
- 一、InstructGPT是在GPT3上微调,ChatGPT是在GPT3.5上微调
- 二、该论文展示了怎么样对语言模型和人类意图之间进行匹配,方法是在人类的反馈上进行微调。
- 三、方法简介:收集很多问题,使用标注工具将问题的答案写出来,用这些数据集对GPT3进行微调。接下来再收集一个数据集,通过刚才微调的模型输入问题得到一些输出答案,人工对这些答案按好坏进行排序,然后通过强化学习继续训练微调后的模型,这个模型就叫InstrunctGPT。
- 四、大的语言模型会生成有问题的输出,因为模型训练用的目标函数不那么对。实际的目标函数:在网上的文本数据预测下一个词。我们希望的目标函数:根据人的指示、有帮助的、安全的生成答案。InstructGPT就是解决这个问题,方法是RLHF(reinforcement learning from human feedback),基于人类反馈的强化学习。
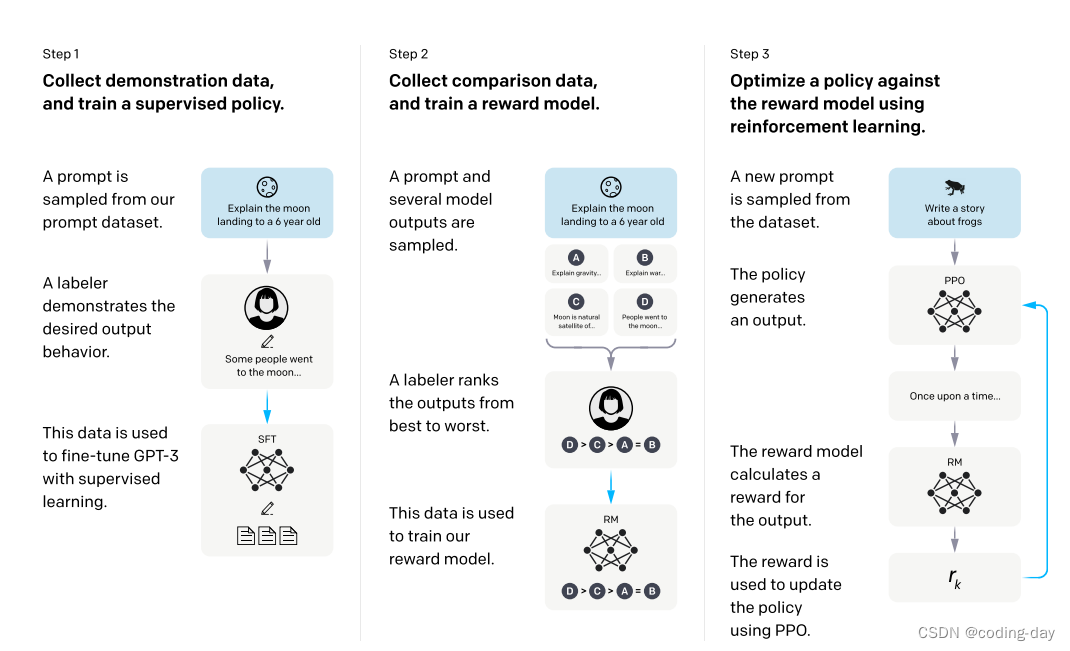 五、重点:两个标注数据集,三个模型。
五、重点:两个标注数据集,三个模型。 - 1、找人来写出各种各样的问题
- 2、让人根据问题写答案
- 3、将问题和答案拼在一起,形成一段对话。
- 4、使用这些对话微调GPT3。GPT3的模型在人类标注的这些数据上进行微调出来的模型叫做SFT(supervised fine-tune),有监督的微调。这就是训练出来的第一个模型。
- 5、给出一个问题,通过SFT模型生成几个答案 (例如:什么是月亮? SFT模型生成了四个答案: A、月亮是太阳系中离地球最近的天体。 B、月亮是太阳系中体积第五大的卫星。 C、月亮是由冰岩组成的天体,在地球的椭圆轨道上运行。 D、月亮是地球的卫星。)
- 6、将四个答案让人根据好坏程度进行排序。
- 7、将大量的人工排序整理为一个数据集,就是第二个标注数据集。
- 8、使用排序数据集训练一个RM模型,reward model,奖励模型。这是第二个模型。
- 9、继续给出一些没有答案的问题,通过强化学习继续训练SFT模型,新的模型叫做RL模型(Reinforcement Learning)。优化目标是使得RF模型根据这些问题得到的答案在RM模型中得到的分数越高越好。这是第三个模型。
- 10、最终微调后的RL模型就是InstructGPT模型。
备注:两次对模型的微调:GPT3模型—>SFT模型—>RL模型,其实这里始终都是同一个模型,只是不同过程中名称不一样。
