
文章目录
提示:本项目分析仅用来学习使用
一、项目背景
作为中国最受欢迎的在线旅游平台(OTP)之一,阿里巴巴集团旗下的飞猪通过提供百万级旅游相关产品(如机票、酒店、旅行团、 ETC)。平台拥有庞大的产品组合,平台积累用户的行为数据,该数据集是用户脱敏行为数据,包含基本属性用户信息和商品基本属性的脱敏信息。
1.1数据来源
阿里云天池数据集:飞猪出行平台用户行为数据推荐
1.2数据介绍
数据由三部分组成:用户历史行为脱敏数据、用户基础属性脱敏数据、商品基础属性脱敏数据。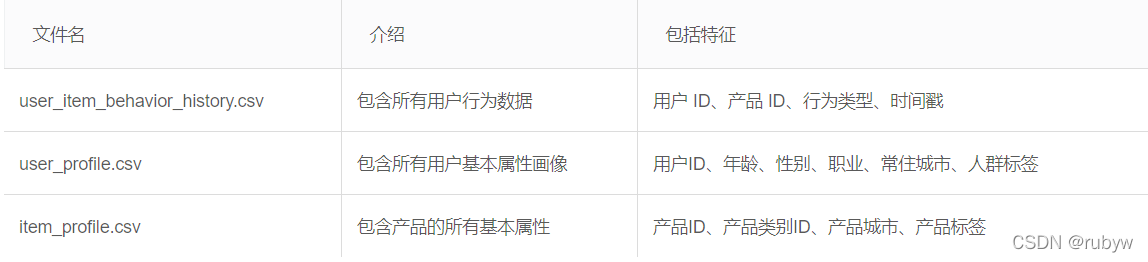
**
行为类型:('clk', 'fav', 'cart','pay')
**
user_item_behavior_history.csv
该数据集涵盖了2019年6月3日至2021年6月3日这两年期间约200万随机用户的所有行为(包括点击、收藏、添加和购买)。数据集的组织类似于MovieLens-20M,即每一行集合代表一个用户数据行为,由用户ID、产品ID、行为类型、日志组成。每列总结了被调查产品的详细信息。
原数据集共2亿多数据,本项目只选取了2021年5月3日至2021年6月3日一个月接近8000,000的数据。
user_profile.csv
该数据集主要包含约五百万随机用户的基本属性,如年龄、性别、职业、居住城市ID、人群标签等。数据集的每一行代表一条用户信息,以逗号分隔。
item_profile.csv
该数据文件主要包含约27万个产品的基本属性特征,如产品类别ID、产品城市、产品标签等。数据集的每一行代表一个产品的信息,以逗号分隔。
二、分析目的
目标是从用户的行为数据中挖掘当前用户的行为特征,通过分析这些特征能够发现平台当前所面临的一些问题并分析原因,从而能出台一些针对性的解决措施,扩大用户的使用转化率。
三、分析思路
- 用户维度-pv/uv/pay:总量、平均人均(日期、时刻、星期)-留存分析:次日、三日、五日、七日、十五日、三十日(用户粘度)-用户画像:年龄、性别、职业、区域分布
- 行为维度-复购率和跳失率情况-用户行为转化率情况-用户行为在时间上的分布
- 商品维度-热门商品分析:点击、收藏、加购、购买前十-商品购买路径分析:点击、收藏、加购——购买(转换率分析)-商品画像:种类、地域、标签分布
四、数据分析
3.1数据清洗
导入数据’user_item_behavior_history.csv’
# 增加列名'user_id', 'item_id', 'behavior_type','timestamp'
reader = pd.read_csv('./data/user_item_behavior_history.csv', header=None, names =['user_id','item_id','behavior_type','timestamp'], iterator=True)# 使用get_chunk方法获取数据
loop =True
chunkSize =10000000# 设置chunksize
chunks =[]import datetime
# start time
starttime = datetime.datetime.now()# long runningwhile loop:try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)except StopIteration:
loop =Falseprint("Iteration is stopped.")# 迭代完成# 拼接chunks
df = pd.concat(chunks, ignore_index=True)# end time
endtime = datetime.datetime.now()# 共计数据获取时间print('loop_time:',(endtime - starttime).seconds)
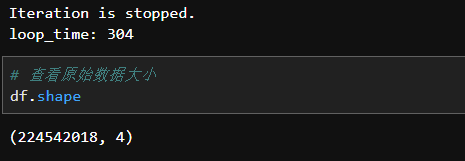
原数据共计获取时间为304秒,也就是5分钟左右,数据共计2亿多行。
# timestamp转为datetime
df['timestamp']= pd.to_datetime(df['timestamp'], unit='s')# 查看前五行数据
df.head()
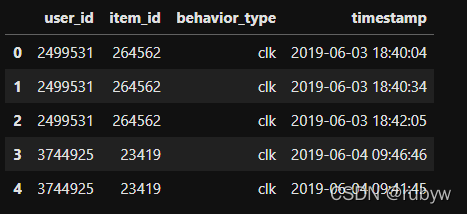
获取分析数据
start_date = pd.to_datetime('20210503',format='%Y-%m-%d %H:%M:%S')# 开始日期
end_date = pd.to_datetime('20210604',format='%Y-%m-%d %H:%M:%S')# 截止时间
df = df[(df['timestamp']>= start_date)&(df['timestamp']<= end_date)]
df = df.sort_values(by='timestamp', ascending=True)# 时间按升序排列
df = df.reset_index(drop=True)# 重置索引
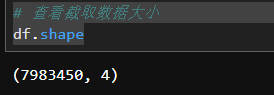
分析的数据共计7,983,450行

由此可见,此时的数据没有缺失值和异常值;
而重复数据在这里是正常的,因为用户是可能在同一时间进行多次相同行为的,所以对重复数据不做处理。
# 把列'nehavior_type'中的'clk','fav','cart','pay'替换为1,2,3,4'''
1——点击
2——收藏
3——加购
4——购买
'''
replace_values ={'clk':1,'fav':2,'cart':3,'pay':4}
df['behavior_type']= df['behavior_type'].replace(replace_values)
# 时间格式转换,获取日期、时间、年、月、日、周几、小时
df['date']= df['timestamp'].dt.date
df['time']= df['timestamp'].dt.time
df['year']= df['timestamp'].dt.year
df['month']= df['timestamp'].dt.month
df['day']= df['timestamp'].dt.day
df['weekday']= df['timestamp'].dt.strftime("%w")
df['hour']= df['timestamp'].dt.hour

3.2用户分析
从用户维度和行为维度两个维度去分析
3.2.1用户维度
3.2.1.1浏览量pv、访客量uv、成交量分析
总量
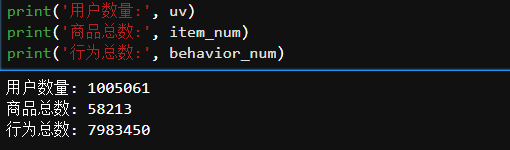
uv = df['user_id'].nunique()# 用户数量uv
item_num = df['item_id'].nunique()# 商品数量
behavior_num = df['behavior_type'].count()# 行为总数
clk_data = df[df['behavior_type']==1]# 点击数据
fav_data = df[df['behavior_type']==2]# 收藏数据
cart_data = df[df['behavior_type']==3]# 加购数据
pay_data = df[df['behavior_type']==4]# 支付数据

由以上得到的数据可以知道:点击>加购>收藏>支付
