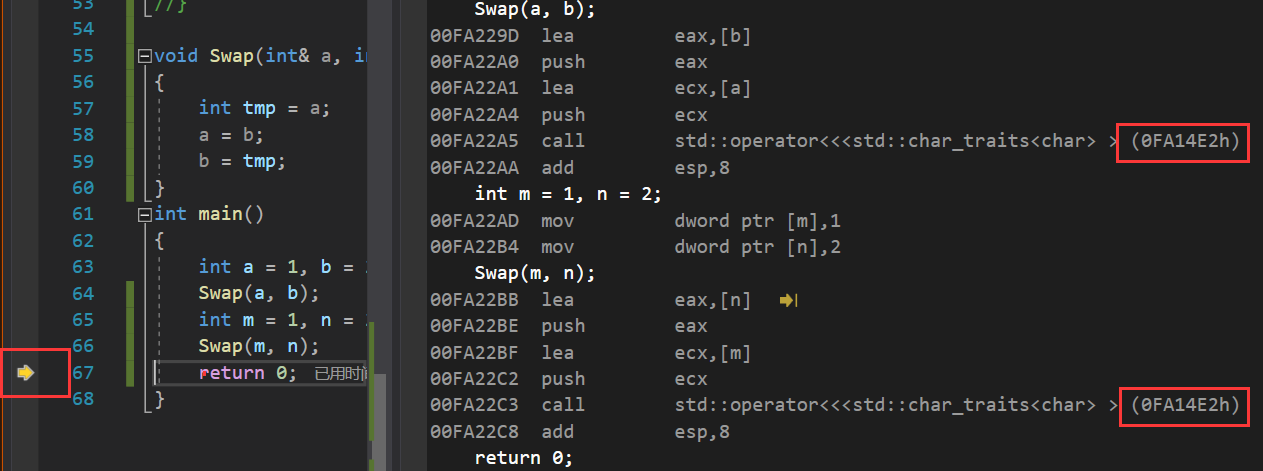
即两种函数调用都是该函数的机器指令被存放在代码段中,对于函数模板来说:我们使用相同类型的参数多次调用同一模板函数时,也只会实例化一个模板。因此同一函数被执行多次都是调用同一段指令,然后在不同的栈帧执行该指令(即在不同的子函数开辟的栈帧调用此函数)
代码段放的是编译后的指令,因此在我们转到反汇编之前都会调试,目的就是让其进行编译。
2.3 参数类型不同的模板调用
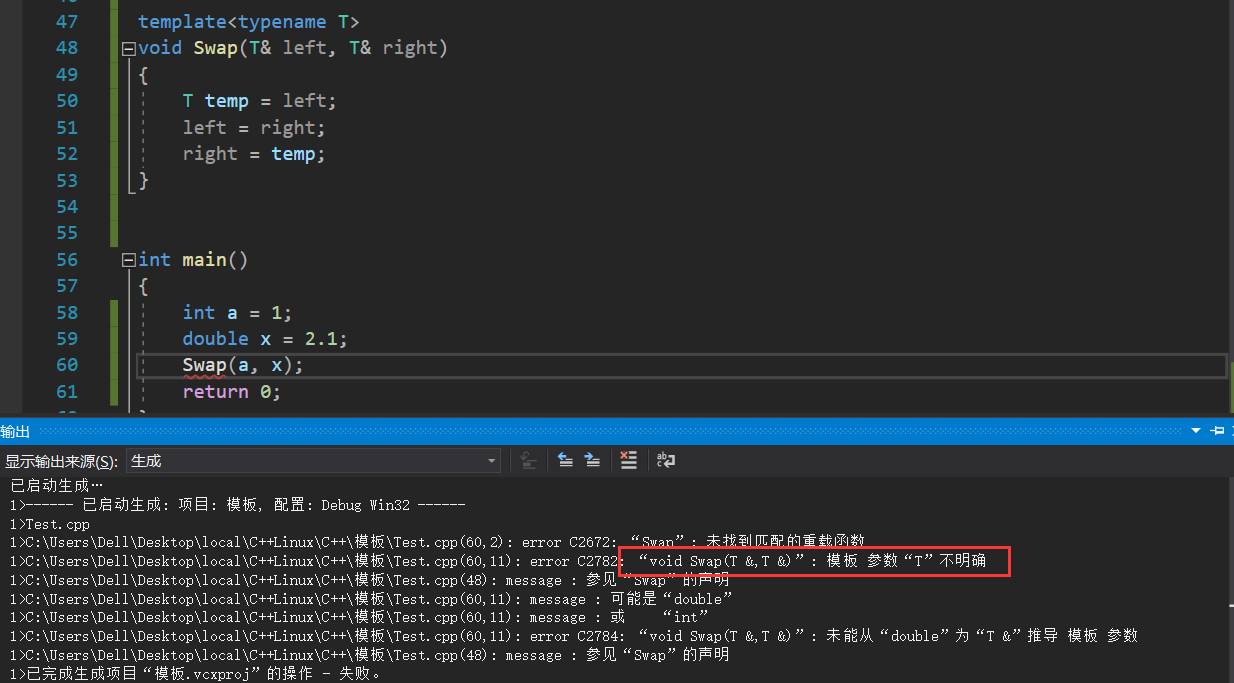
不同类型的参数,我们在调用函数之前就会出错,因此不存在隐式类型转换这一步骤,因为调用之前函数模板会根据传进去的参数进行推演函数,但对于传入不同类型的参数,由于模板中的两个参数类型相同,在推演的过程中就会出错。即便不需要推演,直接调用:
void Swap(int& left, int& right)
同样会出错,因为x类型不匹配,因此会发生隐式类型转换,但由于隐式类型转换的变量具有常性,也就是
const int
类型,传入就会涉及权限的放大,故即便不经过推演也会出错。
那么我们可以怎样解决这个问题呢?
2.3.1. 实例化时进行改变
首先我们可以采用下面的两种方法:(const修饰可以进行隐式类型转换)
template<class T>
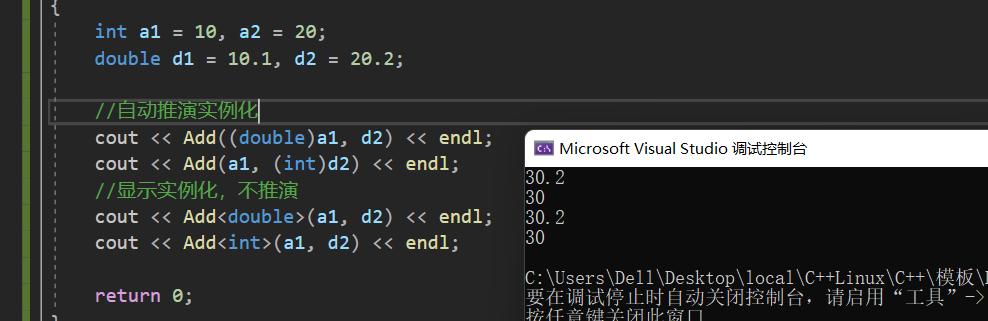
T Add(const T& left,const T& right){return left + right;}intmain(){int a1 =10, a2 =20;double d1 =10.1, d2 =20.2;//自动推演实例化
cout <<Add((double)a1, d2)<< endl;