需要SFT模型的原因:GPT3模型不一定能够保证根据人的指示、有帮助的、安全的生成答案,需要人工标注数据进行微调。
需要RM模型的原因:标注排序的判别式标注,成本远远低于生成答案的生成式标注。
需要RF模型的原因:在对SFT模型进行微调时,生成的答案分布也会发生变化,会导致RM模型的评分会有偏差,需要用到强化学习。
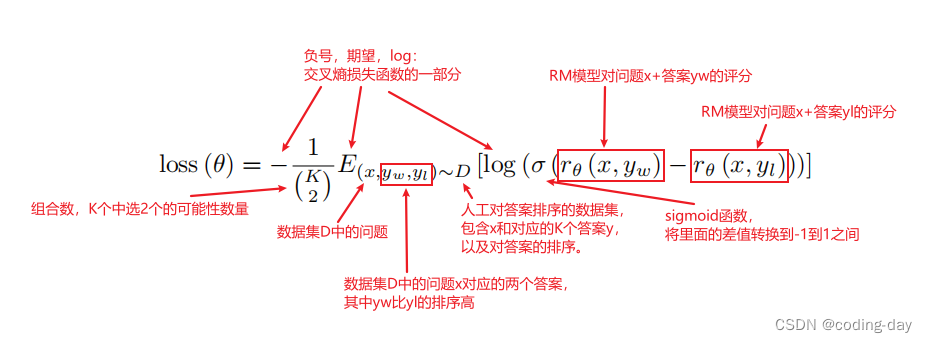
- 六、数据集问题 收集问题集,prompt集:标注人员写出这些问题,写出一些指令,用户提交一些他们想得到答案的问题。先训练一个最基础的模型,给用户试用,同时可以继续收集用户提交的问题。划分数据集时按照用户ID划分,因为同一个用户问题会比较类似,不适合同时出现在训练集和验证集中。 三个模型的数据集:1、SFT数据集:13000条数据。标注人员直接根据刚才的问题集里面的问题写答案。2、RM数据集:33000条数据。标注人员对答案进行排序。3、RF数据集:31000条数据。只需要prompt集里面的问题就行,不需要标注。因为这一步的标注是RM模型来打分标注的。 补充:交叉熵用来评估标签和预测值之间的差距。这里是将排序的分数差转换成分类问题,就可以计算分数差的分类(1或者-1)和真实预测值之间的差距,1表示yw比yl排序更前,-1表示yl比yw排序更前。KL散度用来评估两个概率分布之间的相似度,KL散度始终大于等于0。这里是用来评估πφRL和πSFT两个模型相似度,两个模型相同则KL散度为0,KL散度越大表示两个模型相差越大。
- 七、三种模型详解
一、SFT(Supervised fine-tuning)模型
把GPT3这个模型,在标注好的第一个数据集(问题+答案)上面重新训练一次。
由于只有13000个数据,1个epoch就过拟合,不过这个模型过拟合也没什么关系,甚至训练更多的epoch对后续是有帮助的,最终训练了16个epoch。
二、RM(Reward modeling)模型
把SFT模型最后的unembedding层去掉,即最后一层不用softmax,改成一个线性层,这样RM模型就可以做到输入问题+答案,输出一个标量的分数。
RM模型使用6B,而不是175B的原因:
1、小模型更便宜
2、大模型不稳定,loss很难收敛。如果你这里不稳定,那么后续再训练RL模型就会比较麻烦。
损失函数,输入是排序,需要转换为值,这里使用Pairwise Ranking Loss。
三、RL(Reinforcement learning)模型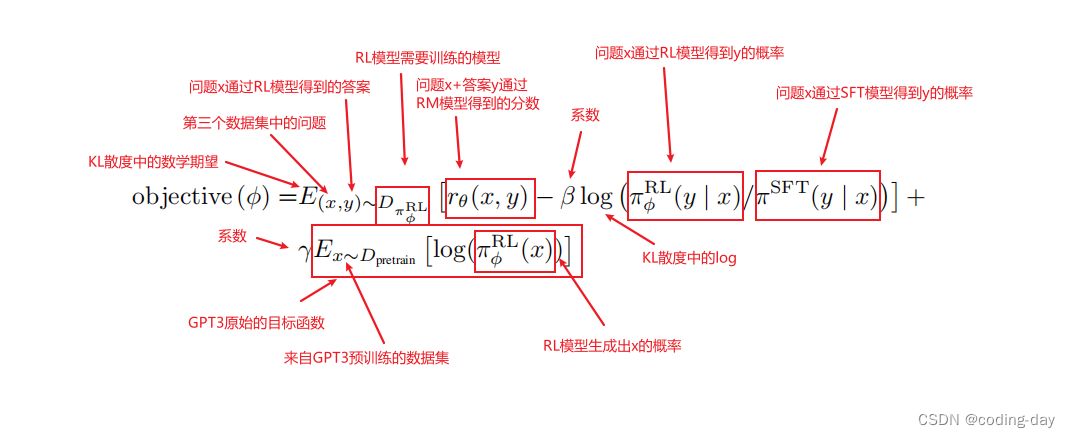