所以转化路径应为:点击—加购—收藏—支付
这里的点击clk相当于浏览pv
page_view =len(clk_data)# 总浏览量
pay_num =len(pay_data)# 总支付量
pv_avg =round(page_view/uv,2)# 总平均浏览量
pay_avg =round(pay_num/uv,2)# 总平均支付量

在这一个月内,总体来看,在1005061个用户中,平均每个人浏览7.19次,支付率为22%,说明用户活跃度不高且支付转化率不高。
日均
# 日访问量
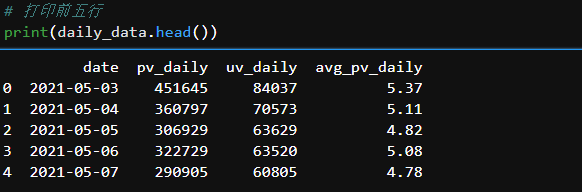
pv_daily = clk_data.groupby('date')['user_id'].count().reset_index().rename(columns={'user_id':'pv_daily'})# 日访客量
uv_daily = df.groupby('date')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv_daily'})# 拼接
daily_data = pd.merge(pv_daily, uv_daily, how='outer', on='date')# 日平均访问量
daily_data['avg_pv_daily']=round(daily_data['pv_daily']/daily_data['uv_daily'],2)
# 日成交量
pay_daily = pay_data.groupby('date')['user_id'].count().reset_index().rename(columns={'user_id':'pay_daily'})# 拼接
daily_data = pd.merge(daily_data, pay_daily, on='date')# 日平均成交量
daily_data['avg_pay_daily']=round(daily_data['pay_daily']/daily_data['uv_daily'],2)

# 创建图形
fig = plt.figure(figsize=(20,8),dpi=80)
plt.grid(True, linestyle="--", alpha=0.5)
ax1 = fig.add_subplot(111)
ax1.plot(daily_data.date, daily_data.avg_pv_daily, label='日平均访问量')
ax1.set_ylabel('日平均访问量')
ax1.set_title('daily_data', size=15)
ax1.legend(loc='upper left')
ax2 = ax1.twinx()# 共享x轴
ax2.plot(daily_data.date, daily_data.avg_pay_daily,'r', label='日平均成交量')
ax2.set_ylabel('日平均成交量')
ax2.set_xlabel('日期', size=15)
ax2.legend(loc='upper right')
plt.show()

每天的人均访问量从上半月急剧下滑,到下半月持续走低,直至月底31号跌倒谷底,然后又突然上升;
每天的人均成交量从月初直线下降,然后缓慢回升,直至月底31号达到顶峰,随后突然回落。
时均
# 每小时访问量
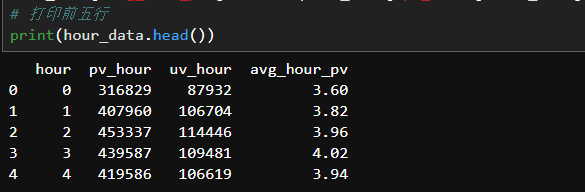
pv_hour = clk_data.groupby('hour')['user_id'].count().reset_index().rename(columns={'user_id':'pv_hour'})# 每小时访客量
uv_hour = df.groupby('hour')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv_hour'})# 拼接
hour_data = pd.merge(pv_hour, uv_hour, how='outer', on='hour')# 每小时平均访问量
hour_data['avg_hour_pv']=round(hour_data['pv_hour']/hour_data['uv_hour'],2)
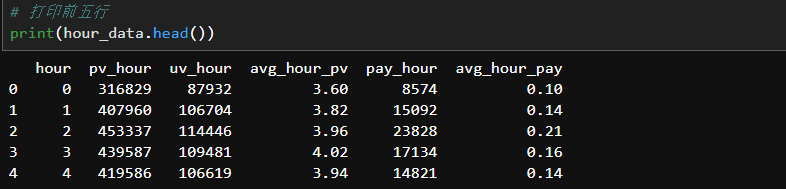
# 每小时成交量
pay_hour = pay_data.groupby('hour')['user_id'].count().reset_index().rename(columns={'user_id':'pay_hour'})# 拼接
hour_data = pd.merge(hour_data, pay_hour, on='hour')# 每小时平均成交量
hour_data['avg_hour_pay']=round(hour_data['pay_hour']/hour_data['uv_hour'],2)
# 创建图形
fig = plt.figure(figsize=(20,8),dpi=80)
plt.grid(True, linestyle="--", alpha=0.5)
ax1 = fig.add_subplot(111)
ax1.plot(hour_data.hour, hour_data.avg_hour_pv, label='每小时平均访问量')
ax1.set_ylabel('每小时平均访问量')
ax1.set_title('hour_data', size=15)
ax1.legend(loc='upper left')
ax2 = ax1.twinx()# 共享x轴
ax2.plot(hour_data.hour, hour_data.avg_hour_pay,'r', label='每小时平均成交量')
ax2.set_ylabel('每小时平均成交量')
ax2.set_xlabel('时刻', size=15)
ax2.legend(loc='upper right')
plt.show()

每时刻的人均访问量从零点开始上升,在凌晨3点之后缓慢回落,在12点之后又开始一直上升,直至下午2点达到顶点,之后急剧下降;
每时刻的人均成交量从零点开始上升,在凌晨3点达到顶点,之后不断回落,在中午12点之后急剧下滑。
周均
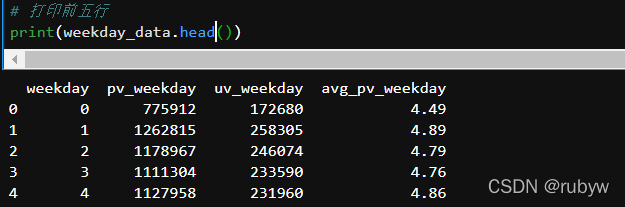
pv_weekday = clk_data.groupby('weekday')['user_id'].count().reset_index().rename(columns={'user_id':'pv_weekday'})
uv_weekday = df.groupby('weekday')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'uv_weekday'})
weekday_data = pd.merge(pv_weekday, uv_weekday, how='outer', on='weekday')
weekday_data['avg_pv_weekday']=round(weekday_data['pv_weekday']/weekday_data['uv_weekday'],2)
pay_weekday = pay_data.groupby('weekday')['user_id'].count().reset_index().rename(columns={'user_id':'pay_weekday'})
