
深度学习:GPT1、GPT2、GPT3的原理与模型代码解读

GPT-1
Introduction
GPT-1(Generative Pre-training Transformer-1)是由OpenAI于2018年发布的第一个基于Transformer模型的预训练语言模型。GPT-1主要针对的是生成型NLP任务,如文本生成、机器翻译、对话系统等。
在当时nlp领域没有一个像ImageNet那样的很大的数据集,而且一句字所含有的语义信息远不如一张图像的语音信息丰富,制作一个在nlp领域与imagenet 语义相当的数据集就需要很大的代价。
所以作者的想法是能不能通过 un-labeled的数据数据集 pre-train好一个通用的模型然后在各个细分领域进行微调。在这期间,作者发现两个问题:
- 训练通用的模型不知道选择什么优化目标。
- 不知道以哪种形式的output来适配所有的下游任务。
GPT的模型作者主要采用Transformer的decoder架构,由于它相较于rnn可以一次性读取更长的句子,容纳更多的语义信息。
Framework
自监督学习
首先介绍LOSS,在自监督训练期间训练标准语言模型,通过最大化最大化下面的likelyhood,其中 u为token的集合,条件概率P采用模型参数为 theta的模型建模。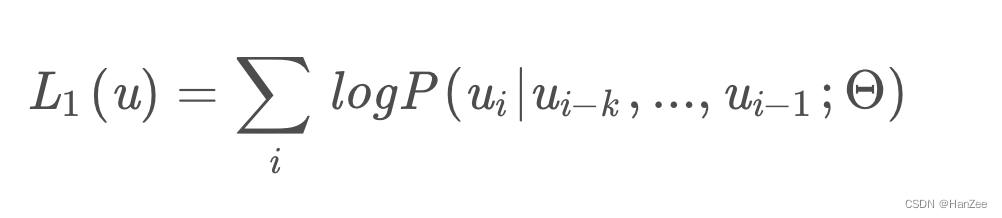
在前向传播的过程中,首先通过词嵌入与位置嵌入获得h0,其中we为token嵌入矩阵,wp为位置嵌入矩阵,然后通过12层transformer块,输入输出保持一致,然后通过softmax获得logits。
微调
保存之前阶段训练的参数,在上述结构的基础上,去掉softmax层,然后加上一层全连接层与特定任务的softmax,然后用有标签的数据集训练,在这期间,半监督学习的参数可以选择处于冻结状态,然后只更新新的全连接层参数。 Loss function 采用 半监督阶段与微调阶段的加权和。
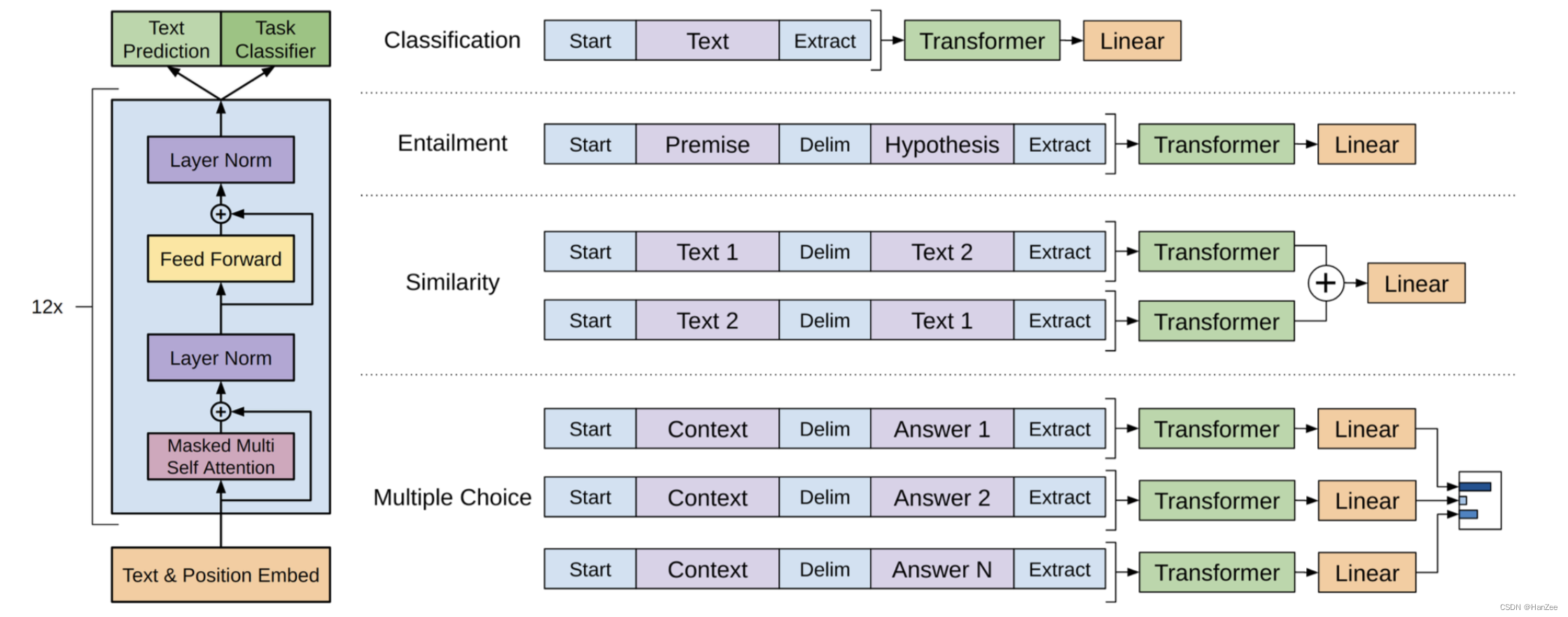
下面是作者给定的各个任务微调的模版:
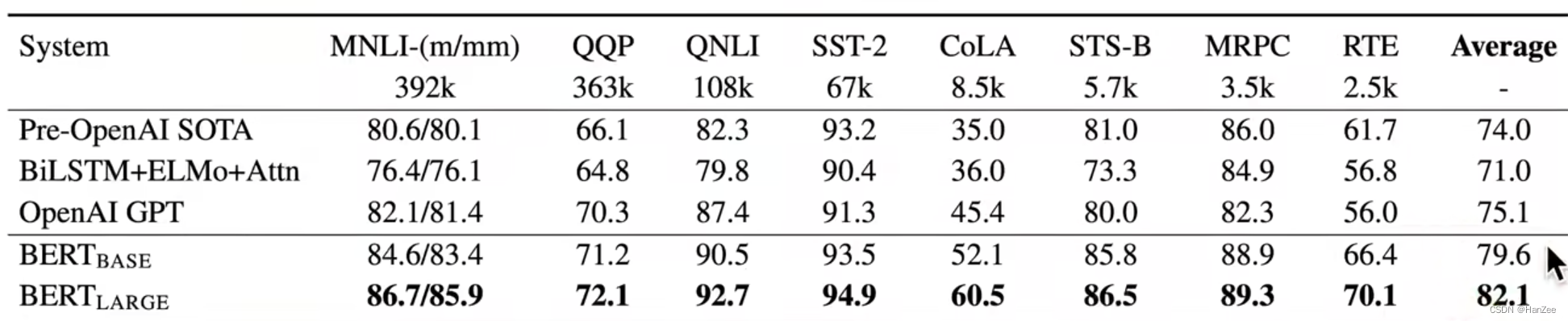
Experiment
GPT-2
Introduction