cout <<Add(a1,(int)d2)<< endl;//显示实例化,不推演
cout << Add<double>(a1, d2)<< endl;
cout << Add<int>(a1, d2)<< endl;return0;}
- 自动推演实例化: 我们在推演之前将原本的类型进行了强制类型转换,这样类型就会统一,虽然隐式类型转换的变量具有常性,但函数模板的参数也是const类型的,因此这种方式可以解决。
- 显示实例化: 在调用函数的时候,我们发现其中已经指定了T的类型,这就代表着指定了这个函数模板的类型,因此会省去推演的步骤,在传参的过程中就会强转临时变量,这与上述一样是可以的。
但是这样的方式过于麻烦,即我们需要的是在函数模板本身进行修改,而不是为了编译成功而修改传入参数的类型。
2.3.2 模板参数数量改变
经过上面的研究,我们发现在调用函数时稍加改动才可以进行编译,这都是因为函数模板中参数类型一致造成的,因此在这里我们采用将参数类型隔离开:
template<class T1, class T2>
T1 Add(const T1& left,const T2& right){return left + right;}intmain(){int a1 =10, a2 =20;double d1 =10.1, d2 =20.2;
cout <<Add(a1, a2)<< endl;
cout <<Add(d1, d2)<< endl;
cout <<Add(a1, d2)<< endl;
cout <<Add(a1, d2)<< endl;return0;}
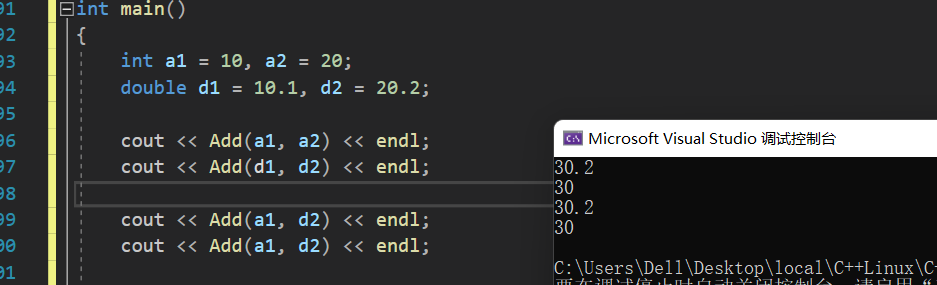
即此方法才是解决此问题的最好方式。
2.3.3 具体函数&模板函数
对于模板函数和具体函数,如果同时定义会不会产生冲突呢?