weekday_data = pd.merge(weekday_data, pay_weekday, on='weekday')
weekday_data['avg_pay_weekday']=round(weekday_data['pay_weekday']/weekday_data['uv_weekday'],2)
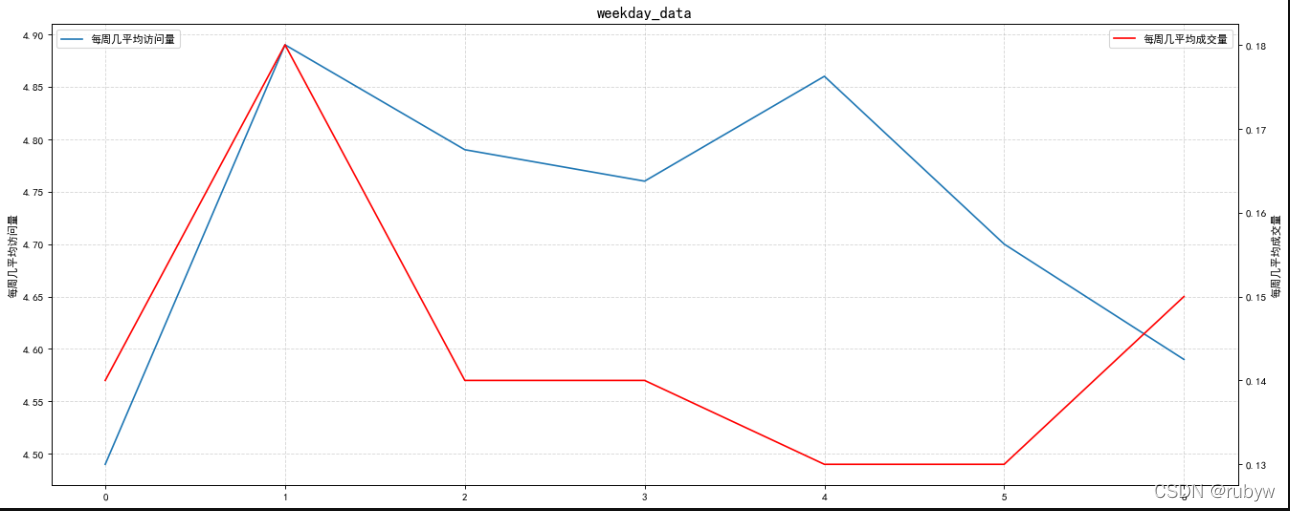
人均访问量最高是周一,最低是周日;
人均支付量最高是周一,最低是周四和周五。
**
总结
**
- 用户在31日人均成交量和人均访问量分别达到最高和最低;
- 用户在凌晨比较活跃,人均成交量高,凌晨两点左右人均成交量最高,下午三点人均访问量最高;
- 周一时的人均成交量和人均访问量同时达到最高;
- 经查询日历,发现2021年5月31日正好是周一,所以可以猜测应该是由于6月份有‘618’活动,活动力度和优惠力度较大,需要在6月之前下单完成,所以用户在活动结束前5.31集中进行购买之前已经收藏和加购好的商品,很少再进行浏览;
- 总体用户的活跃度和支付转化率较低。
3.2.1.2留存分析
次日留存率=(某日新增的用户中,在注册的第2天还进行登录的用户数)/ 该日新增用户数
3日留存率=(某日新增用户中,在注册的第3天还进行登录的用户数)/ 该日新增用户数
7日留存率=(某日新增的用户中,在注册的第7天还进行登录的用户数)/ 该日新增用户数
30日留存率=(某日新增的用户中,在注册的第30天还进行登录的用户数)/ 该日新增用户数
# 创建n日留存函数defcal_retention(data, n):# n为n日留存
user =[]
date = pd.Series(data.date.unique()).sort_values()[:-n]# 时间截取至最后一天的前n天
retention_rates =[]for i in date:
new_user =set(data[data.date == i].user_id.unique())-set(user)# 识别新用户,设初始用户量为零
user.extend(new_user)# 第n天留存状况
user_nday = data[data.date == i+timedelta(n)].user_id.unique()# 第n天登陆的用户状况
a =0for user_id in user_nday:if user_id in new_user:
a +=1
retention_rate = a/len(new_user)# 计算该天第n日留存率
retention_rates.append(retention_rate)# 汇总n日留存数据
data_retention = pd.Series(retention_rates, index=date)return data_retention
# 分别计算留存率
retention_2days = cal_retention(df,1).apply(lambda x:format(x,'.2%'))# 次日留存
retention_3days = cal_retention(df,2).apply(lambda x:format(x,'.2%'))# 3日留存
retention_7days = cal_retention(df,6).apply(lambda x:format(x,'.2%'))# 7日留存
retention_15days = cal_retention(df,14).apply(lambda x:format(x,'.2%'))# 15日留存
retention_30days = cal_retention(df,29).apply(lambda x:format(x,'.2%'))# 30日留存# 留存拼接
retention_data = pd.concat([retention_2days, retention_3days, retention_7days, retention_15days, retention_30days], axis=1)
# 改变列名
retention_data.columns =['次日','3日','7日','15日','30日']
retention_data = retention_data.replace(np.nan,'')print(retention_data)# 存入CSV
retention_data.to_csv('retention.csv', encoding='utf_8_sig')
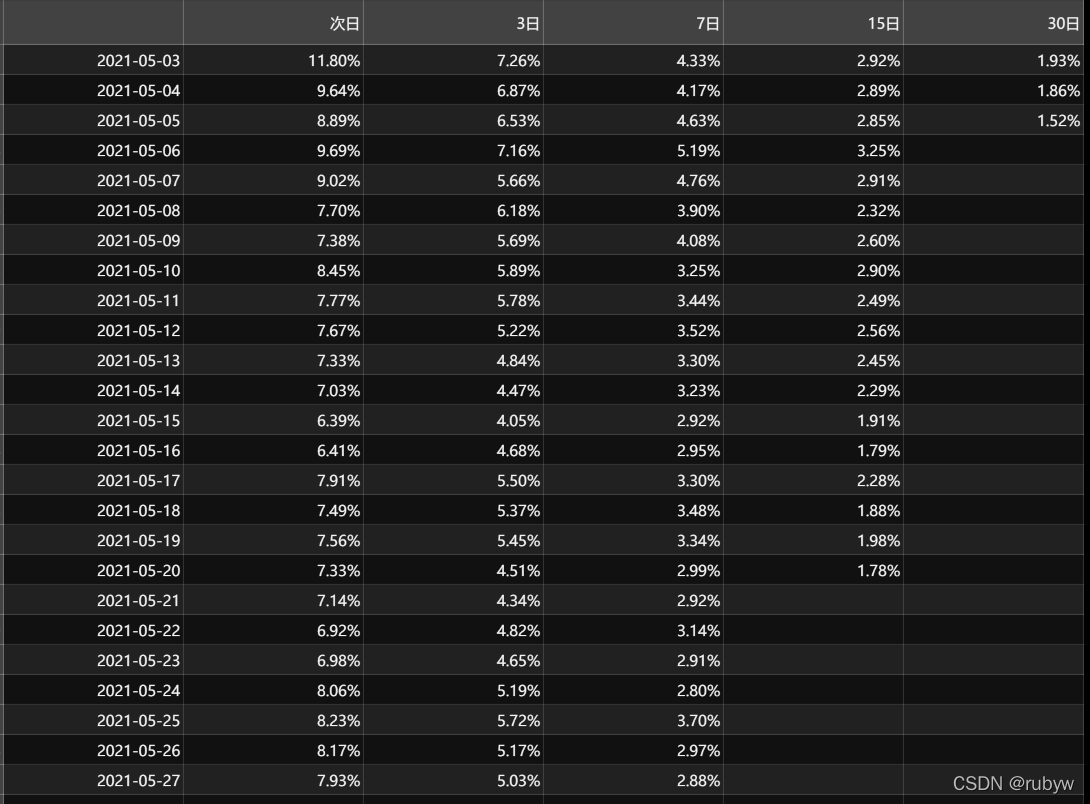
从不同的时间来看,留存率整体是比较低的,但这也可能跟多数用户出行频率不高的原因有关;
从另一个方面,可以加大活动优惠,提升产品品质,增强用户粘度。
3.2.1.3用户画像
只对支付用户进行分析
# 支付用户的消费时间
payuser_date = pay_data[['user_id','hour','weekday']]
时刻
# 支付用户按小时分布
payuser_hour = payuser_date.groupby('hour')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'num'})
# 创建图形
plt.figure(figsize=(20,8), dpi=80)
plt.bar(payuser_hour.hour, payuser_hour.num, label='每小时成交量')
plt.plot(payuser_hour.hour, payuser_hour.num,'ro-', color='r', alpha=0.8, linewidth=3)# 添加标注
plt.xlabel('小时',size=15)
plt.ylabel('成交量',size=15)#添加标题
plt.title('支付用户按小时分布',size=15)# 添加图例
plt.legend(loc='best')# 显示柱状-折线图
plt.show()

用户主要喜欢在凌晨支付,尤其是凌晨两点,在晚上支付最低,分析可能是用户在晚上时间主要在浏览选择自己感兴趣的东西,然后在凌晨才能下定决心支付,越晚越容易‘冲动’哈哈~
星期
# 支付用户按周几分布
payuser_weekday = payuser_date.groupby('weekday')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'num'})print(payuser_weekday)
# 创建图形
plt.figure(figsize=(10,5), dpi=80)
plt.bar(payuser_weekday.weekday, payuser_weekday.num, label='每周几成交量')# 添加标注
plt.xlabel('星期',size=15)
plt.ylabel('成交量',size=15)#添加标题
plt.title('支付用户按星期分布',size=15)# 添加图例
plt.legend(loc='best')# 显示柱状图
plt.show()
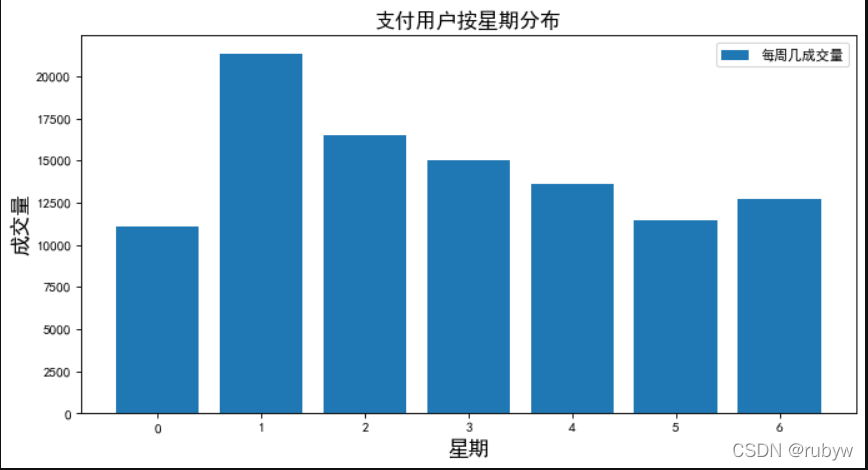
用户喜欢在周一支付,可能跟5.31是星期一有关。