GPT-2在初代的模型架构上变得更大了,参数量达到了1.5B,数据集改为百万级别的WebText,Bert当时最大的参数数量为0.34B,但是作者发现模型架构与数据集都扩大的情况下,与同时期的Bert的优势并不大。
作者提到在当时主流的方法就是在特定的任务上使用特定的数据集,模型跨任务之间的任务泛化性不是特别好,于是作者着重讲了Zero-Shot这个概念。
Zero-shot是指 GPT-2在训练语言模型时与GPT-1的方法一致(文字接龙),只是在模型结构上做了略微的调整,层数与维度做了更大了。在做下游任务时,不再进行微调,最后作者通过实验发现,只进行简单的Zero-Shot,就能与同时期微调后的模型性能相差不大。
Approach
GPT2是在预训练时就考虑各种不同的任务(就是在训练样本中加入了下游任务的相关描述)
,即从:

在模型结构上,调整了每个block Layer Normalization的位置: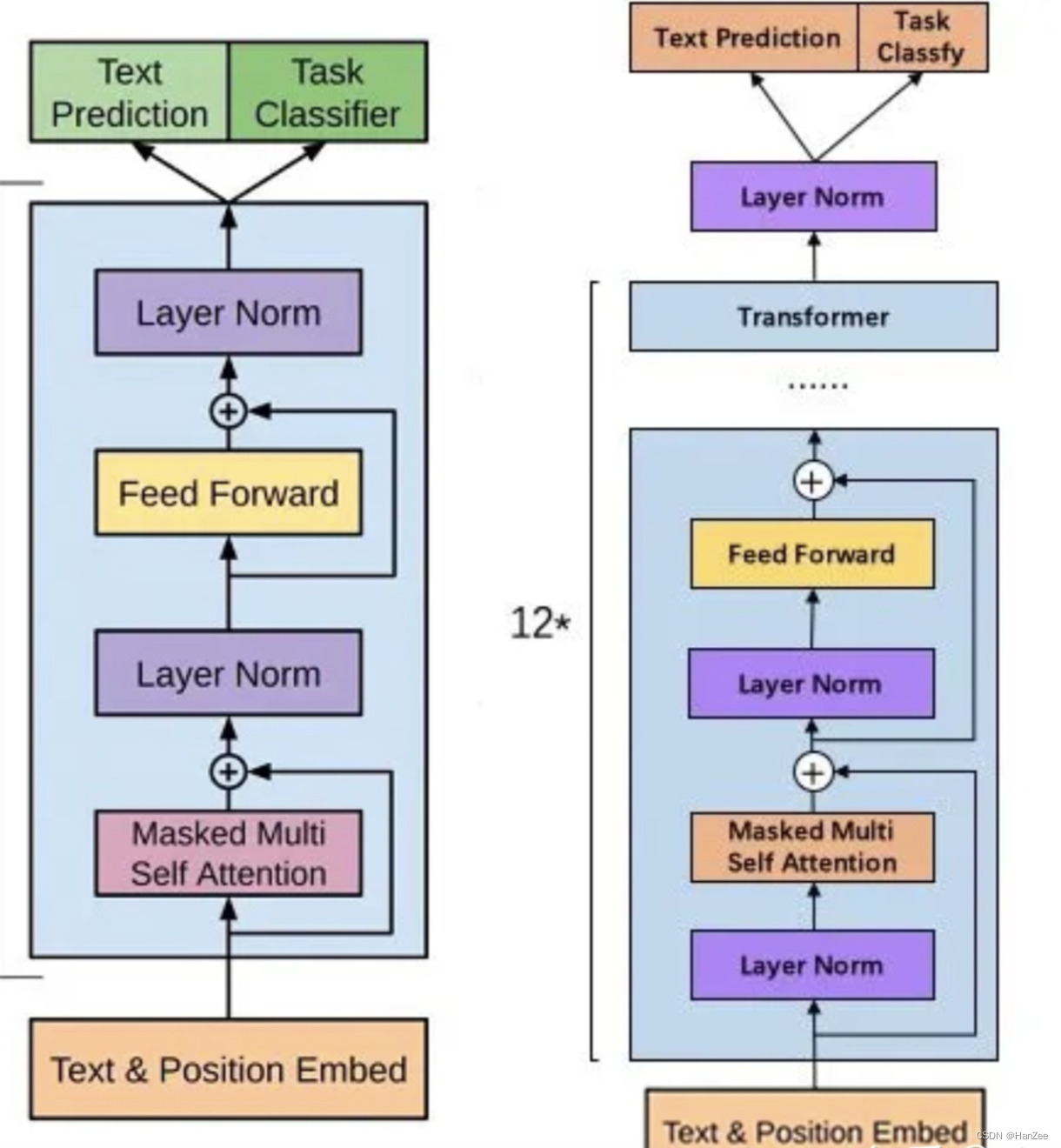
Conclusion
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是我们仍不清楚GPT-2的这种策略究竟能做成什么样子。GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了我们下面要介绍的GPT-3。