//专门处理int的加法函数intAdd(int x,int y)// _Z3Addii{return x + y;}//通用加法函数
template<class T>
T Add(T left, T right)// _Z3TAddii{return left + right;}intmain(){int a =1, b =2;
cout <<Add(a, b)<< endl;return0;}
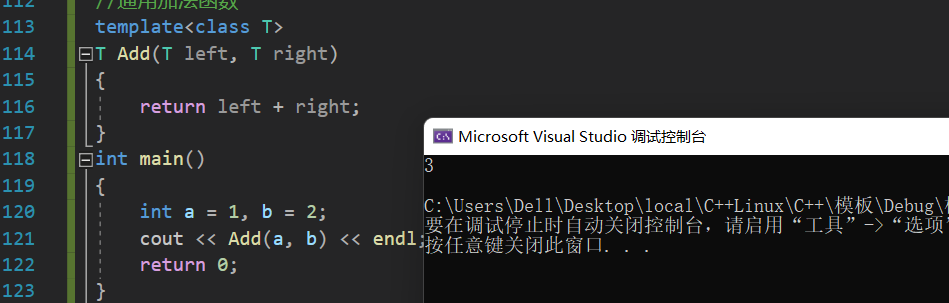
通过执行程序发现,其并不会产生冲突。
对于具体函数和函数模板来说,前者算完成品,后者算半成品,因此编译器为了节省成本会优先使用完成品,因此不会产生冲突。
我们也可以通过实例化指定调用模板函数:
//专门处理int的加法函数intAdd(int x,int y){return x + y;}//通用加法函数
template<class T>
T Add(T left, T right){
cout <<"调用模板T"<< endl;return left + right;}intmain(){int a =1, b =2;
cout << Add<int>(a, b)<< endl;return0;}
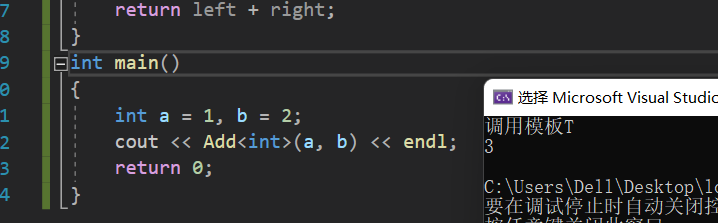
即通过上述两个方式,我们可以得出具体函数和模板函数是可以共存的,可以共存就说明其函数名的修饰规则是不同的。
3. 类模板
对于类来说,我们拿Stack类举例,其存储内容的内部成员的类型可以是int可以是double,我们可以根据需求将其
typedef 类型STDatatype,但如果这样的话,我们要是想同时用一个栈存储int变量,另一个栈存储double变量,这就需要重新建立另一个类,即前者类为StackInt,后者命名为StackDouble,但是这样会造成不小的负担,因此我们引入类模板。