# 读取user_profile.csv,并增加列名'user_id','age','sex','career','use_city_id','crowd_label'
user_profile = pd.read_csv('./data/user_profile.csv', header=None, names =['user_id','age','sex','career','use_city_id','crowd_label'], encoding='utf-8')# 根据user_id拼接user_profile数据
payuser_profile = pd.merge(payuser_date, user_profile, how='left', on='user_id')
年龄
# 最大年龄及最小年龄print(payuser_profile['age'].max(), payuser_profile['age'].min())'''
考虑到平台注册年龄限制,所以最小年龄设置为18岁;
对年龄异常数据进行处理;
'''
payuser_profile = payuser_profile[payuser_profile['age']>=18]print(payuser_profile['age'].min())# 年龄分箱
bins =[18,25,35,45,60,80,125]
labels =['[18-25)','[25-35)','[35-45)','[45-60)','[60-80)','[80-125]']
payuser_profile['age_cut']= pd.cut(x=payuser_profile.age, bins=bins, right=False, labels=labels)print(payuser_profile.head())# 年龄分布
payuser_age = payuser_profile[['user_id','age_cut']].groupby('age_cut')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'num'})print(payuser_age)
# 创建图形
plt.figure(figsize=(10,5), dpi=80)
plt.bar(payuser_age.age_cut, payuser_age.num, label='年龄段成交量')# 添加标注
plt.xlabel('年龄',size=15)
plt.ylabel('成交量',size=15)#添加标题
plt.title('支付用户按年龄段分布',size=15)# 添加图例
plt.legend(loc='best')# 显示柱状图
plt.show()
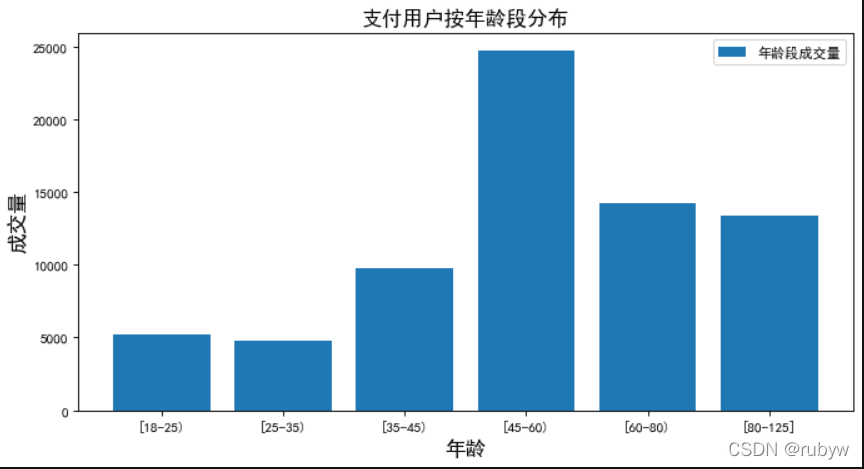
支付用户的年龄主要集中在45~60岁年龄段,这个年龄的用户在退休年龄左右,相对年轻人和中年人来说,没有太大经济和生活压力,更懂得也有时间享受生活出去旅行。
性别
# 性别分布
payuser_sex = payuser_profile[['user_id','sex']].groupby('sex')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'num'})print(payuser_sex)
sexnum1962227540343487
# 画饼图
plt.pie(payuser_sex['num'], labels=payuser_sex['sex'], autopct='%1.2f%%')
plt.title('支付用户按性别分布')
plt.legend(loc='best')
plt.show()
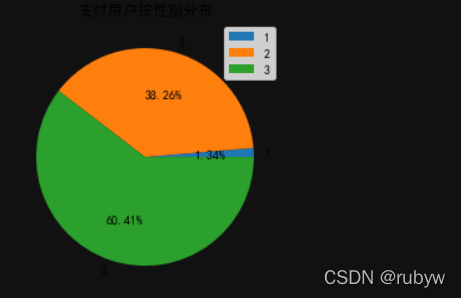
1:未知,2:男性,3:女性
支付用户中女性是男性的1.5倍左右,说明现代女性更加独立自主,更喜欢享受生活喜欢旅行,男性经济方面压力大些,相对来说出行欲望较低。
职业
# 职业分布
payuser_career = payuser_profile.groupby('career')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'num'})
payuser_career['percent']= payuser_career['num']/payuser_career['num'].sum()

支付用户的职业主要集中在职业3上,说明这个职业的人比较喜欢出行,也有可能是职业原因(需要出差等~)。
城市
# 城市分布
payuser_city = payuser_profile.groupby('use_city_id')['user_id'].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={'user_id':'num'})
payuser_city['percent']= payuser_city['num']/payuser_city['num'].sum()
payuser_city = payuser_city[payuser_city['percent']>0.1]print(payuser_city)
use_city_idnumpercent22486490.12
支付用户占比大于10%的城市只有一个:城市224,可能这个城市比较发达,人民相对富裕,除生活开销外,愿意负担出行的费用享受生活。
3.2.2行为维度
3.2.2.1复购率和跳失率
复购率=购买次数>1的用户/所有购买用户
# 统计每个用户支付次数
pay_times = pay_data[['user_id','behavior_type']].groupby('user_id').agg('count').reset_index().rename(columns={'behavior_type':'paycount'})print(pay_times.head())# 统计支付次数大于1的用户
repay_data = pay_times[pay_times['paycount']>1]
user_idpaycount3261051257432314411
复购率=2/5=40%
只购买一次的用户占购买用户总数的60%,有复购行为的人占40%,可以发现高复购次数的人占比较少,商家可以从商品质量、服务制度、物流体验、以及售后服务几个方面寻找原因,找到提高复购率的突破点。
跳失率=点击次数为1的用户/所有点击用户
# 统计每个用户的点击次数
clk_times = pay_data[['user_id','behavior_type']].groupby('user_id').agg('count').reset_index().rename(columns={'behavior_type':'clkcount'})# 统计点击次数为1的用户
clk_onetime = clk_times[clk_times['clkcount']==1]# 计算跳失率
bounce_rate =round(clk_onetime.shape[0]/clk_times.shape[0],2)print('跳失率:', bounce_rate)
跳失率:47%
复购率偏低,且跳失率较高,说明平台对用户没有足够的吸引力让用户停留。
3.2.2.2漏斗分析
用户从点击到最终支付的过程当中流失率(或转化率)状况
# 总体
pv_total =len(df)
clk_num =len(clk_data)# 点击总计
fav_num =len(fav_data)# 收藏总计
cart_num =len(cart_data)# 加购总计
pay_num =len(pay_data)# 支付总计
pv_totalclk_numfav_numcart_numpay_num79834507229031229732300665224022