这里用的是强化学习,因为他的数据分布是随着策略的更新,环境会发生变化的。优化算法是PPO,Proximal Policy Optimization,近端策略优化。简单来说,就是对目标函数objective(φ)通过随机梯度下降进行优化。
参数解释:
1、πSFT:SFT模型。
2、πφRL:强化学习中,模型叫做Policy,πφRL就是需要调整的模型,即最终的模型。初始化是πSFT。
3、(x,y)∼DπφRL:x是第三个数据集中的问题,y是x通过πφRL模型得到的答案。
4、rθ(x,y):对问题x+答案y进行打分的RM模型。
5、πφRL(y | x):问题x通过πφRL得到答案y的概率,即对于每一个y的预测和它的softmax的输出相乘。
6、πSFT(y | x):问题x通过πSFT得到答案y的概率。
7、x∼Dpretrain:x是来自GPT3预训练模型的数据。
8、β、γ:调整系数。
目标函数理解:
优化目标是使得目标函数越大越好,objective(φ)可分成三个部分,打分部分+KL散度部分+GPT3预训练部分
1、将第三个数据集中的问题x,通过πφRL模型得到答案y
2、把一对(x,y)送进RM模型进行打分,得到rθ(x,y),即第一部分打分部分,这个分数越高就代表模型生成的答案越好
3、在每次更新参数后,πφRL会发生变化,x通过πφRL生成的y也会发生变化,而rθ(x,y)打分模型是根据πSFT模型的数据训练而来,如果πφRL和πSFT差的太多,则会导致rθ(x,y)的分数估算不准确。因此需要通过KL散度来计算πφRL生成的答案分布和πSFT生成的答案分布之间的距离,使得两个模型之间不要差的太远。
4、我们希望两个模型的差距越小越好,即KL散度越小越好,前面需要加一个负号,使得objective(φ)越大越好。这个就是KL散度部分。
5、如果没有第三项,那么模型最终可能只对这一个任务能够做好,在别的任务上会发生性能下降。所以第三部分就把原始的GPT3目标函数加了上去,使得前面两个部分在新的数据集上做拟合,同时保证原始的数据也不要丢,这个就是第三部分GPT3预训练部分。
6、当γ=0时,这个模型叫做PPO,当γ不为0时,这个模型叫做PPO-ptx。InstructGPT更偏向于使用PPO-ptx。
7、最终优化后的πφRL模型就是InstructGPT的模型。
以上就是InstructGPT的训练过程。
参考:
版权归原作者 coding-day 所有, 如有侵权,请联系我们删除。