3.1 类模板的定义格式
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类。
template<typename T>
class Stack//注:此Stack类并不完美,但对于演示来说,Stack是否完美并不重要{
public:Stack(int capacity =4){
cout <<"Stack(int capacity = )"<<capacity<<endl;
_a =(T*)malloc(sizeof(T)*capacity);if(_a == nullptr){perror("malloc fail");exit(-1);}
_top =0;
_capacity = capacity;}voidPush(const T& x)//对于这里引用来说,是最好的,因为如果x本身是类,传值就会调用拷贝构造,传引用有效的避免了这种情况{// ....// 扩容
_a[_top++]= x;}
private:
T* _a;int _top;int _capacity;};intmain(){
Stack<int> st1;
st1.Push(1);
Stack<double> st2;
st2.Push(2.1);return0;}
我们发现这样可以更好的定义存储不同类型的两个栈对象st1和st2。对于类模板来说,必须实例化才能在定义时去推演指定的类,如果不在初始化时推演就会报错:
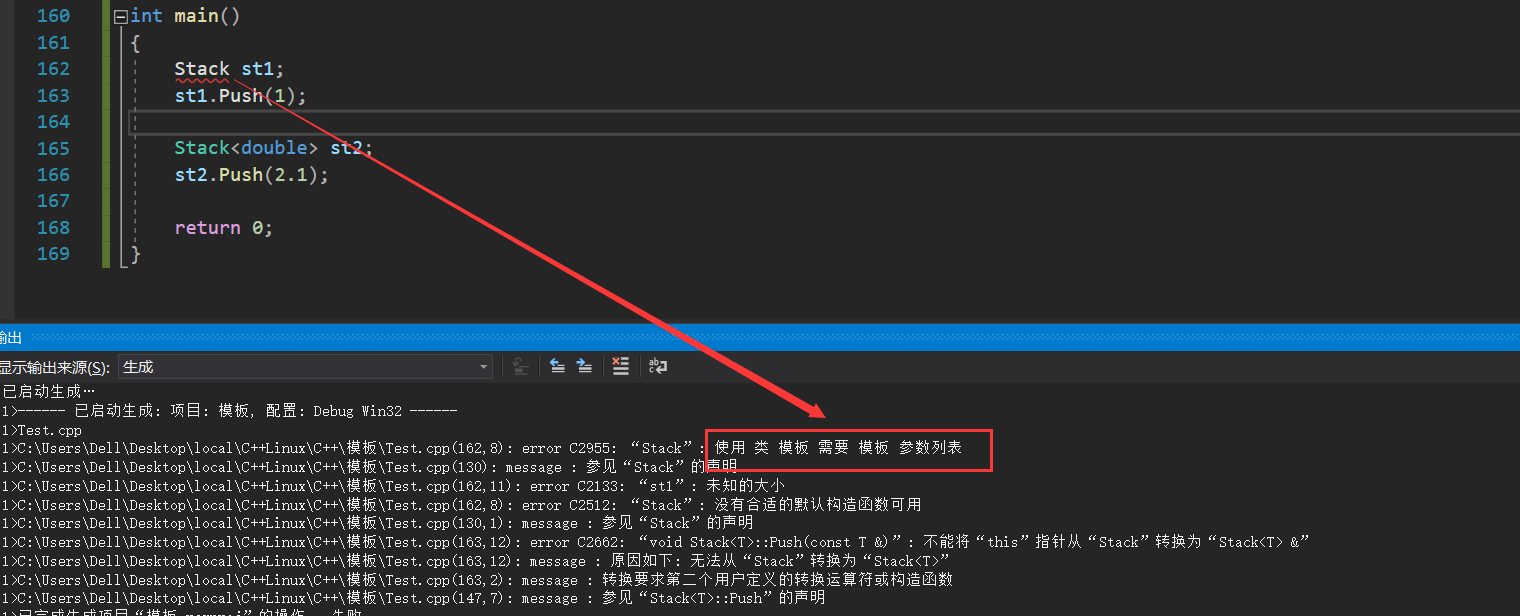
这是因为在初始化时会自动调用构造函数的初始化列表,因此在初始化我们就必须明确具体类型,否则无法进行初始化。
3.2 类模板的示例array
在这里直接上代码:
#defineN10
template<class T>
class array
{
public://通过inline可以减少栈帧的损失inline T& operator[](size_t i)//传引用的优势在这里体现,可以修改{assert(i < N);//强制检查越界return _a[i];}
private:
T _a[N];};intmain(){
array<int> a1;for(size_t i =0; i < N; i++){
a1[i]= i;//等价于 a1.operator[](i) = i;}for(size_t i =0; i < N; i++){//a1.operator[](i)
cout << a1[i]<<" ";}
cout << endl;for(size_t i =0; i < N;++i){
a1[i]++;}for(size_t i =0; i < N; i++){//a1.operator[](i)
cout << a1[i]<<" ";}return0;}
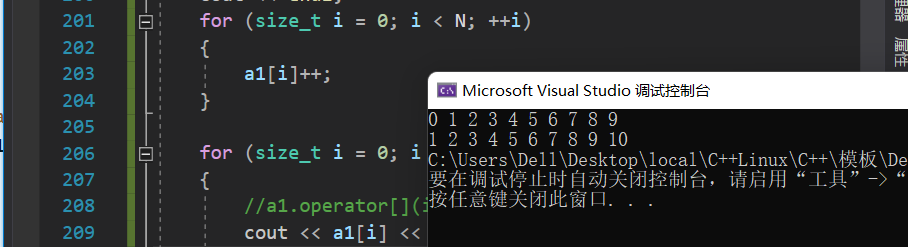
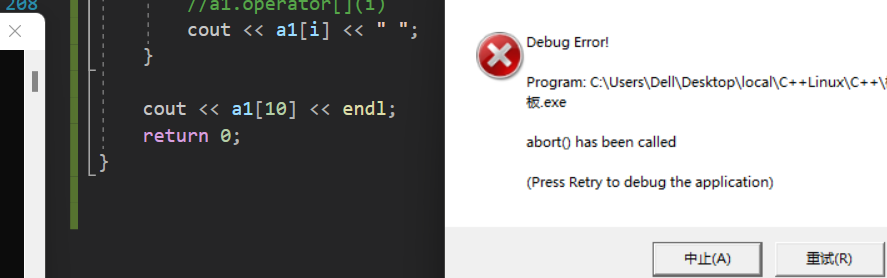
对于此array(静态数组)类,我们可以从中看出其与正常定义数组的优势,对于正常定义的数组,越界访问或许检查不到错误,比如越界读:
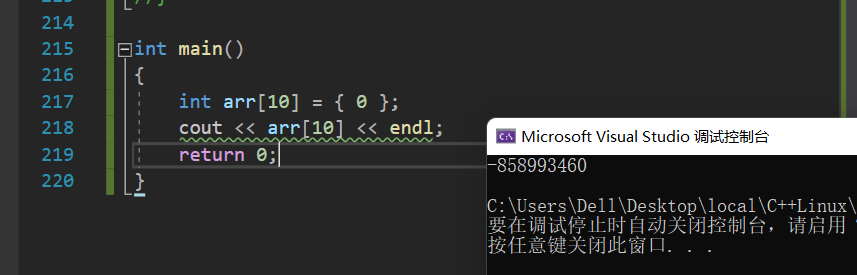
但对于我们自定义的类来说,通过
assert(i<N)
的强制检查,就可以有效的避免这个问题。
4. 模板初阶的总结
以上就是我们这一节所需要掌握的内容。通过以上模板,可以极大地减少代码的负担,从而使我们的代码变得更加完美。
版权归原作者 每天都要进步呀~ 所有, 如有侵权,请联系我们删除。