# 总体各个阶段的流失率计算
Wastage_rate1 =round(1-clk_num/pv_total,4)
Wastage_rate2 =round(1-cart_num/clk_num,4)
Wastage_rate3 =round(1-fav_num/cart_num,4)
Wastage_rate4 =round(1-pay_num/fav_num,3)

浏览—点击—加购—收藏—购买
总浏览到点击的流失率小说明转化率高,点击到加购流失率太高说明点击转化率低,用户进行点击行为后就没有后续了,收藏到购买的流失率很小,说明用户对这两个用户行为差不多,对于收藏的商品购买的可能性很大。
# 漏斗图--matplotlibimport seaborn as sns
from matplotlib.patches import Polygon # Polygon()可以用来传入按顺序组织的多边形顶点,从而生成出多边形from matplotlib.collections import PatchCollection
plt.style.use('seaborn-dark')# 设置主题
plt.rcParams['font.sans-serif']=['SimHei']# 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False# 用来正常显示负号
data =[clk_num, cart_num, fav_num, pay_num]
phase =['点击次数','加购次数','收藏次数','购买次数']
data1 =[clk_num/2- i/2for i in data]# 用来覆盖柱形图左边
data2 =[i+j for i,j inzip(data, data1)]# 柱形图长度=data+覆盖柱形图长度
color_list =['#00685A','#1E786C','#00A08A','#34D0BA']# 柱子颜色
fig,ax = plt.subplots(figsize=(16,9),facecolor='#f4f4f4')
ax.set_title('用户转化漏斗图',fontsize=18)
ax.barh(phase[::-1], data2[::-1], color = color_list, height=0.7)# 柱宽设置为0.7
ax.barh(phase[::-1], data1[::-1], color ='#f4f4f4', height=0.7)# 设置成背景同色,覆盖柱形图
ax.axis('off')
polygons =[]for i inrange(len(data)):# 阶段
ax.text(0,# 坐标
i,# 高度
phase[::-1][i],# 文本,phase[::-1]表示将列表倒序排列
color='black', alpha=0.8, size=16, ha="right")# 数量if i <3:
ax.text(
data2[0]/2,
i,str(data[::-1][i])+'('+str(round(data[::-1][i]/ data[::-1][i+1]*100,1))+'%)',
color='black', alpha=0.8, size=14, ha="center")else:
ax.text(
data2[0]/2,
i,str(data[::-1][i]),
color='black', alpha=0.8, size=14, ha="center")if i <3:# 绘制过渡多边形
polygons.append(Polygon(xy=np.array([(data1[i +1],2+0.35- i),# 因为柱状图的宽度设置成了0.7,所以一半便是0.35(data2[i +1],2+0.35- i),(data2[i],3-0.35- i),(data1[i],3-0.35- i)])))# 使用add_collection与PatchCollection来向Axes上添加多边形
ax.add_collection(PatchCollection(polygons,
facecolor='#F56E8D',
alpha=0.8));
plt.show()

时间
# 建漏斗函数defcal_funnel(data, datetime):
data1 = data.groupby([datetime,'behavior_type']).user_id.count().reset_index().rename(columns={'user_id':'total'})# 不一样时间中,各用户行为的用户数量
lose_rates =[]#流失率
date2 = pd.Series(data1[datetime].unique())for i in date2:
data2 = data1[data1[datetime]== i]
clk_to_cart =1- data2[data2.behavior_type ==3].reset_index().loc[0,'total']/data2[data2.behavior_type ==1].reset_index().loc[0,'total']
cart_to_fav =1-data2[data2.behavior_type ==2].reset_index().loc[0,'total']/data2[data2.behavior_type ==3].reset_index().loc[0,'total']
fav_to_pay =1-data2[data2.behavior_type ==4].reset_index().loc[0,'total']/data2[data2.behavior_type ==2].reset_index().loc[0,'total']
lose_rate =[clk_to_cart, cart_to_fav, fav_to_pay]
lose_rates.append(lose_rate)
data3 = pd.DataFrame(lose_rates, index=date2, columns=['clk_to_cart','cart_to_fav','fav_to_pay'])return data3
# 按日计算
a_day_lose=cal_funnel(df,'date')
# 创建图形
plt.figure(figsize=(20,8), dpi=80)
plt.plot(a_day_lose.index, a_day_lose.clk_to_cart, label='点击——加购')
plt.plot(a_day_lose.index, a_day_lose.cart_to_fav, label='加购——收藏')
plt.plot(a_day_lose.index, a_day_lose.fav_to_pay, label='收藏——购买')# 添加水平线
plt.axhline(y=0,ls="--",c="k", linewidth=1)# 添加标注
plt.xlabel('日期',size=15)
plt.ylabel('转化率',size=15)#添加标题
plt.title('用户行为转化流失率',size=15)# 添加图例
plt.legend(loc='best')# 显示折线图
plt.show()
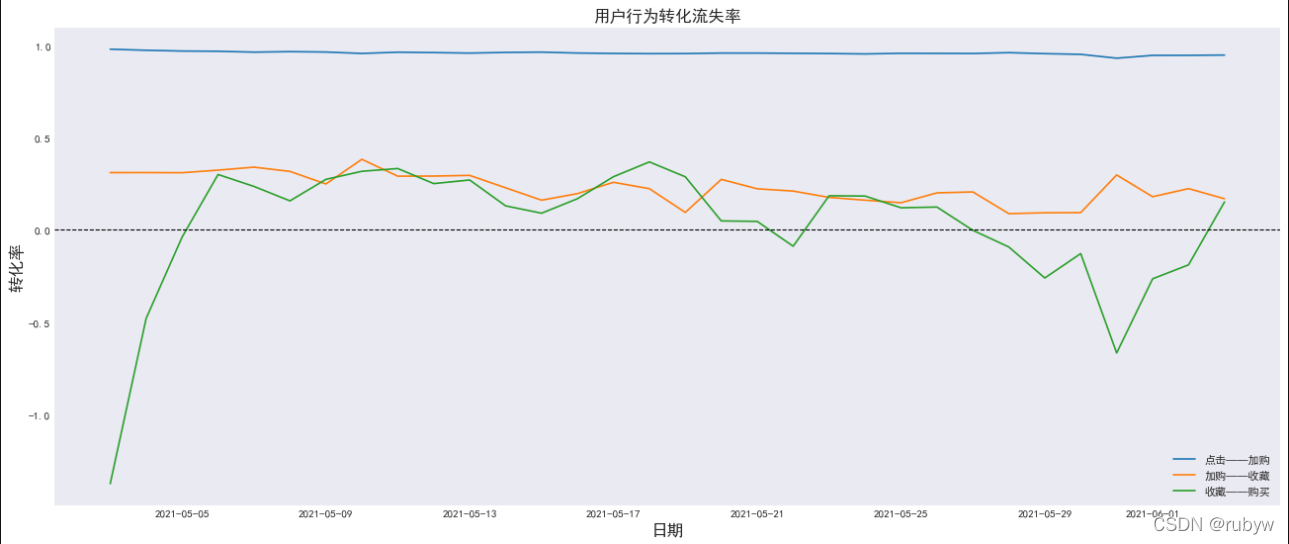