GPT-3
GPT3 可以理解为 GPT2 的升级版,使用了 45TB 的训练数据,拥有 175B 的参数量,真正诠释了什么叫暴力出奇迹。
GPT3 主要提出了两个概念:
情景(in-context)学习:就是对模型进行引导,教会它应当输出什么内容,比如翻译任务可以采用输入:请把以下英文翻译为中文:Today is a good day。这样模型就能够基于这一场景做出回答了,其实跟 GPT2 中不同任务的 token 有异曲同工之妙,只是表达更加完善、更加丰富了。
Zero-shot, one-shot and few-shot:GPT3 打出的口号就是“告别微调的 GPT3”,它可以通过不使用一条样例的 Zero-shot、仅使用一条样例的 One-shot 和使用少量样例的 Few-shot 来完成推理任务。下面是对比微调模型和 GPT3 三种不同的样本推理形式图。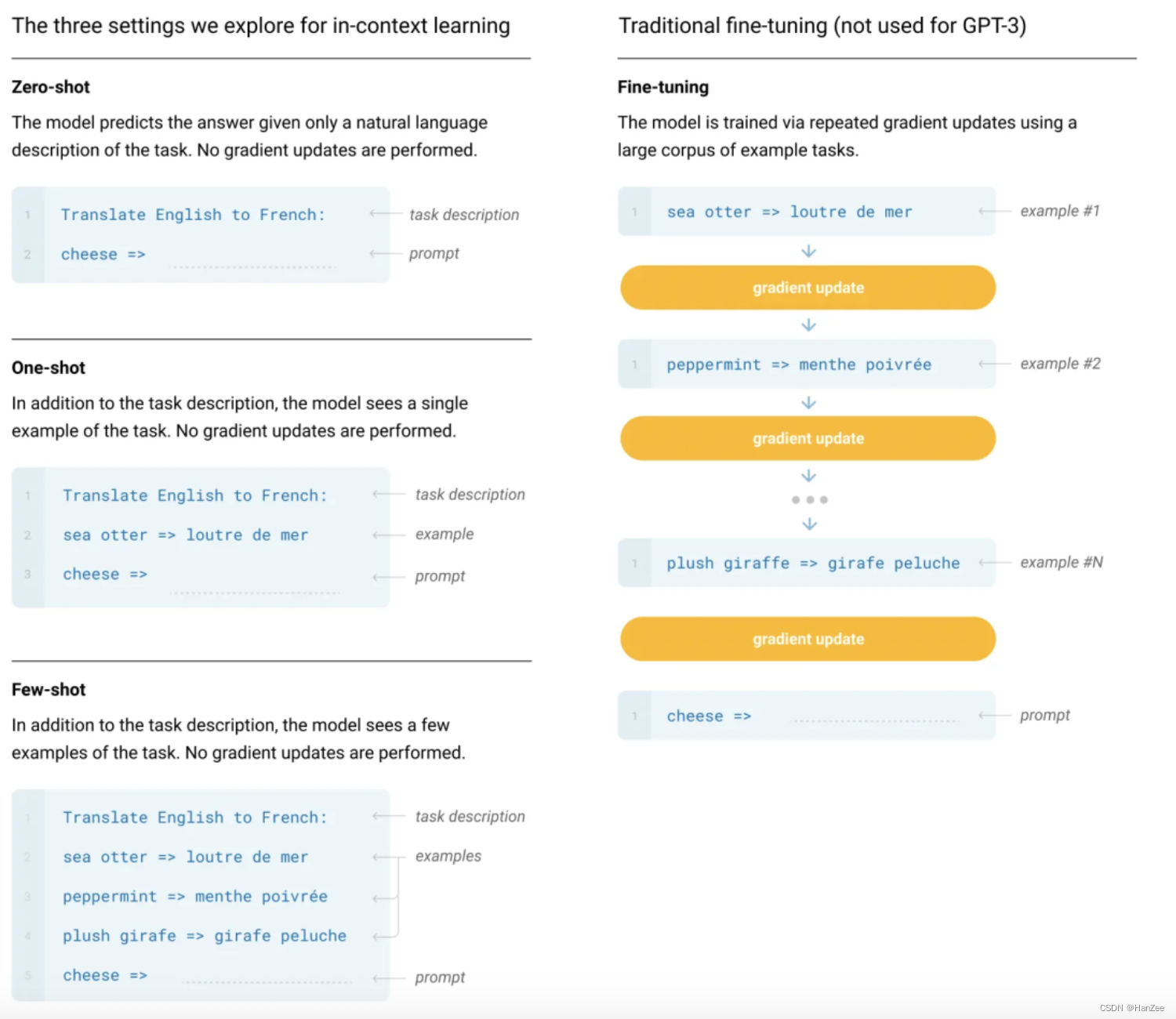
版权归原作者 HanZee 所有, 如有侵权,请联系我们删除。