由上图可以看出,部分日期的收藏—购买流失率处于负值区域,说明该天的成交量大于收藏量,说明成交量只有一小部分来源于收藏,所以不再适用于这种转化路径。
点击—收藏/加购—购买
# 建漏斗函数defcal_funnel(data, datetime):
data1 = data.groupby([datetime,'behavior_type']).user_id.count().reset_index().rename(columns={'user_id':'total'})# 不一样时间中,各用户行为的用户数量
lose_rates =[]#流失率
date2 = pd.Series(data1[datetime].unique())for i in date2:
data2 = data1[data1[datetime]== i]
clk_to_favAndcart =1-(data2[data2.behavior_type ==2].reset_index().loc[0,'total']+ data2[data2.behavior_type ==3].reset_index().loc[0,'total'])/data2[data2.behavior_type ==1].reset_index().loc[0,'total']
favAndcart_to_pay =1-data2[data2.behavior_type ==4].reset_index().loc[0,'total']/(data2[data2.behavior_type ==2].reset_index().loc[0,'total']+data2[data2.behavior_type ==3].reset_index().loc[0,'total'])
lose_rate =[clk_to_favAndcart, favAndcart_to_pay]
lose_rates.append(lose_rate)
data3 = pd.DataFrame(lose_rates, index=date2, columns=['clk_to_favAndcart','favAndcart_to_pay'])return data3
# 按日计算
a_day_lose2=cal_funnel(df,'date')
# 创建图形
plt.figure(figsize=(20,8), dpi=80)
plt.plot(a_day_lose2.index, a_day_lose2.clk_to_favAndcart, label='点击——收藏/加购')
plt.plot(a_day_lose2.index, a_day_lose2.favAndcart_to_pay, label='收藏/加购——购买')# 添加水平线
plt.axhline(y=0.5, ls="--",c="k", linewidth=1)# 添加标注
plt.xlabel('日期',size=15)
plt.ylabel('转化率',size=15)#添加标题
plt.title('用户行为转化流失率',size=15)# 添加图例
plt.legend(loc='best')# 显示折线图
plt.show()

在该月份期间,用户的点击—收藏/加购流失率一直居高不下,转化率极低,收藏/加购—购买的流失率大部分时间都大于50%,只有在月初的时候较低。
3.2.2.3用户行为在时间上的分布
# 按日分布
clk_date = clk_data[['user_id','date']].groupby('date')['user_id'].agg('count')
cart_date = cart_data[['user_id','date']].groupby('date')['user_id'].agg('count')
fav_date = fav_data[['user_id','date']].groupby('date')['user_id'].agg('count')
pay_date = pay_data[['user_id','date']].groupby('date')['user_id'].agg('count')# 按时分布
clk_hour = clk_data[['user_id','hour']].groupby('hour')['user_id'].agg('count')
cart_hour = cart_data[['user_id','hour']].groupby('hour')['user_id'].agg('count')
fav_hour = fav_data[['user_id','hour']].groupby('hour')['user_id'].agg('count')
pay_hour = pay_data[['user_id','hour']].groupby('hour')['user_id'].agg('count')# 按周分布
clk_weekday = clk_data[['user_id','weekday']].groupby('weekday')['user_id'].agg('count')
cart_weekday = cart_data[['user_id','weekday']].groupby('weekday')['user_id'].agg('count')
fav_weekday = fav_data[['user_id','weekday']].groupby('weekday')['user_id'].agg('count')
pay_weekday = pay_data[['user_id','weekday']].groupby('weekday')['user_id'].agg('count')
# 创建图形
fig = plt.figure(figsize=(20,10),dpi=80)
plt.grid(True, linestyle="--", alpha=0.5)
plt.xticks([])#去掉横坐标值
plt.yticks([])#去掉纵坐标值
ax1 = fig.add_subplot(311)
date = clk_date.index.tolist()
ax1.bar(date, clk_date.values, label='每日用户点击量')
ax1.set_ylabel('数量')
ax1.set_title('用户行为按天分布', size=10)
ax1.legend(loc='upper left')
ax2 = ax1.twinx()
ax2.plot(date, cart_date.values,'r', label='每日用户加购量', linewidth=2)
ax2.plot(date, fav_date.values,'k', label='每日用户收藏量', linewidth=2)
ax2.plot(date, pay_date.values,'y', label='每日用户购买量', linewidth=2)
ax2.set_ylabel('数量')
ax2.set_xlabel('日期')
ax2.legend(loc='upper right')
ax1 = fig.add_subplot(312)
hour = clk_hour.index.tolist()
ax1.bar(hour, clk_hour.values, label='每小时用户点击量')
ax1.set_ylabel('数量')
ax1.set_title('用户行为按时刻分布', size=10)
ax1.legend(loc='upper left')
ax2 = ax1.twinx()
ax2.plot(hour, cart_hour.values,'r', label='每日用户加购量', linewidth=2)
ax2.plot(hour, fav_hour.values,'k', label='每日用户收藏量', linewidth=2)
ax2.plot(hour, pay_hour.values,'y', label='每日用户购买量', linewidth=2)
ax2.set_ylabel('数量')
ax2.set_xlabel('时刻')
ax2.legend(loc='upper right')
ax1 = fig.add_subplot(313)
weekday = clk_weekday.index.tolist()
length =len(clk_weekday)
x = np.arange(length)# 横坐标
total_width, n =0.6,3# 柱状总宽度,数据组数
width = total_width / n # 每个柱状的宽度
x1 = x - width /3# 第一组柱状横坐标起始位置
x2 = x1 + width # 第二组柱状横坐标起始位置
x3 = x2 + width # 第三组柱状横坐标起始位置
ax1.plot(weekday, clk_weekday.values,'r', linewidth=1, label='每周几用户点击量')
ax1.set_ylabel('数量')
ax1.set_title('用户行为按星期分布', size=10)
ax1.legend(loc='upper left')
ax2 = ax1.twinx()
ax2.bar(x1, cart_weekday.values, width=width, label='每周几用户加购量')
ax2.bar(x2, fav_weekday.values, width=width, label='每周几用户收藏量')
ax2.bar(x3, pay_weekday.values, width=width, label='每周几用户购买量')
ax2.set_xticks(x, weekday)
ax2.set_ylabel('数量')
ax2.set_xlabel('星期')
ax2.legend(loc='upper right')
plt.show()
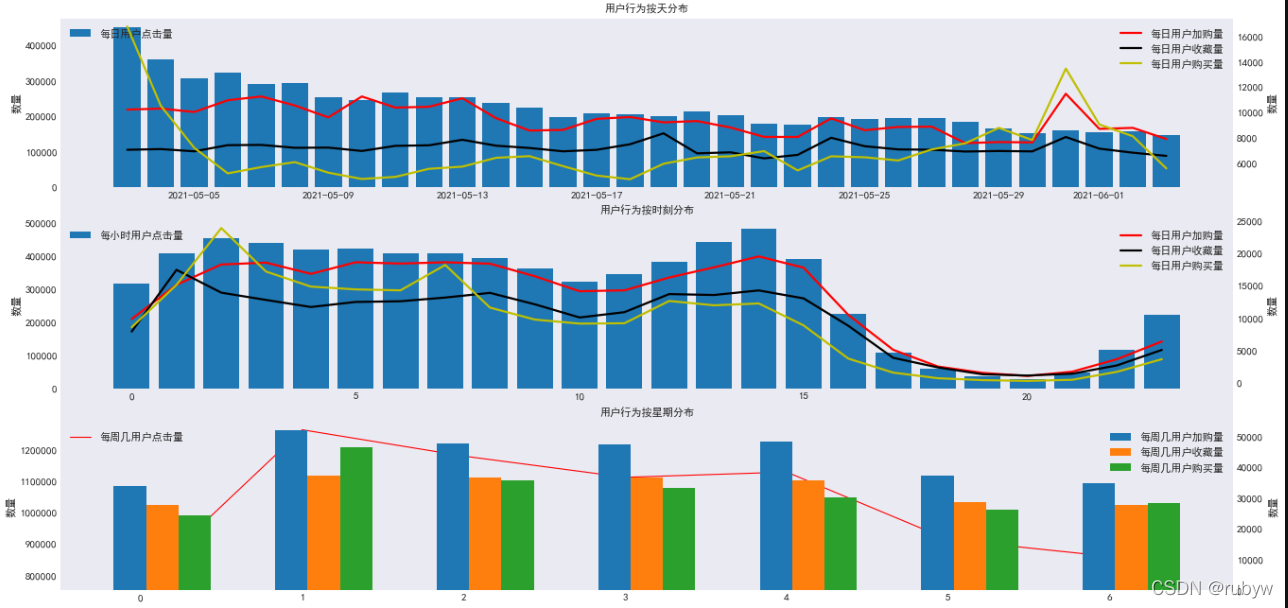
- 用户点击量在月初最高,随着时间的推移不断降低直至平缓,收藏、加购、购买在5月底拐点一致,达到最高;
- 用户在傍晚活跃度最低,喜欢在凌晨支付,尤其是凌晨2点,其余时刻用户点击和加购的变化一致,收藏和购买的变化一致;
- 用户在周一最活跃,点击、收藏、加购、购买同时达到最大值,购买路径转化率最高。
3.3 商品分析
3.3.1热门商品分析
# 读取数据'item_profile.csv'
item_profile = pd.read_csv('./data/item_profile.csv', header=None, names =['item_id','item_category_id','item_city','item_label'], encoding='utf8')print(item_profile.head())
# 按商品分组统计商品被点击、加购、收藏、购买的数量
item_clk_num = clk_data.groupby('item_id')['behavior_type'].count().reset_index().rename(columns={'behavior_type':'clk_num'})
item_cart_num = cart_data.groupby('item_id')['behavior_type'].count().reset_index().rename(columns={'behavior_type':'cart_num'})
item_fav_num = fav_data.groupby('item_id')['behavior_type'].count().reset_index().rename(columns={'behavior_type':'fav_num'})
item_pay_num = pay_data.groupby('item_id')['behavior_type'].count().reset_index().rename(columns={'behavior_type':'pay_num'})
# 商品点击Top10
item_clk_num = item_clk_num.sort_values(by='clk_num', ascending=False)
item_clk_Top10 = item_clk_num.head(10)# 商品收藏+加购Top10
favcart_data = pd.concat([fav_data, cart_data], axis=0)
item_favcart_num = favcart_data.groupby('item_id')['behavior_type'].count().reset_index().rename(columns={'behavior_type':'favcart_num'})
item_favcart_num = item_favcart_num.sort_values(by='favcart_num', ascending=False)
item_favcart_Top10 = item_favcart_num.head(10)# 商品购买Top10
item_pay_num = item_pay_num.sort_values(by='pay_num', ascending=False)
item_pay_Top10 = item_pay_num.head(10)
3.3.2购买路径分析
1.点击——购买:ctop_rate; 2.收藏/加购——购买:ftop_rate;
# Top10转化率
df1 = item_clk_Top10.merge(item_pay_Top10, on='item_id').merge(item_favcart_Top10, on='item_id')# 点击——购买
df1['ctop_rate']=round(df1['pay_num']/df1['clk_num'],4)# 收藏/加购——购买
df1['fctop_rate']=round(df1['pay_num']/df1['favcart_num'],4)print(df1)# 平均转化率
ctop_avg_rate =round(df1['pay_num'].sum()/df1['clk_num'].sum(),2)
fctop_avg_rate =round(df1['pay_num'].sum()/df1['favcart_num'].sum(),2)
# matplotlib可视化import matplotlib.ticker as ticker
fig = plt.figure(figsize=(8,5),dpi=80)
colors =['#CC9999','#FFFF99','#666699']
x =tuple(df1['item_id'].apply(str))#list transform to tupleprint(x)# 点击-购买转化率
ax1 = fig.add_subplot(211)
ax1.set_title('点击Top10商品购买转化率',fontsize=14)
ax1.bar(x,df1.clk_num,width=0.3,color=colors)# 柱状图显示点击量
ax1.set_xlabel('商品ID', size =10)
ax1.set_ylabel('点击量', size =10)
ax2 = ax1.twinx()
ax2.plot(x,df1.ctop_rate)
ax2.set_ylabel('点击-购买转化率', size =10)
ax2.yaxis.set_major_formatter(ticker.PercentFormatter(xmax=1, decimals=1))
ax2.axhline(y=ctop_avg_rate,c='r',ls=':',label='平均购买转换率')#添加水平直线# 收藏-购买转化率
ax3 = fig.add_subplot(212)
ax3.set_title('收藏/加购Top10商品购买转化率',fontsize=14)
ax3.bar(x,df1.favcart_num,color=colors,width=0.3)
ax3.set_xlabel('商品ID', size =10)
ax3.set_ylabel('收藏加购量', size =10)
ax4 = ax3.twinx()
ax4.axhline(y=fctop_avg_rate,c='r',ls=':',label='平均购买转换率')#添加水平直线
ax4.plot(scale_ls,df1.fctop_rate)
ax4.set_ylabel('收藏/加购-购买转化率', size =10)
ax4.yaxis.set_major_formatter(ticker.PercentFormatter(xmax=1, decimals=1))
plt.tight_layout()# 自动调整各子图间距
plt.show()
 通过可视化分析,点击量、收藏加购量高的商品,购买转化率不一定高,相关性不成正比,尤其是收藏加购量最高的商品购买转化率反而是最低的,可以这类商品增加关注。
通过可视化分析,点击量、收藏加购量高的商品,购买转化率不一定高,相关性不成正比,尤其是收藏加购量最高的商品购买转化率反而是最低的,可以这类商品增加关注。
3.3.3商品画像
# item_pay_Top10根据item_id拼接item_profile
payitem_profile = pd.merge(item_pay_Top10, item_profile, how='left', on='item_id')
item_category_num = payitem_profile.groupby('item_category_id')['pay_num'].sum().reset_index().rename(columns={'pay_num':'pay_sum'})
item_city_num = payitem_profile.groupby('item_city')['pay_num'].sum().reset_index().rename(columns={'pay_num':'pay_sum'})
item_label_num = payitem_profile.groupby('item_label')['pay_num'].sum().reset_index().rename(columns={'pay_num':'pay_sum'})
# matplotlib可视化
fig = plt.figure(figsize=(9,5),dpi=80)# 购买商品Top10种类分布
ax1 = fig.add_subplot(311)
ax1.set_title('购买商品Top10种类分布',fontsize=14)
x1 =tuple(item_category_num['item_category_id'].apply(str))
y1 = item_category_num['pay_sum']
colors1 =['#CC9999','#FFFF99','#666699']
ax1.barh(x1,y1,color=colors1)
ax1.set_xlabel('商品种类', size =10)
ax1.set_ylabel('成交量', size =10)# 购买商品Top10区域分布
ax1 = fig.add_subplot(312)
ax1.set_title('购买商品Top10区域分布',fontsize=14)
x1 =tuple(item_city_num['item_city'].apply(str))
y1 = item_city_num['pay_sum']
colors2 =['#FF9900','#009999','#CCCC99','#CC3399']
ax1.barh(x1,y1,color=colors2)
ax1.set_xlabel('城市', size =10)
ax1.set_ylabel('成交量', size =10)# 购买商品Top10标签分布
ax1 = fig.add_subplot(313)
ax1.set_title('购买商品Top10标签分布',fontsize=14)
x1 =tuple(item_label_num['item_label'].apply(str))
y1 = item_label_num['pay_sum']
colors3 =['#FF6666','#0099CC','#009966']
ax1.barh(x1,y1,color=colors3)
ax1.set_xlabel('商品标签', size =10)
ax1.set_ylabel('成交量', size =10)
plt.tight_layout()# 自动调整各子图间距
plt.show()
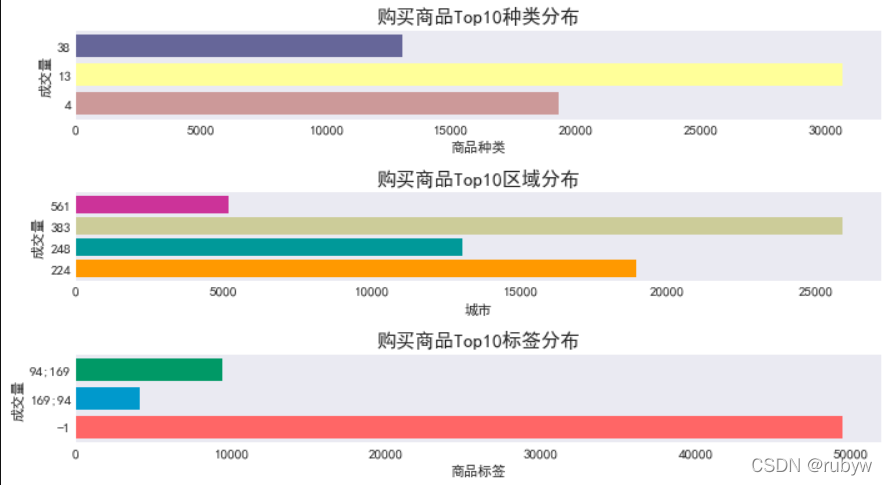
购买商品Top10的种类主要集中在ID为4、13、30的种类;
购买商品Top10 的城市主要分布在ID为224、248、383、561的城市;
购买商品Top10 的标签主要是ID为-1、169、94的标签。
五、总结
- 从总体上看,用户的活跃度和转化率都比较低,可能跟产品性质有关,一般使用频率不高,只有有需求时才会产生用户行为;
- 用户在凌晨三点成交率最高,在晚上8点最低,周日不活跃成交率低;是否有活动优惠对用户行为影响较大,会提前选好自己感兴趣的商品,直到活动将近结束时才会决定购买;
- 支付用户的年龄主要集中在45~60岁年龄段,这个年龄的用户在退休年龄左右,没有太大经济和生活压力,也有时间享受生活;支付用户的职业主要是ID为3,这个可能跟职业性质有关;支付用户中女性远大于男性,说明现在的女性更独立自主喜欢出行,更懂得享受生活,而男性可能经济压力较大,出行欲望较低;
- 用户的复购率很低,低于50%,跳失率很高,将近50%,留存率整体很低,说明用户粘度不高,平台对用户的吸引力很低,商家可以从页面设计、精准推送、服务制度以及售后服务几个方面寻找原因;
- 用户点击到加购的流失率太高,说明商品对用户的吸引度不够,收藏到购买的流失率极低,说明用户收藏商品的购买可能性极高,但收藏量较低,用户转化率问题比较大,整体太低,需要根据用户需求针对性的改善平台及其商品;
- 在商品Top10分析中,可以看出高点击量、收藏加购量的商品,购买量不一定最高,购买商品的种类和标签具有集中性,可以对这类商品提高关注度,提高转化率;
- 由于本项目的数据样本只有一个月,导致时间维度特征不够复杂,所以对于有些指标的分析具有局限性,如果有多个月份数据按月份维度分析会更好,结果也更具参考意义。
版权归原作者 rubyw 所有, 如有侵权,请联系我们删除。